Downloaded 133 times









![Questions? About the Presenter Randy Shoup has been the primary architect for eBay's search infrastructure since 2004. Prior to eBay, Randy was Chief Architect and Technical Fellow at Tumbleweed Communications, and has also held a variety of software development and architecture roles at Oracle and Informatica. [email_address]](https://image.slidesharecdn.com/bestpracticesforscalingwebsites-lessonsfromebaytokyo-110515181212-phpapp01/75/Best-Practices-for-Large-Scale-Websites-Lessons-from-eBay-16-2048.jpg)

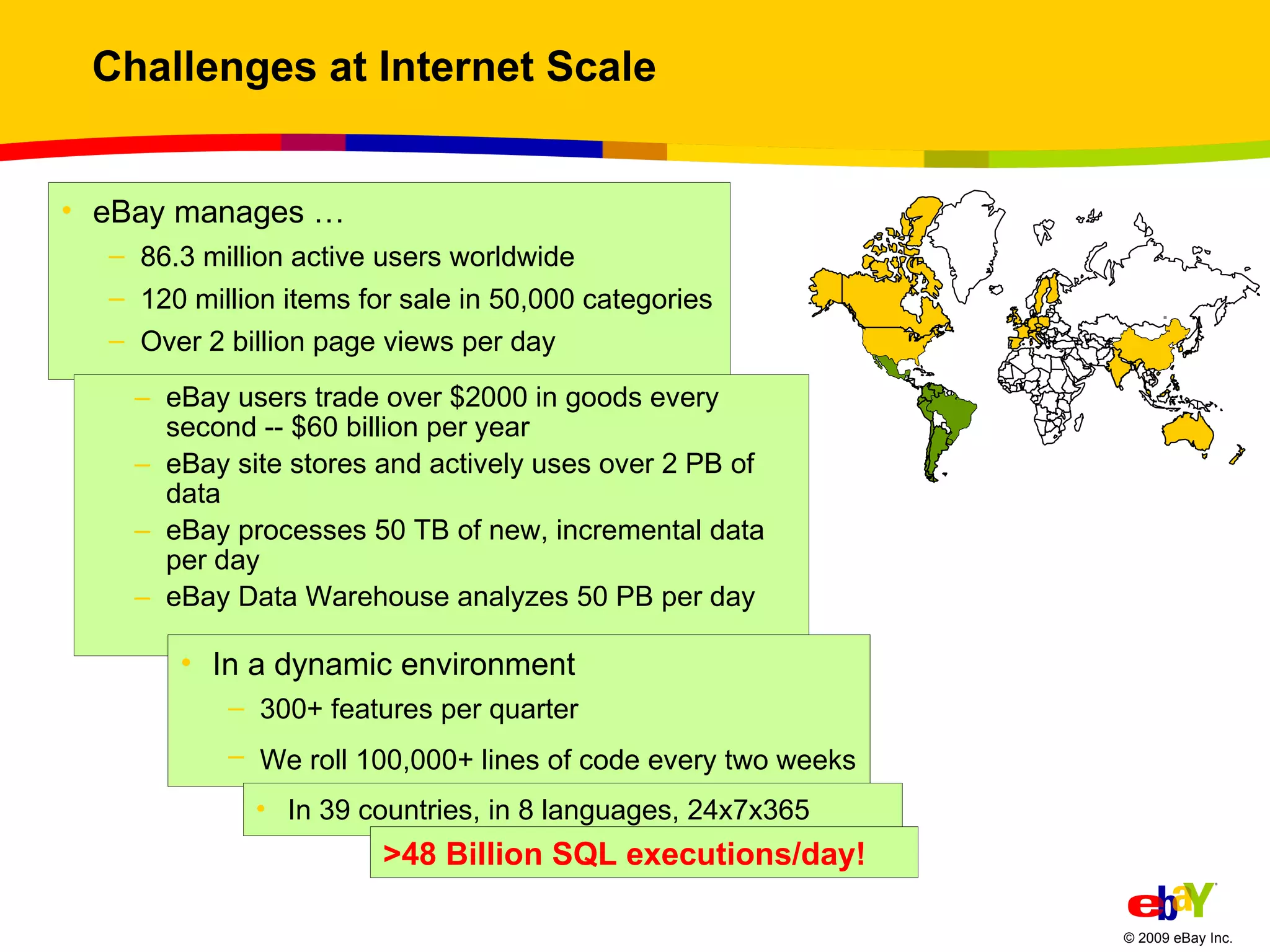
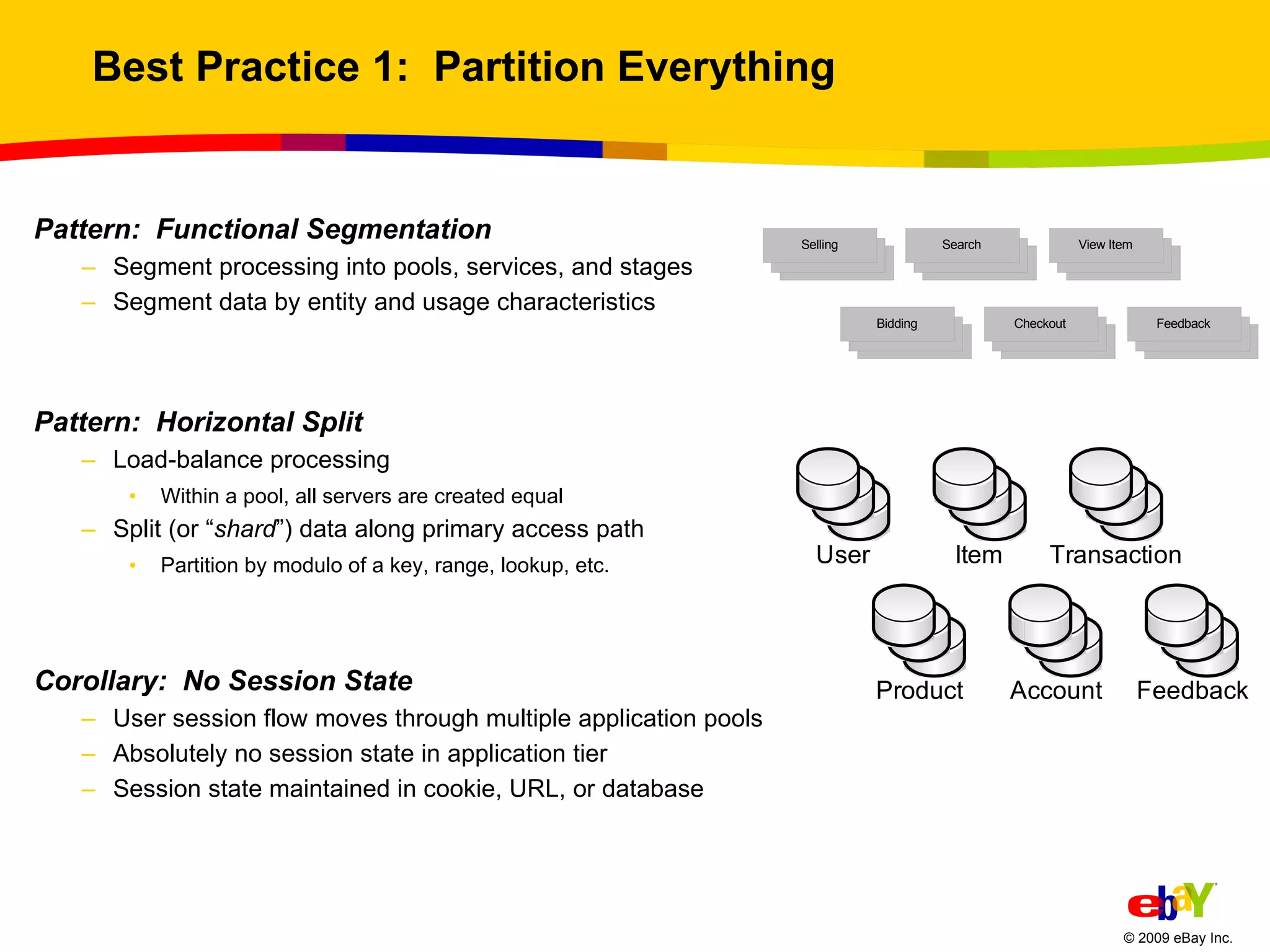
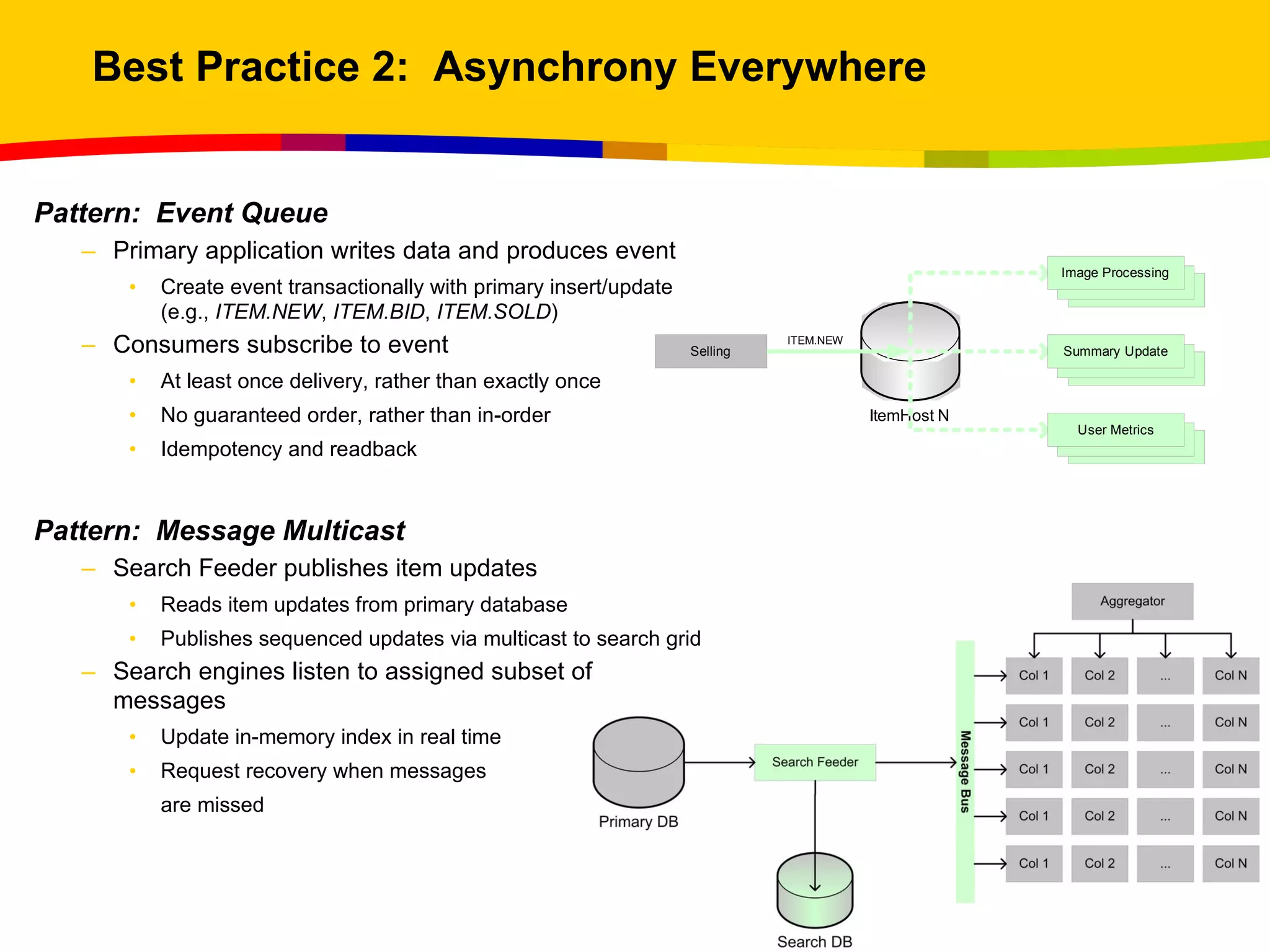
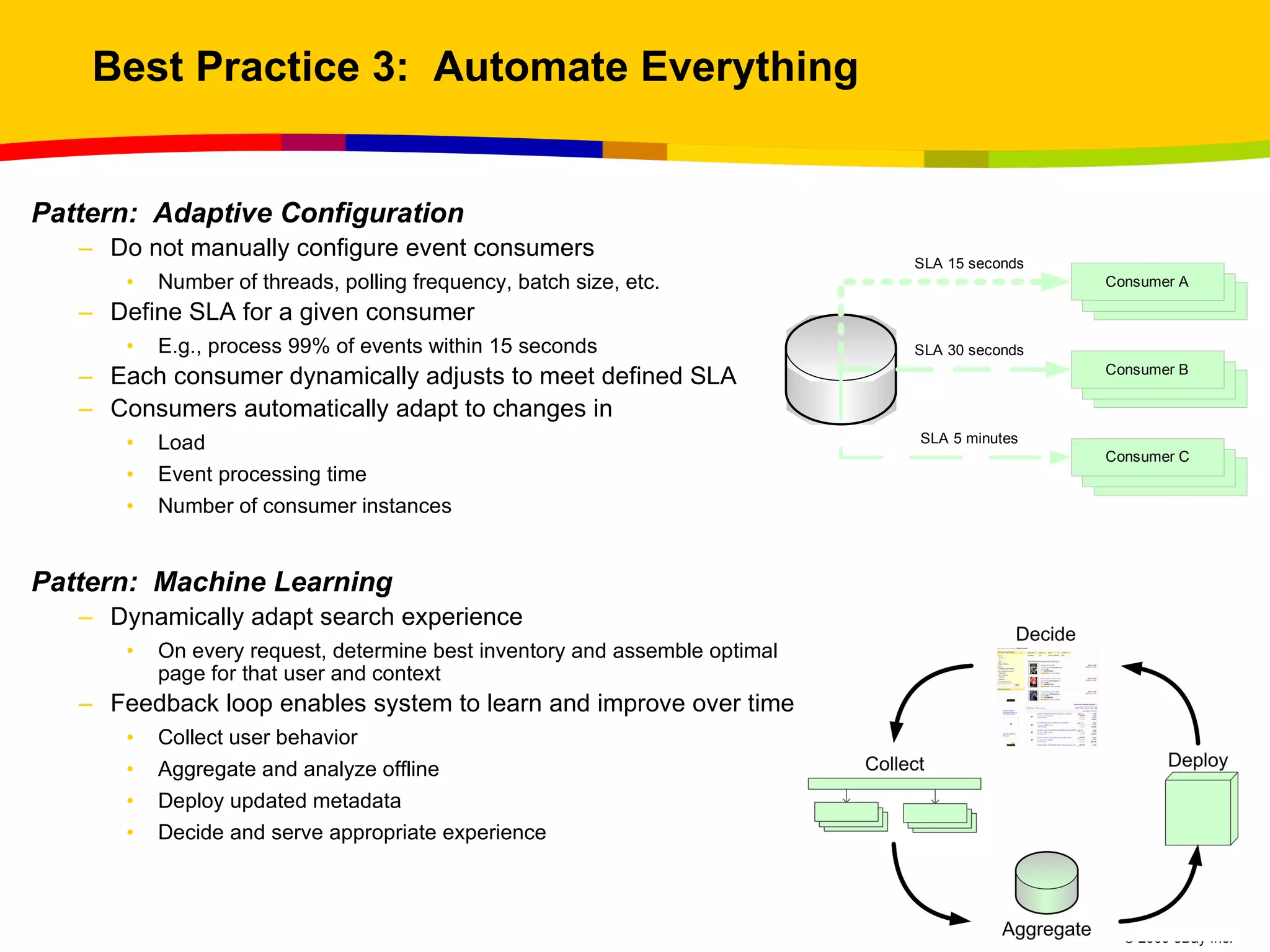
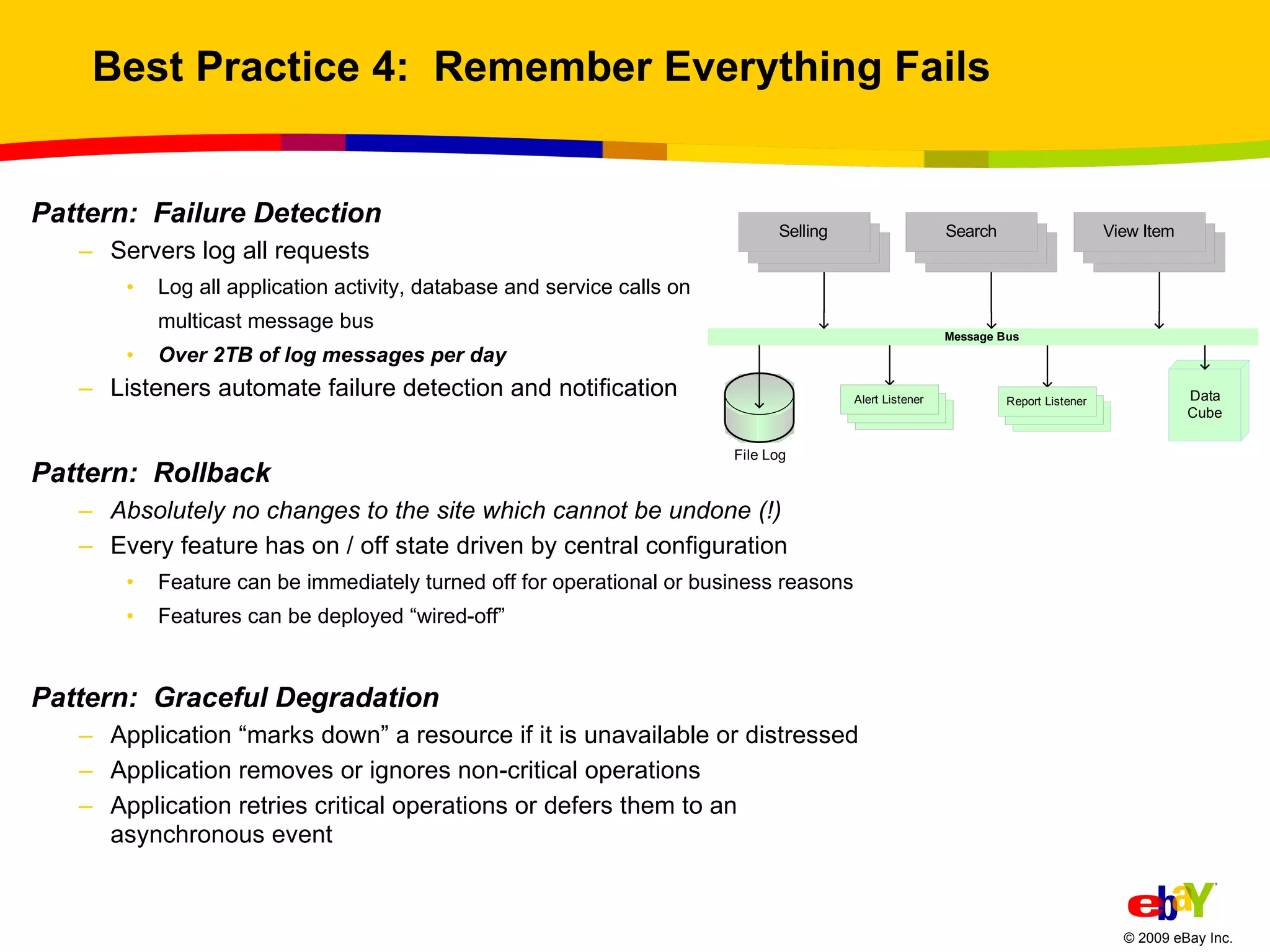
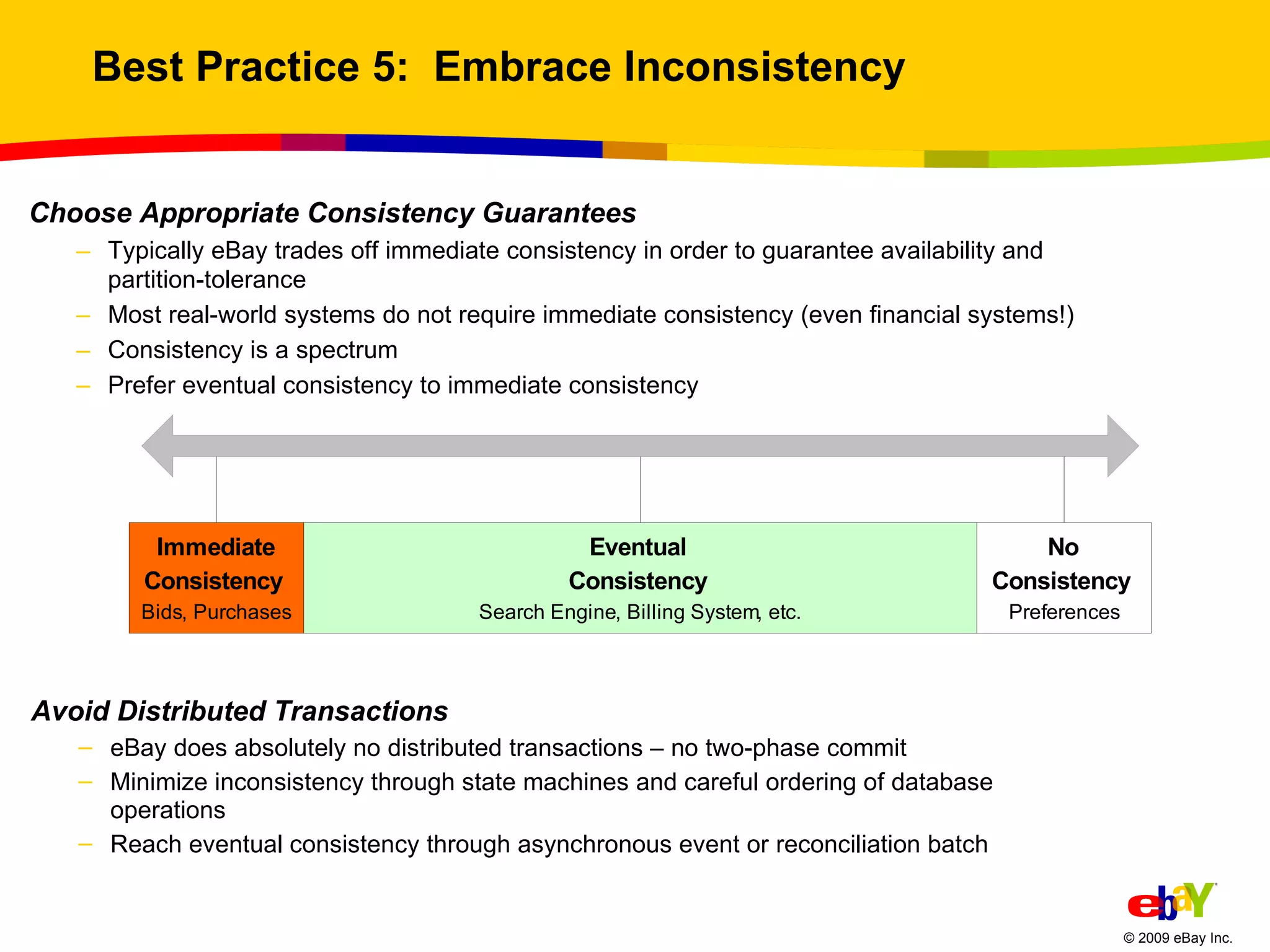
The document outlines best practices for scaling websites, drawing lessons from eBay's architectural strategies. It emphasizes the importance of partitioning, adopting asynchronous processing, automation, building systems that tolerate failure, and understanding consistency trade-offs. These practices aim to enhance scalability, availability, and manageability in high-demand internet environments.

























![Own Your Own Impact: Incident Response at Airbnb [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/futurestack16airbnb-161202194236-thumbnail.jpg?width=640&height=640&fit=bounds)

































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





