This document discusses gaps between theory and practice in large scale matrix computations for networks. It provides an overview of representing networks as matrices and canonical problems like PageRank that can be modeled as matrix computations. It then discusses different methods for solving these problems, like Monte Carlo methods, relaxation methods, and Krylov subspace methods. It analyzes the computational complexity of these approaches and identifies open problems, such as developing unified convergence results for different algorithms and handling "top k" convergence. The talk concludes by identifying more structured problems on networks that could leverage matrix computations.







![My research!
Models and algorithms for high performance !
A
L
B
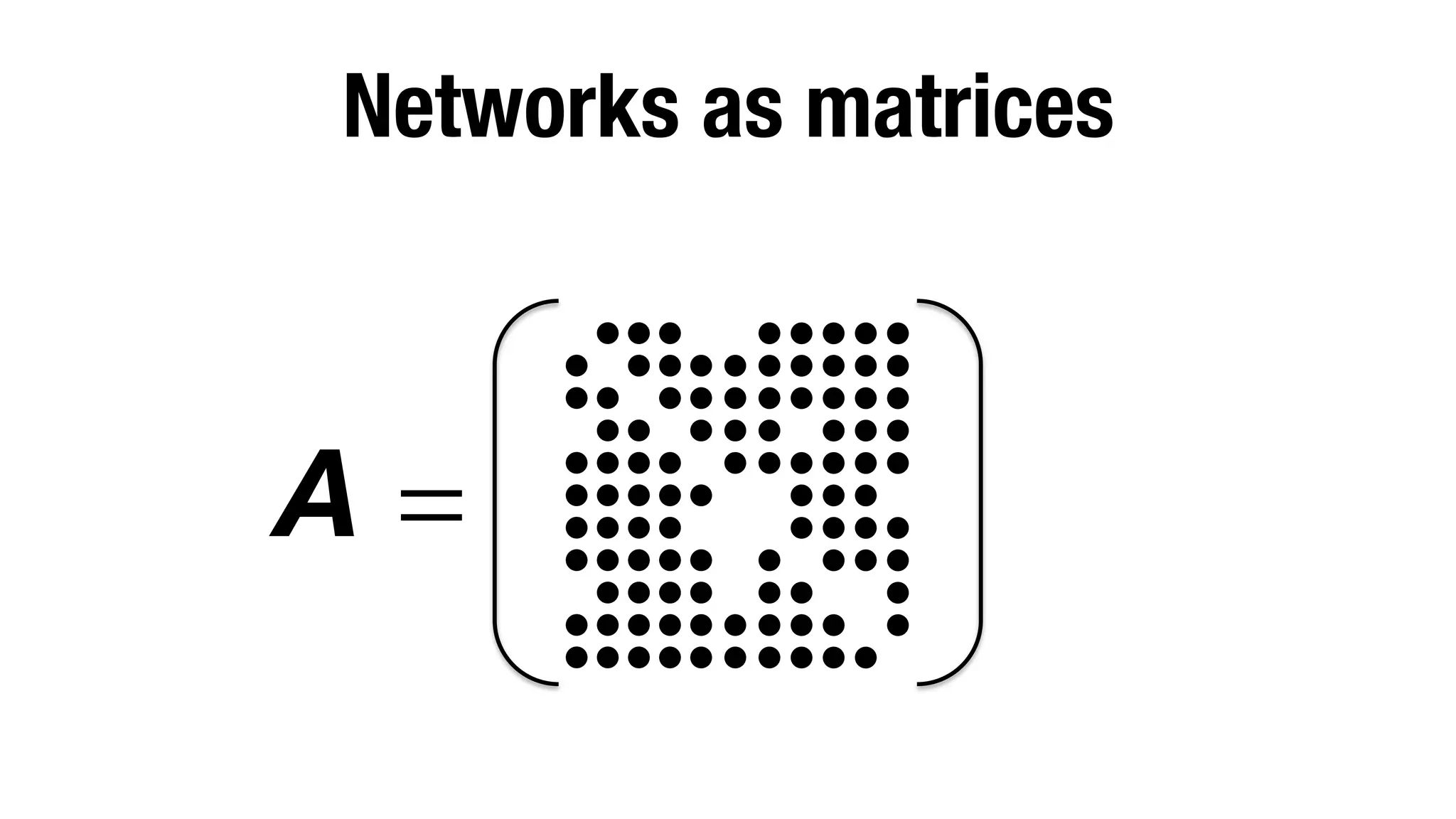
Tensormatrix and network computations on data
eigenvalues"
This proposal is for matchand a power method
ing triangles using
Network alignment
tensor Massive matrix "
CH, Y. HOU, AND J. TEMPLETON
P
methods:
maximize
Tijk xi xj xk
-
j0
Triangle
j
i
k
k
0
i0
std
2
A
L
ijk
computations
subject to kxk2 = 1
AxX b
=
[x(next) ]i = ⇢ · (
j xk
min kAx Tijk xbk+
jk
where ! ensures the 2-norm
Ax = x
SSHOPM method due to "
B
Fast & Scalable"
Network analysis
xi )
Kolda and Mayo
on multi-threaded
IfHuman,proteinsinteraction networks 48,228 and
xi (b) Std,j ,= 0.39 cm xk are
x
and
- indicatorsinteraction networks with triangles
distributed
Yeast protein
257,978
Big tensor T has associated nonzeros
triangles
data methods too
The
~100,000,000,000
architectures
0
0
We work with it implicitly
1
the edges (i, i ), (j, j ), and
8
0](https://image.slidesharecdn.com/gaps-matrix-computations-posted-131121231632-phpapp01/75/Gaps-between-the-theory-and-practice-of-large-scale-matrix-based-network-computations-9-2048.jpg)



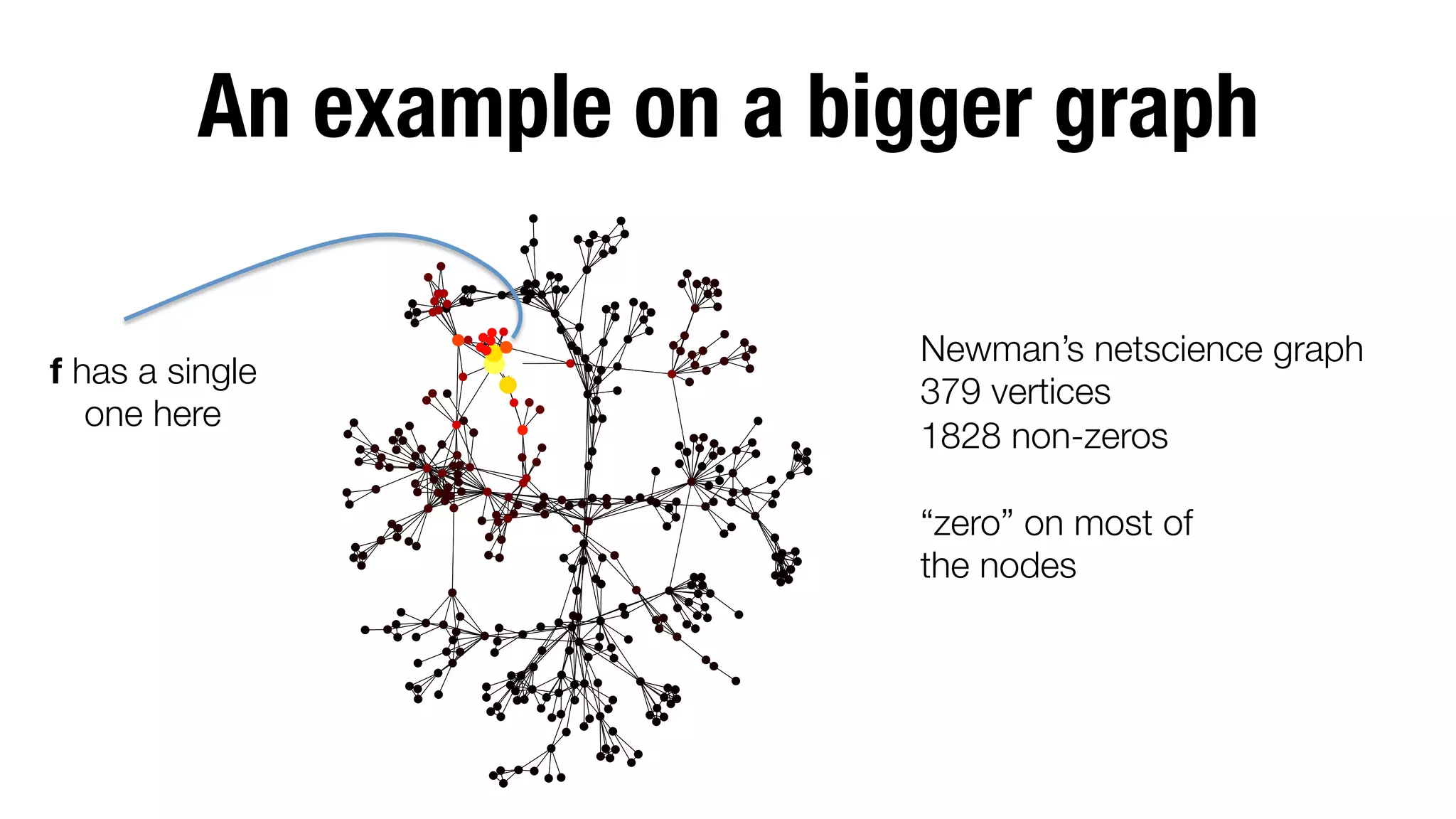




![Gauss-Seidel and Gauss-Southwell
Methods to solve A x = b
Update
x(k+1) = x(k) + ⇢j ej
such that
[Ax(k+1) ]j = [b]j
In words “Relax” or “free” the jth coordinate of your solution vector in
order to satisfy the jth equation of your linear system.
Gauss-Seidel repeatedly cycle through j = 1 to n
Gauss-Southwell use the value of j that has the highest magnitude residual
r(k) = b
Ax(k)](https://image.slidesharecdn.com/gaps-matrix-computations-posted-131121231632-phpapp01/75/Gaps-between-the-theory-and-practice-of-large-scale-matrix-based-network-computations-19-2048.jpg)


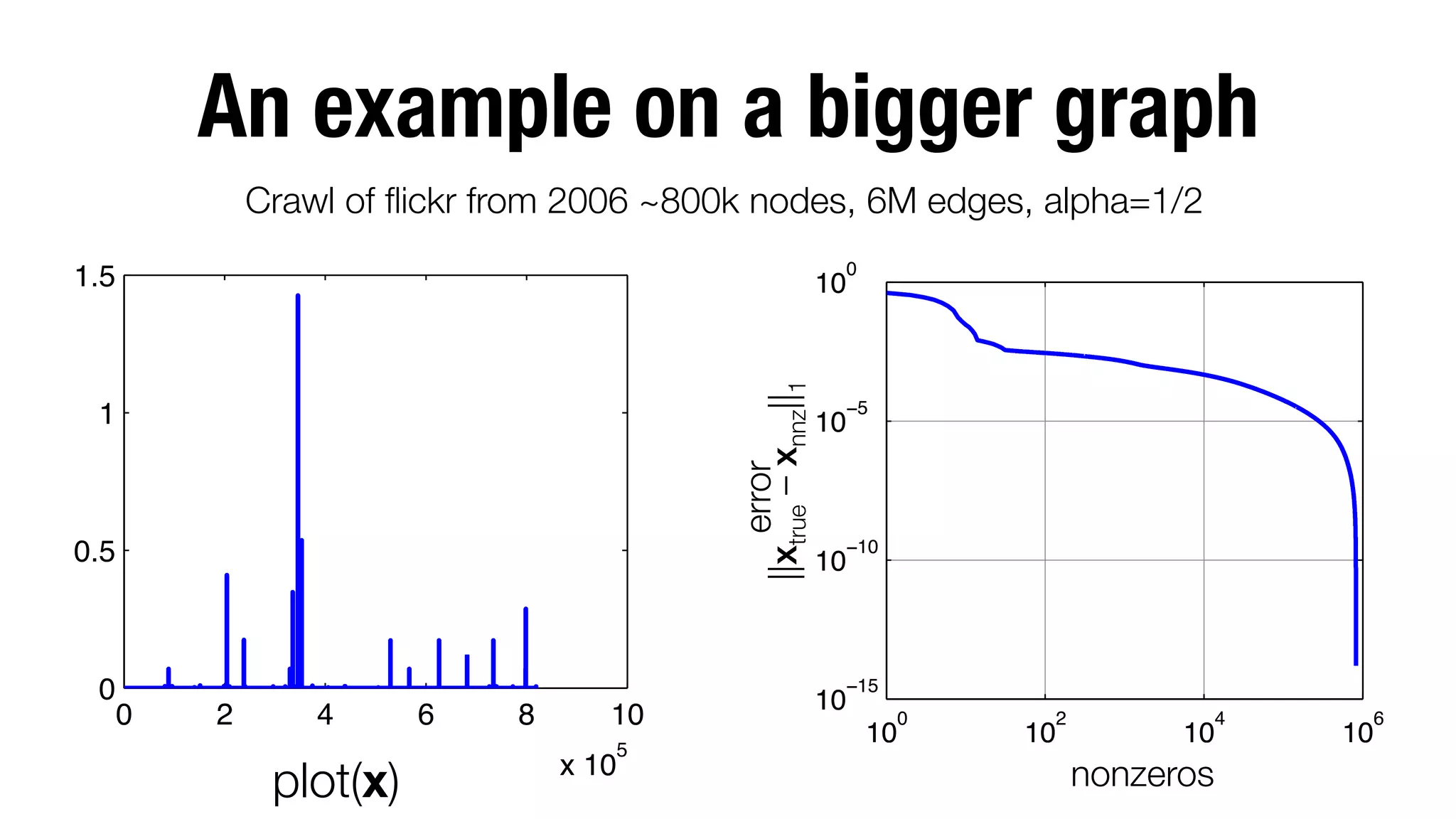
![Python code for PPR Push
# main loop!
while sumr > eps/(1-alpha):!
j = max(r.iteritems, !
key=(lambda x: r[x])!
rj = r[j]!
x[j] += rj!
r[j] = 0!
sumr -= rj!
deg = len(graph[j])!
for i in graph[j]:!
if i not in r: r[i] = 0.!
r[j] += alpha/deg*rj!
sumr += alpha/deg*rj!
# initialization !
# graph is a set of sets!
# eps is stopping tol!
# 0 < alpha < 1!
x = dict()!
r = dict()!
sumr = 0.!
for (node,fi) in f.items():!
r[node] = fi!
sumr += fi!
!
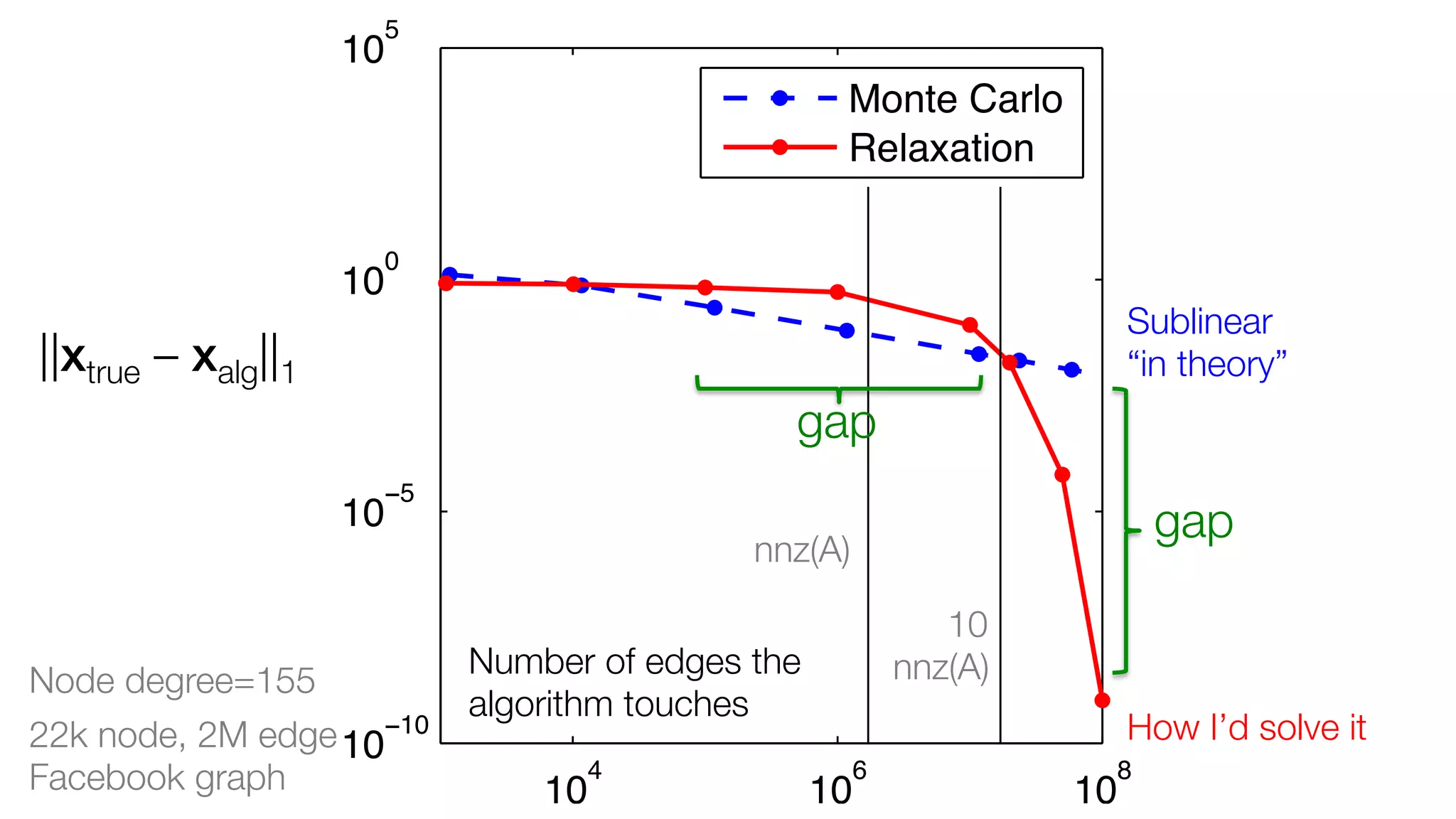
If f ≥ 0, this terminates when ||xtrue – xalg||1 <](https://image.slidesharecdn.com/gaps-matrix-computations-posted-131121231632-phpapp01/75/Gaps-between-the-theory-and-practice-of-large-scale-matrix-based-network-computations-22-2048.jpg)