Download as PDF, PPTX



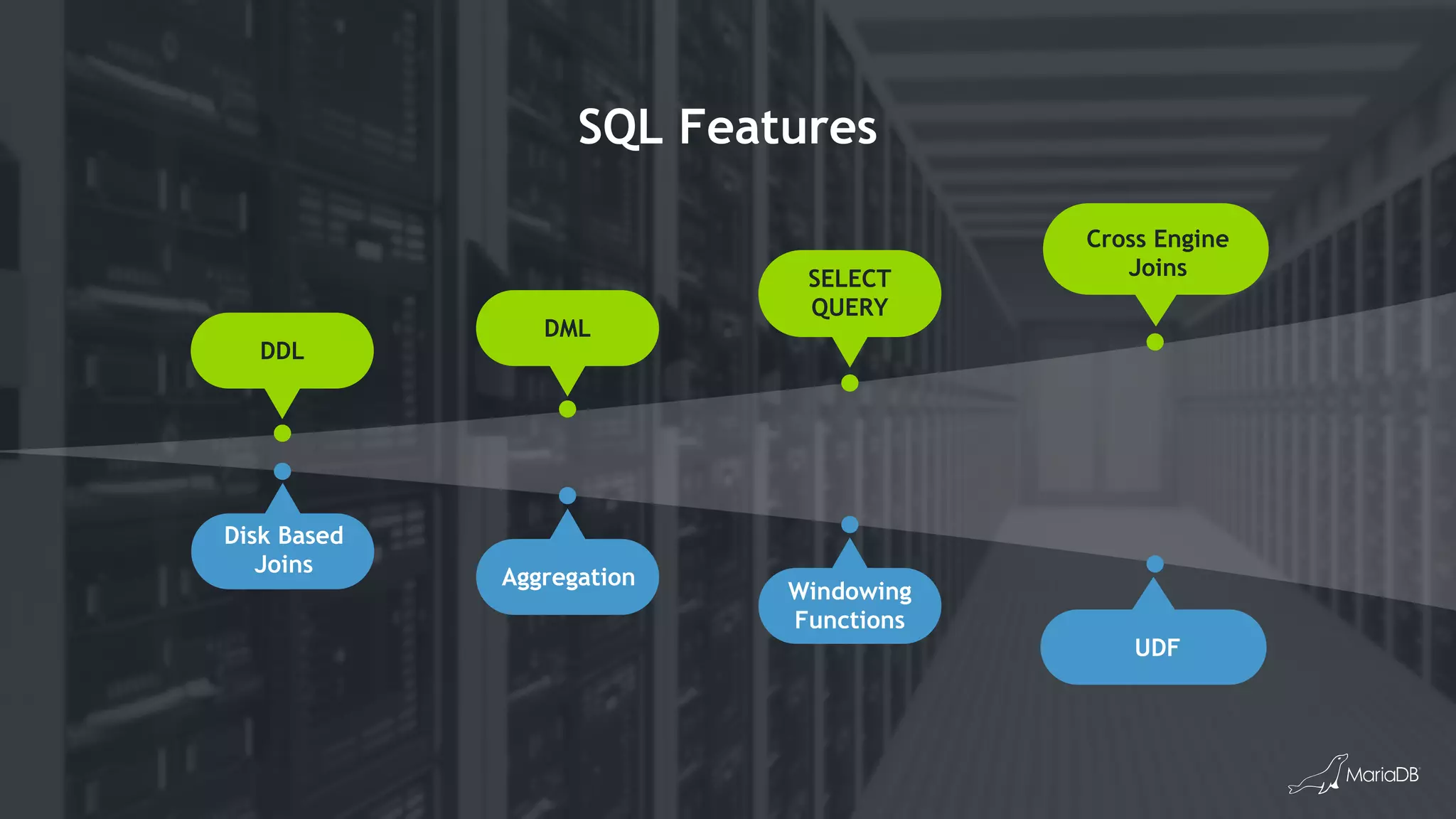



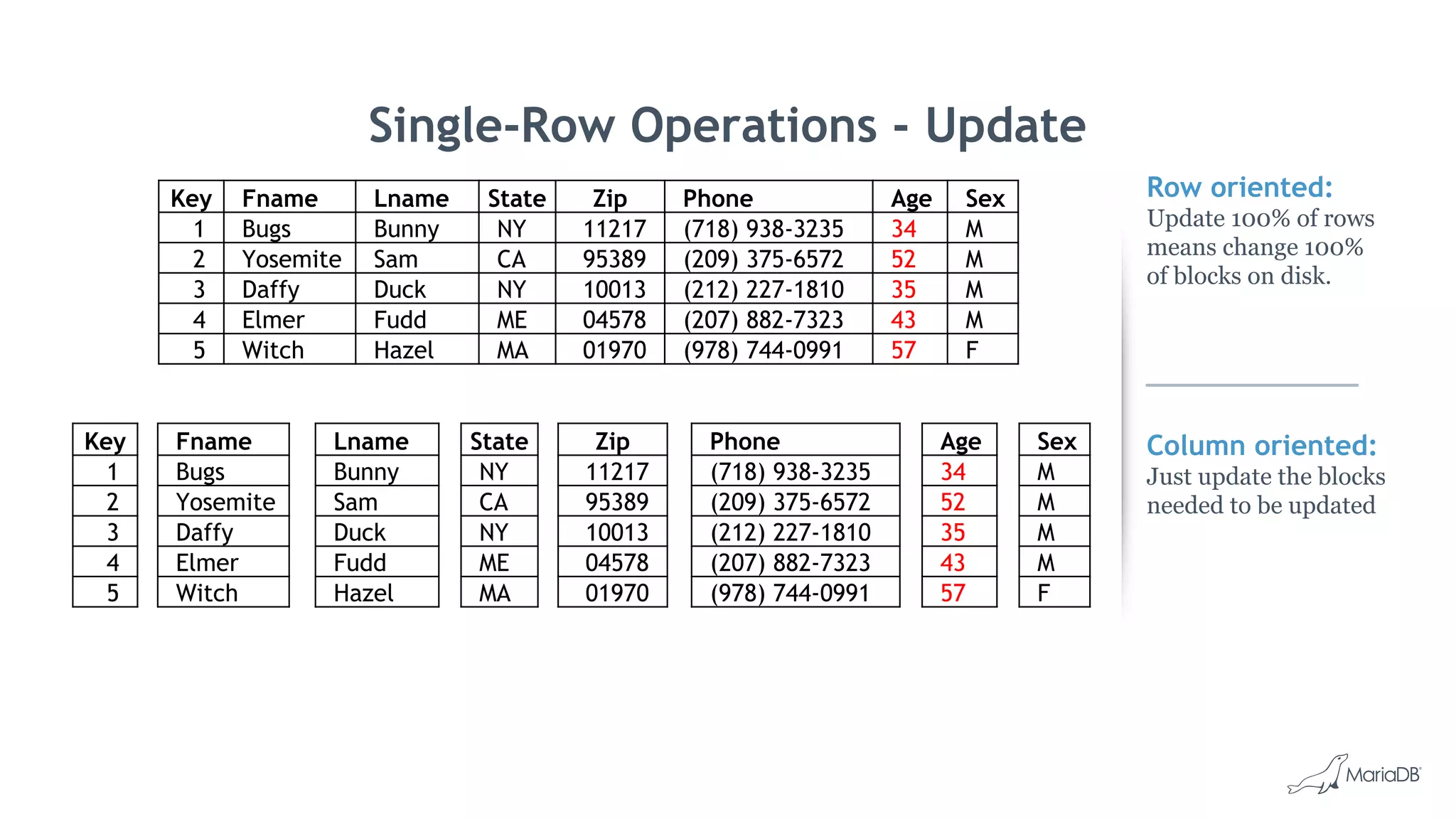
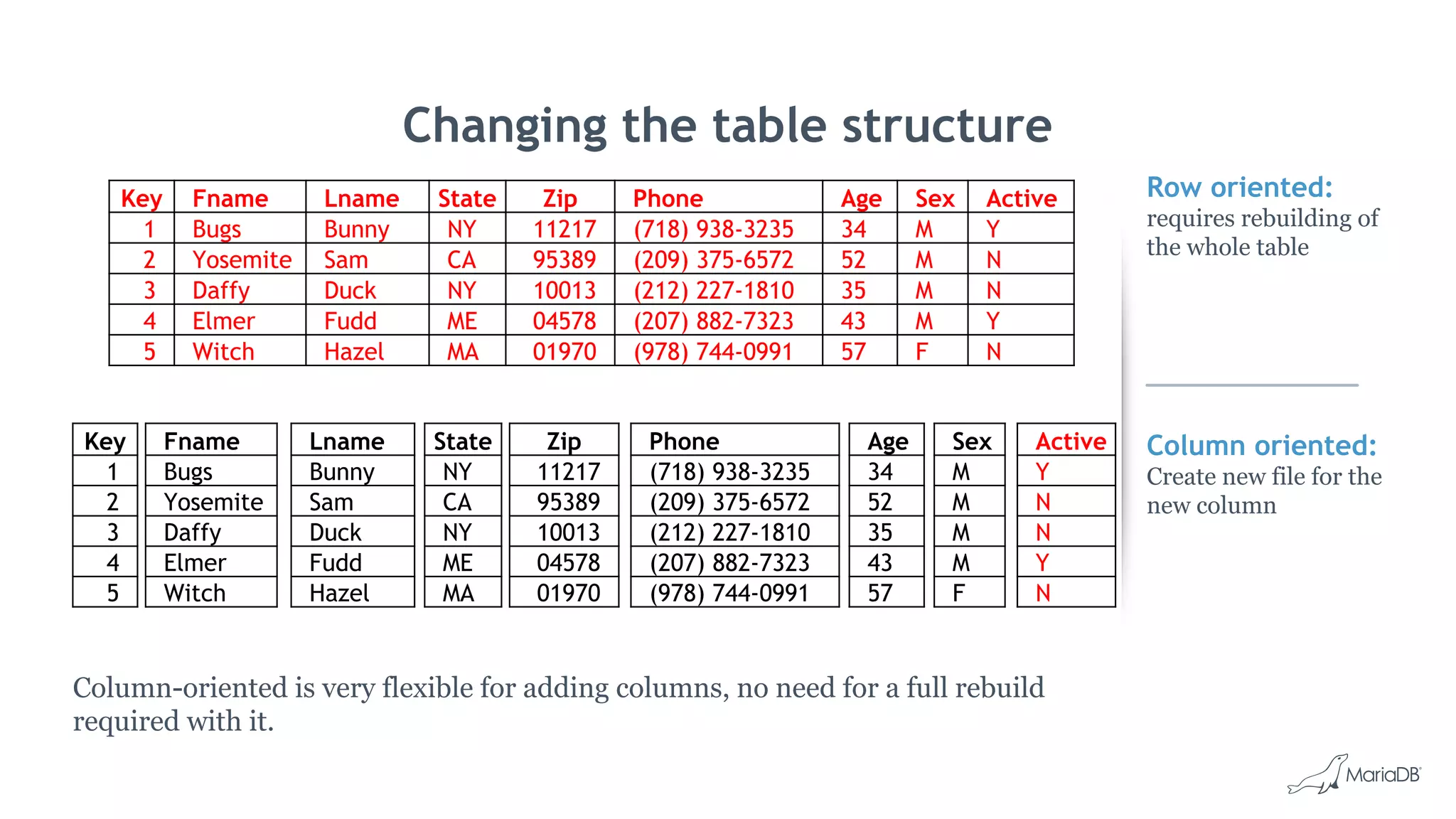
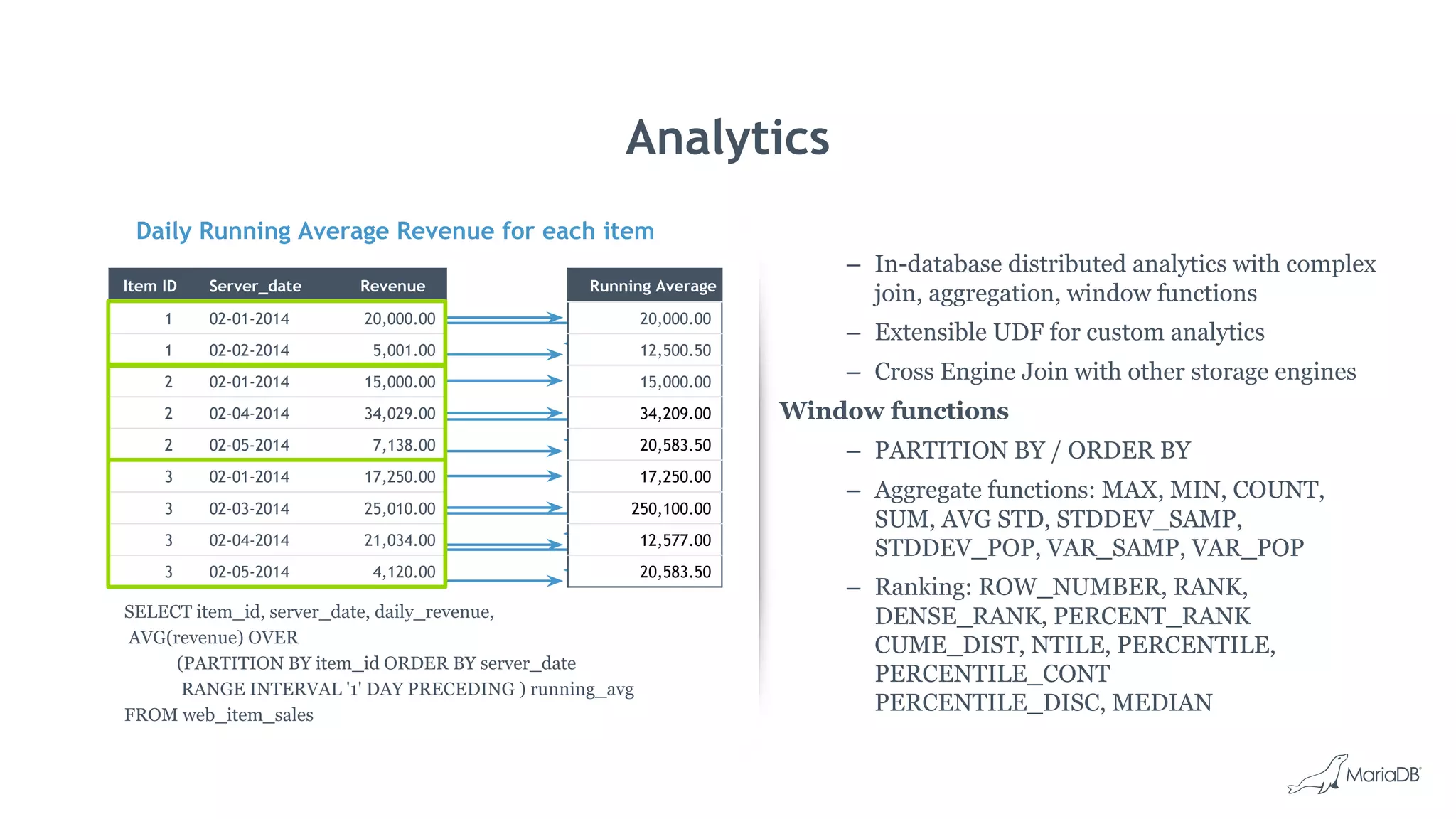

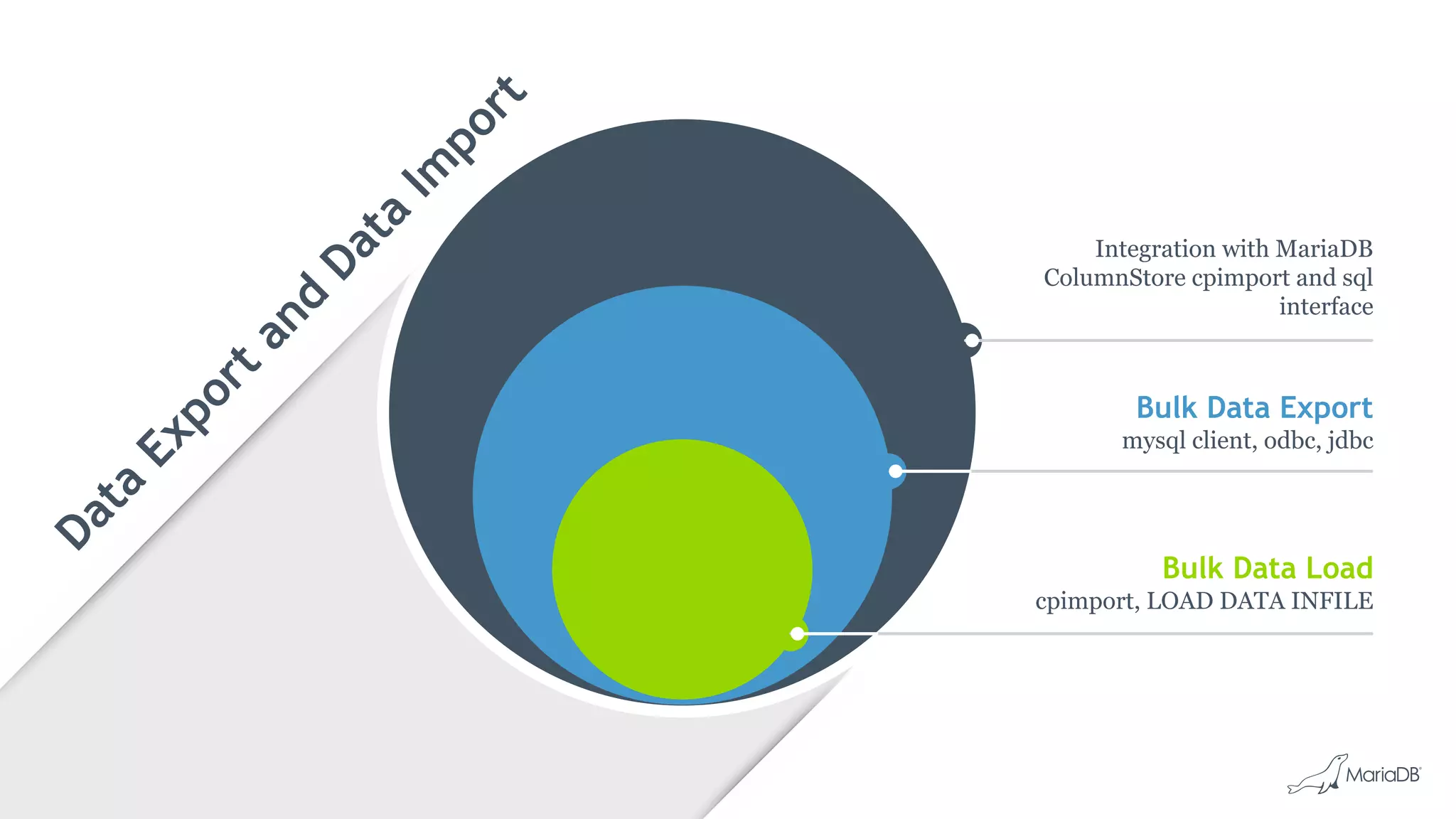
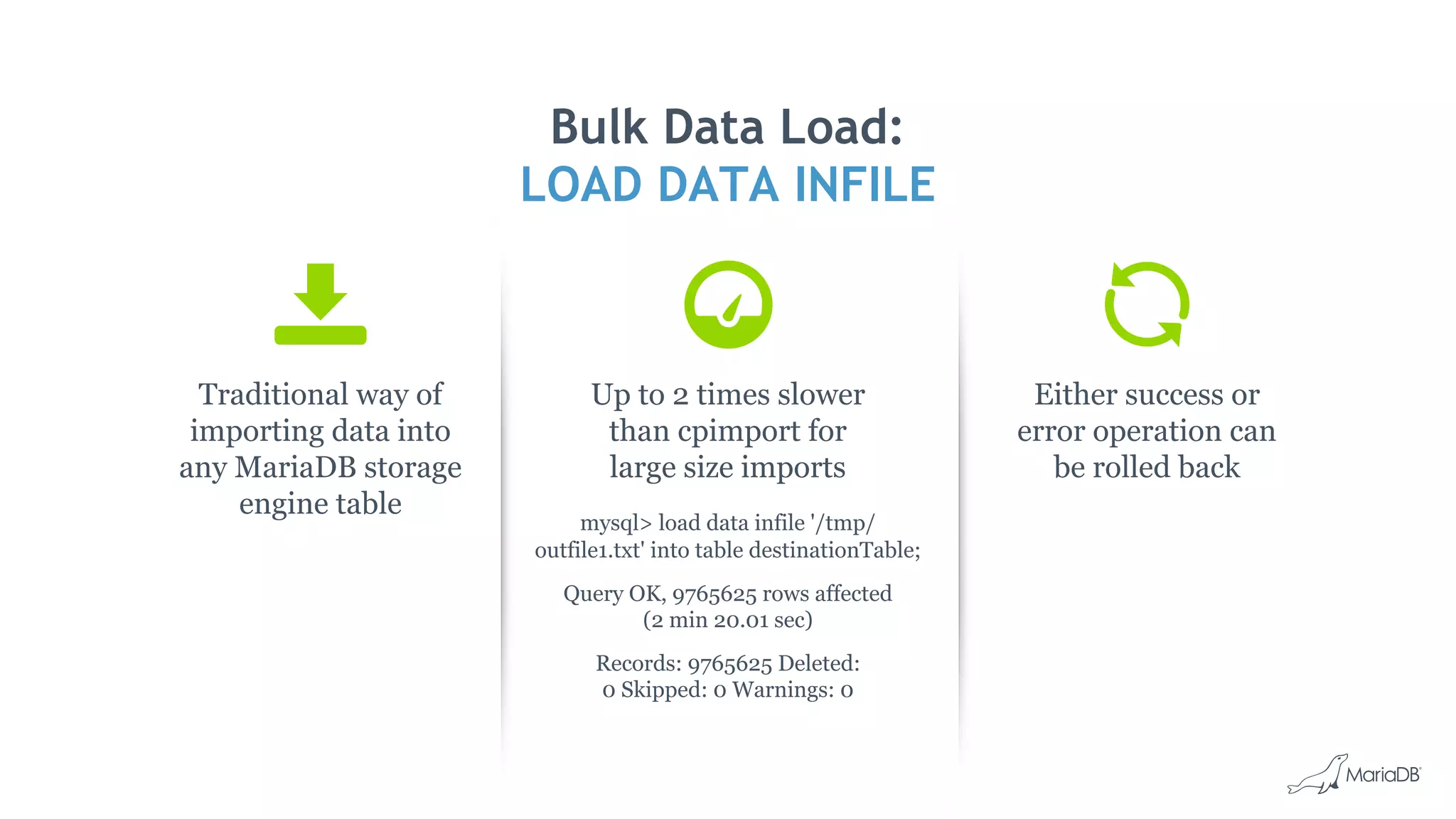
![Bulk Data Load: cpimport
• Fastest way to load data into MariaDB ColumnStore
• Load data from CSV file
cpimport dbName tblName [loadFile]
• Load data from Standard Input
mysql -e 'select * from source_table;' -N db2 | cpimport destination_db
destination_tbl -s 't‘
• Load data from Binary Source file
cpimport -I1 mydb mytable sourcefile.bin
• Multiple tables in can be loaded in parallel by launching multiple jobs
• Read queries continue without being blocked
• Successful cpimport is auto-committed
• In case of errors, entire load is rolled back](https://image.slidesharecdn.com/2017emearoadshowwienmariadbcolumnstore-171013063032/75/Big-Data-Analysen-mit-MariaDB-ColumnStore-24-2048.jpg)
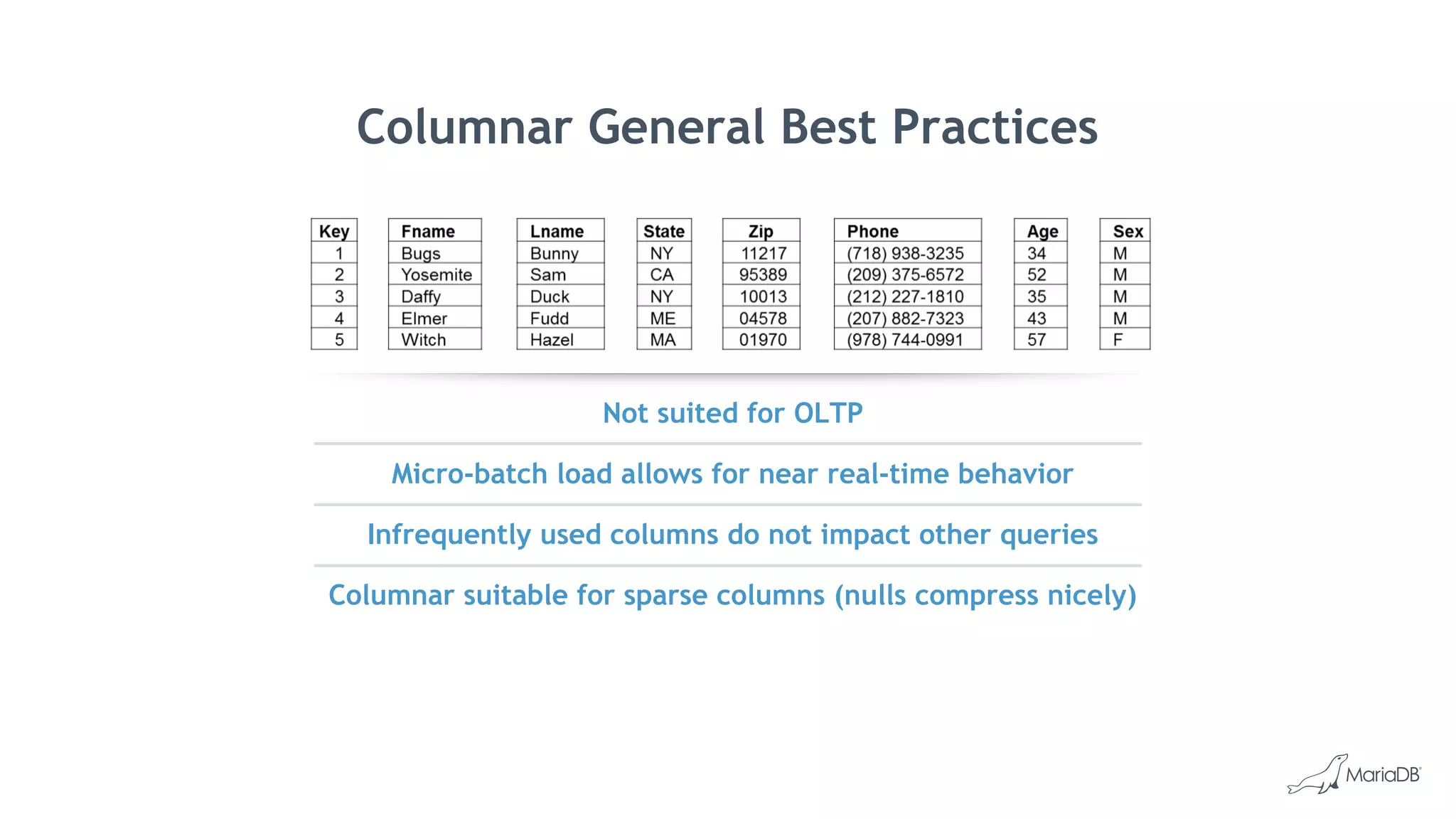







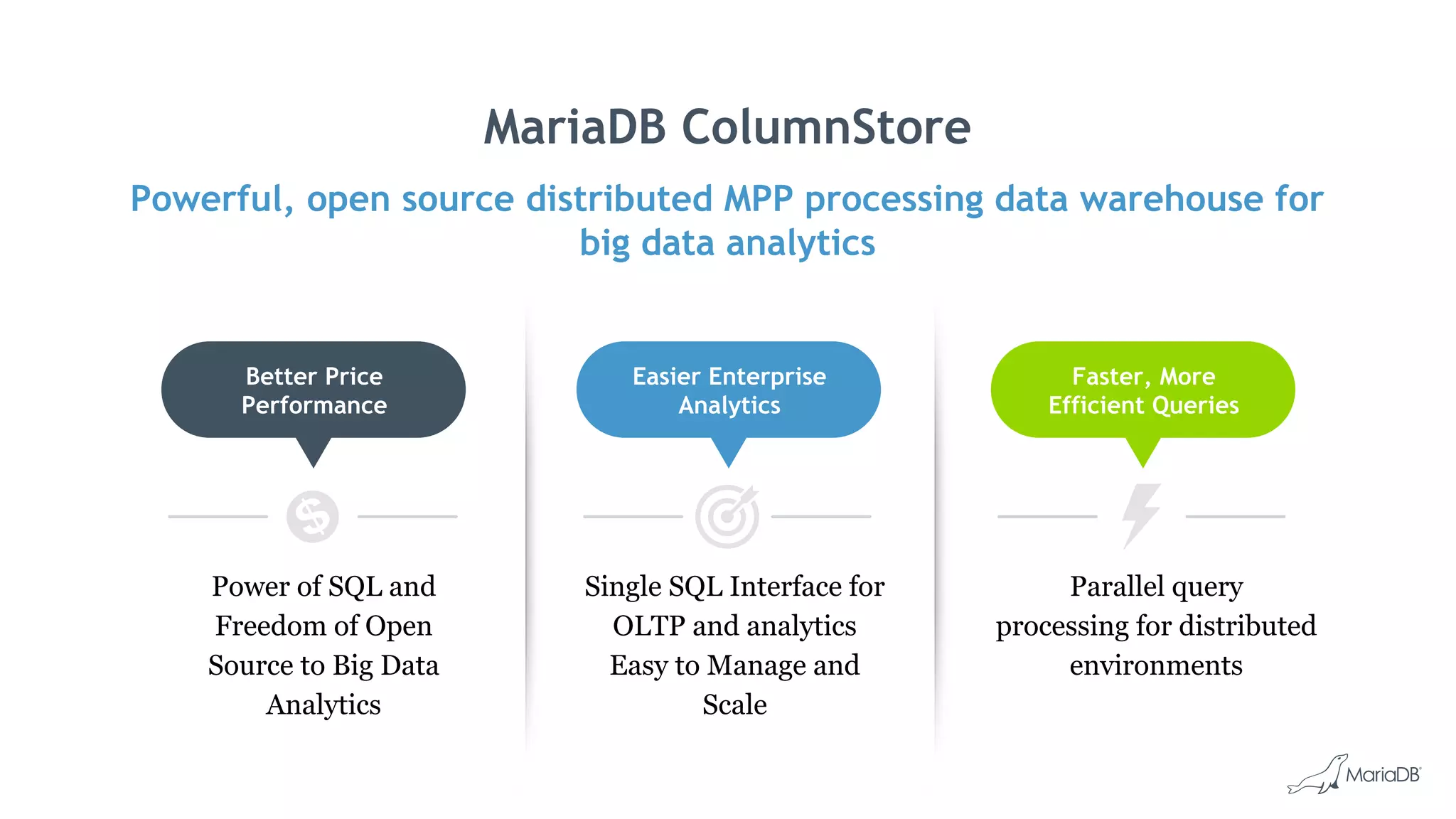
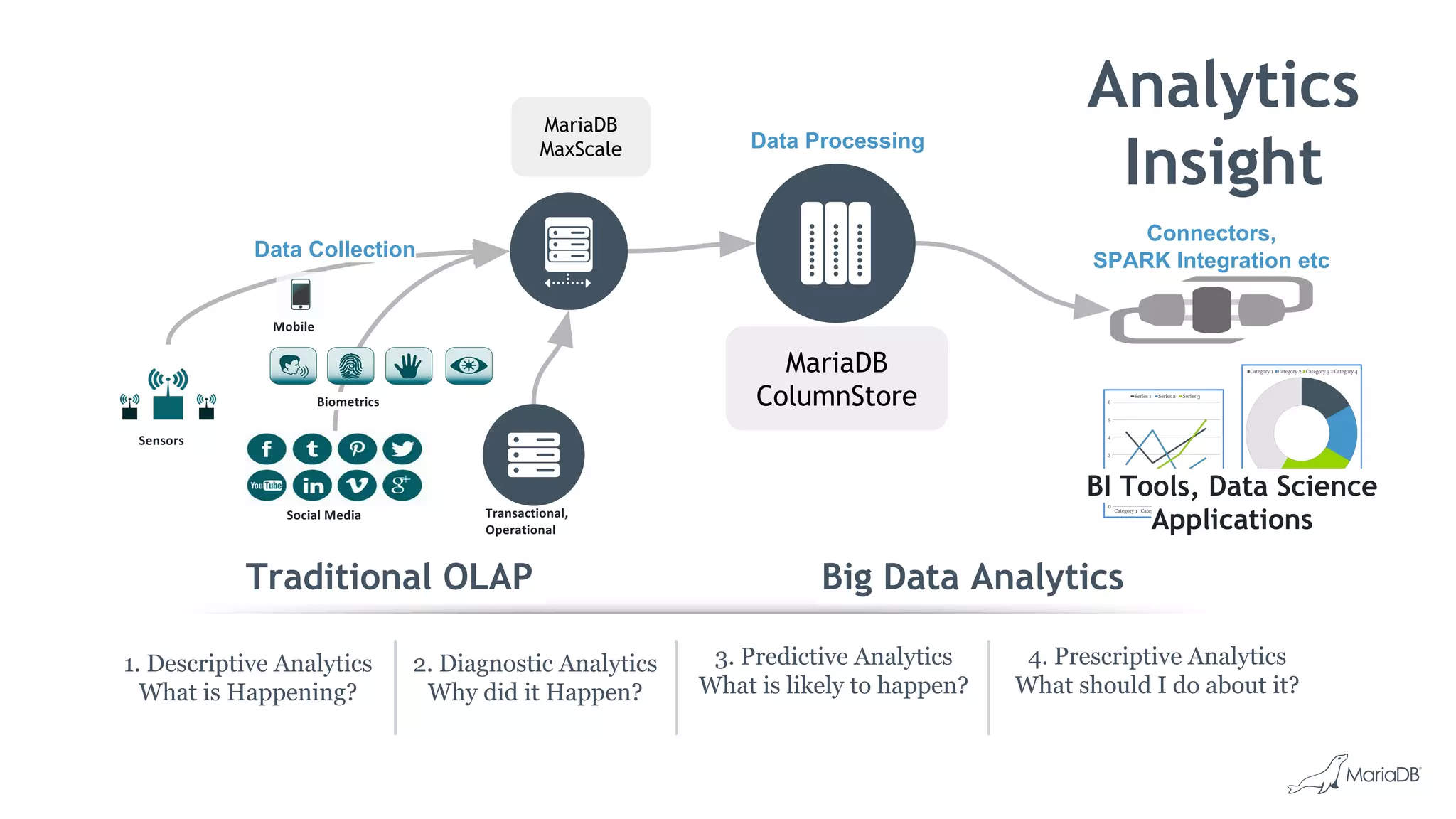
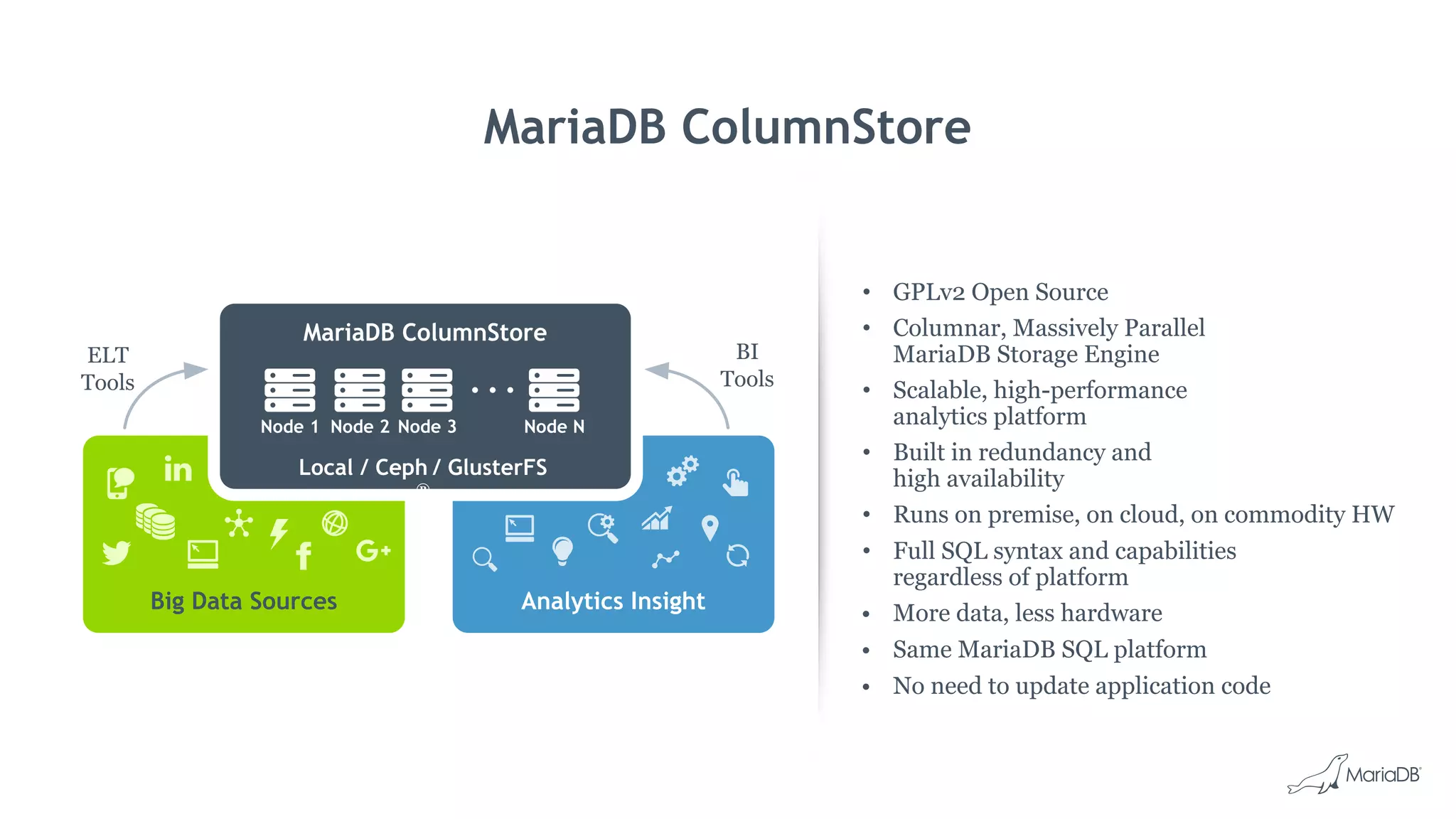
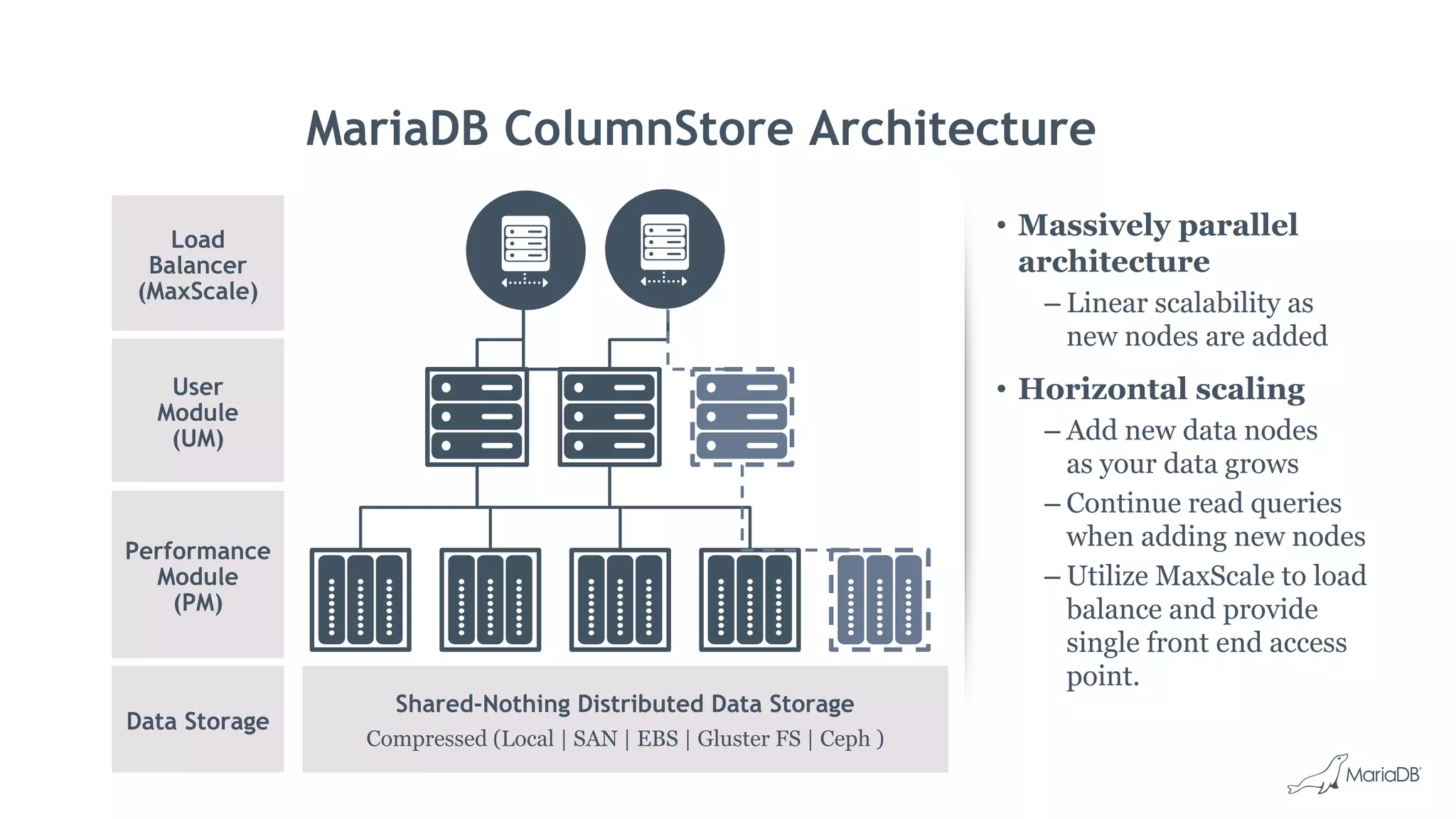
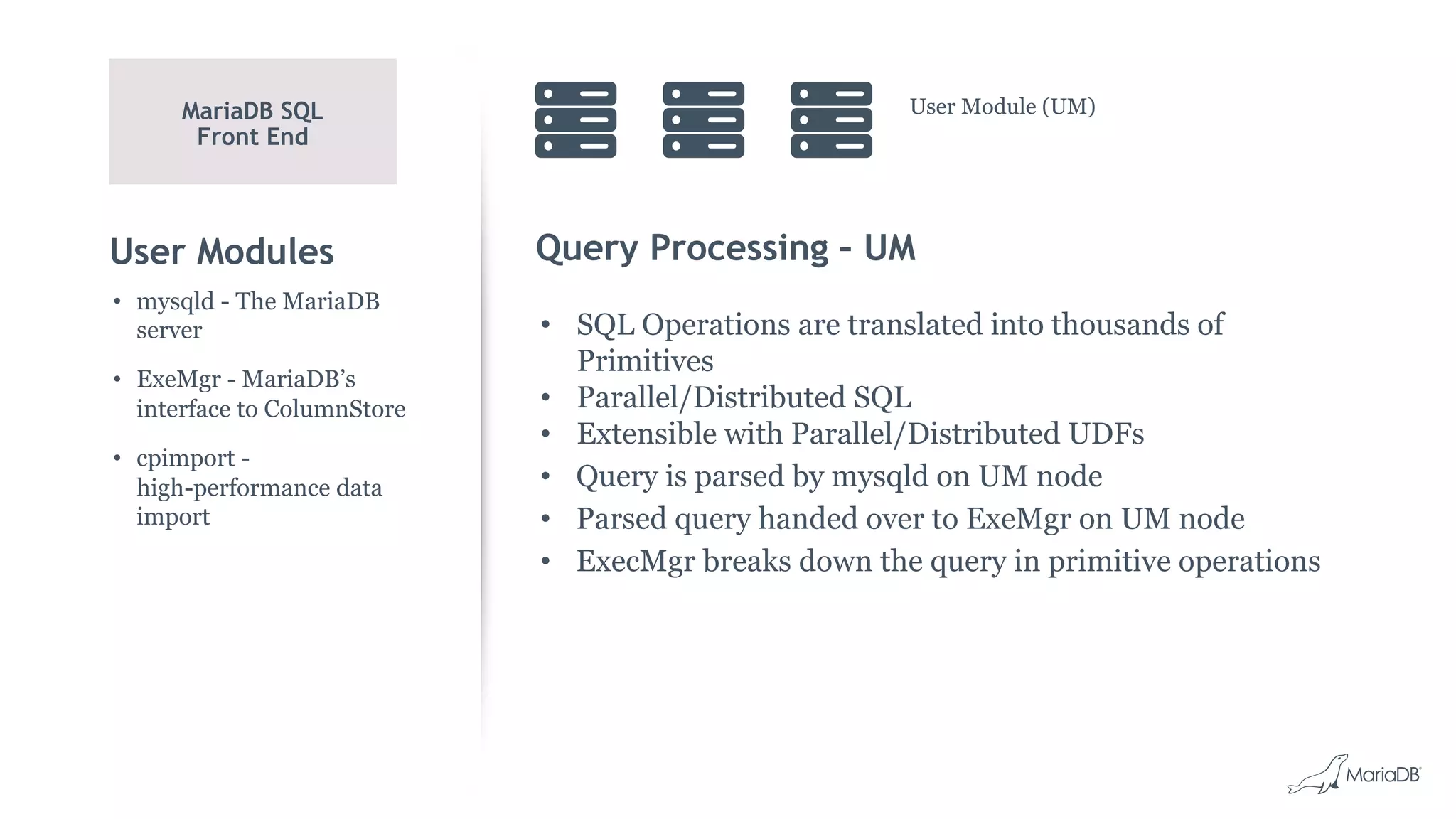
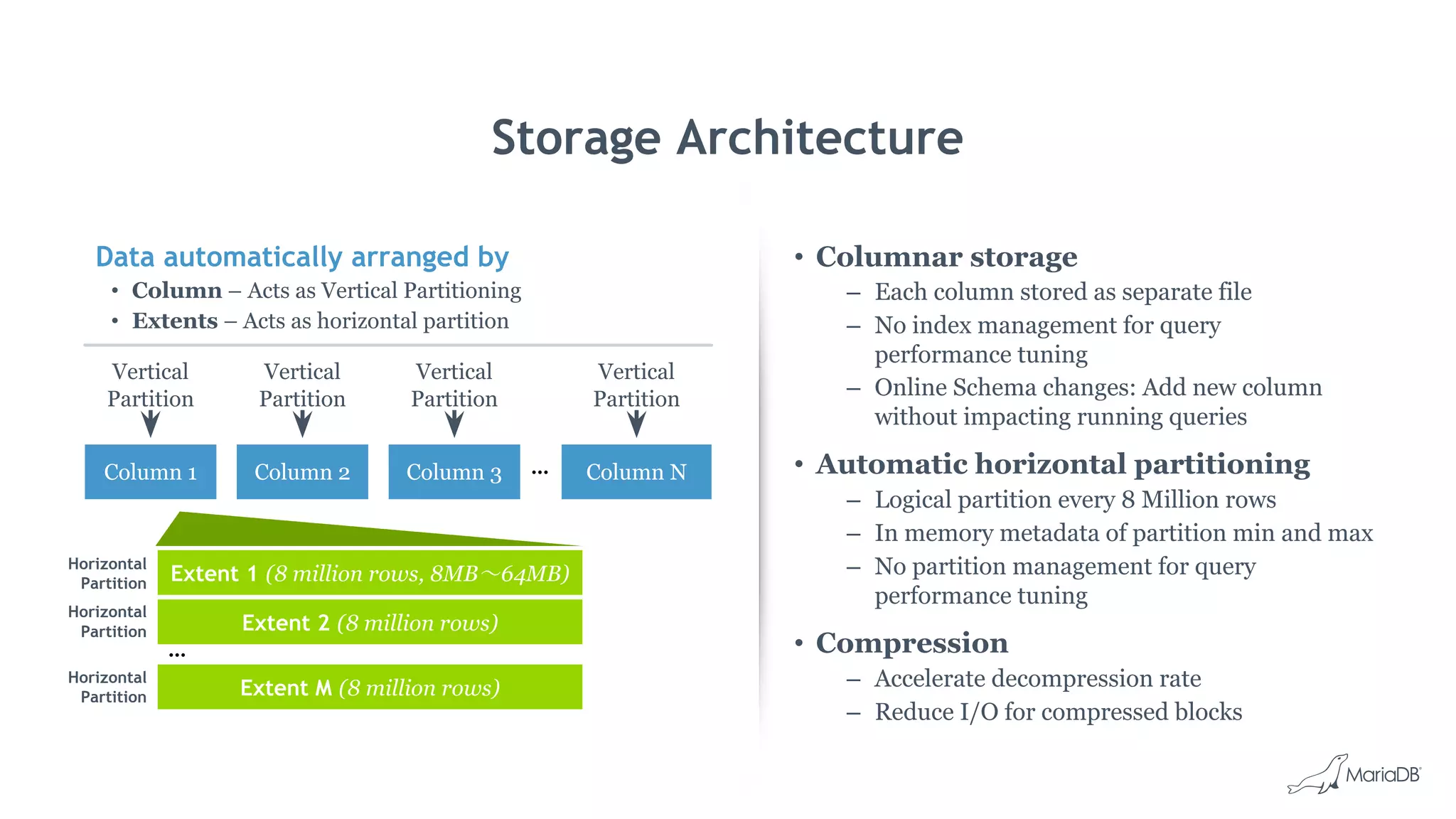
MariaDB ColumnStore is an open source distributed data warehouse that provides fast, efficient queries for big data analytics using a massively parallel processing architecture. It stores data in columns rather than rows to improve compression and allow filtering and aggregation of specific columns for analytical queries. ColumnStore allows for both transactional and analytical workloads on the same database using a single SQL interface and is easy to manage, scale and deploy on-premises or in the cloud.























![[db tech showcase OSS 2017] A25: Replacing Oracle Database at DBS Bank by Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628030047-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase OSS 2017] A23: Analytics with MariaDB ColumnStore by MariaD...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628024921-thumbnail.jpg?width=640&height=640&fit=bounds)










































