Future Work
・sequential densitymodel の選択によって状態空間上の距離が定義出来るか
・Solomonoff induction (Hutter, 2005) のような全域な確率密度モデルの解析
・sequential density modelとDQNにおけるQ-learningの学習速度があっていないの
で、密度モデルに忘却を導入するか、密度モデルとQ関数を対応が取れたものにす
る
・連続空間においてもpseusdo-count が回数の概念に合うかどうかの検証
35.
引用文献
Bellemare et al.(2016). Unifying Count-Based Exploration and Intrinsic Motivation. NIPS2016
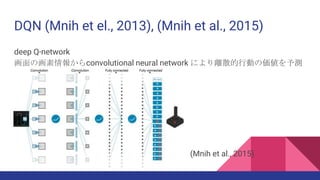
Mnih et al. (2013). Playing Atari with Deep Reinforcement Learning.
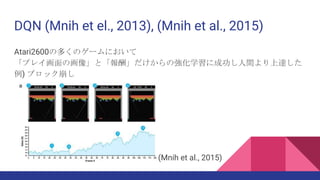
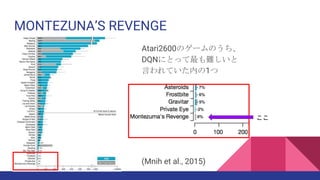
Mnih et al. (2015). Human-level control through deep reinforcement learning.
Nair et al. (2015). Massively Parallel Methods for Deep Reinforcement Learning.
van Hasselt et al. (2015). Deep Reinforcement Learning with Double Q-learning.
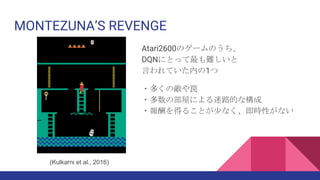
Kulkarni et al. (2016). Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and
Intrinsic Motivation. NIPS2016
Bellemare et al. (2014). Skip Context Tree Switching. 31st ICML
36.
引用文献
van Hasselt etal. (2015). Double Q-learning. NIPS2010
Machado et al. (2014). Domain-independent optimistic initialization for reinforcement learning.
arxiv:1410.4604
Mnih et al. (2016). Asynchronous methods for deep reinforcement learning. arXiv:1602.01783
Strehl and Littman. (2008). An analysis of model-based interval estimation for Markov desicion process.
Journal of Computer Science, 74(8):1309 - 1331.
Kolter and Ng. (2009). Near-bayesian exploration in polynominal time. 26th ICML
Shumidhuber. (2008). Driven by compression progress.
37.
引用文献
Bellemare et al.(2013). The Arcade Learning Environment: An evaluation platform for general agents.
Journal of Artificial Intelligence Research, 47: 253-279
Hutter (2005). Universal artificial intelligence: Sequential decisions based on algorithmic probability.
Springer





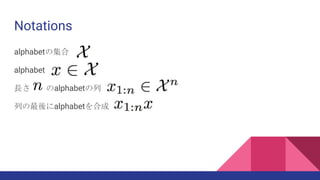












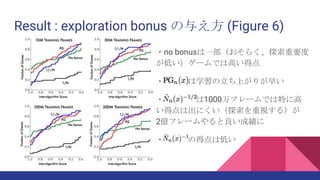
![exploration bonus with pseudo-count
以下の式(6)によるexploration bonusを与える
係数は0.05を使用
+0.01は安定化のため
この値は、今回のDQNでは報酬を[-1, +1]に限定しているため
正規化の必要はなし](https://image.slidesharecdn.com/unifyingcount-basedexplorationandintrinsicmotivation-160925153844/85/Unifying-count-based-exploration-and-intrinsic-motivation-22-320.jpg)













![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/model-basedreinforcementlearningviameta-policyoptimization-190705000247-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neuroscience-Inspired Artificial Intelligence](https://cdn.slidesharecdn.com/ss_thumbnails/dl201807133-180723071605-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)


