Download as PDF, PPTX

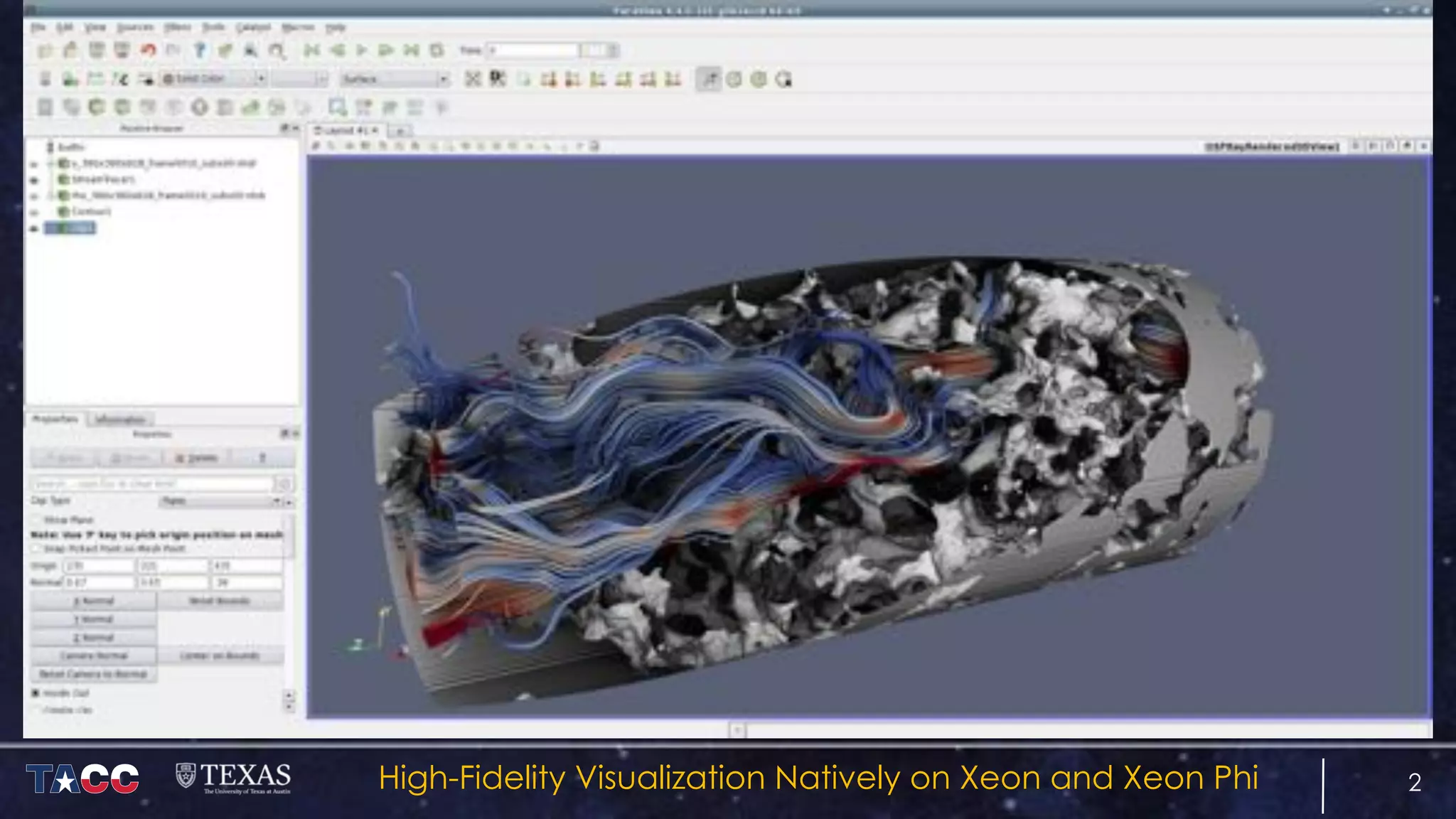




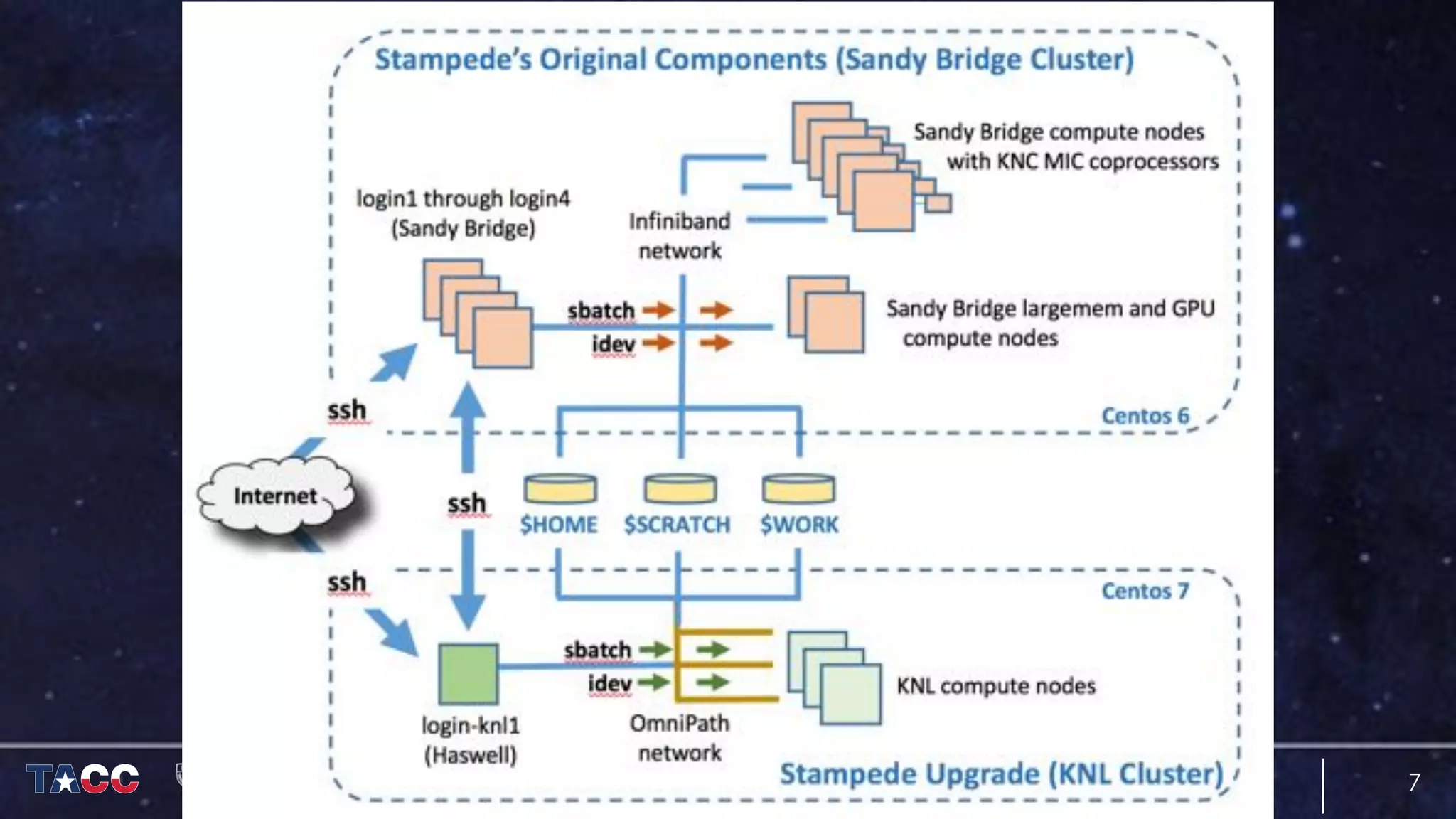


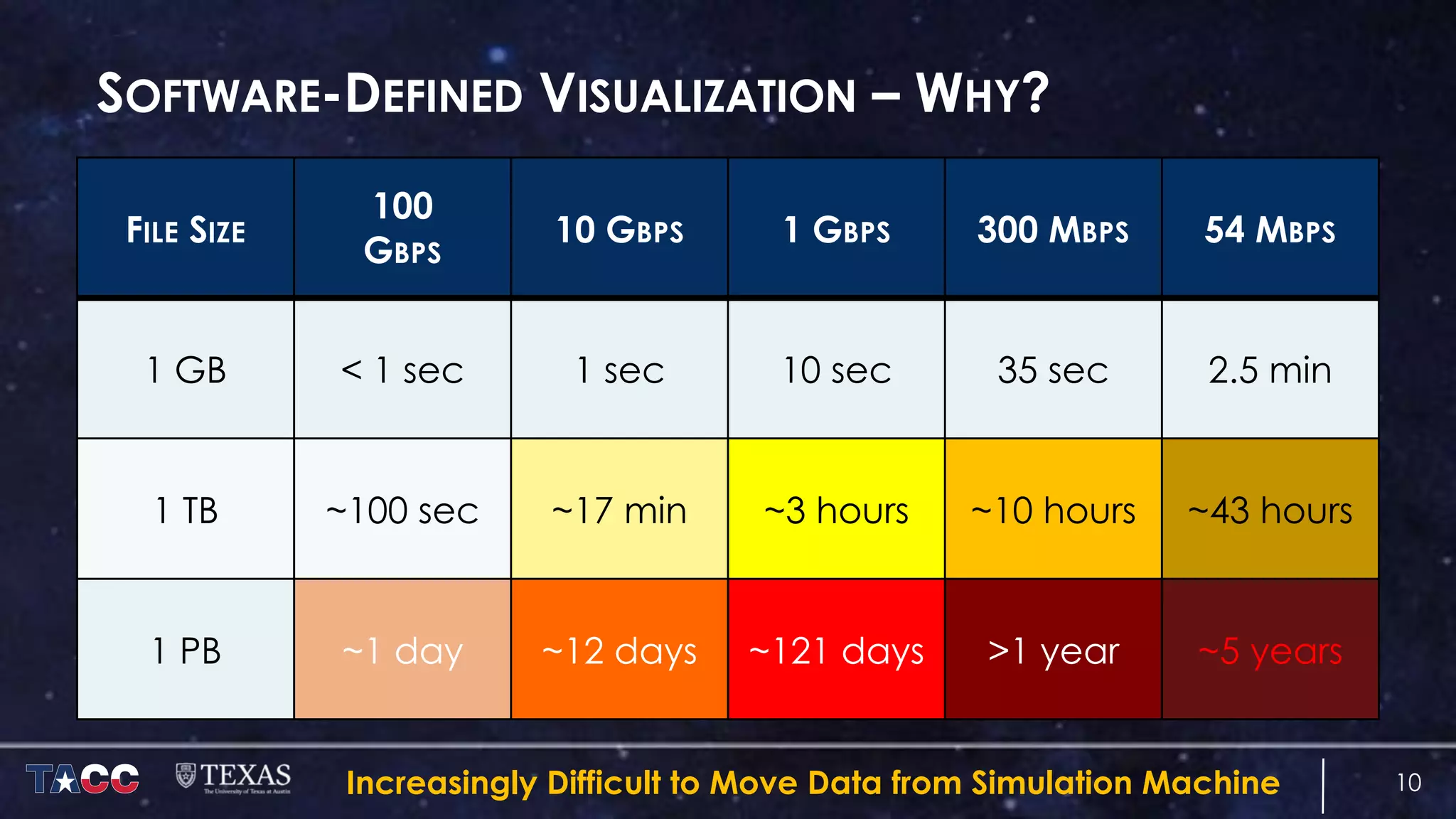
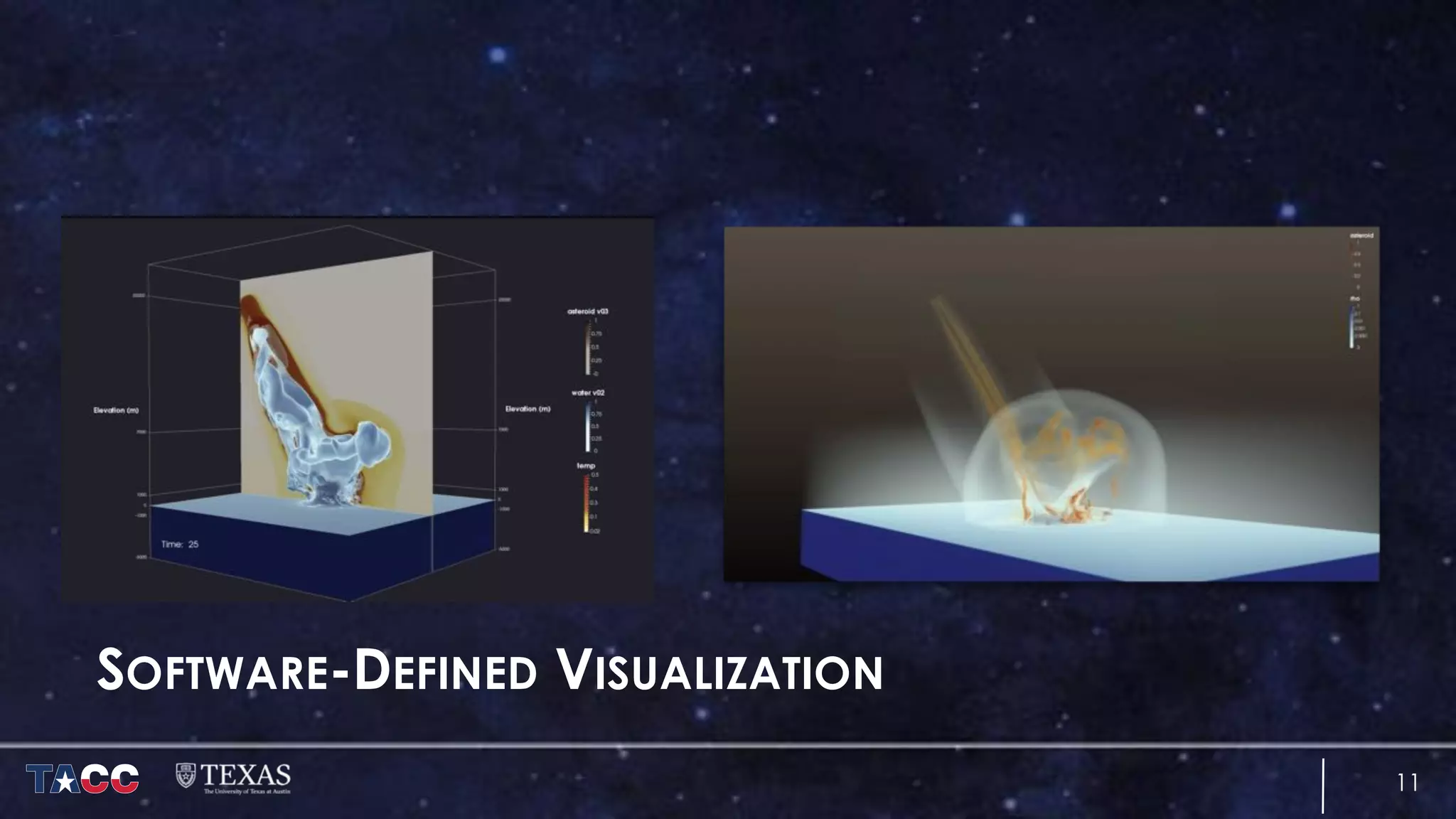

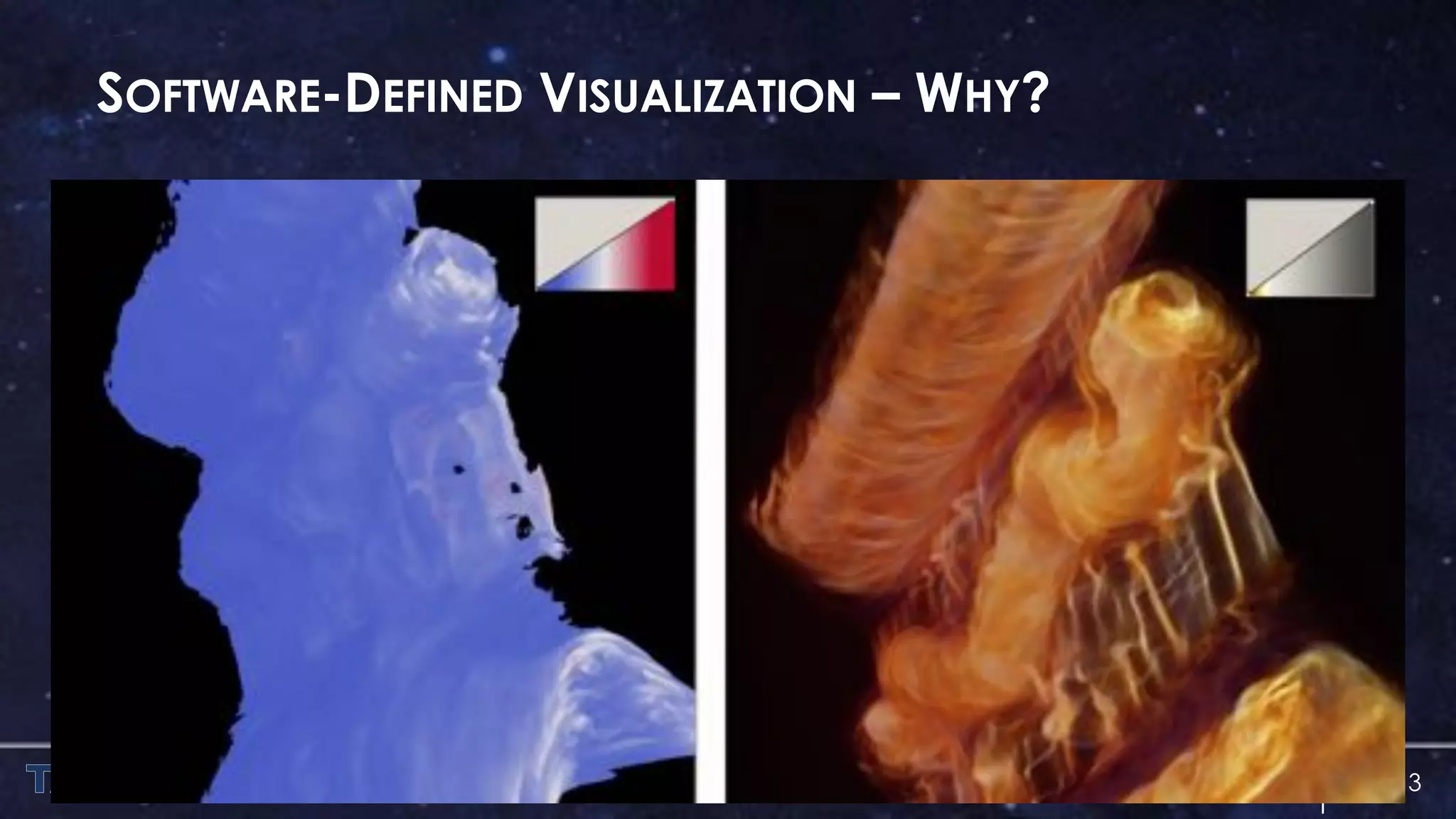
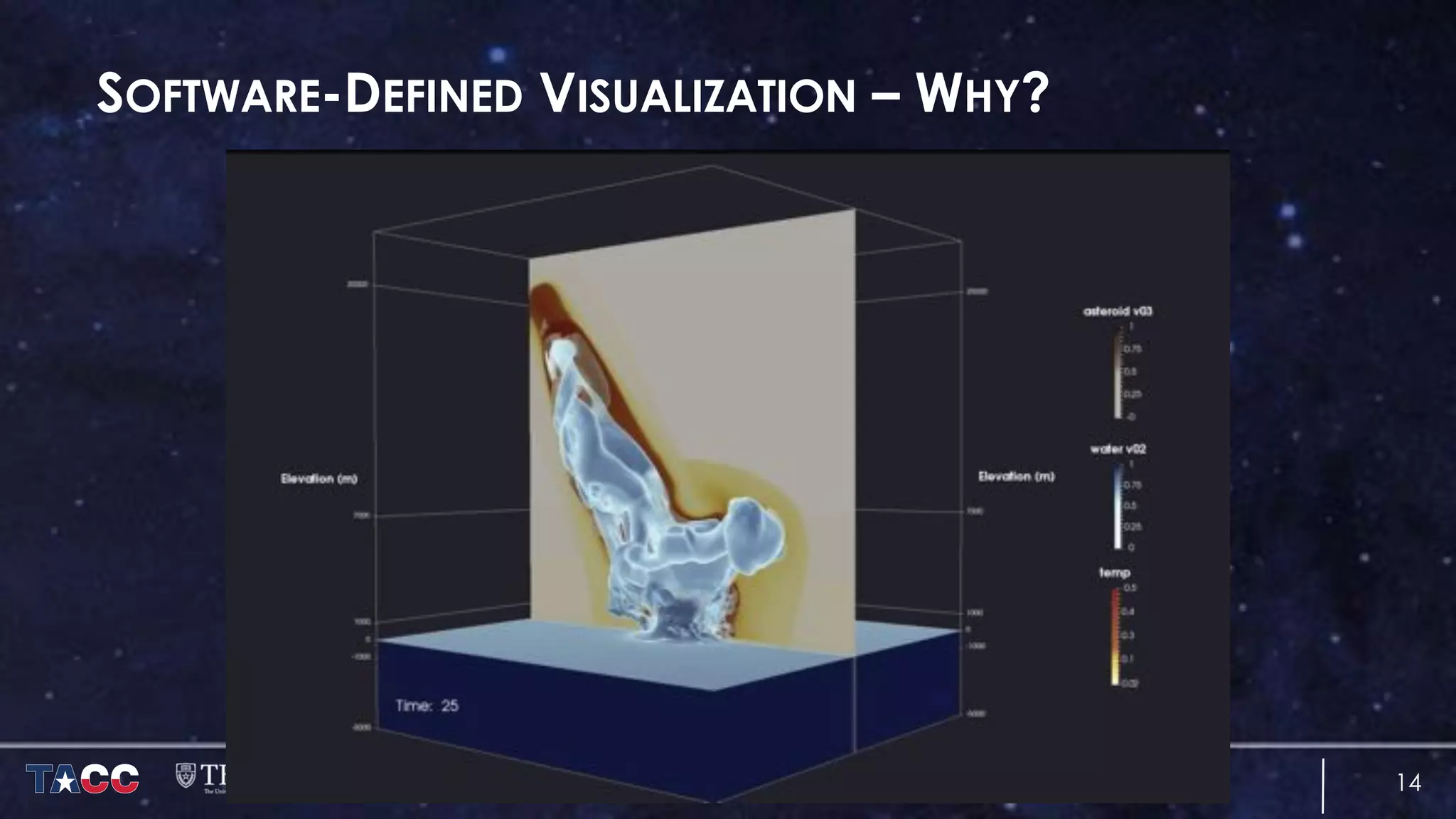





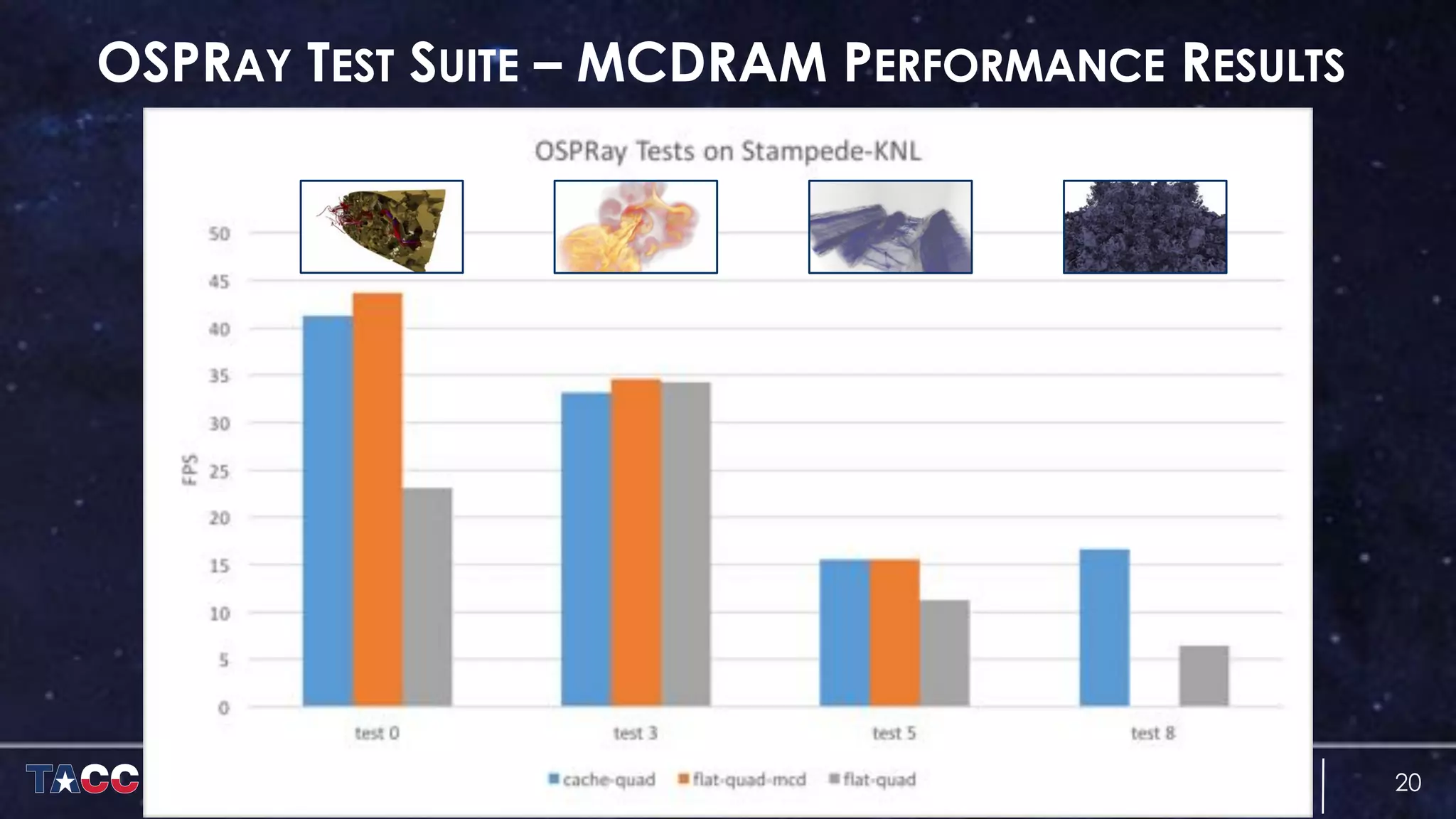

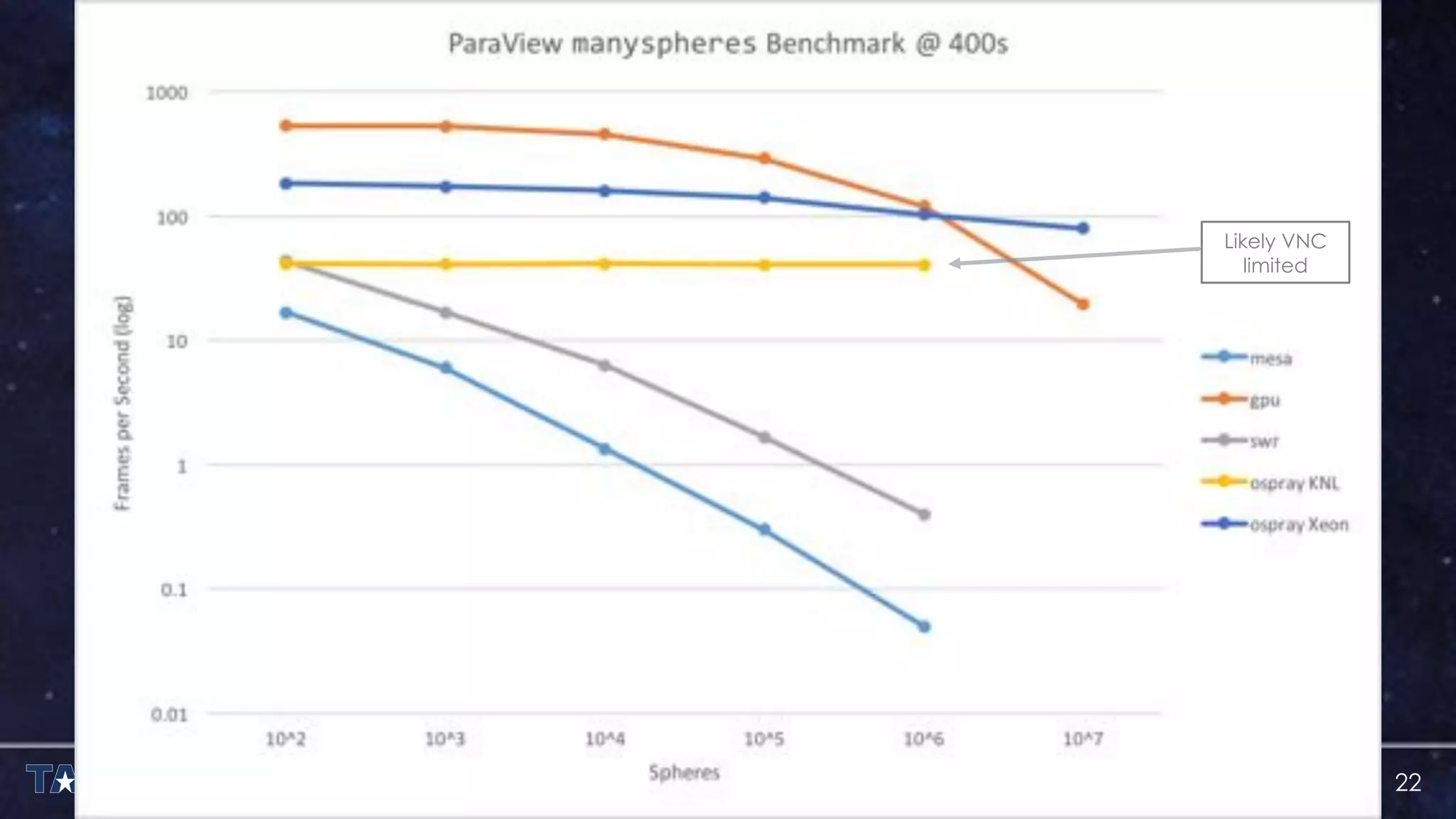

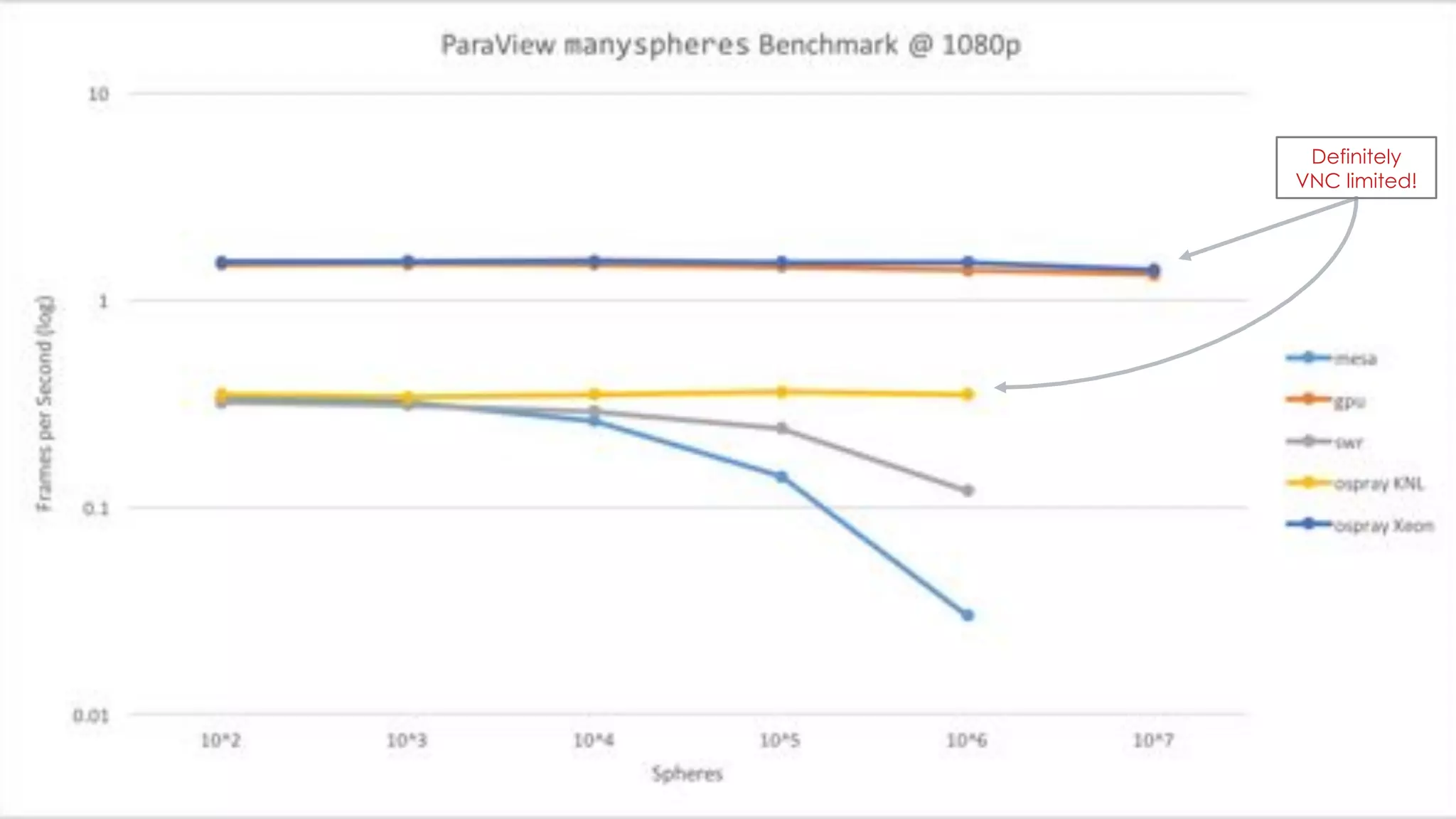
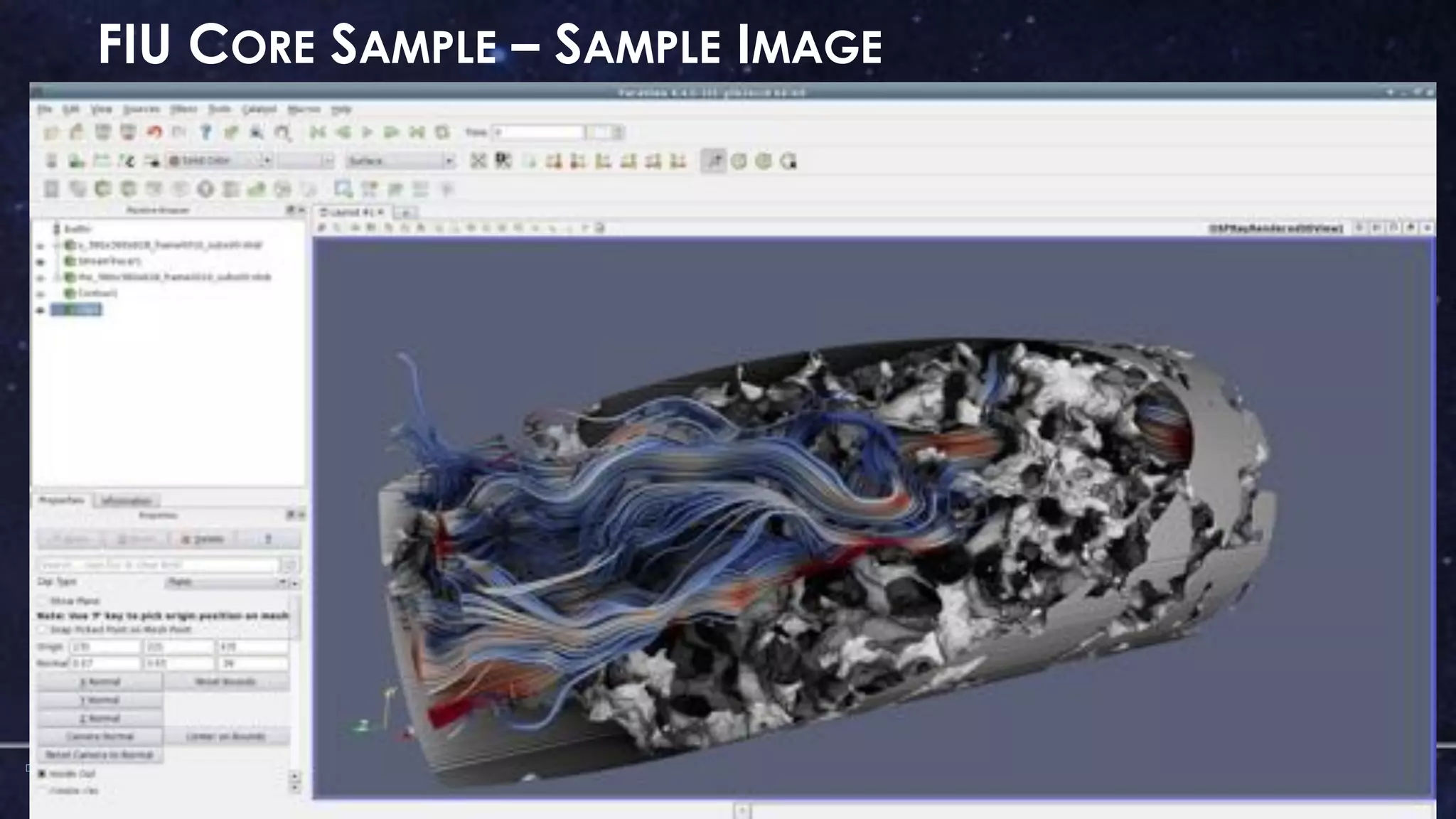
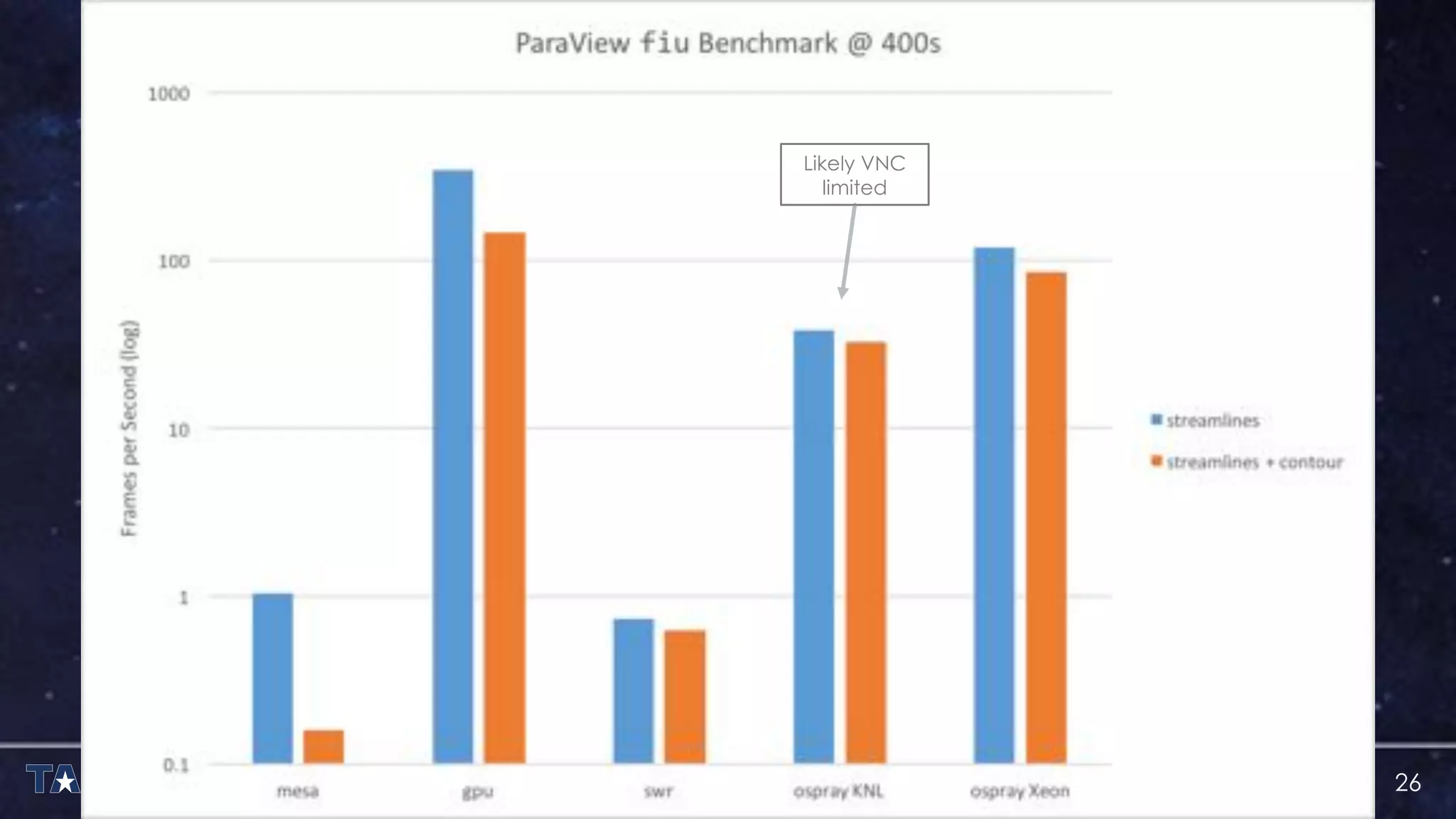
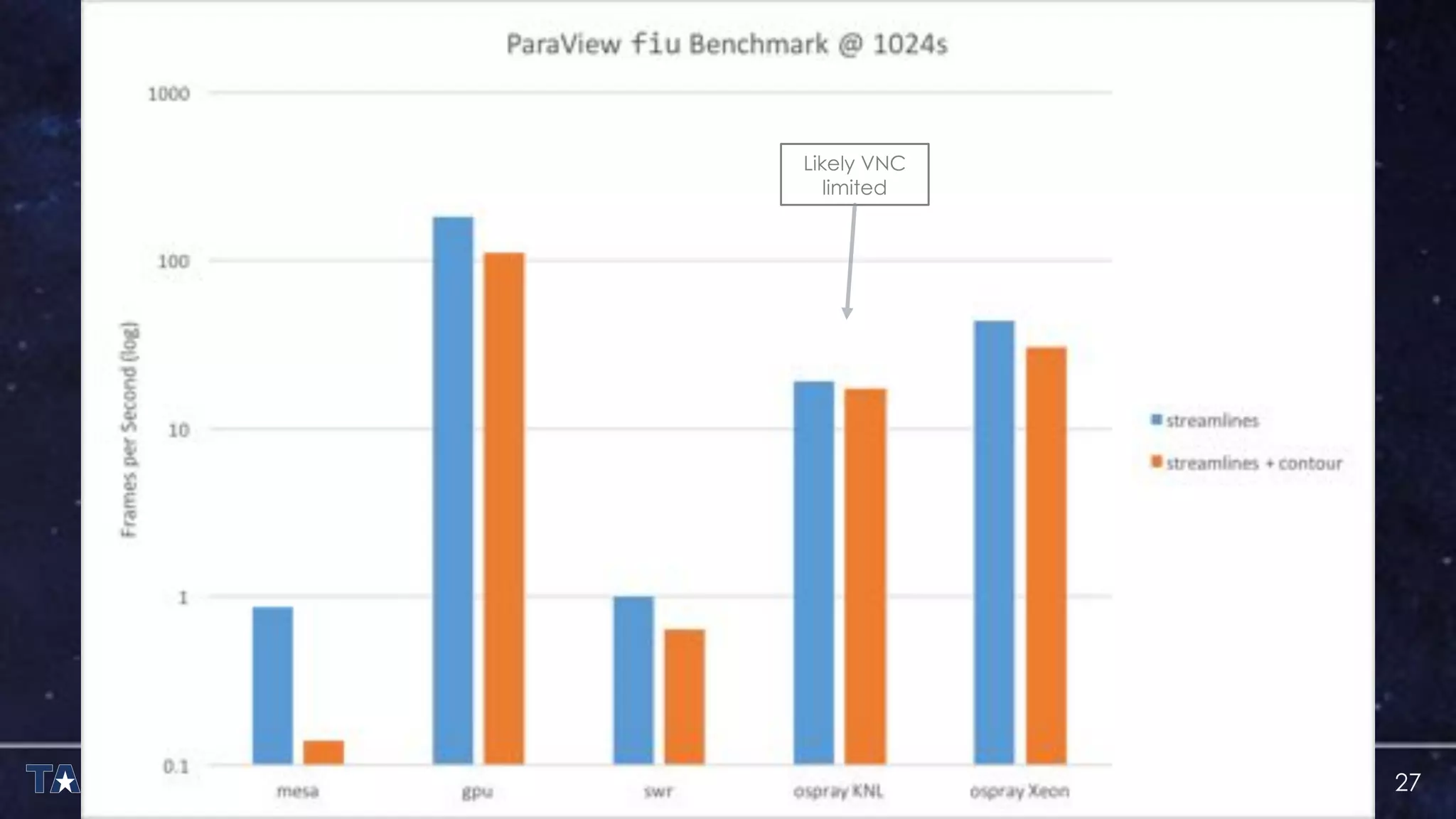
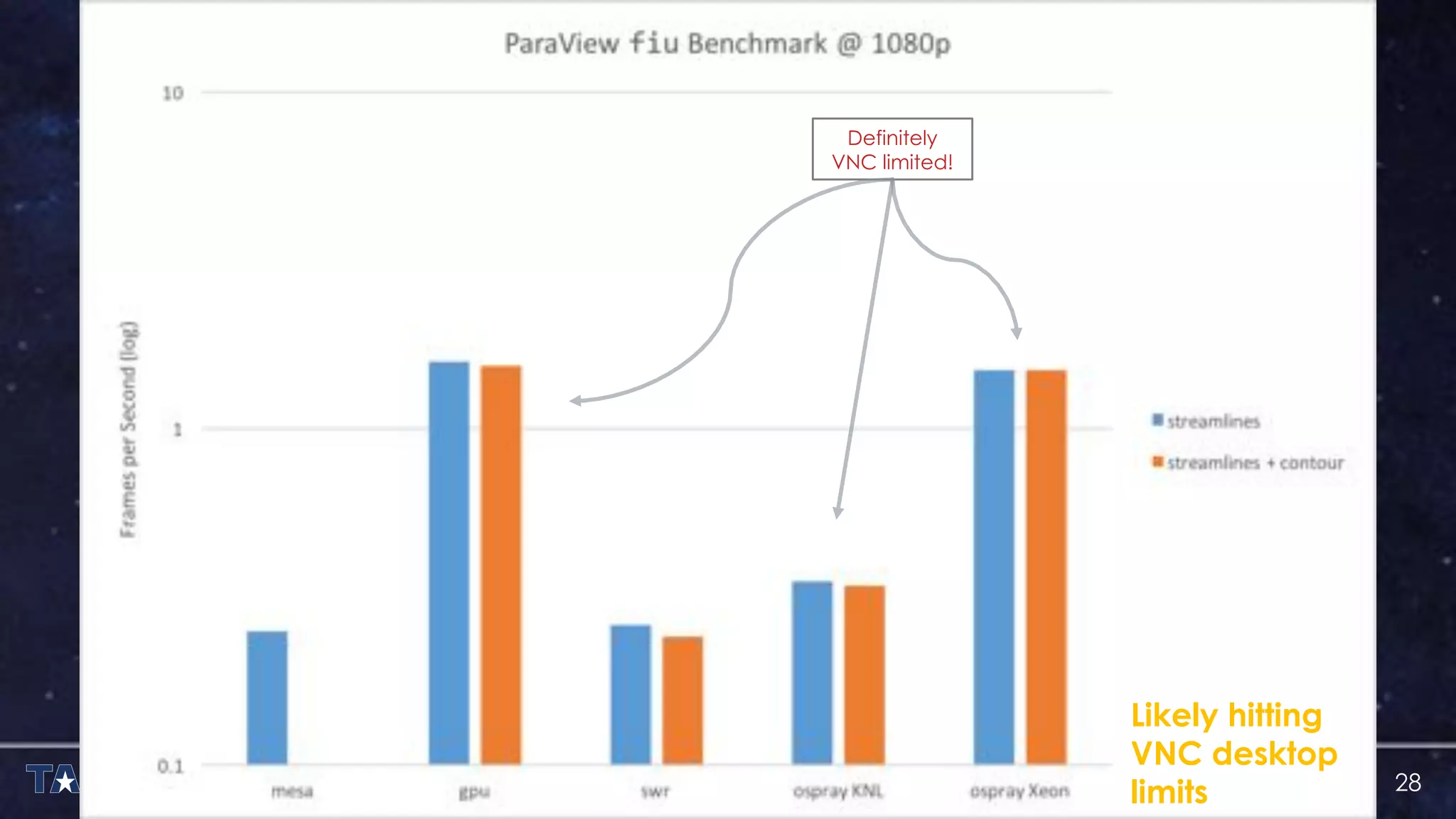



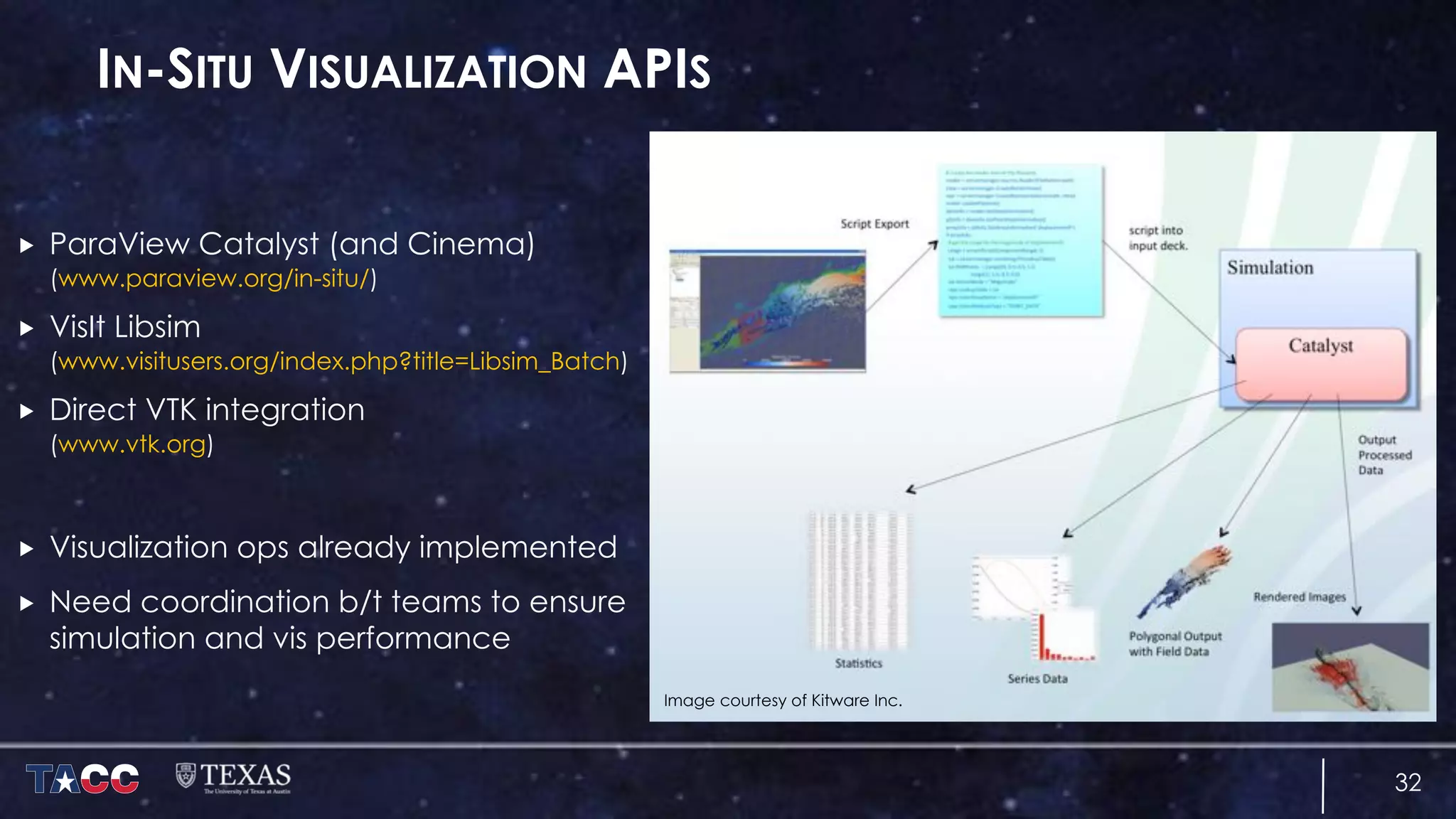





The document discusses the architecture and capabilities of TACC's Stampede and Stampede KNL supercomputers, emphasizing their high-fidelity visualization technologies. It outlines the software-defined visualization stack designed to optimize visualization performance on these systems, particularly highlighting in-situ visualization techniques to overcome data bottlenecks. The future of in-situ visualization is addressed, suggesting collaborative efforts in implementing visualization APIs and frameworks to enhance simulation and analysis capabilities.























































































