Downloaded 102 times


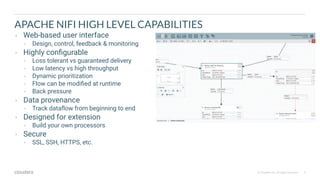
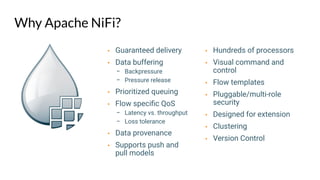


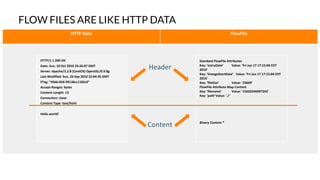





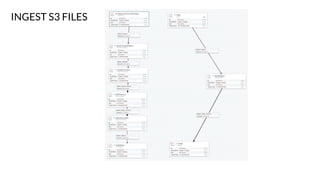
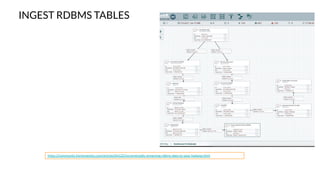

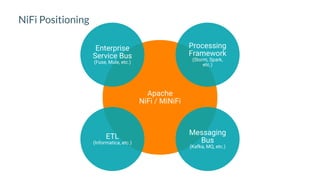
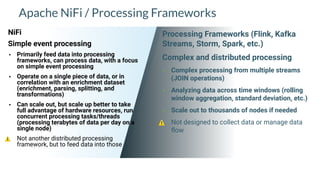
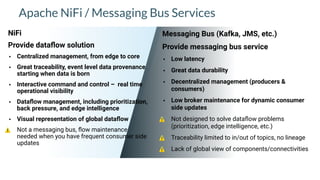
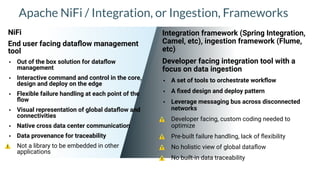

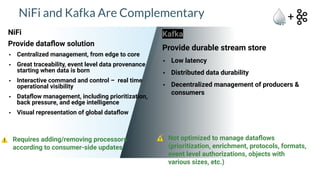


Apache NiFi is a data flow management tool that facilitates the ingestion, transformation, and routing of data through a web-based user interface with capabilities for data provenance, securing data, and dynamic configuration. It supports numerous processors and can handle both structured and unstructured data, making it flexible for various use cases within big data ecosystems. Key features include support for Apache Kafka, Hive, and the ability to execute SQL queries against records, emphasizing its usability in data integration and monitoring.
















































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)





