More Related Content

PPT

PDF
本当にわかる Spectre と Meltdown 
PPTX

PDF
emscriptenでC/C++プログラムをwebブラウザから使うまでの難所攻略 
PPTX

PDF

PDF

PDF
20230105_TITECH_lecture_ishizaki_public.pdf What's hot

PDF

PDF
Nervesが開拓する「ElixirでIoT」の新世界 
PDF
エンジニアなら知っておきたい「仮想マシン」のしくみ v1.1 (hbstudy 17) 
PDF

PDF
Docker 9 tips~意外と知られていない日常で役立つ便利技 
PDF

PDF

PDF

PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料) 
PDF
OpenAPI 3.0でmicroserviceのAPI定義を試みてハマった話 
PDF

PPTX
そうだったのか! よくわかる process.nextTick() node.jsのイベントループを理解する 
PDF

PDF
OpenStackで始めるクラウド環境構築入門(Horizon 基礎編) 
PDF
YugabyteDBを使ってみよう - part2 -(NewSQL/分散SQLデータベースよろず勉強会 #2 発表資料) 
PDF
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021 
PPTX
世界一わかりやすいClean Architecture 
PPTX
BuildKitによる高速でセキュアなイメージビルド 
PDF

PDF
Similar to SpectreとMeltdown:最近のCPUの深い話

PDF
Meltdown/Spectreの脆弱性、リスク、対策 
PPTX

PDF

PDF
SpectreBustersあるいはLinuxにおけるSpectre対策 
PDF
2012-04-25 ASPLOS2012出張報告(公開版) 
PDF

PDF

PDF
C base design methodology with s dx and xilinx ml 
PDF

PPTX
20200709 fjt7tdmi-blog-appendix 
PDF

PDF
【de:code 2020】 AI on IA 最新情報 ~ CPU で AI を上手に動かすための 5 つのヒント ~ ![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理 ![[CB19] Semzhu-Project – 手で作る組込み向けハイパーバイザと攻撃検知手法の新しい世界 by 朱義文](https://cdn.slidesharecdn.com/ss_thumbnails/semzhu-projectcodeblue2019ja-191211063913-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[CB19] Semzhu-Project – 手で作る組込み向けハイパーバイザと攻撃検知手法の新しい世界 by 朱義文 
PDF
バイナリより低レイヤな話 (プロセッサの心を読み解く) - カーネル/VM探検隊@北陸1 
PPTX
2017-11-15 OpenStack最新情報セミナー Lightning Talk OpenStack環境における通信高速化 ~超入門~ 
PDF

PDF
0章 Linuxカーネルを読む前に最低限知っておくべきこと 
PDF
【学習メモ#7th】12ステップで作る組込みOS自作入門 
PDF
More from LINE Corporation

PDF

PDF
Reduce dependency on Rx with Kotlin Coroutines 
PDF
Kotlin/NativeでAndroidのNativeメソッドを実装してみた 
PDF
Use Kotlin scripts and Clova SDK to build your Clova extension 
PDF
The Magic of LINE 購物 Testing 
PPTX

PDF
UI Automation Test with JUnit5 
PDF
Feature Detection for UI Testing 
PDF

PDF

PDF

PDF

PDF
LINE Chatbot - 活動報名報到設計分享 
PDF
在 LINE 私有雲中使用 Managed Kubernetes 
PDF

PDF
LINE 區塊鏈平台及代幣經濟 - LINK Chain及LINK介紹 
PDF
LINE Things - LINE IoT平台新技術分享 
PDF

PDF
LINE Platform API Update - 打造一個更好的Chatbot服務 
PDF
Keynote - LINE 的技術策略佈局與跨國產品開發 SpectreとMeltdown:最近のCPUの深い話
- 1.
Spectre と Meltdown:
最近のCPU の深い話
LINE Developer Meetup #42 @京都 2018/07/26
LINE 株式会社 開発1センター LINE開発1室
Hirotaka Kawata @hktechno
- 2.
自己紹介
川田 裕貴 (HirotakaKawata) @hktechno
● 開発1センター LINE 開発1室
○ LINE スタンプ・着せかえ・絵文字ショップの開発
○ IoT 関連のことを少々
● 昔話: 友達と FPGA で自作 CPU を作っていた
○ 主にコンパイラ (gcc の移植) をしていた
○ 本を書いた http://amzn.asia/g2NTIUW
● セキュリティ・キャンプ全国大会2018 講師
○ 同じような話をする予定
- 3.
- 4.
Spectre と Meltdownについて
CPU を対象としたサイドチャネル攻撃に対する脆弱性
● 2018年1月に Google の Project Zero などが共同で公開した
論文が発端
○ https://meltdownattack.com/
● オリジナルの手法は大きく分けて3つ (Variant 1,2,3)
○ Variant 3 のことを特に Meltdown と呼ぶ
● 現代の CPU アーキテクチャを巧妙に操ることにより、
サイドチャネル攻撃を可能に
○ 具体的には、メモリ内容の吸い取り
- 5.
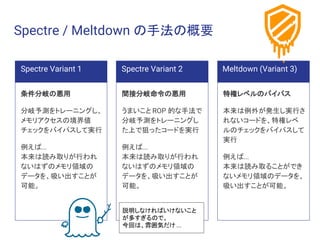
Spectre / Meltdownの手法の概要
Code Name 通称 CVE
Spectre Variant 1 Bounds Check Bypass CVE-2017-5753
Variant 2 Branch Target Injection CVE-2017-5715
Meltdown Variant 3 Rouge Cache Data Load CVE-2017-5754
Spectre / Meltdown には、大きく3つの手法が存在する
- 6.
Spectre / Meltdownの手法の概要
条件分岐の悪用
分岐予測をトレーニングし、
メモリアクセスの境界値
チェックをバイパスして実行
例えば...
本来は読み取りが行われ
ないはずのメモリ領域の
データを、吸い出すことが
可能。
Spectre Variant 2
間接分岐命令の悪用
うまいこと ROP 的な手法で
分岐予測をトレーニングし
た上で狙ったコードを実行
例えば...
本来は読み取りが行われ
ないはずのメモリ領域の
データを、吸い出すことが
可能。
Meltdown (Variant 3)
特権レベルのバイパス
本来は例外が発生し実行さ
れないコードを、特権レベ
ルのチェックをバイパスして
実行
例えば...
本来は読み取ることができ
ないメモリ領域のデータを、
吸い出すことが可能。
Spectre Variant 1
説明しなければいけないこと
が多すぎるので、
今回は、雰囲気だけ ...
- 7.
- 8.
Meltdown と Spectreの難しい点
よく CPU アーキテクチャを理解していないと、理解困難
● アセンブリが書けるだけでは、知識が足りない
● 繊細な CPU の気持ちを、よくわかっている必要がある
ハードウェア由来の脆弱性、ソフトウェアでの対策が困難
● 不可能ではないが、パフォーマンスの低下を伴う
● Spectre Variant 2 については、一部のアーキテクチャでは
ハードウェア支援がないと対策がとても難しい
- 9.
サイドチャネル攻撃 - Flush+ Reload
メモリアクセスのレイテンシの差を利用した攻撃
1. キャッシュをクリア (特に、以下の array2 の領域)
○ キャッシュを追い出す (Eviction) させてもいい
2. メモリを間接的にアクセスさせる
○ y = array2[array[x] * 4096]
○ array[x] のメモリ内容を基に array2 にアクセスする
○ 4096 をかけるのは、プリフェッチを防ぐため
3. array2 のアクセスレイテンシを調べる
○ キャッシュに乗っていればレイテンシ低⇓
○ 過去にアクセスされた可能性大 => 値がわかる
- 10.
- 11.
サイドチャネル攻撃 - Flush+ Reload
array2
攻撃対象
data[x] = 0xa
array1
CPU
時間のかかる何か
if (Array 境界値チェック)
array1[array2[x]]
その先の何か
まだ終わってない
x は確定していた!
array[0xa] もアクセスできる!
キャッシュに乗る!
準備完了
先に実行だ!
- 12.
サイドチャネル攻撃 - Flush+ Reload
array2
攻撃対象
data[x] = 0xa
array1
CPU
array1 を Flush
時間のかかる何か
if (Array 境界値チェック)
array1[array2[x]]
その先の何か
array1 を Reload
Array1 のキャッシュを消す
Array1 のアクセスレイテンシをチェック
過去にアクセスしたことがあれば速い。
レイテンシの差で、array2 のデータがわかる...
- 13.
- 14.
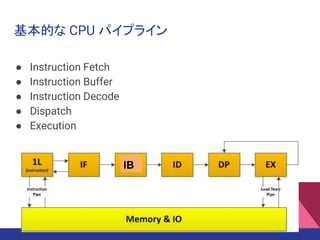
基本的な CPU パイプライン
●Instruction Fetch
● Instruction Buffer
● Instruction Decode
● Dispatch
● Execution
IB
- 15.
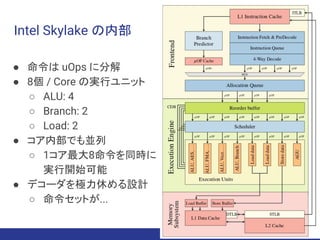
Intel Skylake の内部
●命令は uOps に分解
● 8個 / Core の実行ユニット
○ ALU: 4
○ Branch: 2
○ Load: 2
● コア内部でも並列
○ 1コア最大8命令を同時に
実行開始可能
● デコーダを極力休める設計
○ 命令セットが...
- 16.
- 17.
Meltdown / Spectreがなぜ起きるのか
現代の CPU が命令を実行する際に行う、高度なハードウェアレ
ベルでの最適化が原因
● 特に、”投機的実行 (Speculative Execution)” と呼ばれる、命
令を先読みして高速化する手法が問題
CPU 内で行われる投機的実行の例
● 命令のプリフェッチ
● ☆ アウト・オブ・オーダー実行 (順序を守らない実行)
● ☆ 分岐予測器を組み合わせた投機的実行
- 18.
- 19.
- 20.
アウト・オブ・オーダー実行
(Out of OrderExecution, OoO)
先読みした命令の依存関係を解析して、実行できる命令から実際
の記述順序を無視して先に実行する
● 命令間のレジスタ依存関係を動的に解析する
○ 例えば、即値ロード命令は他の命令と依存関係がない
○ 即値ロード命令の例: mov eax, 0x1
● CPU は、複数の命令実行ポートを持っている
○ すべての命令が同時に実行完了するとは限らない
● 依存しているレジスタの結果が準備されたら、先に実行
○ レジスタマッピングや、書き戻しのバッファリングにより整
合性を保つ
- 21.
- 22.
- 23.
アウト・オブ・オーダー実行の疑問
● あるレジスタ (eaxや ebx) は CPU 内に1つじゃないの?
○ レジスタ・リネーミングを利用しています
○ 実はすべてただのエイリアスです
● CPU 内部で ”同時” に実行できる命令は1つじゃないの?
○ 複数の命令実行ポートが並列に並べられています
○ 例えば、Haswell 以降なら8実行ポート
● メモリアクセスを行う命令も並列に実行するの?
○ Intel の最近の CPU はメモリアクセスも OoO です
● なんでコンパイラでやらないの?
○ 成功していたら Itanium は死んでいない
- 24.
アウト・オブ・オーダー実行を支える技術 - 1
レジスタ・リネーミング(Register Renaming)
● 物理レジスタを、内部の仮想レジスタにリネームする
● 命令の依存をより少なくできる
mov eax, [eax]
inc eax
mov [eax], eax
mov eax, ebx
mov eax, [eax]
同じ eax レジスタ
しかし、依存はない
実は先に実行可能
- 25.
アウト・オブ・オーダー実行を支える技術 - 1
レジスタ・リネーミング(Register Renaming)
● 内部的なレジスタファイル内の物理レジスタと、論理レジスタ
(eax, ebx…) との対応を持つ
○ 論理レジスタの数倍の物理レジスタを持っている
mov r1, [r1]
inc r1
mov [r1], r1
mov r3, r2
mov r3, [r3]
レジスタ依存はない
先に実行可能
- 26.
アウト・オブ・オーダー実行を支える技術 - 2
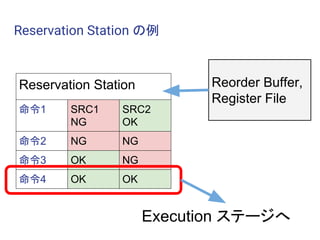
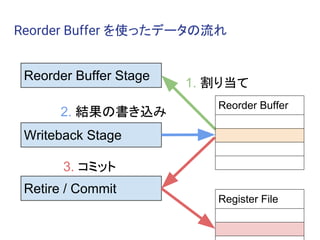
Tomasuloのアルゴリズム
● Reservation Station
○ 命令の依存関係を待つところ
○ ソースレジスタが利用可能かを監視して、 実行可能であれ
ば実行を開始する
○ Unified な方式、実行ポートごとに持たせる方式
● Re-order Buffer
○ 命令のコミットを制御するバッファ
○ 演算の結果は一度ここへ書かれる
※ 実際の Intel の CPU がこの通り実装されているわけではない
- 27.
- 28.
- 29.
- 30.
- 31.
分岐予測の例 - 簡単な分岐命令
moveax, [eax]
cmp eax, 0
je is_zero
...
...
is_zero:
...
...
実行完了するまで
Jump するかわからない
Load (遅い)
Block 1
Block 2
Block1 or Block2
どちらかを投機的に実行したいが、高
確率で正解を選びたい
基本的な if 文であれば PC 相対ジャンプであることが多い
- 32.
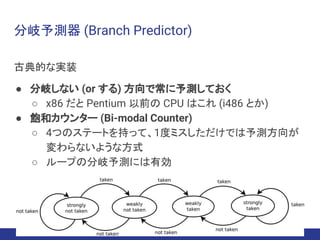
分岐予測器 (Branch Predictor)
古典的な実装
●分岐しない (or する) 方向で常に予測しておく
○ x86 だと Pentium 以前の CPU はこれ (i486 とか)
● 飽和カウンター (Bi-modal Counter)
○ 4つのステートを持って、1度ミスしただけでは予測方向が
変わらないような方式
○ ループの分岐予測には有効
- 33.
分岐予測器 - 最近のCPU の実装
いくつかの方式の組み合わせで、あらゆるパターンでも予測
● 局所的分岐予測
○ 同じアドレスの命令の、過去の分岐履歴を利用
○ 同じアドレスで、同じパターンを繰り返す場合有用
● グローバル分岐予測
○ 過去のコア全体の分岐履歴のパターンをもとに、次の分岐
の挙動を予測
● 上記の組み合わせを bit 演算で行い、予測テーブルを引く
○ PC + 局所履歴 + グローバル履歴
○ 具体的な実装は後述
- 34.
分岐予測の例 - 絶対アドレス間接ジャンプ
(IndirectBranch)
レジスタに格納されたアドレスにジャンプする場合
● レジスタに格納されたアドレスが確定するまで、投機的実行が
できない
○ これまでの手法は、PC 相対 + 即値ジャンプの場合
○ 間接ジャンプで、特にLoad が噛むととても遅い
● 間接ジャンプ先も、実は予測可能では?
○ 同じ PC のジャンプは、よく同じアドレスにジャンプするので
はないか?
● BTB (Branch Target Buffer) というテーブルを持つ
※ PC (Program Counter): Intel では IP (Instruction Pointer)
実行中命令のアドレスのこと
- 35.
現代の CPU の分岐予測器の進化
分岐予測器の進化は、最近でも続いている(というかアツい)
● 電力をそれほど消費せずに性能向上が可能
○ 分岐予測のミスは大きなペナルティ
○ ブランチ命令の先のパイプラインが止まってしまう
● ニューラルネットワーク分岐予測機
○ AMD の CPU? Intel も?
● 各社詳しい仕様は公開していない
○ 改良されたという事実のみが記載されている
○ 外側から観察して挙動を推測するのみ
- 36.
- 37.
- 38.
Spectre Variant 1対策
array の index のビットをマスクする
● array の外側にアクセスできないようにすればいい
○ ブランチ命令はいくらでも学習可能なので使えない
○ 投機的実行が起きても問題ないように
● ビット演算のみで行う
○ パフォーマンス低下もそれほどではない
● Linux Kernel : array_index_nospec
○ https://github.com/torvalds/linux/blob/v4.17/include/l
inux/nospec.h#L49
- 39.
- 40.
Meltdown - SpectreVariant 3
ユーザー権限で任意のメモリ領域の内容を推測可能な脆弱性
● Spectre シリーズの中で最もリスクが高い (個人的な感想)
● カーネル空間に物理メモリがそのままマップされている
○ Linux (x86_64) の場合 0xffff800000000000
○ 通常は、ユーザーモードから読むことは不可能
● 投機的実行と CPU の特権レベルの関わりが影響
○ 特権レベルを無視して CPU が投機的実行を行う
○ 投機的実行を行ったあとに、特権違反により例外発生
○ キャッシュの内容は...?
- 41.
Meltdown の裏側 -投機的実行
コードでは3行で説明できるぐらい簡単
● 裏で何が起きているのかを説明するのが難しい
...
raise_exception(); // 実際はここまで
// 以下の行には到達しない, でも OoO で実行されてる
access(probe_array[data * 4096]);
CPU の投機的実行は何を行うのだろう?
- 42.
Meltdown の裏側 -投機的実行
kernel_adder の内容を Flush+Reload で推測する例
raise_exception();
access(probe_array[*kernel_addr * 4096]);
投機的実行により、kernel_addr と proble_array の load が
raise_exception() より先に行われる
● 特権レベルの確認は、後から行われる
● proble_array を Flush + Reload で *kernel_addr を吸い出し
- 43.
Meltdown の裏側 -投機的実行
Meltdown のアセンブリの例
; rcx = kernel address
; rbx = probe array
retry:
mov al, byte [rcx] ; 実際はここで例外
shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax]
- 44.
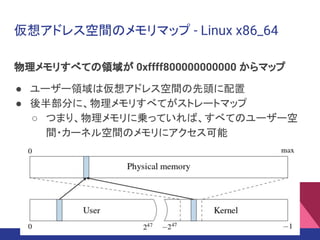
仮想アドレス空間のメモリマップ - Linuxx86_64
物理メモリすべての領域が 0xffff800000000000 からマップ
● ユーザー領域は仮想アドレス空間の先頭に配置
● 後半部分に、物理メモリすべてがストレートマップ
○ つまり、物理メモリに乗っていれば、すべてのユーザー空
間・カーネル空間のメモリにアクセス可能
- 45.
- 46.
Meltdown 対策
Kernel PageTable Isolation : KPTI
● カーネルページテーブルの分離
○ ユーザープロセスのページテーブルから、カーネル領域が
見えないように
○ Linux では KAISER という仕組みを実装
● パフォーマンス低下の問題
○ 最近の Intel CPU では、PCID 関連サポートが有る
■ Haswell 以降
○ 新しい Kernel + CPU を使っていれば問題ない
- 47.
- 48.
Spectre Variant 2
BTB(Branch Target Buffer) と分岐履歴をコントロールして、上
手に特定のアドレスの命令を投機的実行させる
● BTB は、コア内で共通である
● 同じコア違うプロセスで、同一のメモリマップのプログラムを走
らせ、うまいこと BTB と分岐履歴を訓練
○ 例えば、SMT (HT) で動作している場合など
● その中でアクセスしたデータはキャッシュに残る
○ もしかしたらデータを抜き出せるかもしれない
○ あまり成功率は高くない
● 対策: Retpoline, (IBRS, IBPB, STIBP) 命令
- 49.
- 50.
Spectre / Meltdownまとめ
● Meltdown は大きな影響がある
○ Kernel 領域のメモリ領域の推測が比較的簡単に可能
○ 対策も、CPU によっては大きなパフォーマンス低下
○ 最新の CPU + 最新の Kernel では影響が緩和
● Spectre は...?
○ ハードウェアの根本的な動作が原因で、対策が難しい
○ 沢山の派生手法、Intel 以外の CPU でも発生
○ 対策により多少のパフォーマンス低下が発生
○ Spectre 単体でのリスクはそれほど高くない









![サイドチャネル攻撃 - Flush + Reload
メモリアクセスのレイテンシの差を利用した攻撃
1. キャッシュをクリア (特に、以下の array2 の領域)
○ キャッシュを追い出す (Eviction) させてもいい
2. メモリを間接的にアクセスさせる
○ y = array2[array[x] * 4096]
○ array[x] のメモリ内容を基に array2 にアクセスする
○ 4096 をかけるのは、プリフェッチを防ぐため
3. array2 のアクセスレイテンシを調べる
○ キャッシュに乗っていればレイテンシ低⇓
○ 過去にアクセスされた可能性大 => 値がわかる](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-9-320.jpg)
![時間のかかる何か
if (Array 境界値チェック)
array1[array2[x]]
その先の何か
サイドチャネル攻撃 - Flush + Reload
array2
攻撃対象
array1
CPU
時間かかるなぁ
ここはよく true だから今回も true のときの
処理を投機的に実行だ!
間違ってたらあとでやりなおす!](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-10-320.jpg)
![サイドチャネル攻撃 - Flush + Reload
array2
攻撃対象
data[x] = 0xa
array1
CPU
時間のかかる何か
if (Array 境界値チェック)
array1[array2[x]]
その先の何か
まだ終わってない
x は確定していた!
array[0xa] もアクセスできる!
キャッシュに乗る!
準備完了
先に実行だ!](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-11-320.jpg)
![サイドチャネル攻撃 - Flush + Reload
array2
攻撃対象
data[x] = 0xa
array1
CPU
array1 を Flush
時間のかかる何か
if (Array 境界値チェック)
array1[array2[x]]
その先の何か
array1 を Reload
Array1 のキャッシュを消す
Array1 のアクセスレイテンシをチェック
過去にアクセスしたことがあれば速い。
レイテンシの差で、array2 のデータがわかる...](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-12-320.jpg)






![アウト・オブ・オーダー実行の例
mov eax, [eax]
xor ebx, ebx
add ebx, eax
inc ecx
add eax, ecx
Load (遅い)
↑の命令とは依存がない
↑の命令とは依存がない
※ 簡単な例で、特にアセンブリに意味はない](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-21-320.jpg)
![アウト・オブ・オーダー実行の例
mov eax, [eax]
xor ebx, ebx
add ebx, eax
inc ecx
add eax, ecx
Load (遅い)
↑の命令とは依存がない
↑の命令とは依存がない
1
2
3
2
3
⇓実行順
命令の順番を入れ替えても構わない
しかも、開いてるポートで並列に実行できる](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-22-320.jpg)

![アウト・オブ・オーダー実行を支える技術 - 1
レジスタ・リネーミング (Register Renaming)
● 物理レジスタを、内部の仮想レジスタにリネームする
● 命令の依存をより少なくできる
mov eax, [eax]
inc eax
mov [eax], eax
mov eax, ebx
mov eax, [eax]
同じ eax レジスタ
しかし、依存はない
実は先に実行可能](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-24-320.jpg)
![アウト・オブ・オーダー実行を支える技術 - 1
レジスタ・リネーミング (Register Renaming)
● 内部的なレジスタファイル内の物理レジスタと、論理レジスタ
(eax, ebx…) との対応を持つ
○ 論理レジスタの数倍の物理レジスタを持っている
mov r1, [r1]
inc r1
mov [r1], r1
mov r3, r2
mov r3, [r3]
レジスタ依存はない
先に実行可能](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-25-320.jpg)



![分岐予測の例 - 簡単な分岐命令
mov eax, [eax]
cmp eax, 0
je is_zero
...
...
is_zero:
...
...
実行完了するまで
Jump するかわからない
Load (遅い)
Block 1
Block 2
Block1 or Block2
どちらかを投機的に実行したいが、高
確率で正解を選びたい
基本的な if 文であれば PC 相対ジャンプであることが多い](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-31-320.jpg)




![Spectre Variant 1
分岐予測をコントロールして、実際とは異なる方向に予測させた
上で、メモリ領域を吸い出す
if (x < array1_size)
y = array2[array1[x] * 4096];
● 予め正規の x で何度か実行し、分岐予測を訓練させる
● x を悪意のあるもの (array1_size 以上など) に設定
○ array2 の領域の読み取りが投機的実行されてしまう
○ Flush + Reload により読み取り可能](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-37-320.jpg)



![Meltdown の裏側 - 投機的実行
コードでは3行で説明できるぐらい簡単
● 裏で何が起きているのかを説明するのが難しい
...
raise_exception(); // 実際はここまで
// 以下の行には到達しない, でも OoO で実行されてる
access(probe_array[data * 4096]);
CPU の投機的実行は何を行うのだろう?](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-41-320.jpg)
![Meltdown の裏側 - 投機的実行
kernel_adder の内容を Flush+Reload で推測する例
raise_exception();
access(probe_array[*kernel_addr * 4096]);
投機的実行により、kernel_addr と proble_array の load が
raise_exception() より先に行われる
● 特権レベルの確認は、後から行われる
● proble_array を Flush + Reload で *kernel_addr を吸い出し](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-42-320.jpg)
![Meltdown の裏側 - 投機的実行
Meltdown のアセンブリの例
; rcx = kernel address
; rbx = probe array
retry:
mov al, byte [rcx] ; 実際はここで例外
shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax]](https://image.slidesharecdn.com/309264309260meltdown2fspectre-linedmkyoto3-180727042633/85/Spectre-Meltdown-CPU-43-320.jpg)