
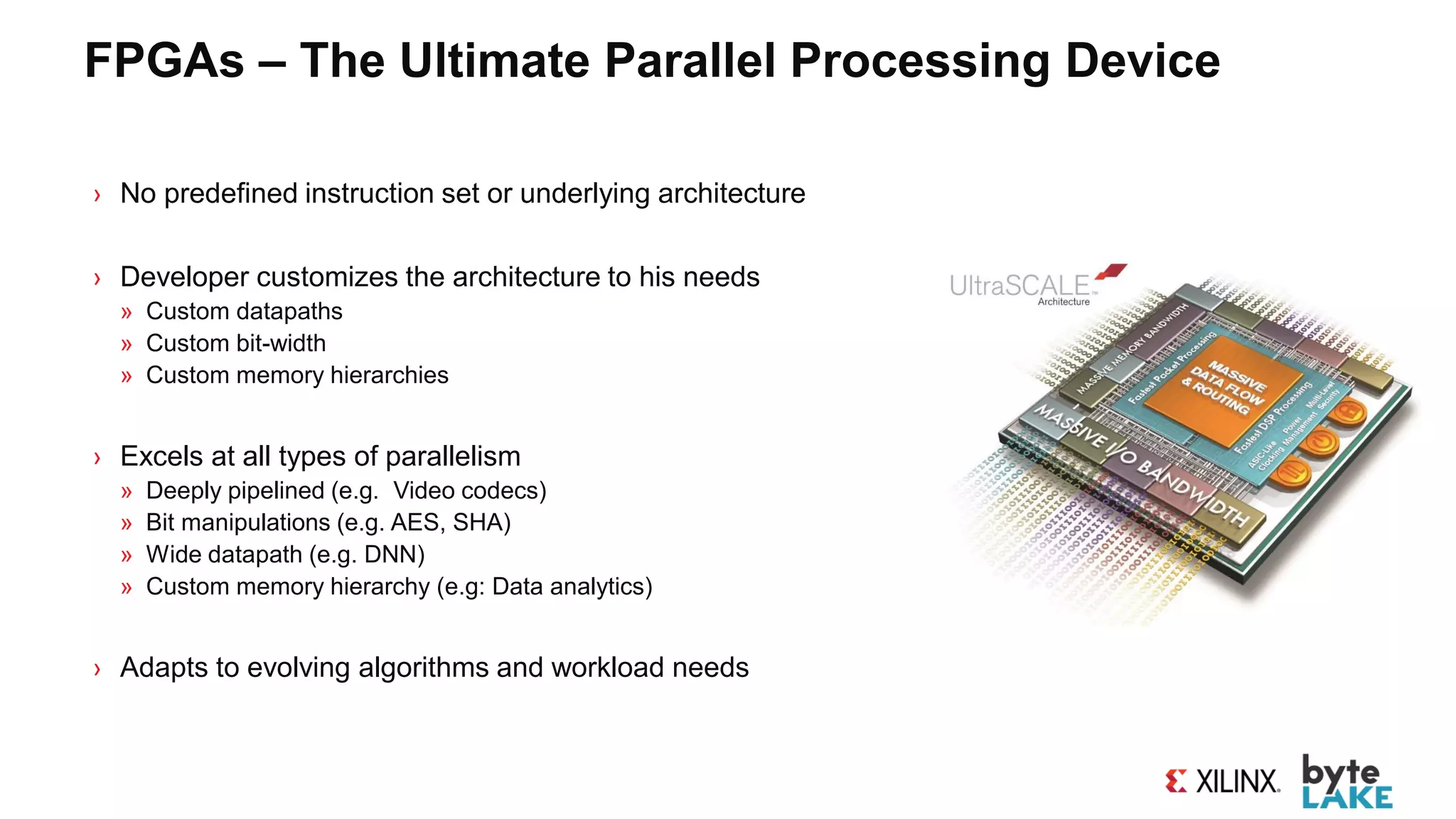

![Using C, C++ or OpenCL to Program FPGAs
› Xilinx pioneered C to FPGA compilation technology (aka “HLS”) in 2011
› Enables “Software Programmability” of FPGAs
› Includes open source collection of optimized HLS libraries
loop_main:for(int j=0;j<NUM_SIMGROUPS;j+=2) {
loop_share:for(uint k=0;k<NUM_SIMS;k++) {
loop_parallel:for(int i=0;i<NUM_RNGS;i++) {
mt_rng[i].BOX_MULLER(&num1[i][k],&num2[i][k],ratio4,ratio3);
float payoff1 = expf(num1[i][k])-1.0f;
float payoff2 = expf(num2[i][k])-1.0f;
if(num1[i][k]>0.0f)
pCall1[i][k]+= payoff1;
else
pPut1[i][k]-=payoff1;
if(num2[i][k]>0.0f)
pCall2[i][k]+=payoff2;
else
pPut2[i][k]-=payoff2;
}
}
}
FPGACompile](https://image.slidesharecdn.com/bytelakexilinxcfd-optimized-for-alveosc19wsv7-191203102626/75/CFD-Acceleration-with-FPGA-byteLAKE-s-Xilinx-s-presentation-from-H2RC-workshop-SC19-4-2048.jpg)
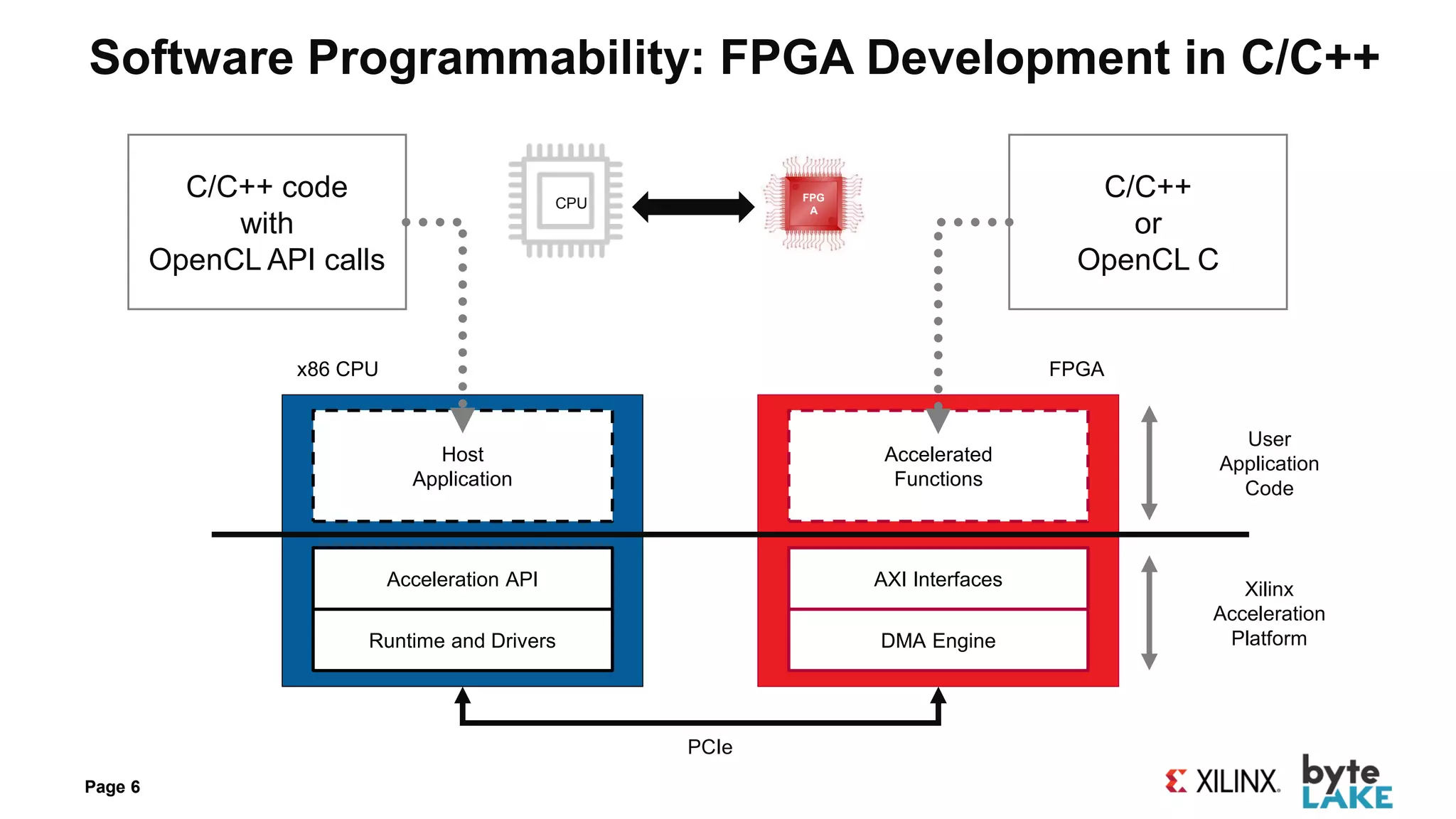

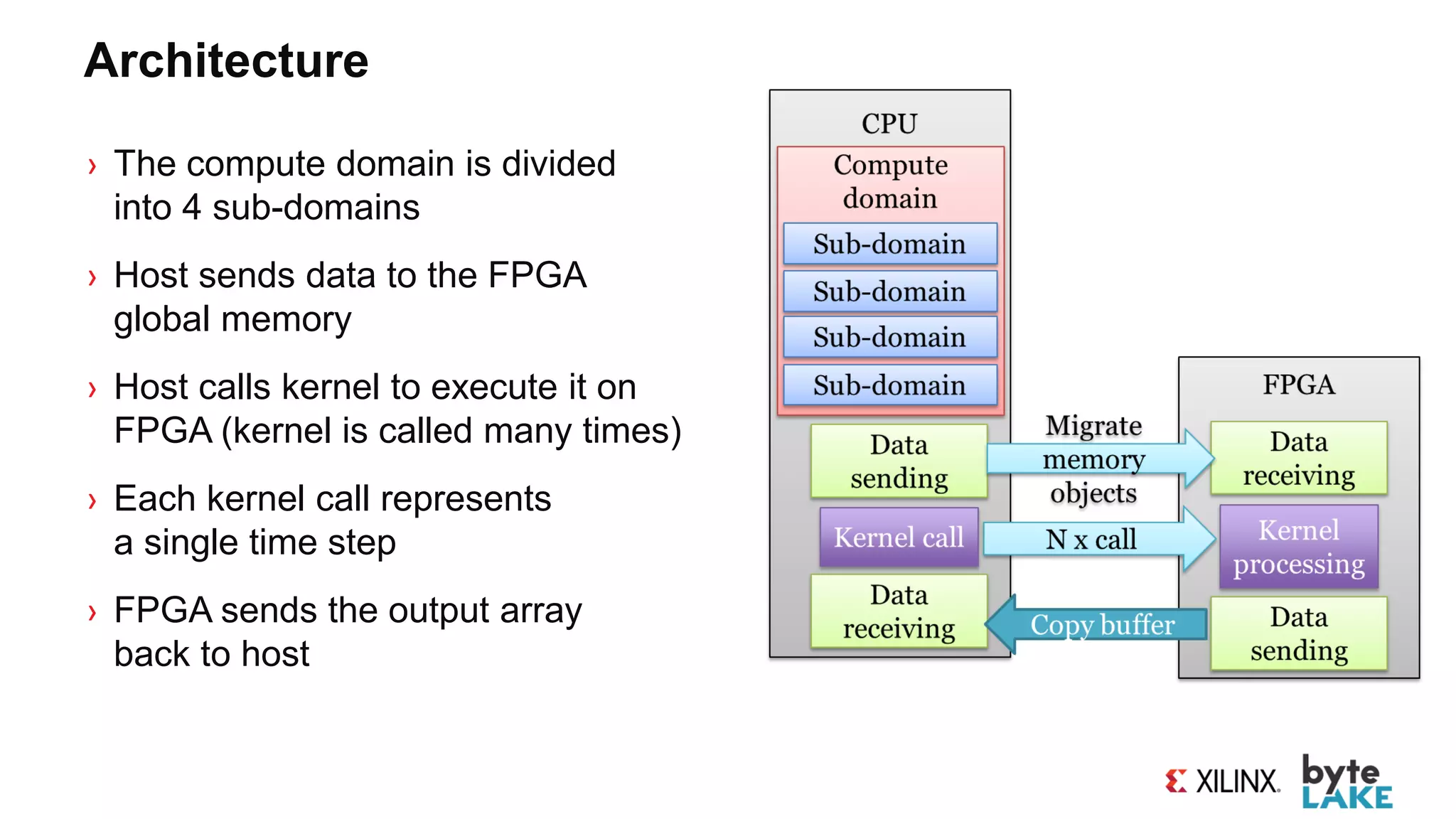
![Alveo Optimizations
5774.60
4597.60 4572.00
1179.00
673.10 575.70 483.60 342.90 23.80 9.96
Execution time [s]](https://image.slidesharecdn.com/bytelakexilinxcfd-optimized-for-alveosc19wsv7-191203102626/75/CFD-Acceleration-with-FPGA-byteLAKE-s-Xilinx-s-presentation-from-H2RC-workshop-SC19-8-2048.jpg)
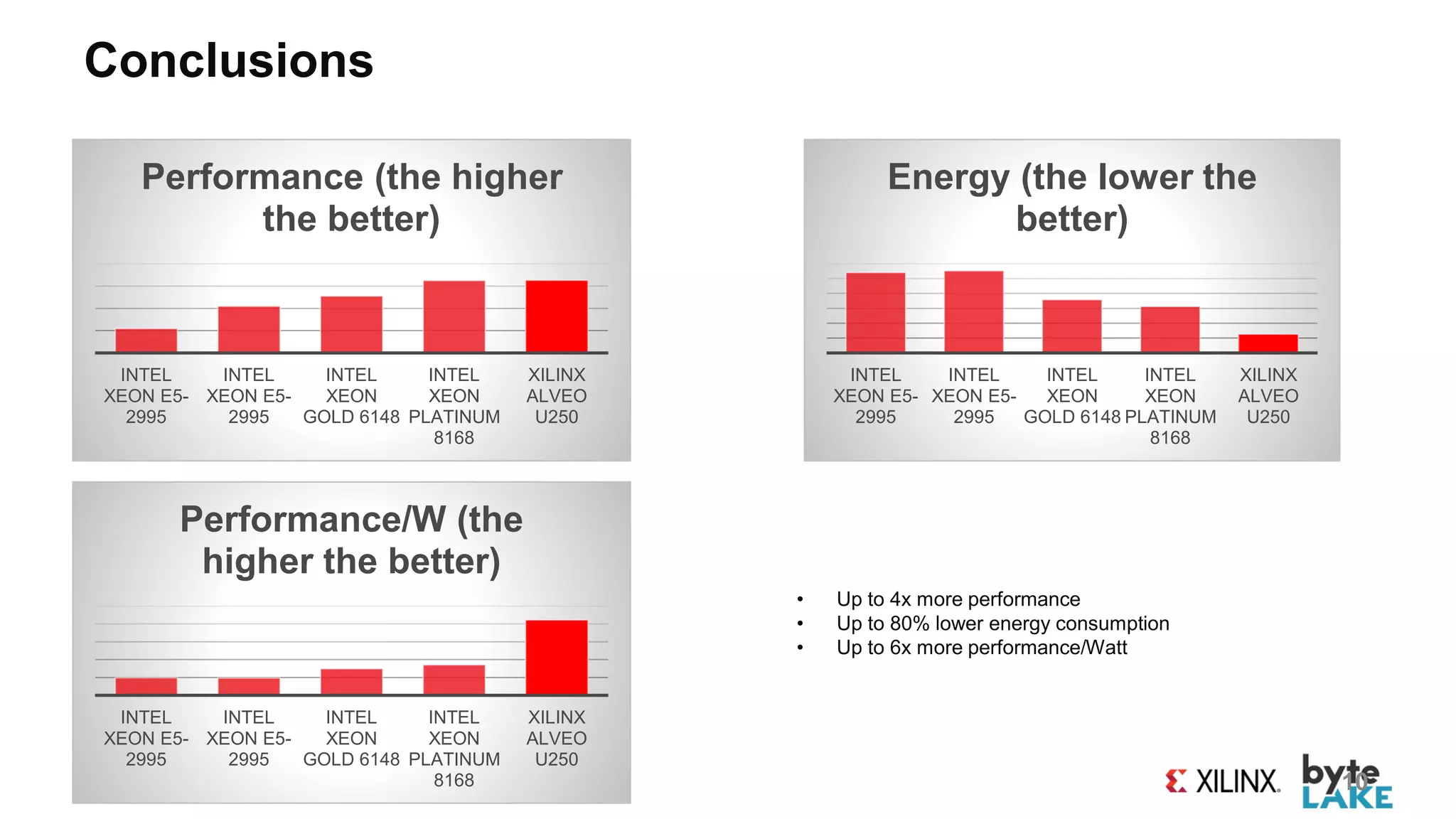





The document discusses ByteLake's CFD suite leveraging FPGA technology for computational fluid dynamics, emphasizing its customization and efficiency benefits through parallel processing. It highlights the Vitis development environment that enables software programmability of FPGAs and presents performance comparisons with Intel Xeon processors, showcasing up to 4x performance improvements and up to 80% energy savings. The roadmap includes AI-driven microservices for various industries such as automotive, construction, and oil & gas.























































































