Download as PDF, PPTX






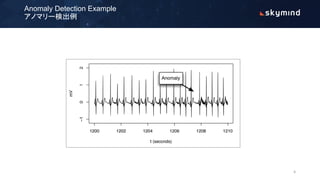
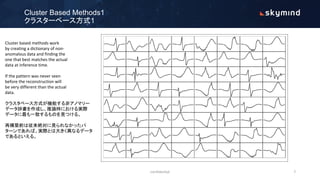
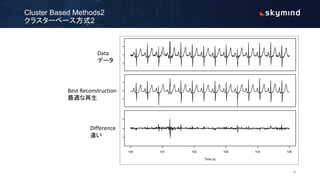
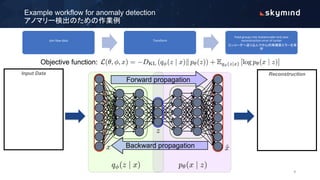










The document discusses various approaches to anomaly detection using deep learning, highlighting the limitations of methods such as probabilistic, distance, domain, reconstruction, and information theoretic-based techniques. It emphasizes the need for multiple algorithms to effectively handle large datasets, addressing issues of class imbalance and the necessity of efficient computation and storage solutions. Additionally, it outlines the training process of autoencoders for detecting anomalies and the design considerations for production environments.







































![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)







































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




