Downloaded 893 times

























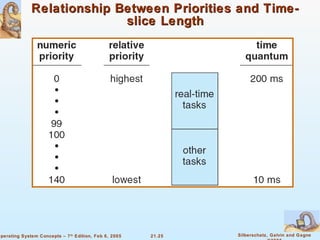




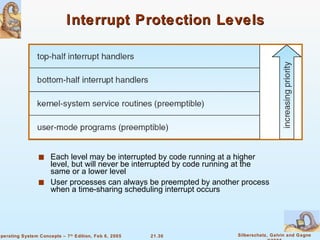




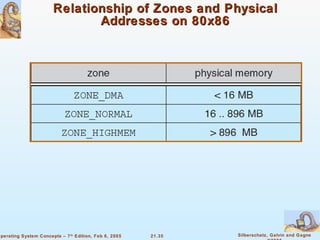
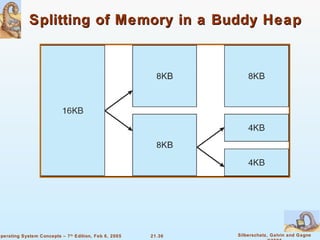

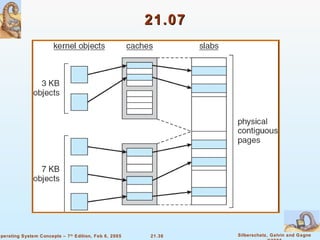






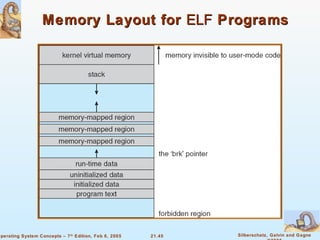



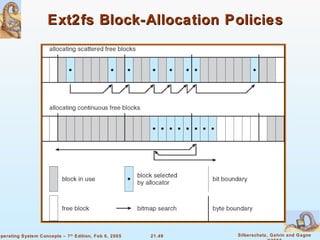


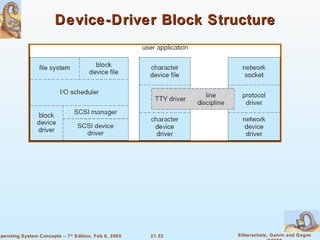











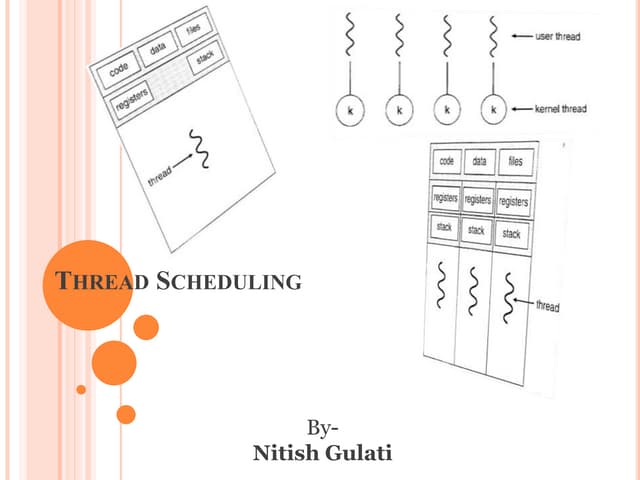
Linux is an open-source operating system based on UNIX with a modular kernel. It uses processes, memory management and file systems similar to UNIX. The Linux kernel supports features like symmetric multiprocessing, virtual memory and loading of kernel modules. Popular Linux distributions package and distribute the Linux system along with utilities and applications.