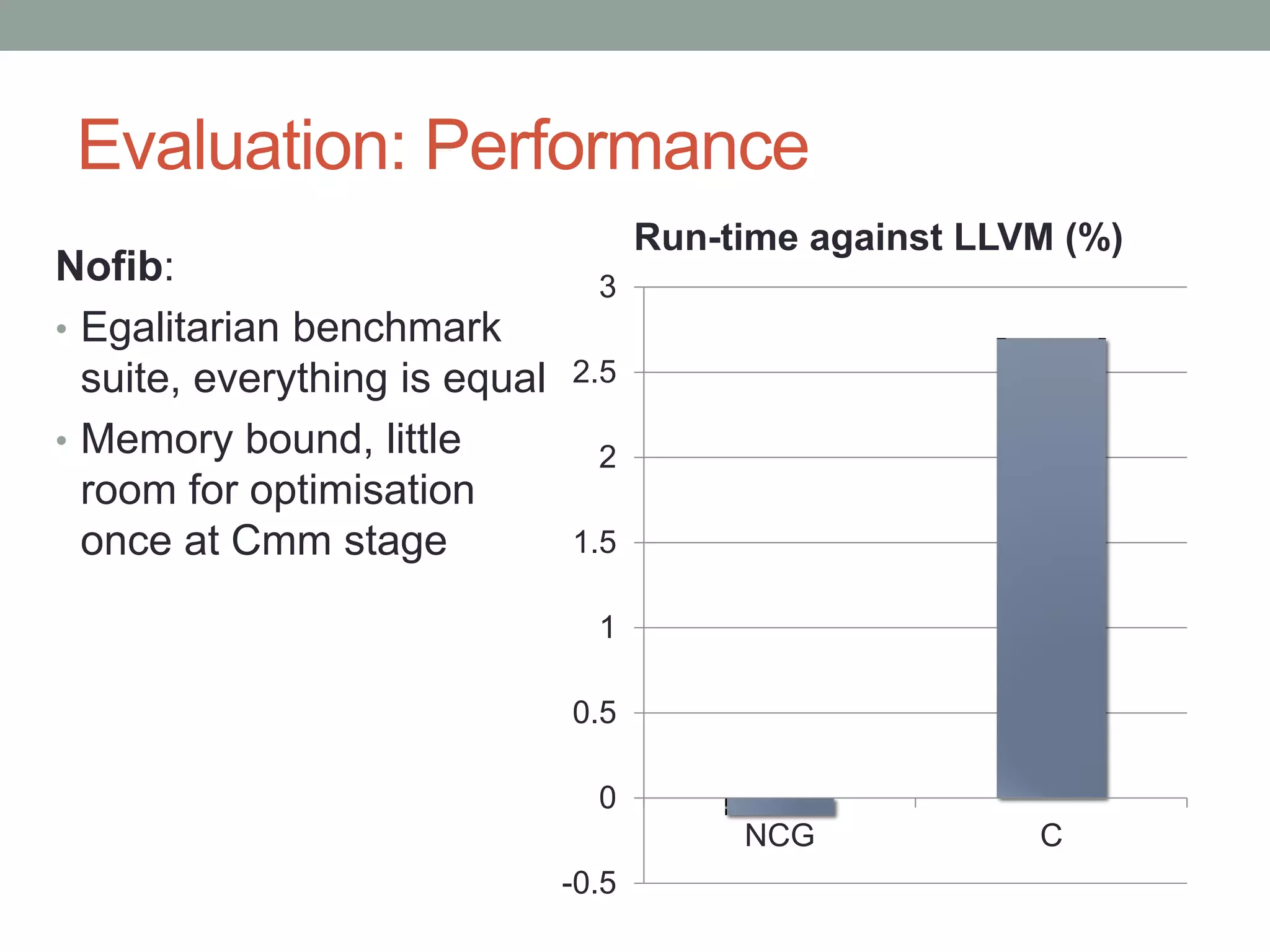
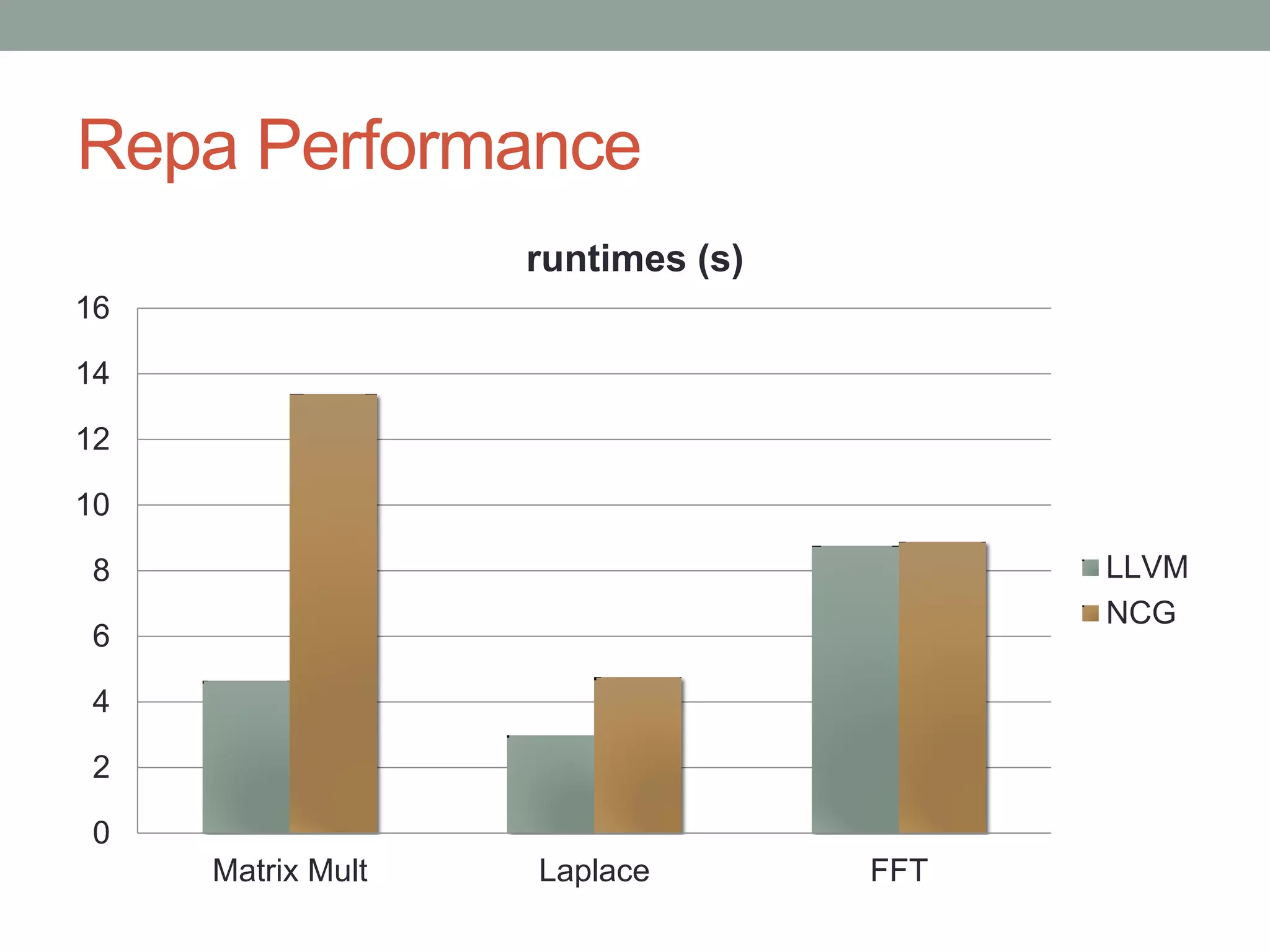
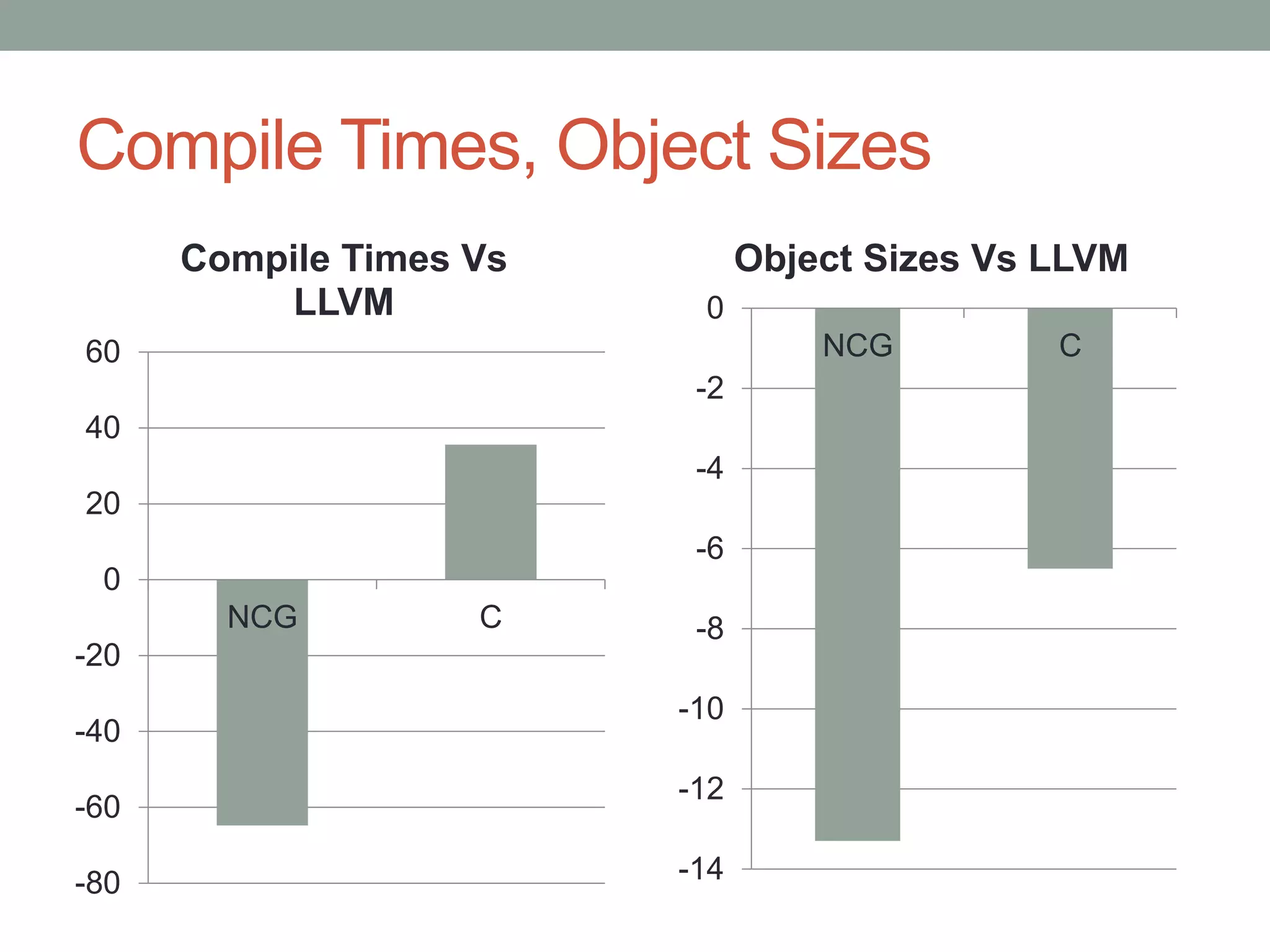
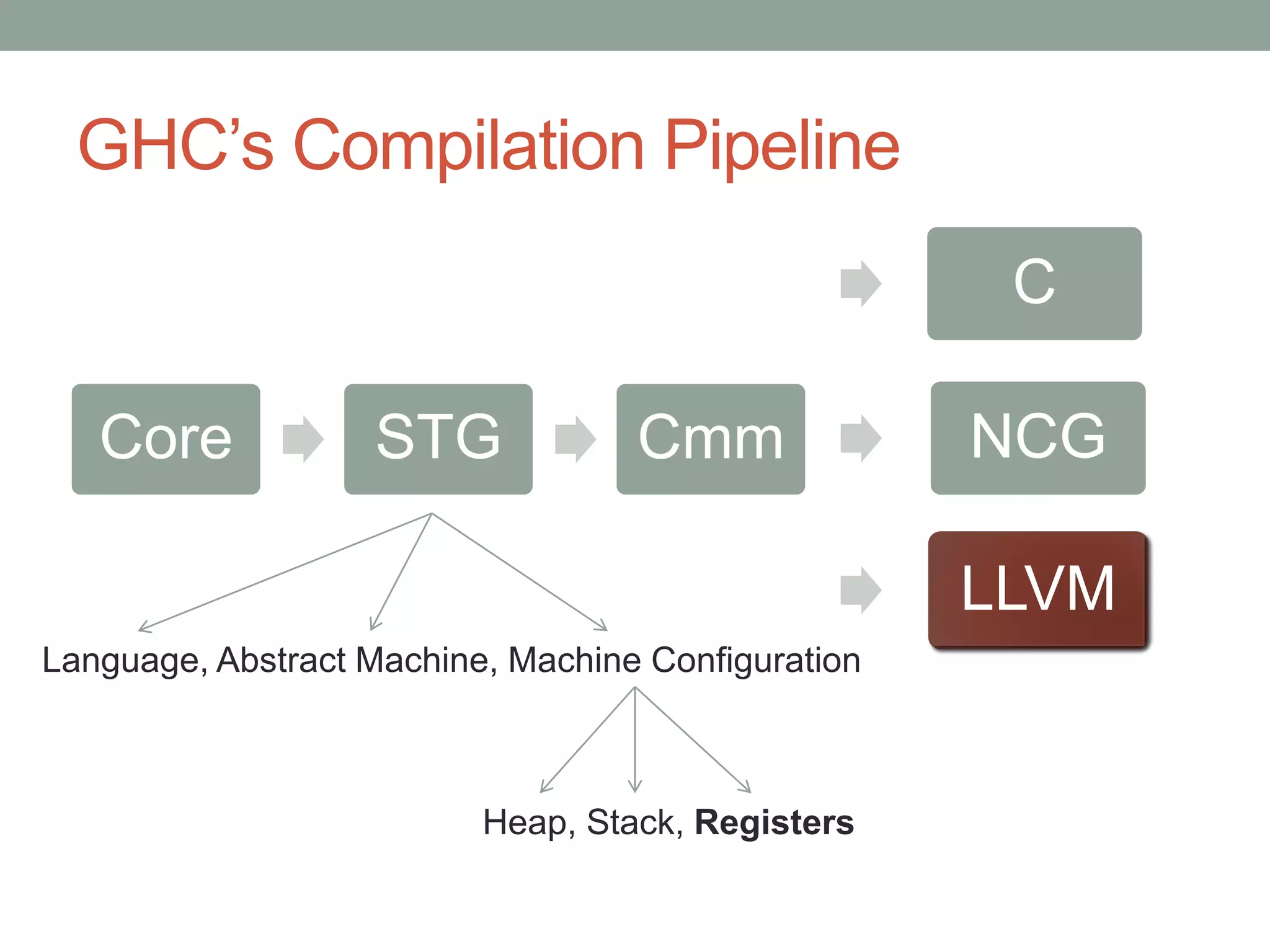
This document discusses an LLVM backend that has been developed for the GHC Haskell compiler. The LLVM backend aims to simplify GHC's compilation pipeline, improve performance, and outsource maintenance work. Key aspects covered include how the backend handles GHC's STG registers and "tables next to code" optimization. Evaluation shows the LLVM backend is simpler to develop and maintain than GHC's existing C and native code generator backends. It also provides performance that is equal to or better than the other backends.



![Example
collat :: Int -> Word32 -> Int Run-time (ms)
collat c 1 = c 2000
collat c n | even n = 1800
collat (c+1) $ n `div` 2 1600
| otherwise = 1400
collat (c+1) $ 3 * n + 1
1200
1000
pmax x n = x `max` (collat 1 n, n)
800
600
main = print $ foldl pmax (1,1)
400
[2..1000000]
200
0
LLVM C NCG
Different, updated run-times compared to paper](https://image.slidesharecdn.com/ghc-llvm-hs10-slides-111018142902-phpapp02/75/Haskell-Symposium-2010-An-LLVM-backend-for-GHC-4-2048.jpg)






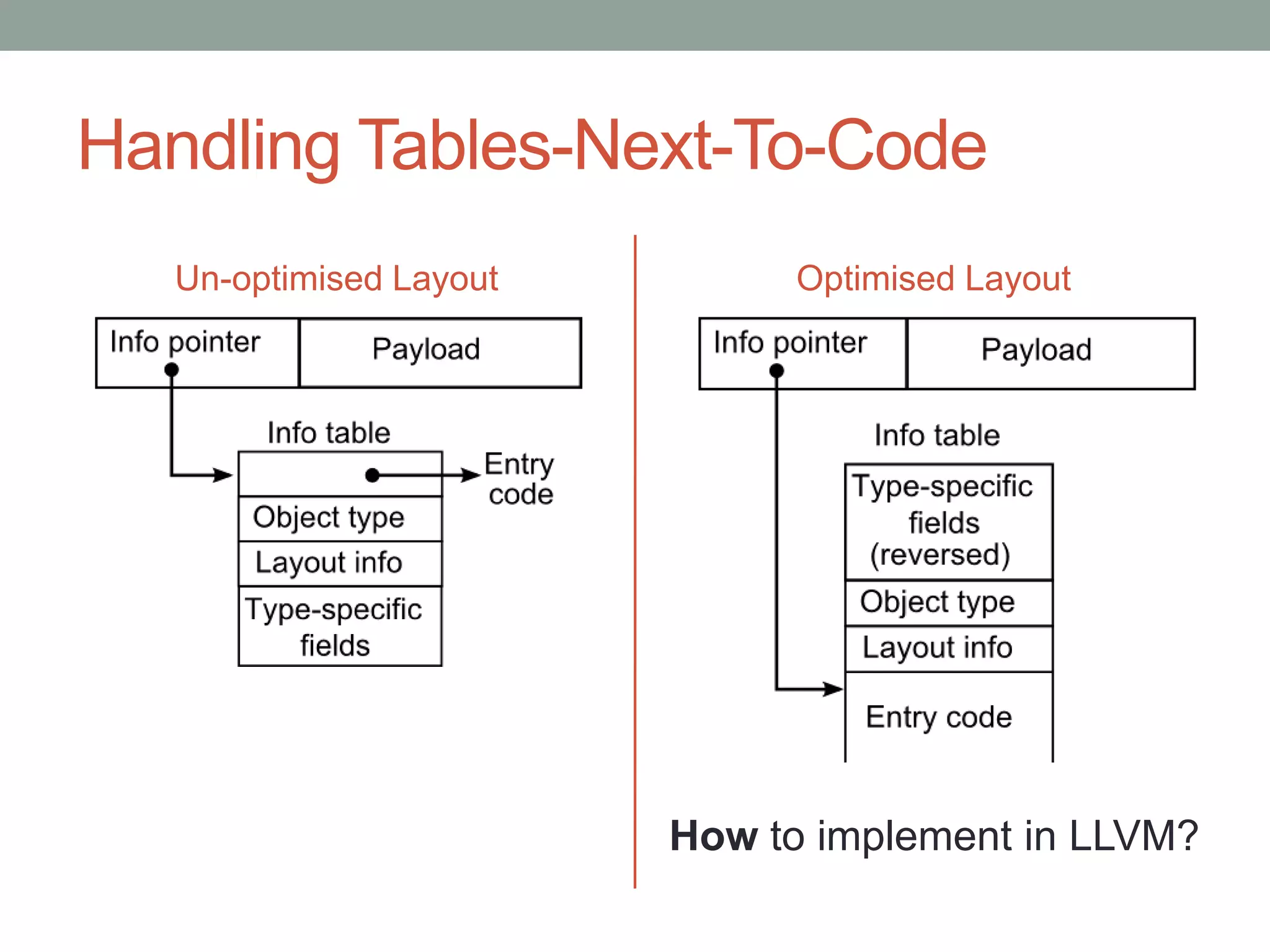
![Handling Tables-Next-To-Code
Use GNU Assembler sub-section feature.
• Allows code/data to be put into numbered sub-section
• Sub-sections are appended together in order
• Table in <n>, entry code in <n+1>
.text 12
sJ8_info:
movl ...
movl ...
jmp ...
[...]
.text 11
sJ8_info_itable:
.long ...
.long 0
.long 327712](https://image.slidesharecdn.com/ghc-llvm-hs10-slides-111018142902-phpapp02/75/Haskell-Symposium-2010-An-LLVM-backend-for-GHC-13-2048.jpg)