More Related Content

PDF
Fast and Light-weight Binarized Neural Network Implemented in an FPGA using L... 
PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」) 
PDF
2015年度GPGPU実践プログラミング 第9回 行列計算(行列-行列積) 
PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説 
PDF
2015年度先端GPGPUシミュレーション工学特論 第2回 GPUによる並列計算の概念と�メモリアクセス 
PDF

PDF
最近強化学習の良記事がたくさん出てきたので勉強しながらまとめた 
PDF
What's hot

PPTX

PDF

PDF

PDF
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化 
PDF
混合整数ブラックボックス最適化に向けたCMA-ESの改良 / Optuna Meetup #2 
PDF
2015年度GPGPU実践プログラミング 第7回 総和計算 
PDF

PDF

PDF

PPTX
Curriculum Learning (関東CV勉強会) 
PDF
【DL輪読会】Scaling laws for single-agent reinforcement learning 
PDF
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜 
PDF
![[DL輪読会]機械学習におけるカオス現象について](https://cdn.slidesharecdn.com/ss_thumbnails/20190419dlhacks-190510023936-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF
ARM CPUにおけるSIMDを用いた高速計算入門 
PDF

PPTX

PPTX
ウェーブレット変換の基礎と応用事例:連続ウェーブレット変換を中心に 
PDF
Tensorflow Liteの量子化アーキテクチャ Similar to LUT-Network その後の話(2022/05/07)

PPTX
LUT-Network ~本物のリアルタイムコンピューティングを目指して~ 
PPTX
LUT-Network ~Edge環境でリアルタイムAIの可能性を探る~ 
PPTX
機械学習応用システムの開発技術�(機械学習工学)�の現状と今後の展望� 
PDF
20171212 gtc pfn海野裕也_chainerで加速する深層学習とフレームワークの未来 
PPTX

PPTX

PDF
深層学習フレームワーク Chainer の開発と今後の展開 
PDF
機械学習工学と機械学習応用システムの開発@SmartSEセミナー(2021/3/30) LUT-Network その後の話(2022/05/07)
- 1.
- 2.
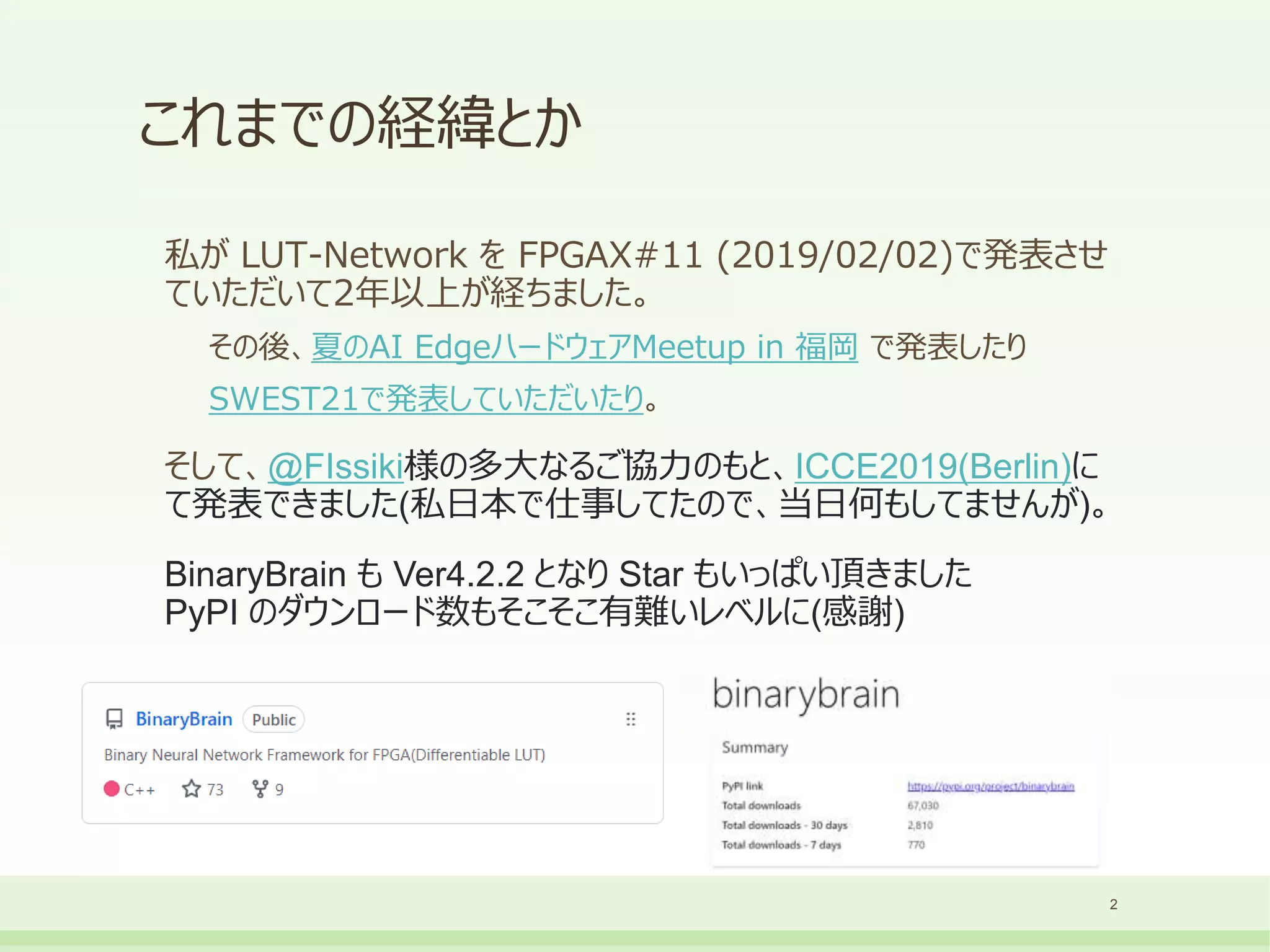
これまでの経緯とか
私が LUT-Network をFPGAX#11 (2019/02/02)で発表させ
ていただいて2年以上が経ちました。
その後、夏のAI EdgeハードウェアMeetup in 福岡 で発表したり
SWEST21で発表していただいたり。
そして、@FIssiki様の多大なるご協力のもと、ICCE2019(Berlin)に
て発表できました(私日本で仕事してたので、当日何もしてませんが)。
BinaryBrain も Ver4.2.2 となり Star もいっぱい頂きました
PyPI のダウンロード数もそこそこ有難いレベルに(感謝)
2
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
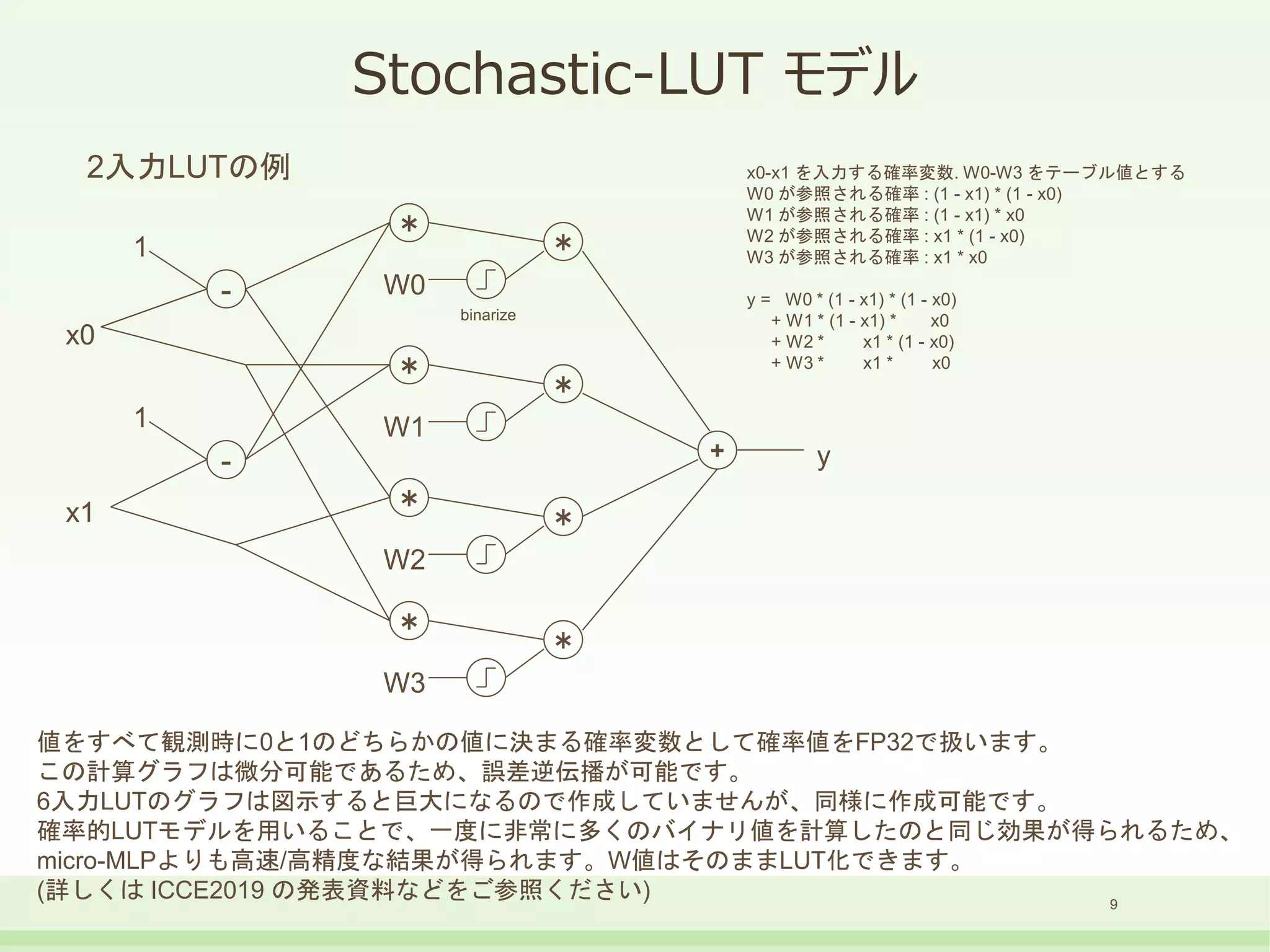
Stochastic-LUT モデル
9
-
*
-
x0
x1
*
W0
binarize
*
*
W1
*
*
W2
*
*
W3
1
1
+ y
2入力LUTの例x0-x1 を入力する確率変数. W0-W3 をテーブル値とする
W0 が参照される確率 : (1 - x1) * (1 - x0)
W1 が参照される確率 : (1 - x1) * x0
W2 が参照される確率 : x1 * (1 - x0)
W3 が参照される確率 : x1 * x0
y = W0 * (1 - x1) * (1 - x0)
+ W1 * (1 - x1) * x0
+ W2 * x1 * (1 - x0)
+ W3 * x1 * x0
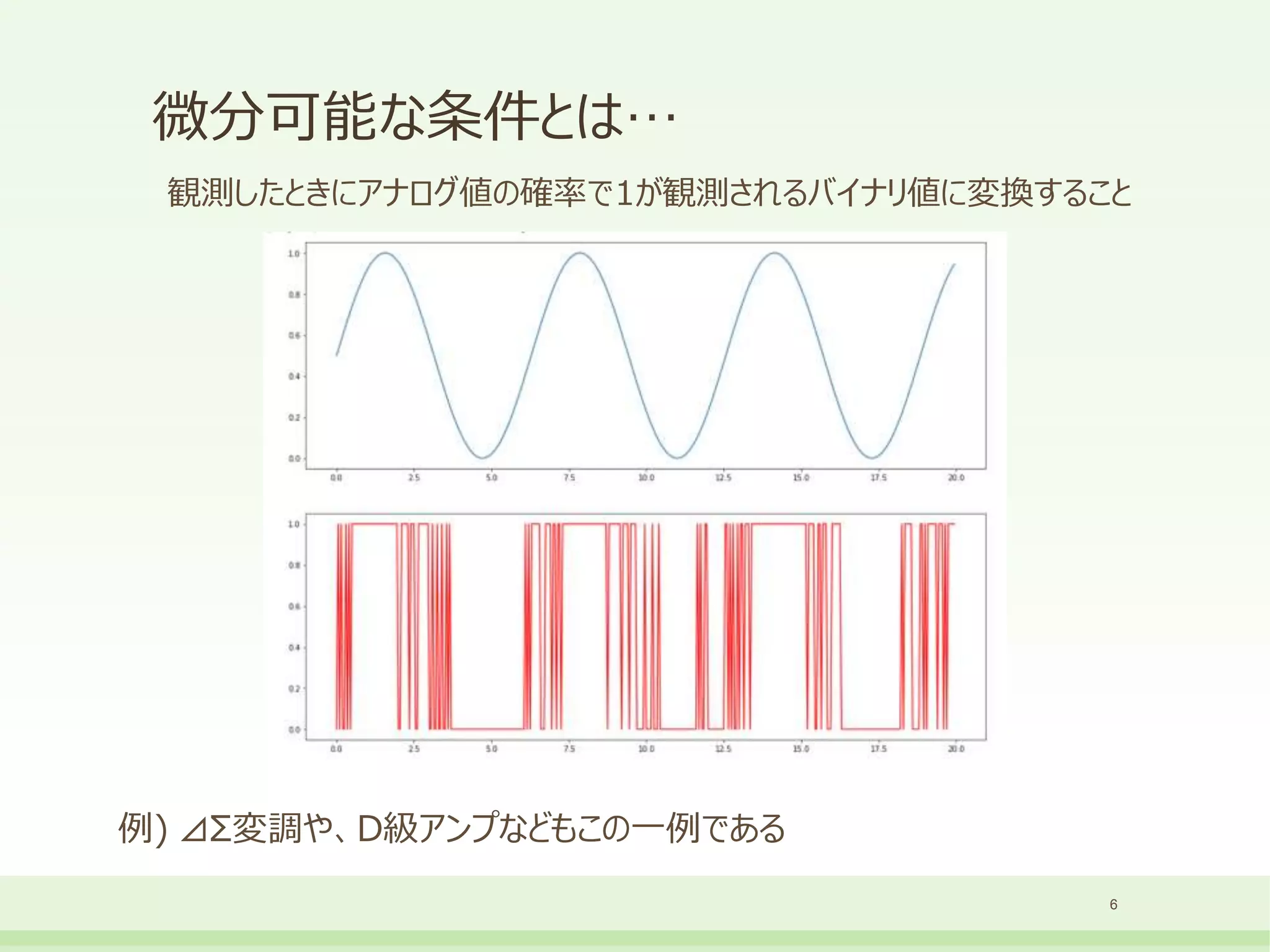
値をすべて観測時に0と1のどちらかの値に決まる確率変数として確率値をFP32で扱います。
この計算グラフは微分可能であるため、誤差逆伝播が可能です。
6入力LUTのグラフは図示すると巨大になるので作成していませんが、同様に作成可能です。
確率的LUTモデルを用いることで、一度に非常に多くのバイナリ値を計算したのと同じ効果が得られるため、
micro-MLPよりも高速/高精度な結果が得られます。W値はそのままLUT化できます。
(詳しくは ICCE2019 の発表資料などをご参照ください)
- 10.
- 11.
- 12.
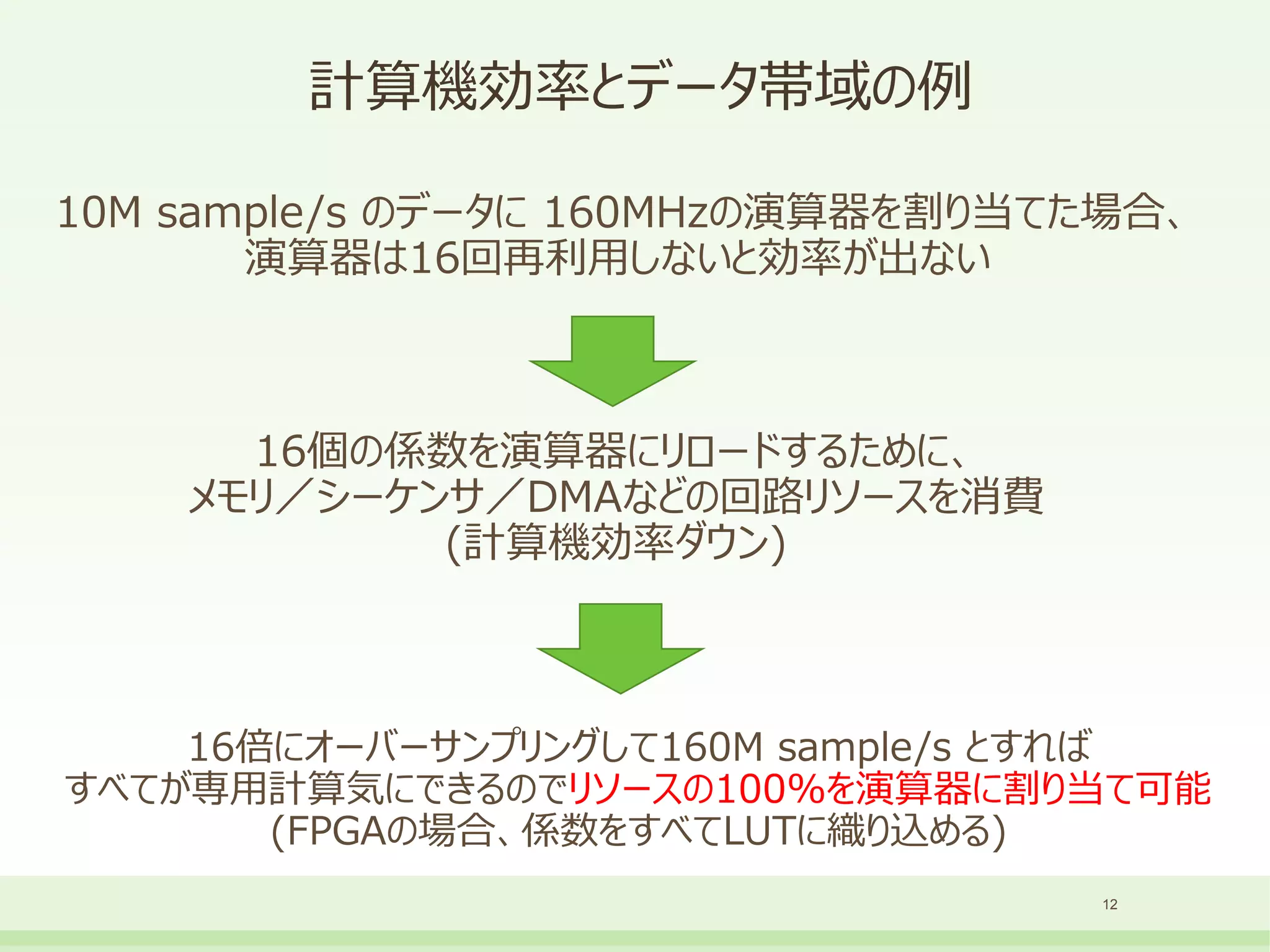
計算機効率とデータ帯域の例
10M sample/s のデータに160MHzの演算器を割り当てた場合、
演算器は16回再利用しないと効率が出ない
12
16個の係数を演算器にリロードするために、
メモリ/シーケンサ/DMAなどの回路リソースを消費
(計算機効率ダウン)
16倍にオーバーサンプリングして160M sample/s とすれば
すべてが専用計算気にできるのでリソースの100%を演算器に割り当て可能
(FPGAの場合、係数をすべてLUTに織り込める)
- 13.
- 14.
- 15.
- 16.
BinaryBrain の話
• どうやって学習させるの?となったときに 6入力1出力のLUTモデルが
細かすぎて、cuBLAS とか使って速く書くのが困難。
• なので、PyTorch とか Tensorflow でやるのは困難
• 仕方がないから自作しました → BinaryBrain
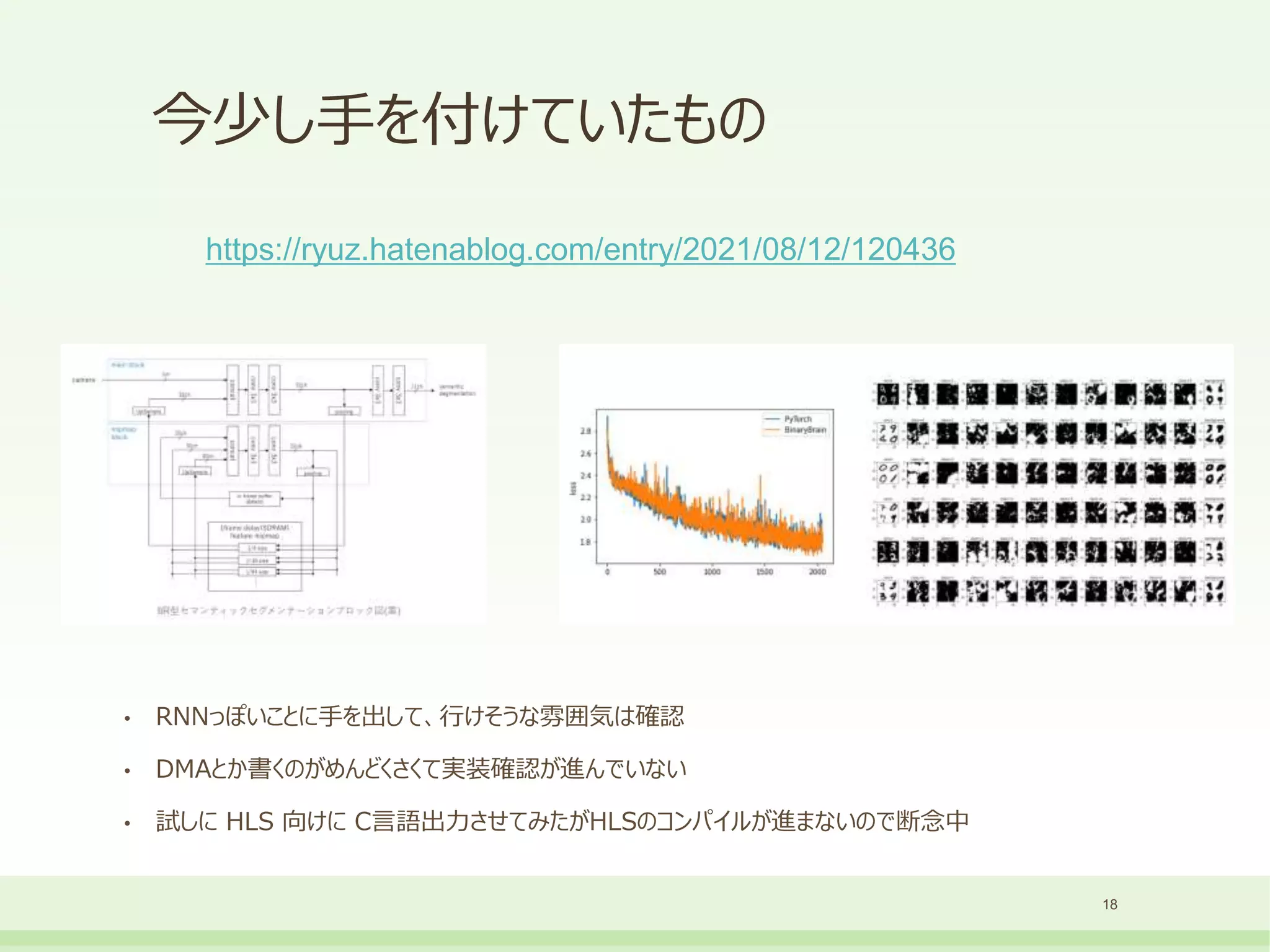
• 現在 RNN 対応とかもしつつ Ver 4 を公開中
• https://github.com/ryuz/BinaryBrain
16
- 17.
- 18.
- 19.
- 20.
• 著者アクセス先
• 渕上竜司 (Ryuji Fuchikami)
• e-mail : ryuji.fuchikami@nifty.com
• Web-Site : http://ryuz.my.coocan.jp/
• Blog. : http://ryuz.txt-nifty.com/
• GitHub : https://github.com/ryuz/
• Twitter : https://twitter.com/Ryuz88
• Facebook : https://www.facebook.com/ryuji.fuchikami
• YouTube : https://www.youtube.com/user/nekoneko1024
20





![Stochastic-LUTモデルの内部のパラメータ
10
input[n-1:0]
output
LUTテーブルは入力数nに対してn次元を持ち、その中で連続体として振舞います。
上記は2入力LUTにXORを学習させた場合の模式図です。
内部の状態テーブルを参照する形式を取るために、パーセプトロンモデルと違っ
て単独でテーブルをXOR形状に学習することも可能です
2入力LUTをXOR学習させた場合の例](https://image.slidesharecdn.com/lut-network20220507-220507041710-4cb7ebb1/75/LUT-Network-2022-05-07-10-2048.jpg)