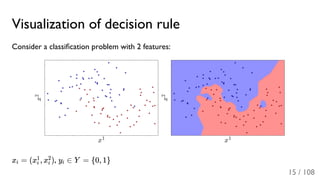
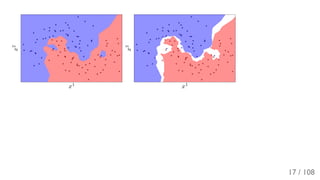
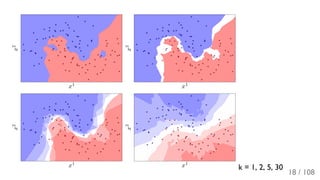
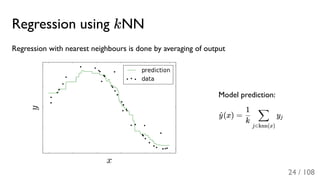
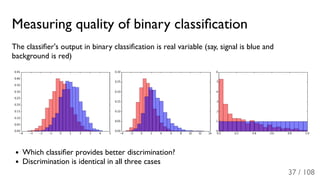
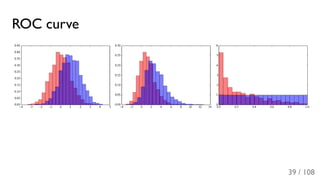
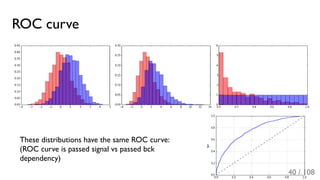
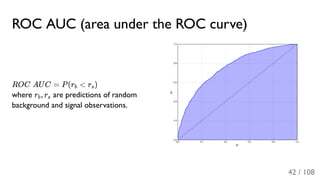
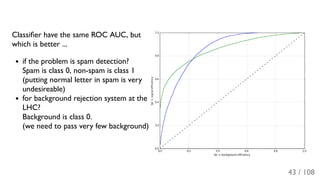
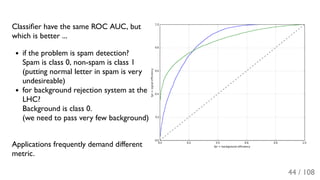
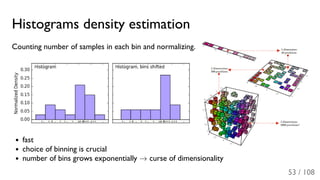
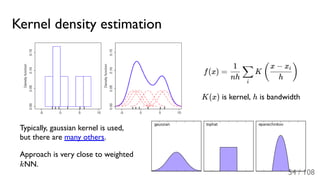
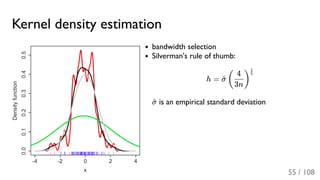
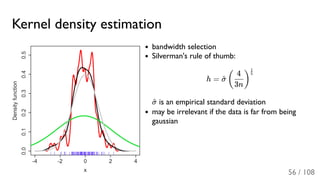
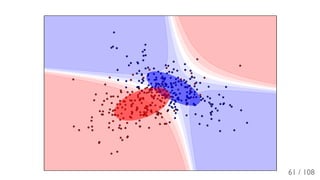
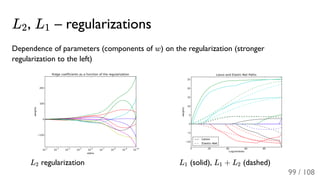
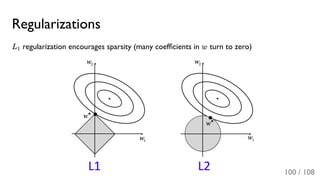
The document outlines the principles and applications of machine learning, particularly in science and industry, highlighting various algorithms and their uses in different fields, including particle physics, spam detection, and health monitoring. It discusses classification and regression problems, the challenges of model selection, and the significance of performance metrics like ROC curves. The document also emphasizes the importance of statistical underpinnings in machine learning and the need for proper techniques to handle data's probabilistic nature.


















































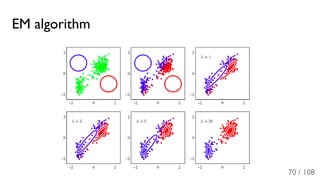
![Expectation-Maximization algorithm [Dempster et al., 1977]
Idea: introduce set of hidden variables π (x)
Expectation: π (x) = p(x ∈ c) =
Maximization:
Maximization step is trivial for Gaussian distributions.
EM-algorithm is more stable and has good convergence properties.
c
c
π f (x; θ )∑c~ c~ c~ c~
π f (x; θ )c c c
πc
θc
= π (x )
i
∑ c i
= arg π (x ) log f (x , θ )
θ
max
i
∑ c i c i c
68 / 108](https://image.slidesharecdn.com/1-lecture-graddays-170420145217/85/Machine-learning-in-science-and-industry-day-1-69-320.jpg)

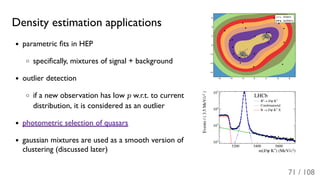
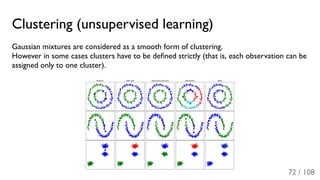











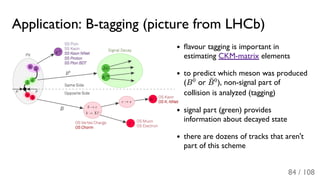

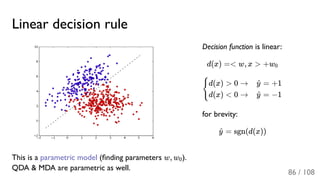























































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)
















![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)









