Download as PDF, PPTX



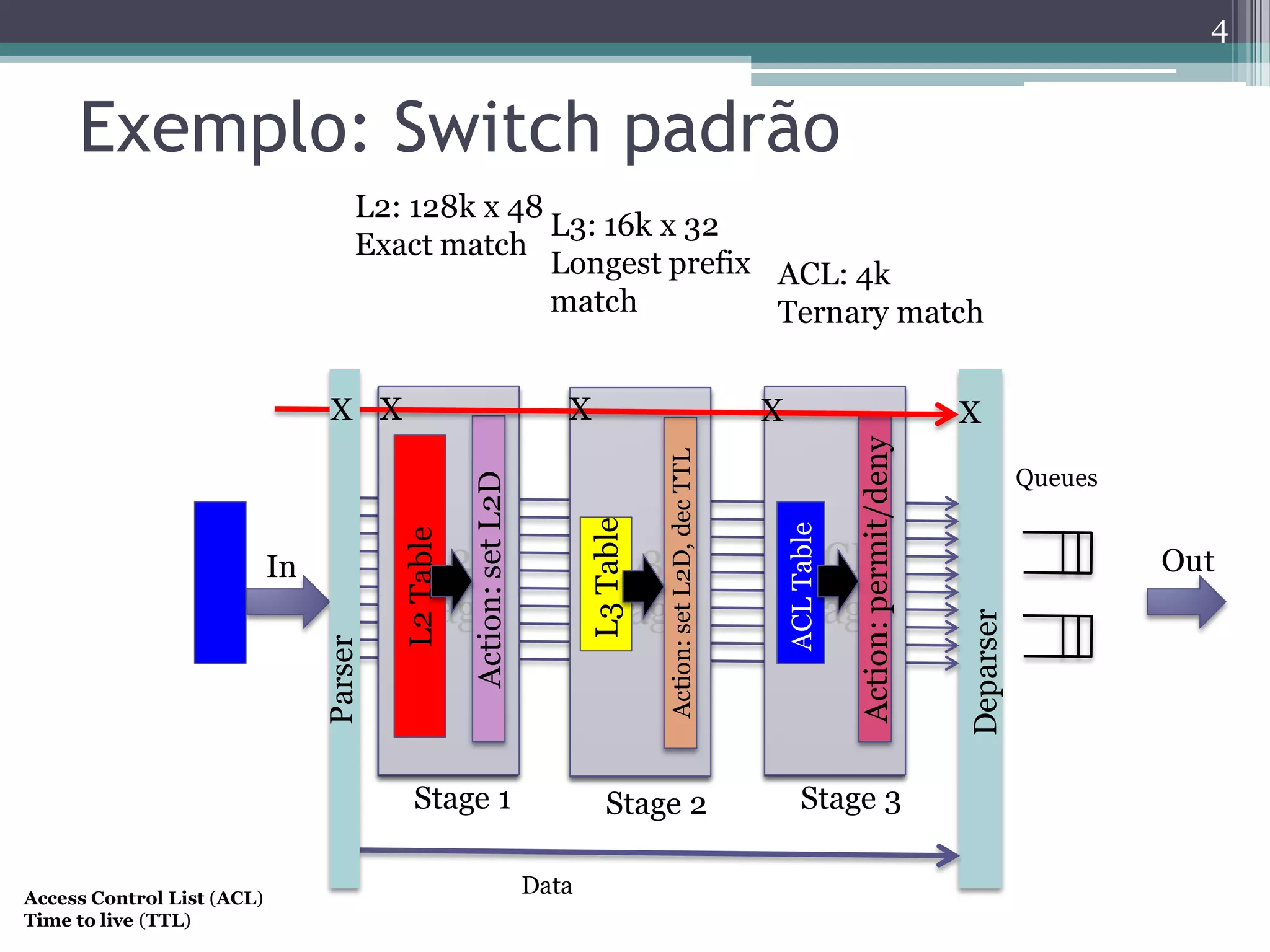






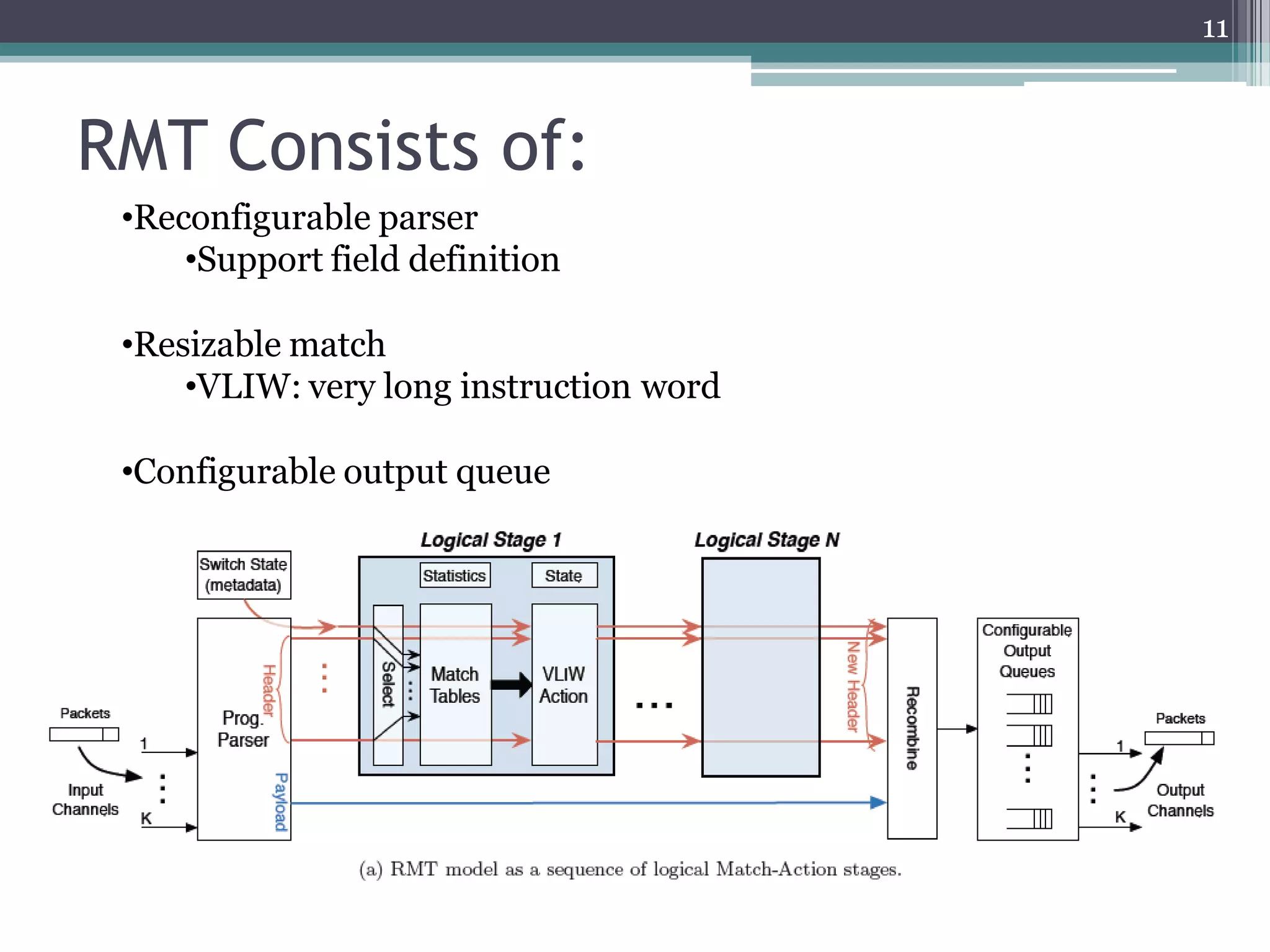
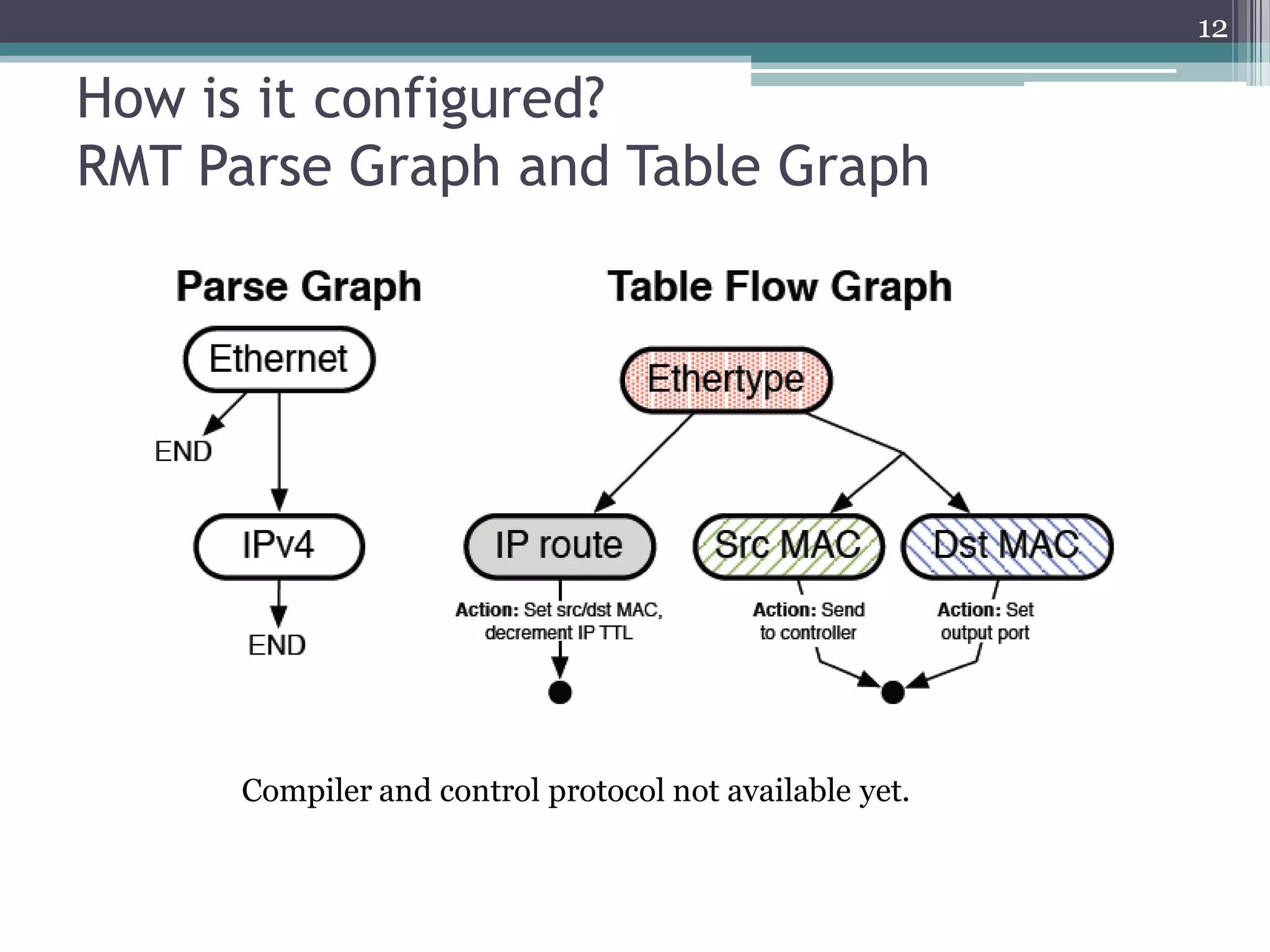

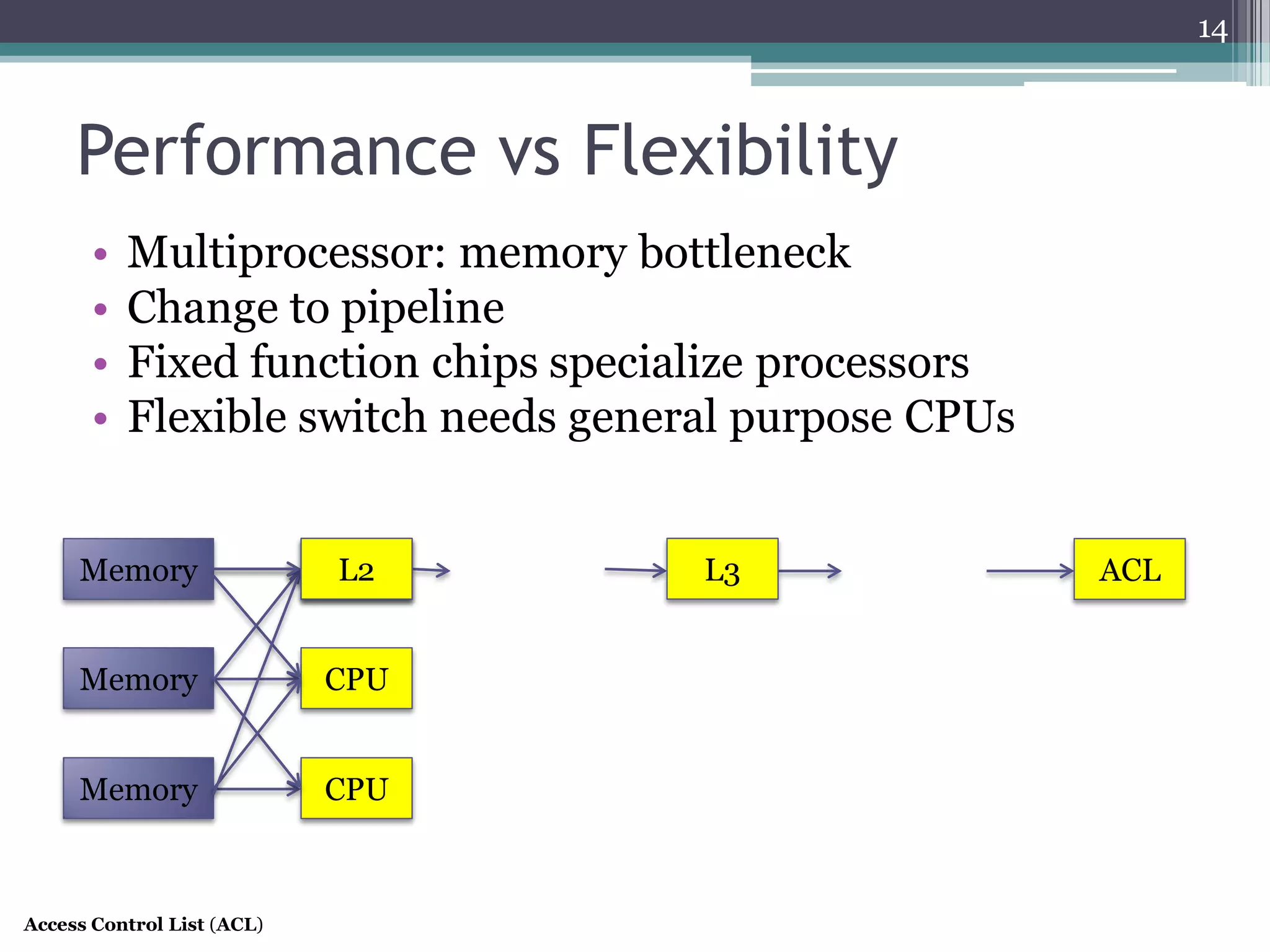


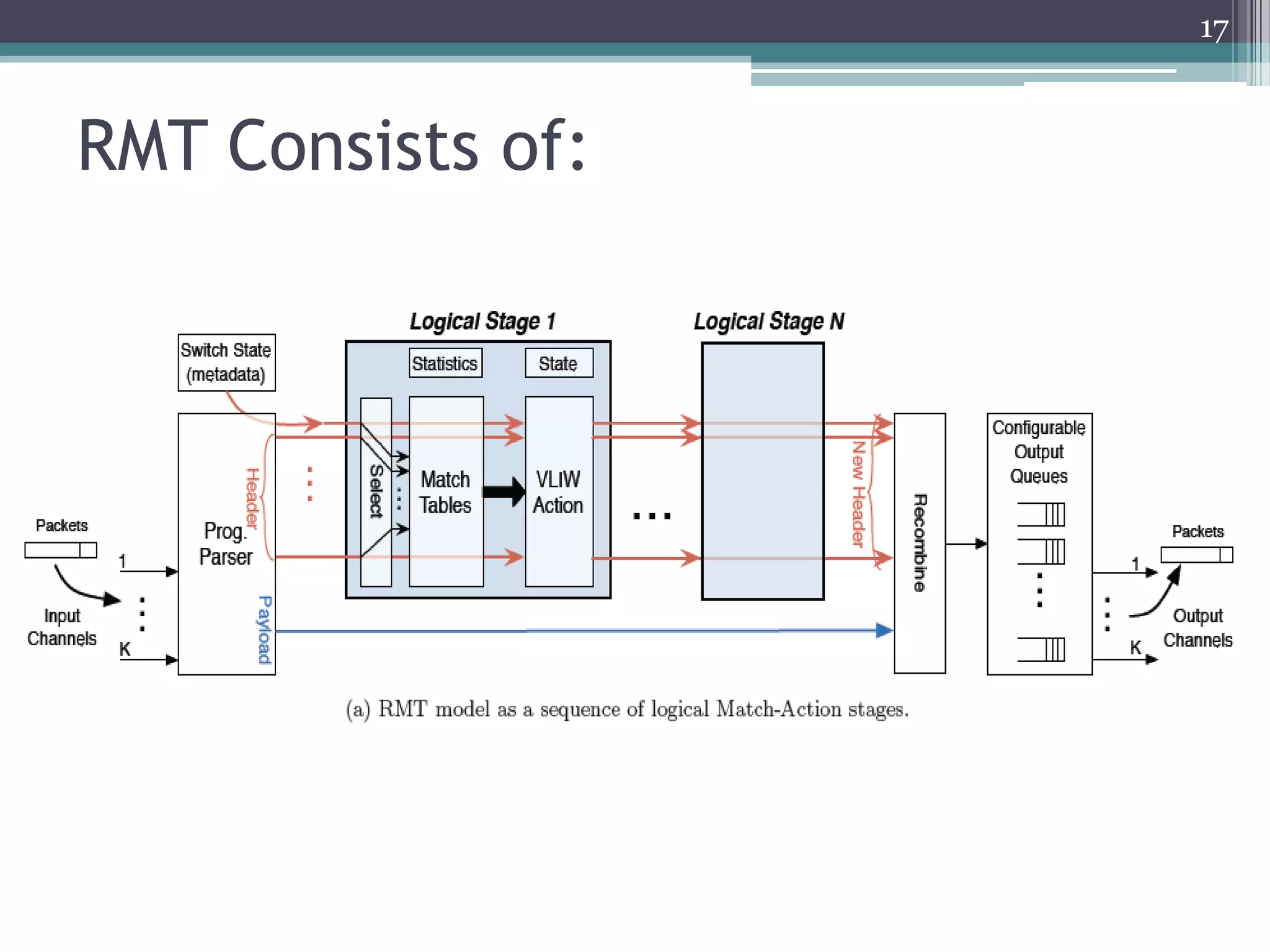
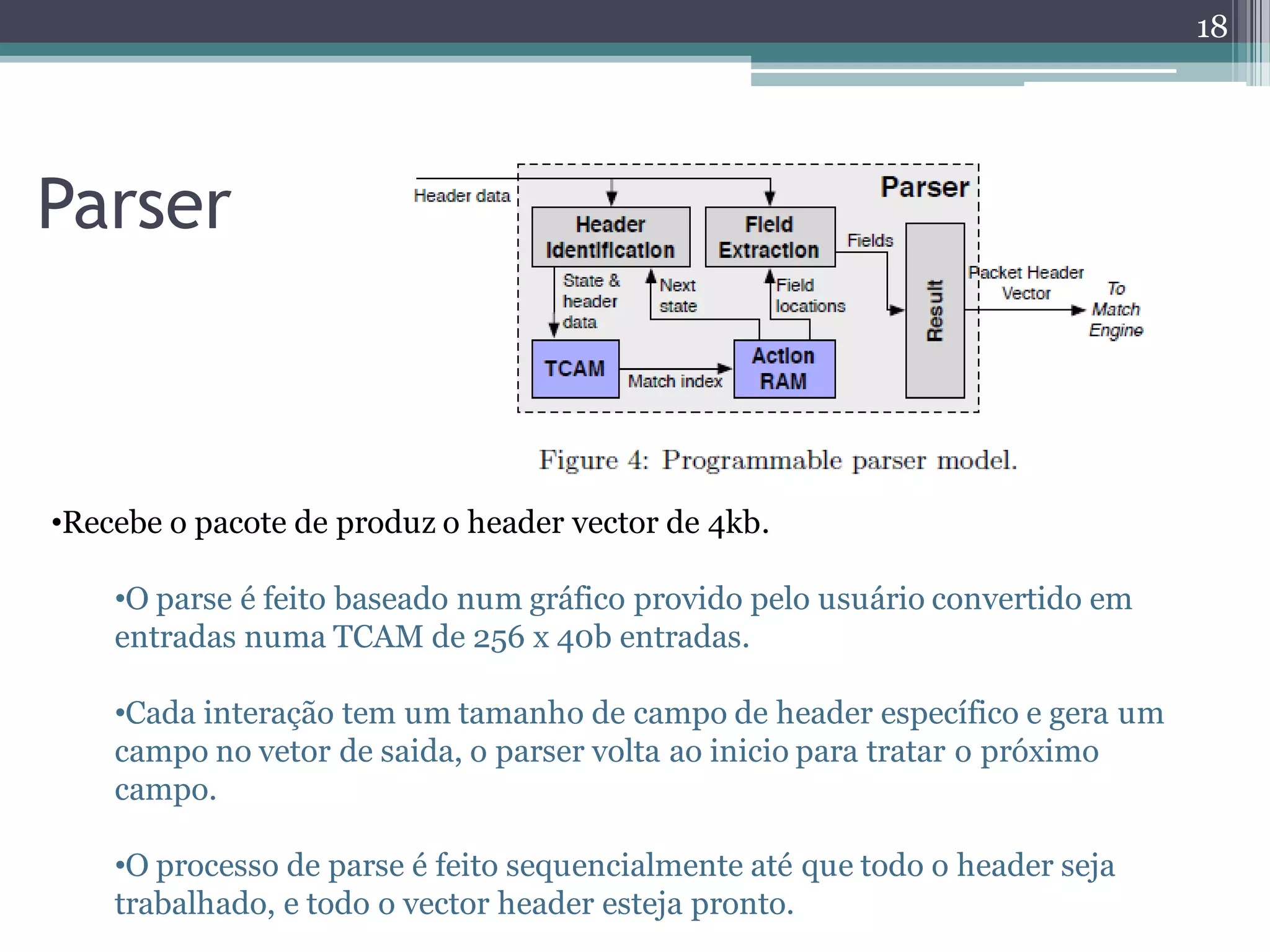
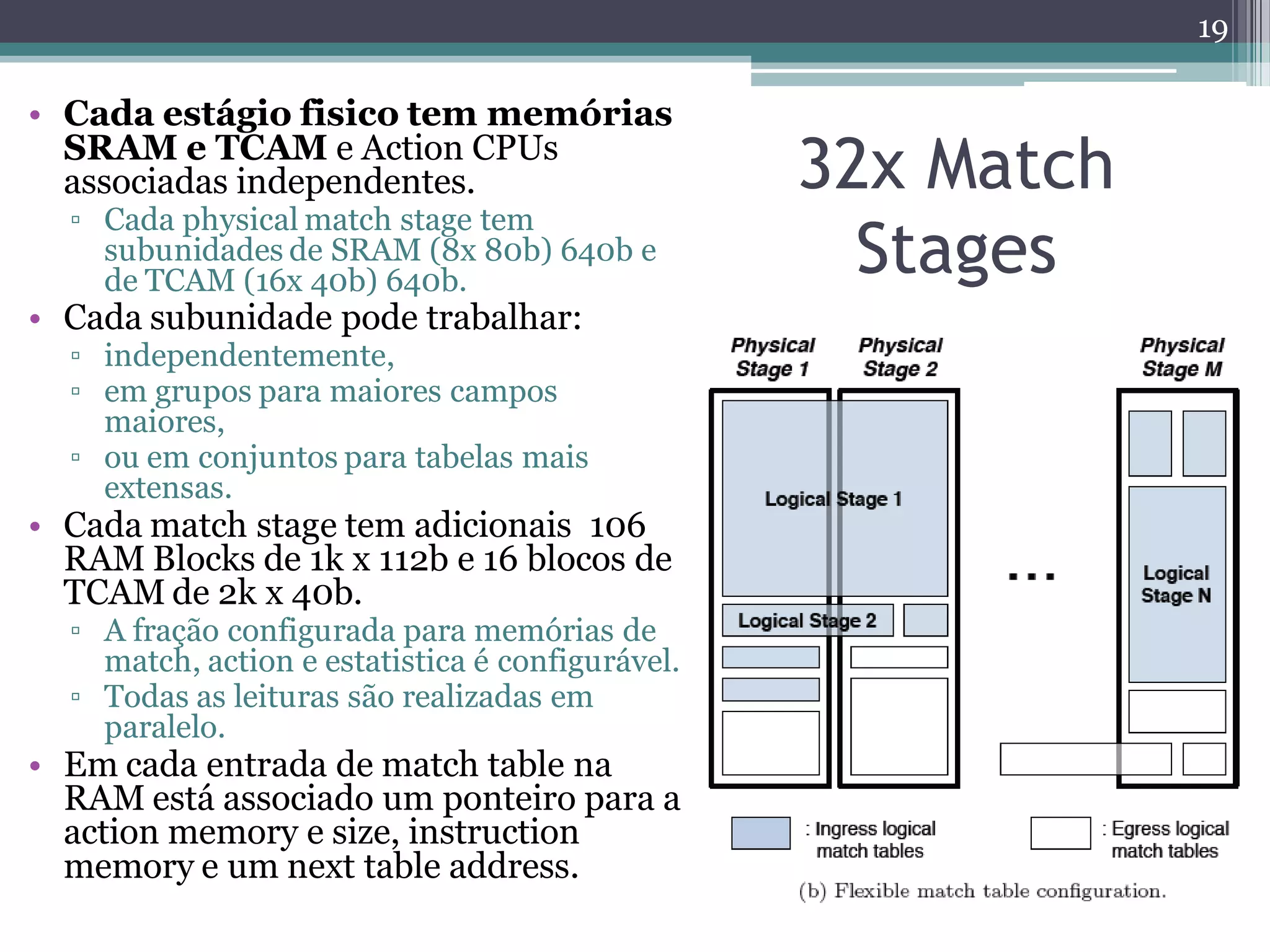
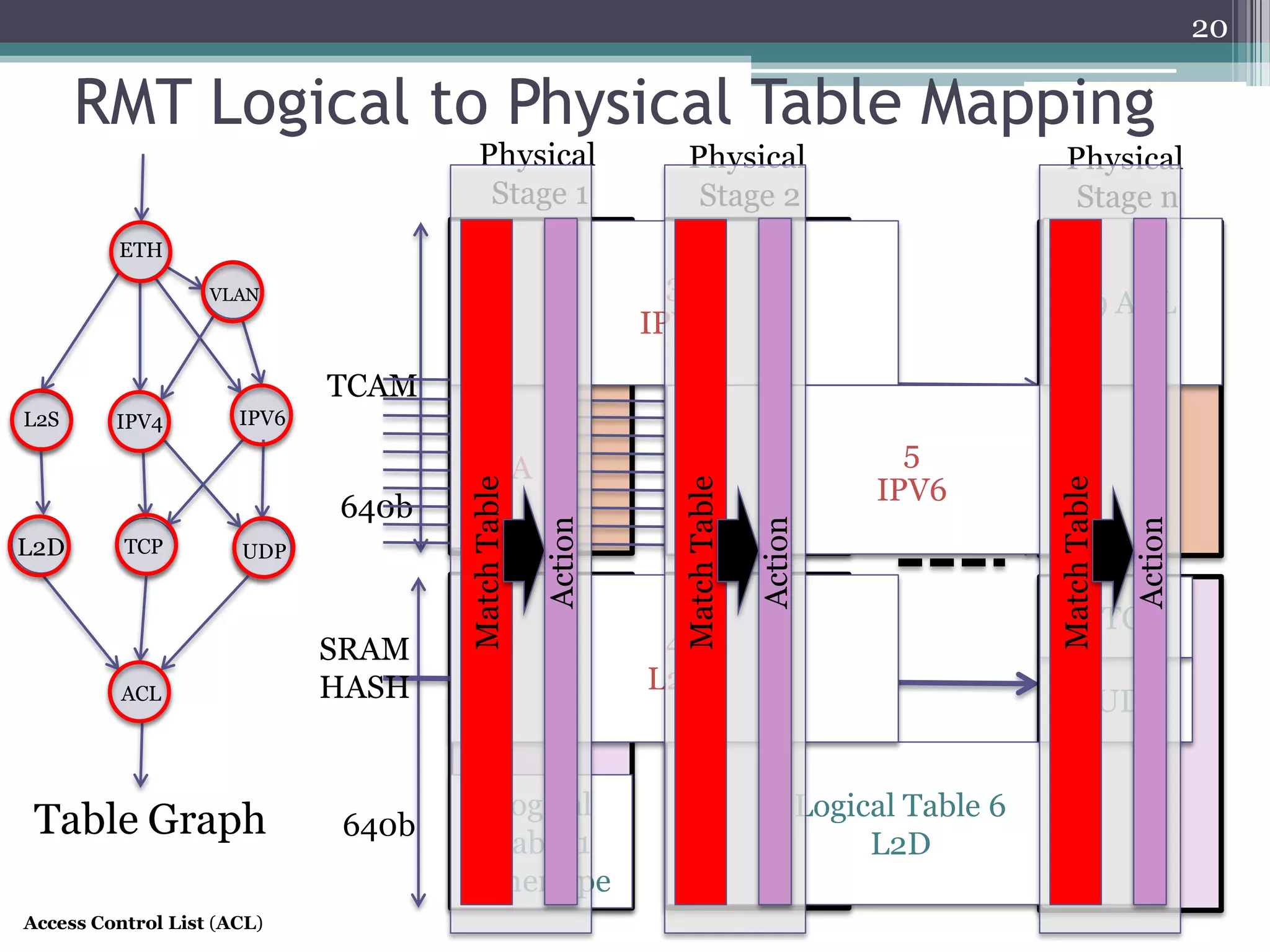
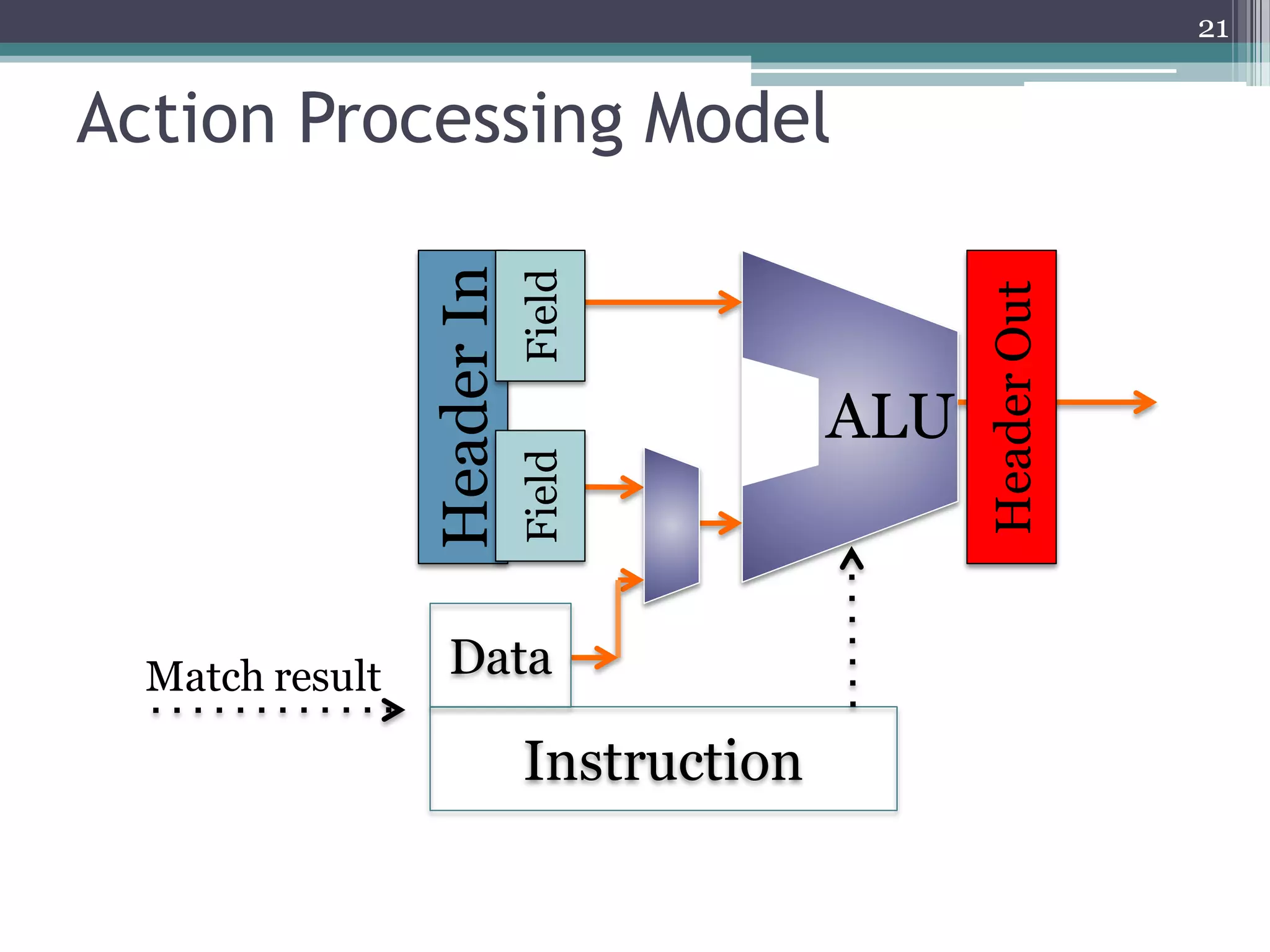
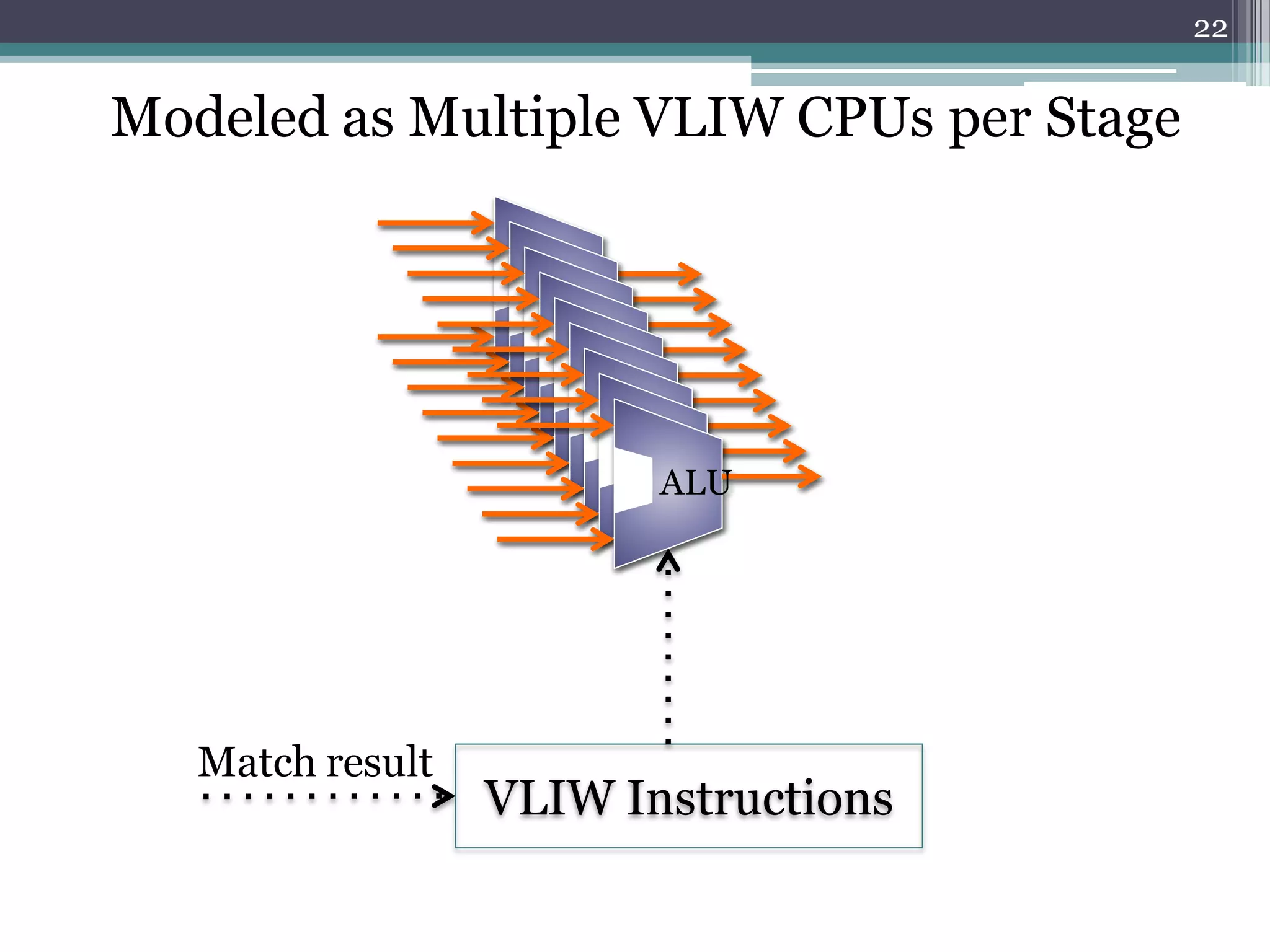


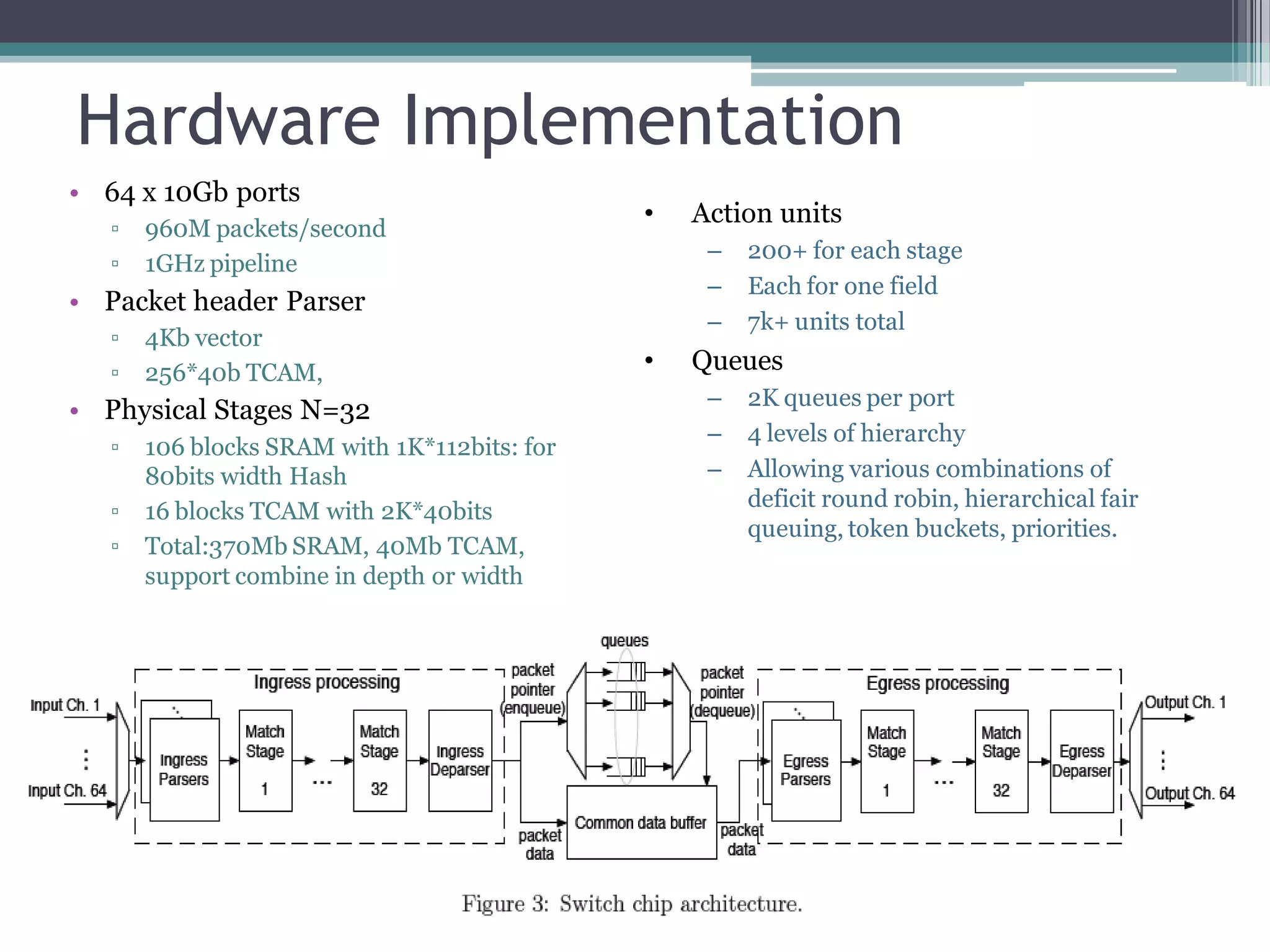

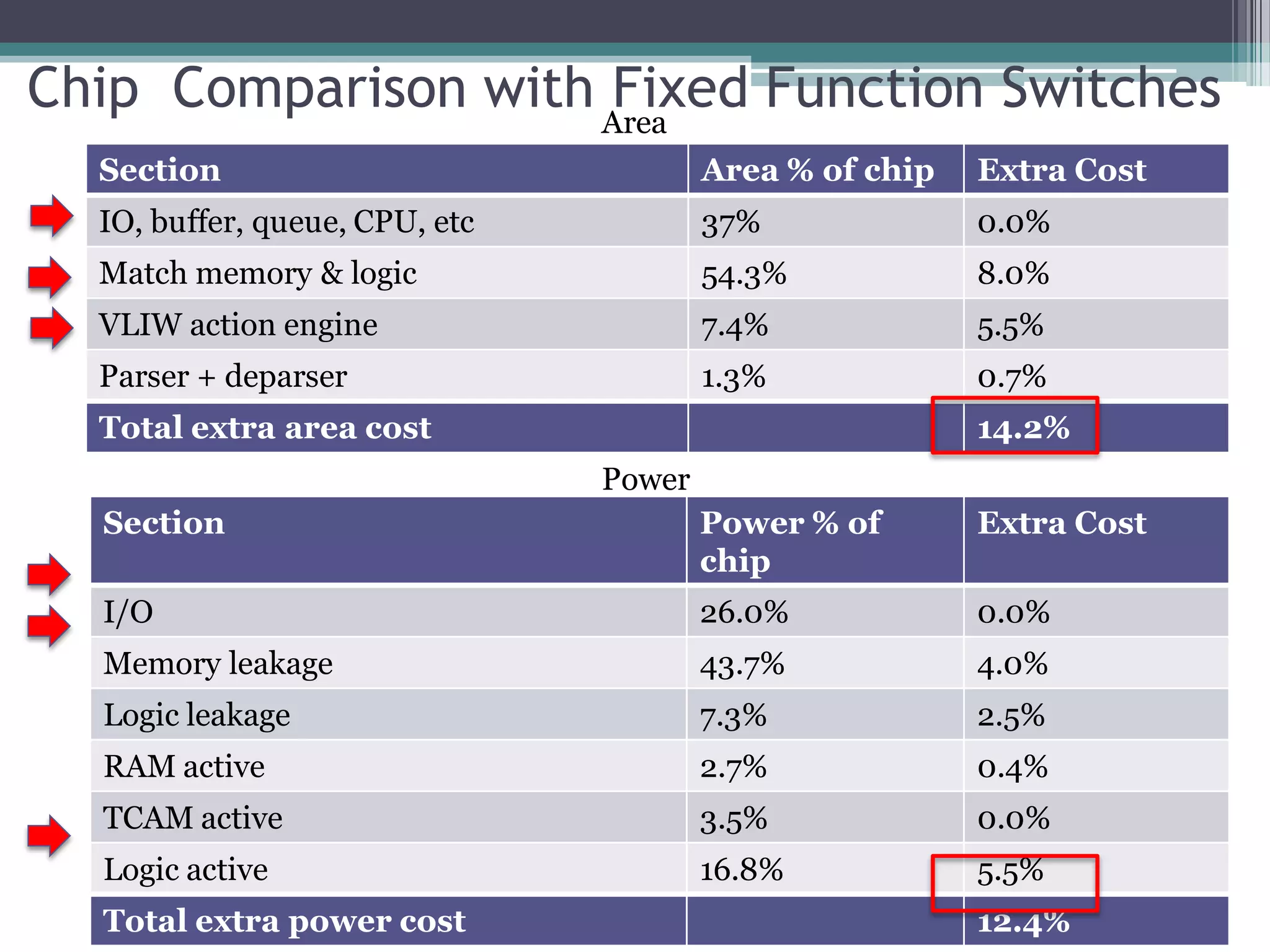


The document discusses the implementation of a 64-port, 10 Gbps switch using the Reconfigurable Match Tables (RMT) model for Software Defined Networking (SDN). It highlights the need for flexibility in hardware switches, detailing the architecture and capabilities of the RMT, which allows modifications to packet processing without changing the hardware. The RMT enables dynamic adjustments to match tables, header fields, and actions, offering a programmable and efficient approach to network data handling.















































