Downloaded 34 times



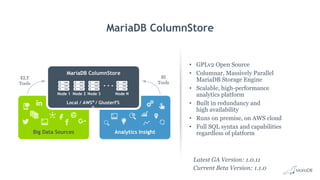
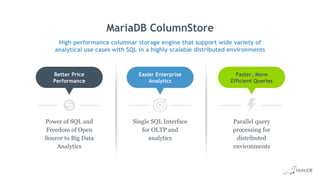



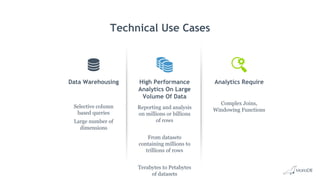




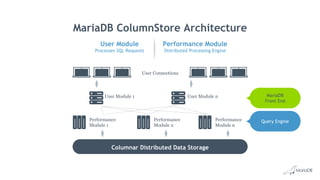


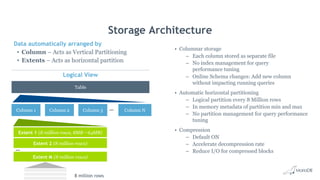
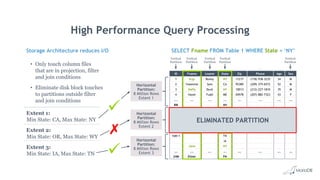

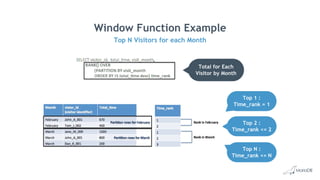

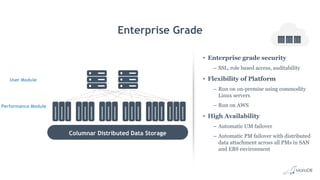



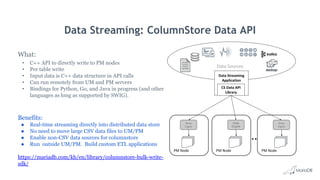
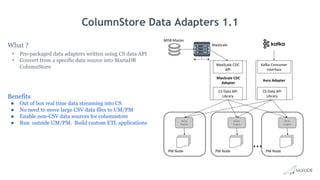




Big Data Analytics with MariaDB ColumnStore provides an overview of MariaDB ColumnStore. Key points include: - MariaDB ColumnStore is an open source columnar storage engine that provides high performance analytics on large datasets in a scalable distributed environment using standard SQL. - Columnar storage organizes data by columns rather than rows, improving query performance by only accessing relevant columns. It supports workloads from terabytes to petabytes of data. - Common use cases include data warehousing, financial services, healthcare, telecom, and any workload requiring analysis of millions to billions of rows. - The architecture employs a distributed query processing model with horizontal partitioning and parallel query execution across nodes for high scalability
































![[db tech showcase OSS 2017] A23: Analytics with MariaDB ColumnStore by MariaD...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628024921-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase OSS 2017] A25: Replacing Oracle Database at DBS Bank by Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628030047-thumbnail.jpg?width=640&height=640&fit=bounds)










![[db tech showcase Tokyo 2017] C37: MariaDB ColumnStore analytics engine : use...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstoreusecases1-170911080447-thumbnail.jpg?width=640&height=640&fit=bounds)










































