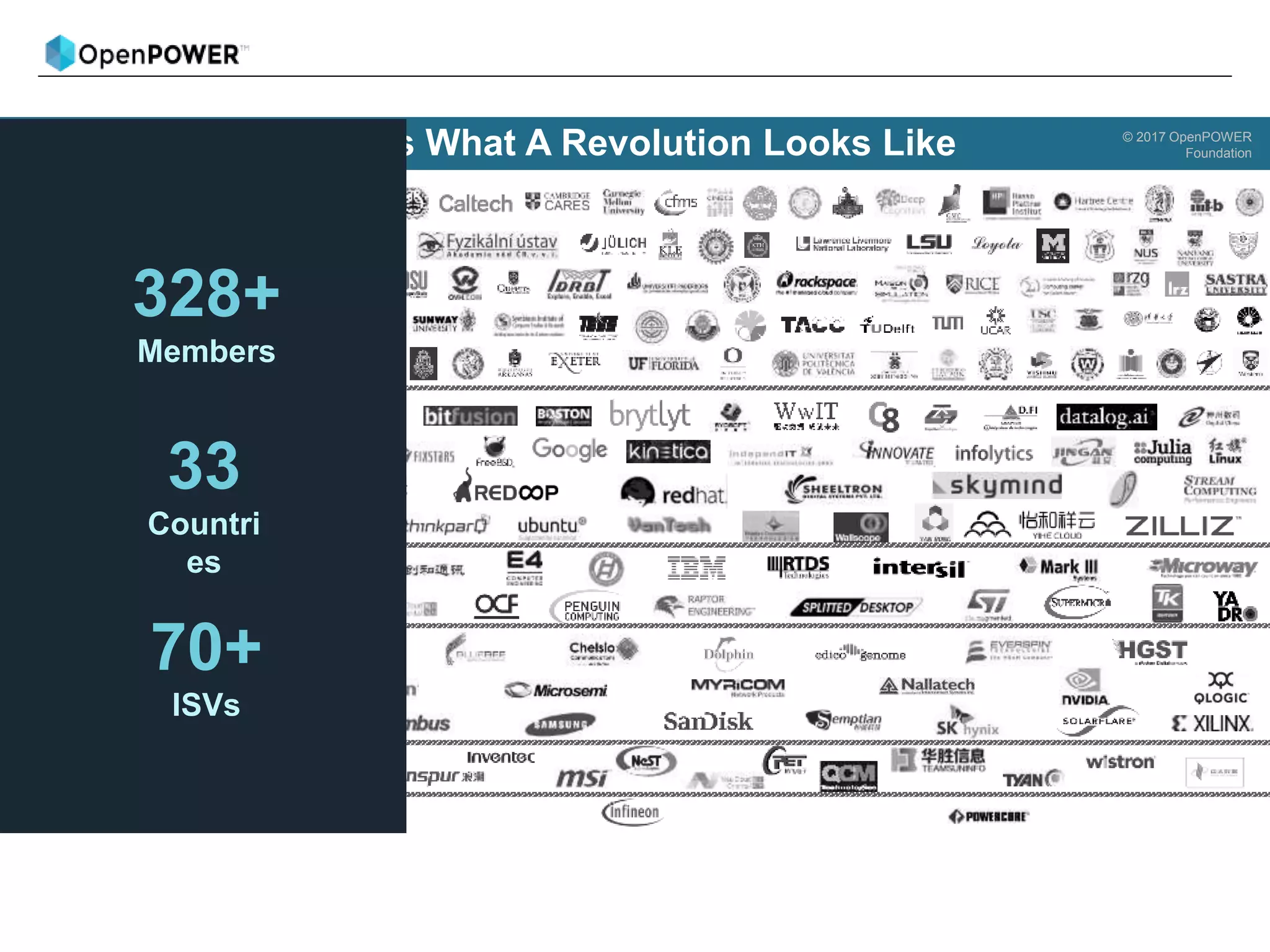
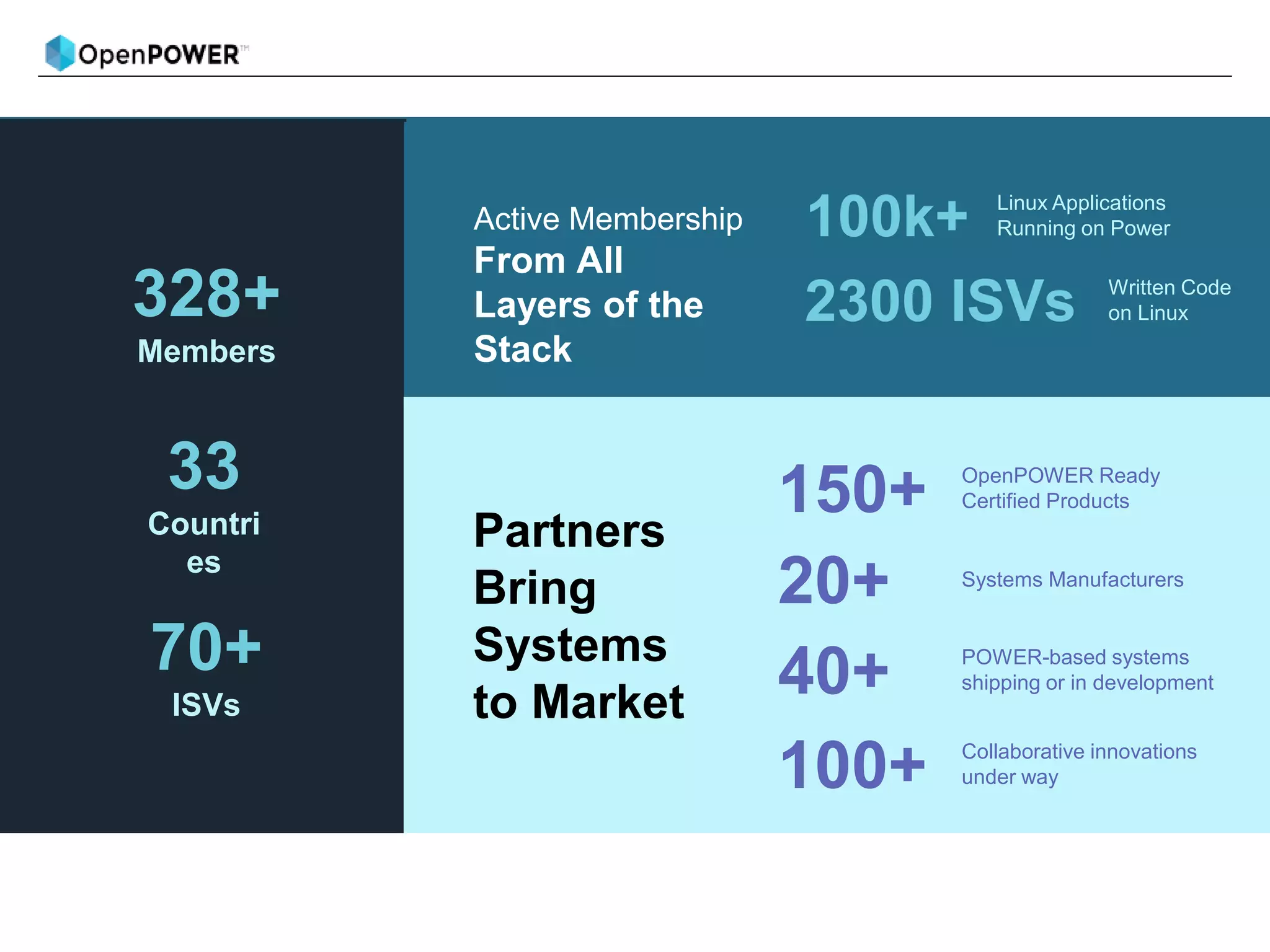
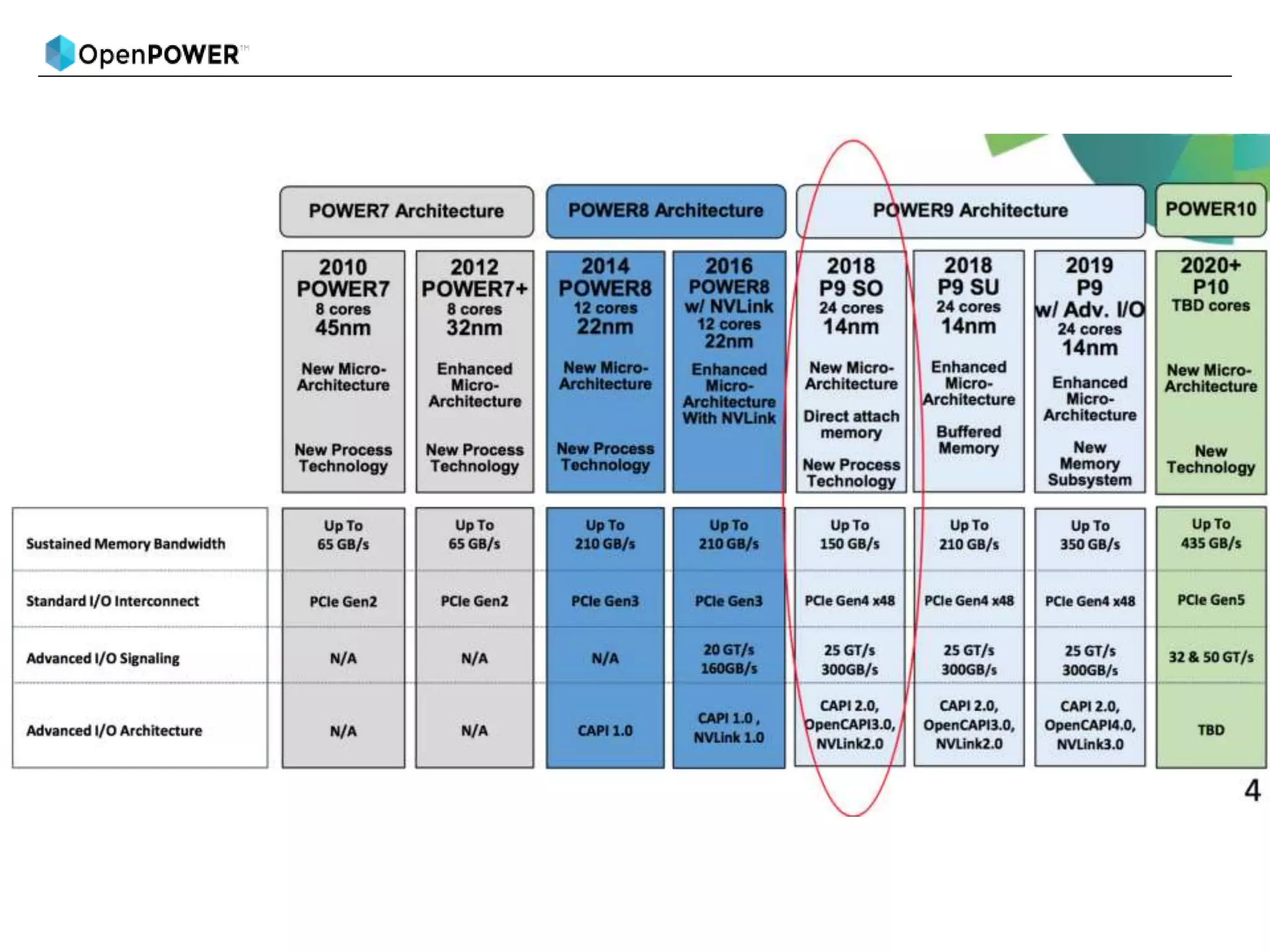
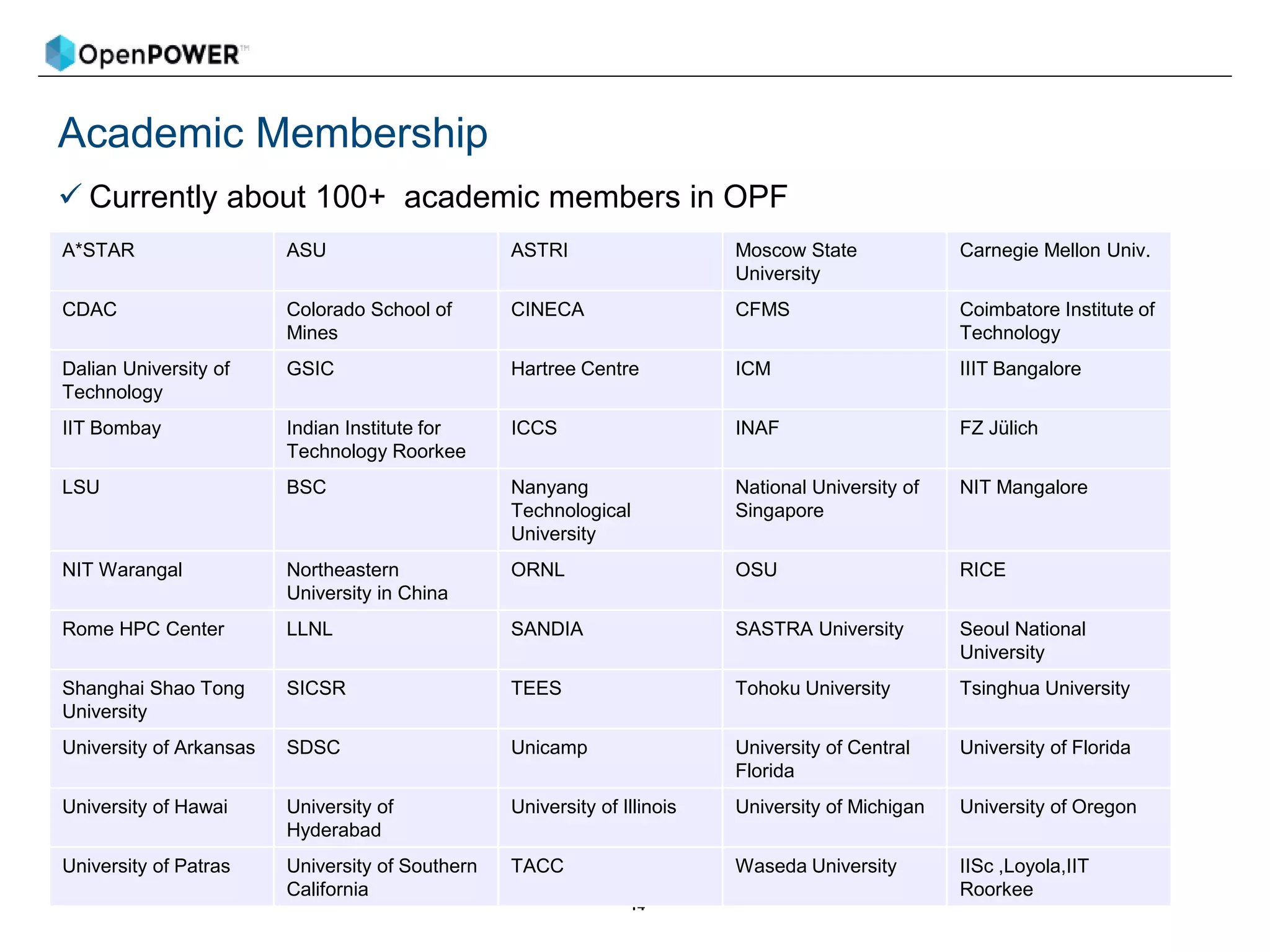
The document provides details about an OpenPOWER and AI workshop being held on June 18-19, 2018 at the Barcelona Supercomputing Center.
Day 1 will provide an introduction to AI and cover topics like Power9 and PowerAI features, large model support, and use case demonstrations. Day 2 will focus on deeper learning exercises and industry use cases using Power9 features like distributed deep learning.
The agenda lists out the schedule and topics to be covered each day, including welcome sessions, technical presentations, breaks and wrap-up discussions.



























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)










