Downloaded 160 times

















![the gateway provider. This process would also enable the gateway provider to create a profile of
the entity, which must include the name of the entity and an entity ID. For example, in the case
of care facilities, this could be a facility ID assigned by the facility registry or an HIP/HIU ID
created by the gateway.
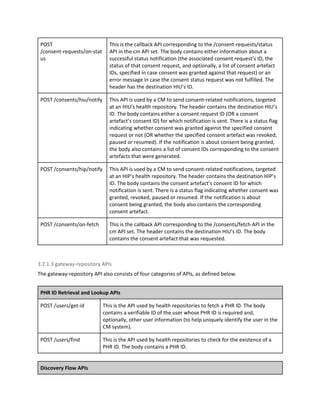
2. Submitting health repository details: The entity must furnish the name of its associated health
repository provider and the access URL - in the repository provider’s domain - for all the HIF APIs
of this entity. The access URL must be in the list of access URLs provided by the entity’s
repository provider when registering itself.
All these steps must be undertaken by suitable human representatives of the entity that is being
onboarded.
3.1.2 Onboarding CMs and health repositories
Like HIPs and HIUs, CMs and health repository providers also need to register themselves with a
gateway provider. This process also involves an entity validation step and an information submission
step. However, in the case of CMs and repositories, there are no externally available registries and as
such, gateway providers need to create these registries.
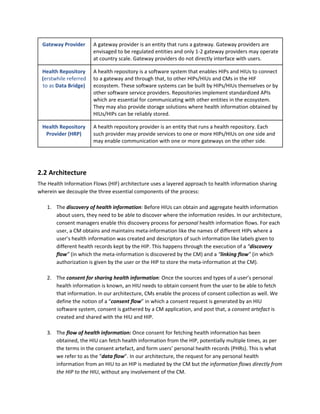
3.1.2.1 CM registration
CMs need to validate themselves by providing information about license, if any, obtained from a
healthcare or other regulator and details about their registration as a company (or, if they are not a
company, then details of having registered as an organization of the type they are). CMs may also be
required to submit a certificate from a certification agency that claims the CM’s software system to be
compliant with the HIF standards. Through the certificate or otherwise, CM’s must provide SLAs on all
the HIF APIs implemented by them.
Once validated, CMs must submit all data that is required to create the CM’s entry in the CM registry.
The base schema for the CM registry is given below. This schema may be extended by the gateway.
Schema for CM registry:
cm-info: {
// private attributes:
cm-id: “integer”, // UUID used for addressing CM internally
license: “string” // Base-64 encoded license document issued by a regulator
sla-details: “object” // Details of SLA provided by the CM
reg-time: “string” // Registration time of the CM, in date-time format
last-updated: “string” // Time of last update of CM info, in date-time format
// public attributes:
cm-full-name: “string”, // Full name of the CM, an arbitrary alpha-numeric string
cm-name: “string”, // Name of the CM used in all PHR IDs issued by it, format: [a-z|A-Z|-|.]*](https://image.slidesharecdn.com/healthinformationflows-technicalstandards-v0-200705063446/85/Health-Information-Flows-Technical-Standards-V-0-5-19-320.jpg)
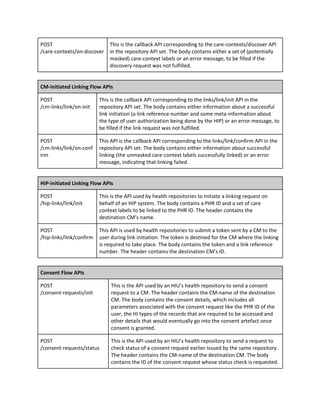
![accessURLs: [ // list of URLs that could be used to access CM APIs
accessURL: “string”, // URL for accessing CM APIs
]
pki-certificate: “string”, // Base-64 encoded X.509 certificate with CM’s long-term public key.
isActive: “boolean” // Flag indicating whether CM is currently active or not
isBlacklisted: “boolean” // Flag indicating whether CM has been blacklisted by the gateway
}
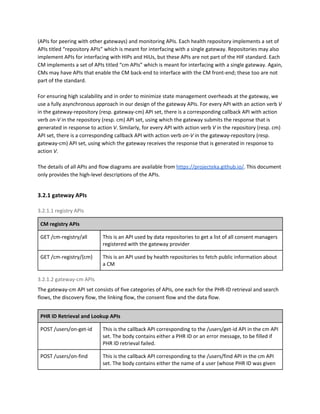
3.1.2.1 Repository registration
Like CMs, health repository providers must also furnish company registration details at the time of
registration in order to validate themselves. Software certification and SLAs must also be submitted. As
in the case of CMs, repository providers must submit other information that is needed to create a
registry entry for the repository provider. The base repository provider registry schema is given below. It
is extensible by gateway providers.
Schema for repository provider registry:
repository-provider-info: {
// private attributes:
repo-provider-id: “integer”, // UUID used for addressing the provider internally
sla-details: “object” // Details of SLA provided by the repository provider
reg-time: “string” // Registration time of the repository provider, in date-time format
last-updated: “string” // Time of last update of repository provider info, in date-time format
hip-list: [ // List of HIPs for whom this is an associated repository provider
hip-id: “string” // HIP ID as defined at the time of HIP registration
]
hiu-list: [ // List of HIUs for whom this is an associated repository provider
hiu-id: “string” // HIU ID as defined at the time of HIU registration
]
// public attributes:
repo-provider-full-name: “string”, // Full name, an arbitrary alpha-numeric string
accessURLs: [ // list of URLs that could be used to access repository provider APIs
accessURL: “string”, // URL for accessing repository provider APIs
]
pki-certificate: “string”, // Base-64 encoded X.509 cert with provider’s long-term public key
isActive: “boolean” // Flag indicating whether provider is currently active or not
isBlacklisted: “boolean” // Flag indicating whether provider has been blacklisted
}](https://image.slidesharecdn.com/healthinformationflows-technicalstandards-v0-200705063446/85/Health-Information-Flows-Technical-Standards-V-0-5-20-320.jpg)

![3.3 Flows
In presenting the various flows, we use the following conventions:
● Solid lines for interactions which are covered by this standard; dotted lines for interactions
which are also part of the flows but not covered by the standard.
● API names in bold and API parameters in brackets in the form of (header; body).
● HIP-IDs, HIU-IDs and CM-names are referred to as hip, hiu and cm respectively.
● The symbol “|” denotes the logical operator OR.
● Parameters enclosed in square brackets “[ .. ]” are to be treated as optional parameters.
● We require that every request have a unique request ID (a UUID generated by the API
requester) and a timestamp. These are not explicitly shown in the flow diagrams. Every callback
API (API ending in on-V for some verb V) must additionally have an ID whose value is the request
ID of the API request that is being responded to. This is also omitted in the diagrams.
● We specify only key body parameters in the flow diagrams and do this at a high level e.g.
consent-details is a parameter which contains various details related to a consent creation
request. Detailed description of API body contents and parameters is available from:
https://projecteka.github.io/
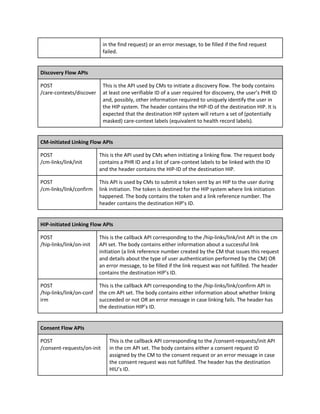
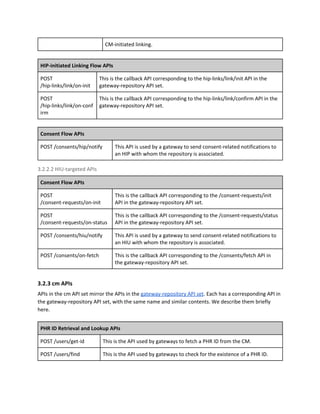
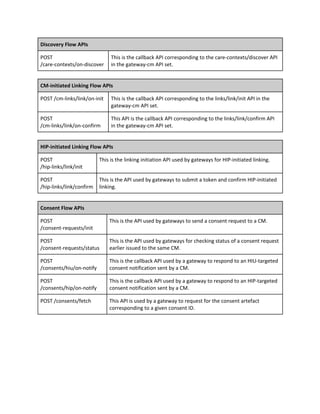
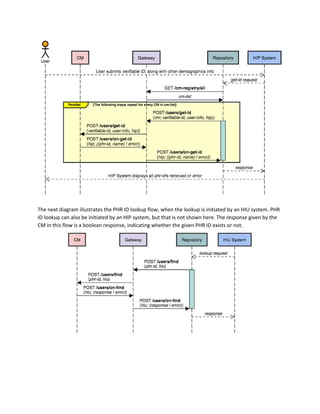
3.3.1 PHR ID retrieval and lookup
We illustrate how PHR ID retrieval works when initiated at an HIP system. Retrieval can also be initiated
by an HIU system but that flow is not shown here. PHR ID retrieval begins with the user submitting a
verifiable ID to an HIP along with demographic information, triggering a get-id request to the associated
health repository. The health repository first gets a list of all available CMs from the gateway using the
registry API. For all CMs in the list of CMs, the repository sends simultaneous requests containing the
verifiable ID and demographic information submitted by the user. Each CM internally matches the
provided information against all user profiles and returns a PHR ID (and name of the user) if a match
succeeds. The matching algorithm is CM-determined and may involve doing fuzzy matches on user
demographic information. Eventually, the HIP system displays all PHR IDs returned by the different CMs
and lets the user select which PHR ID to use in succeeding flows.](https://image.slidesharecdn.com/healthinformationflows-technicalstandards-v0-200705063446/85/Health-Information-Flows-Technical-Standards-V-0-5-29-320.jpg)

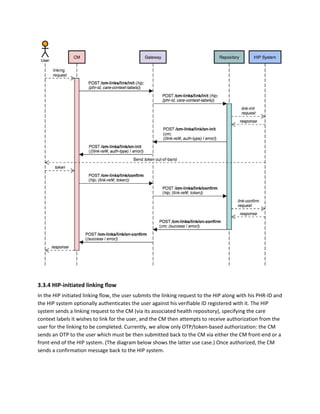


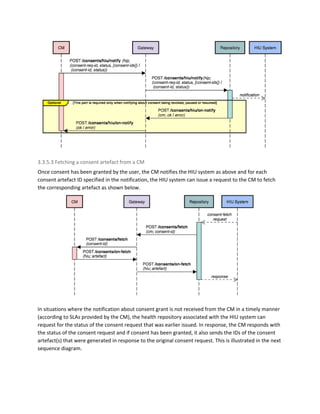


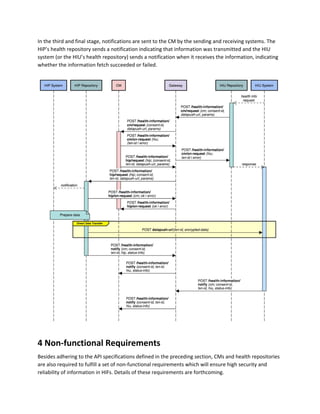

This document outlines a technical architecture for the consented sharing of personal health information through health data consent managers (CMS) and addresses health information flows between health information providers (HIPs) and health information users (HIUs). It emphasizes principles such as privacy by design, scalability, and user centricity, aiming to facilitate a system applicable globally despite being developed as part of India's national health stack initiative. The architecture includes layers for discovery, consent, and data flow, driven by the need to improve user control and interoperability in health information exchange.


























































![Angel Tax Presentation To DIPP [Section 56(2)(viib)]](https://cdn.slidesharecdn.com/ss_thumbnails/angeltaxpresentation-04012019-190109040930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Angel Tax] White Paper On Section 56 (2)(viib) And Section 68](https://cdn.slidesharecdn.com/ss_thumbnails/whitepaperonsection562viibandsection68-181220180554-thumbnail.jpg?width=640&height=640&fit=bounds)


























