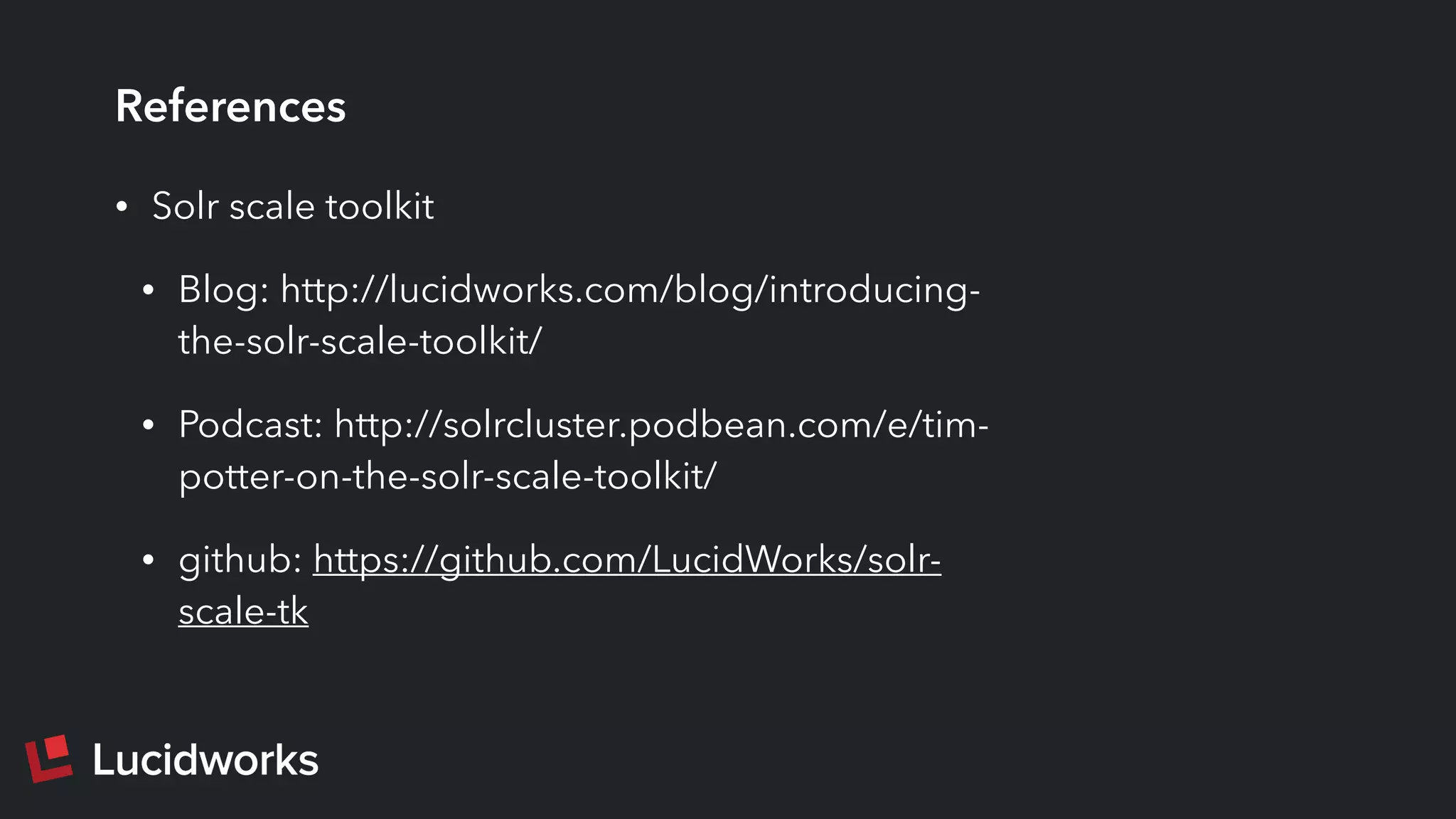
Download as PDF, PPTX


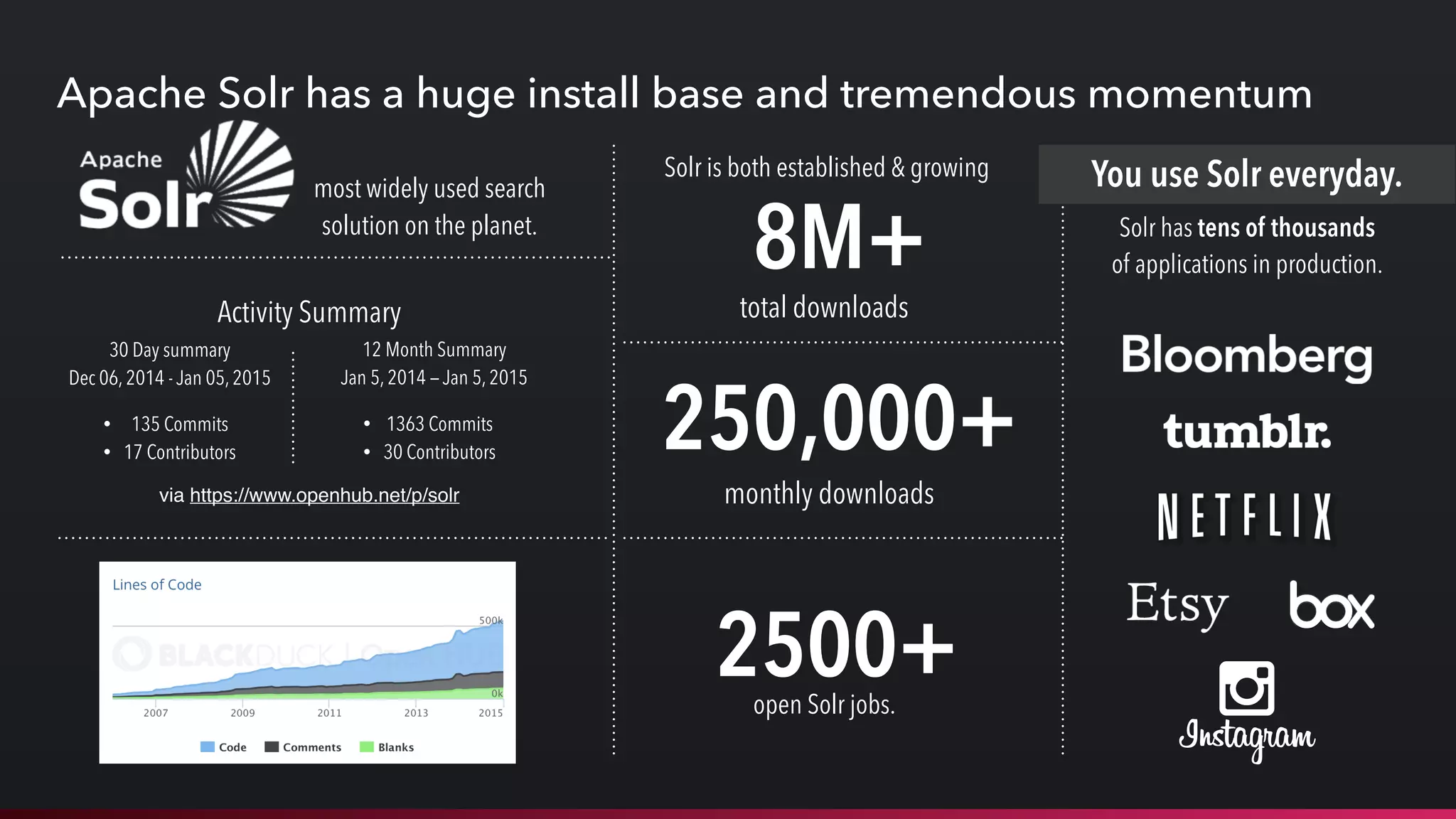


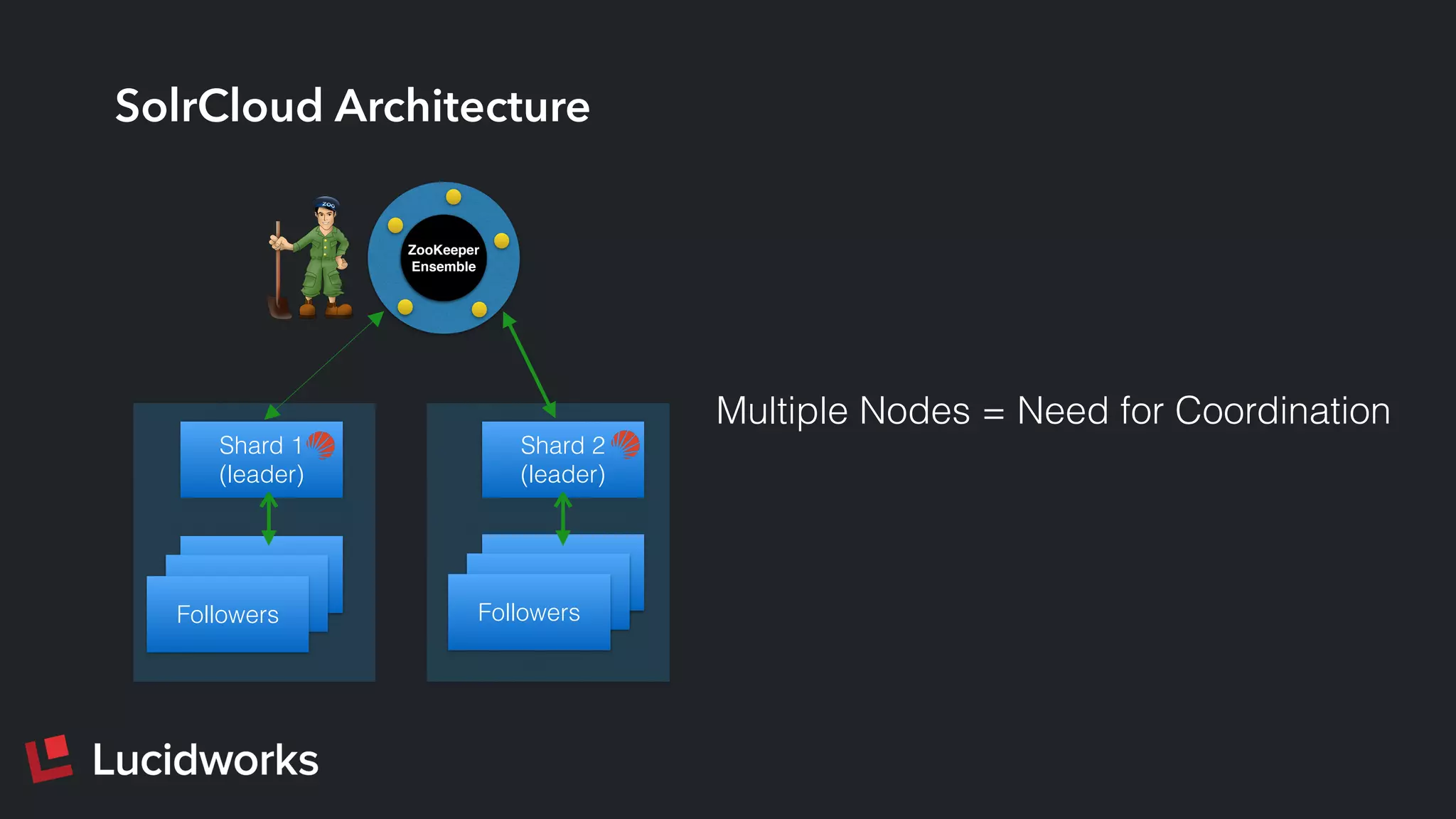



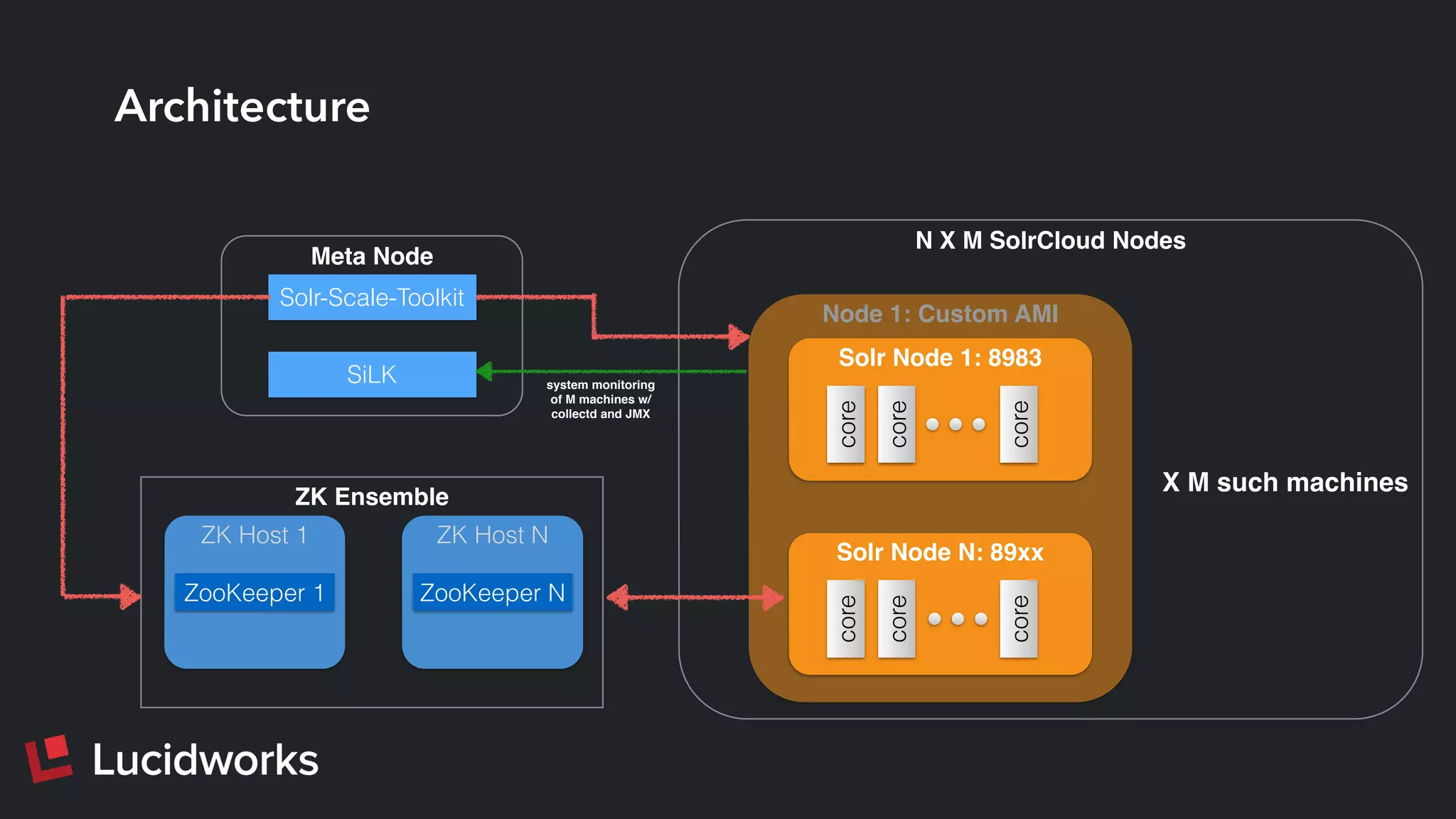




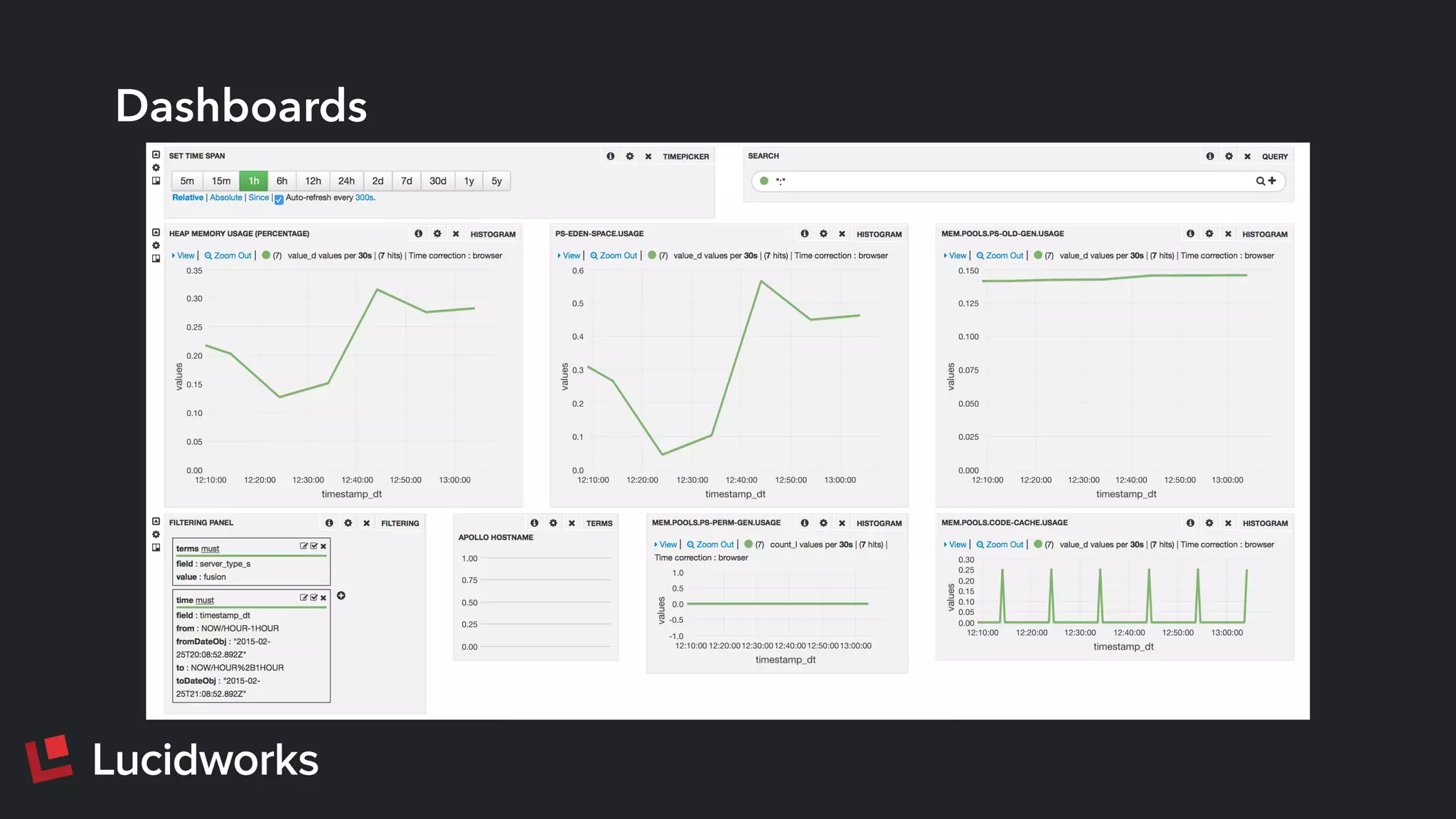


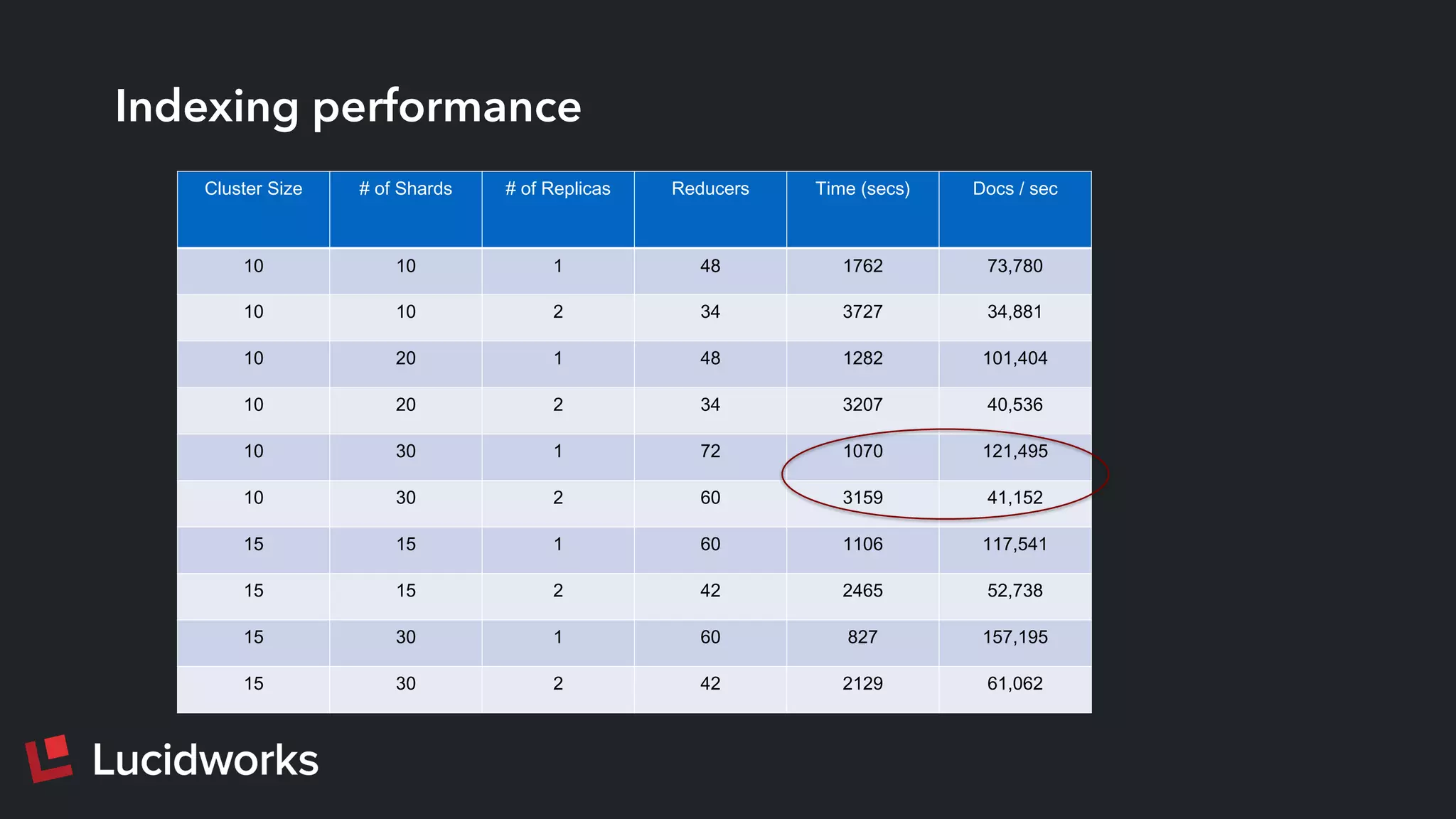





This document discusses deploying and managing Apache Solr at scale. It introduces the Solr Scale Toolkit, an open source tool for deploying and managing SolrCloud clusters in cloud environments like AWS. The toolkit uses Python tools like Fabric to provision machines, deploy ZooKeeper ensembles, configure and start SolrCloud clusters. It also supports benchmark testing and system monitoring. The document demonstrates using the toolkit and discusses lessons learned around indexing and query performance at scale.















































![[Hic2011] using hadoop lucene-solr-for-large-scale-search by systex](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011usinghadoop-lucene-solr-for-large-scale-searchbysystex-111205021544-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





































