Downloaded 80 times





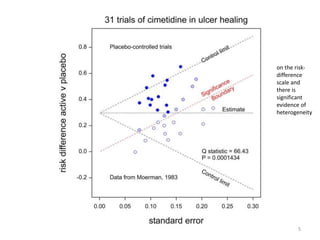


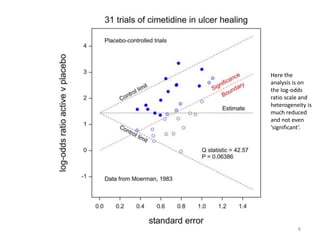


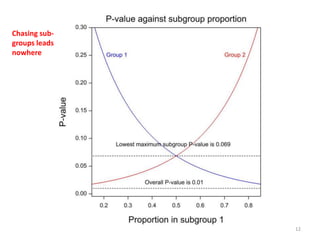


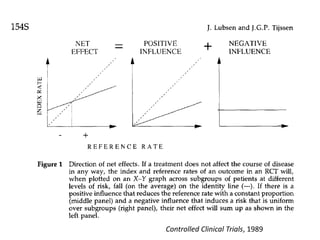

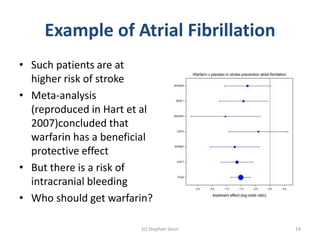
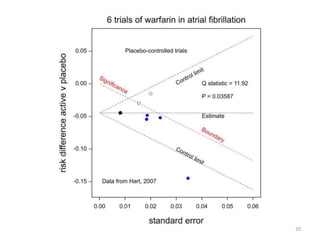
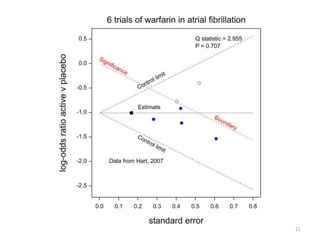

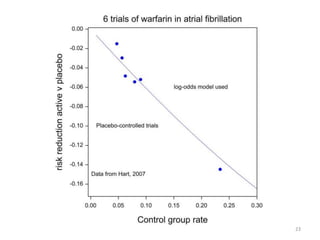
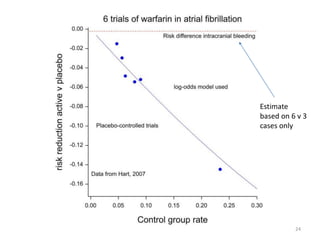

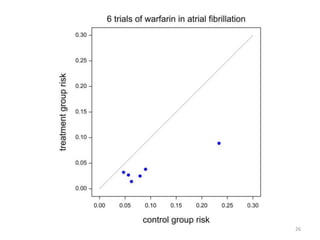





Stephen Senn argues that clinical trials are often unrepresentative of real-world clinical practice, and it's crucial to use appropriate analysis scales and real-world data for better decision-making. He emphasizes that trying to make trials more representative is not the solution; rather, we need effective modeling and auxiliary information to translate results into practical applications. The document highlights the importance of collaboration among medical professionals and statisticians to better evaluate treatment benefits and risks in real-world settings.























































































