Download to read offline






![Server-side ensemble distillation
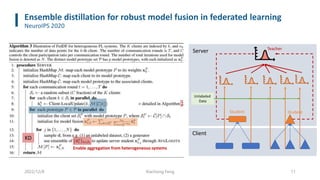
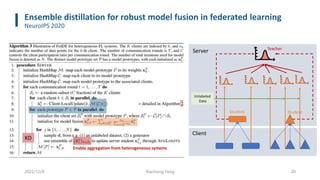
• FedAvg’s protocol can be enhanced to enable model heterogeneity by leveraging server-side ensemble distillation
on top of the aggregation step
• The server can maintain a set of prototypical models, with each prototype representing all learners with same
architecture. After collecting updates from clients, the server firstly performs a per-prototype aggregation and then
produces soft targets for each received client model either leveraging unlabeled data or synthetically generated
examples.
• Next, such soft targets are averaged and used to fine tune each aggregated model prototype, exchanging
knowledge among clients with different model architecture.
• [30] Tao Lin, Lingjing Kong, Sebastian U Stich, and Martin Jaggi. Ensemble distillation for robust model fusion in
federated learning. Advances in Neural Information Processing Systems, 33:2351–2363, 2020.
• [41] Felix Sattler, Tim Korjakow, Roman Rischke, and Wojciech Samek. Fedaux: Leveraging unlabeled auxiliary data
in federated learning. IEEE Transactions on Neural Networks and Learning Systems, 2021.
2022/12/8 Xiachong Feng 10](https://image.slidesharecdn.com/feddistill-221208030447-84e4669b/85/Knowledge-Distillation-for-Federated-Learning-a-Practical-Guide-10-320.jpg)

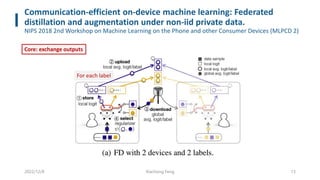


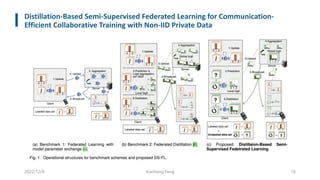




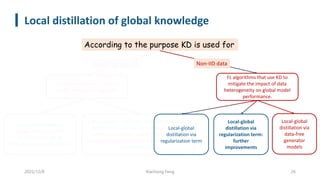
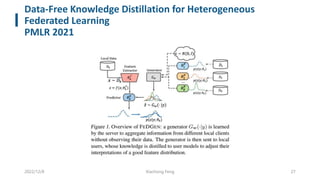


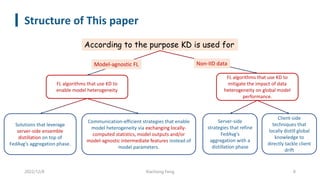
This document summarizes knowledge distillation techniques for federated learning. It discusses how knowledge distillation has been used to enable model heterogeneity by exchanging model outputs or features instead of parameters. It also describes how distillation can be applied at the server-side to refine model aggregation or at the client-side to mitigate the effects of non-IID data distributions. The document structures the discussion according to whether distillation is used to allow for model heterogeneity or address data heterogeneity and provides examples of approaches within each category.


































![[OREILLY AI LONDON 2019] Anomaly Detection in Smart Buildings using Federated...](https://cdn.slidesharecdn.com/ss_thumbnails/oreillyailondon2019-250320154727-d2c2115c-thumbnail.jpg?width=640&height=640&fit=bounds)














![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)

















