Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
JY
Uploaded by
Junko Yamada
PPTX, PDF
8,832 views
T検定と相関分析概要
北海道大学 2016年度 行動科学実験実習資料 (※学部生向け授業、スライド中の統計値などは適当)
Education
◦
Related topics:
T-Test Overview
•
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 33 times
1
/ 42
2
/ 42
3
/ 42
4
/ 42
5
/ 42
6
/ 42
7
/ 42
8
/ 42
9
/ 42
10
/ 42
11
/ 42
12
/ 42
13
/ 42
14
/ 42
15
/ 42
16
/ 42
Most read
17
/ 42
18
/ 42
19
/ 42
Most read
20
/ 42
21
/ 42
22
/ 42
23
/ 42
24
/ 42
25
/ 42
26
/ 42
27
/ 42
28
/ 42
29
/ 42
30
/ 42
31
/ 42
32
/ 42
33
/ 42
34
/ 42
35
/ 42
36
/ 42
37
/ 42
38
/ 42
39
/ 42
40
/ 42
41
/ 42
42
/ 42
Most read
More Related Content
PPTX
統計的検定と例数設計の基礎
by
Senshu University
PDF
Granger因果による 時系列データの因果推定(因果フェス2015)
by
Takashi J OZAKI
PDF
金融×AIで解くべき問題は何か?
by
Tsunehiko Nagayama
PPTX
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
by
西岡 賢一郎
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PDF
分析のビジネス展開を考える―状態空間モデルを例に @TokyoWebMining #47
by
horihorio
PDF
統計的因果推論勉強会 第1回
by
Hikaru GOTO
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
統計的検定と例数設計の基礎
by
Senshu University
Granger因果による 時系列データの因果推定(因果フェス2015)
by
Takashi J OZAKI
金融×AIで解くべき問題は何か?
by
Tsunehiko Nagayama
協力ゲーム理論でXAI (説明可能なAI) を目指すSHAP (Shapley Additive exPlanation)
by
西岡 賢一郎
一般化線形混合モデル入門の入門
by
Yu Tamura
分析のビジネス展開を考える―状態空間モデルを例に @TokyoWebMining #47
by
horihorio
統計的因果推論勉強会 第1回
by
Hikaru GOTO
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
by
Ken'ichi Matsui
What's hot
PDF
研究発表のためのプレゼンテーション技術
by
Shinnosuke Takamichi
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
Pythonではじめるロケーションデータ解析
by
Hiroaki Sengoku
PDF
推薦アルゴリズムの今までとこれから
by
cyberagent
PDF
R Markdownによるドキュメント生成と バージョン管理入門
by
nocchi_airport
PDF
工学系大学4年生のための論文の読み方
by
ychtanaka
PDF
研究分野をサーベイする
by
Takayuki Itoh
PPTX
画像キャプションの自動生成
by
Yoshitaka Ushiku
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
PDF
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
PDF
臨床疫学研究における傾向スコア分析の使い⽅ 〜観察研究における治療効果研究〜
by
Yasuyuki Okumura
PDF
状態空間モデルの考え方・使い方 - TokyoR #38
by
horihorio
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
5 クラスタリングと異常検出
by
Seiichi Uchida
PDF
Statistical Semantic入門 ~分布仮説からword2vecまで~
by
Yuya Unno
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
非ガウス性を利用した 因果構造探索
by
Shiga University, RIKEN
PDF
Visualizing Data Using t-SNE
by
Tomoki Hayashi
研究発表のためのプレゼンテーション技術
by
Shinnosuke Takamichi
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
Pythonではじめるロケーションデータ解析
by
Hiroaki Sengoku
推薦アルゴリズムの今までとこれから
by
cyberagent
R Markdownによるドキュメント生成と バージョン管理入門
by
nocchi_airport
工学系大学4年生のための論文の読み方
by
ychtanaka
研究分野をサーベイする
by
Takayuki Itoh
画像キャプションの自動生成
by
Yoshitaka Ushiku
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
臨床疫学研究における傾向スコア分析の使い⽅ 〜観察研究における治療効果研究〜
by
Yasuyuki Okumura
状態空間モデルの考え方・使い方 - TokyoR #38
by
horihorio
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
5 クラスタリングと異常検出
by
Seiichi Uchida
Statistical Semantic入門 ~分布仮説からword2vecまで~
by
Yuya Unno
2 3.GLMの基礎
by
logics-of-blue
非ガウス性を利用した 因果構造探索
by
Shiga University, RIKEN
Visualizing Data Using t-SNE
by
Tomoki Hayashi
Viewers also liked
PDF
1 3.分散分析 anova
by
logics-of-blue
PDF
1 2.t検定
by
logics-of-blue
PDF
ランダムフォレスト
by
Kinki University
PDF
1 1.はじめに
by
logics-of-blue
PDF
エニグマ暗号とは何だったのか
by
Takahiro (Poly) Horikawa
PDF
「生物統計学」演習問題集
by
Keiji Miura
ODP
第4回関東ゼロからはじめるR言語勉強会(t検定を勉強してみよう)
by
Iida Keisuke
PPTX
第三回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
3.9 - same sport, different school
by
Vasili K Andrews
PPTX
Creative activities week 2
by
HCEfareham
PPTX
Horror themes:narratives
by
Hussnia Wali
PPTX
Historia de la tegnologia arquitectura maya
by
'Gene Cardenas
DOCX
基本統計量について
by
wada, kazumi
PDF
2013年度秋学期 統計学 第13回「不確かな測定の不確かさを測る ― 不偏分散とt分布」
by
Akira Asano
PDF
New World of Work
by
Albert Esplugas
PDF
胃と腸10月号2011
by
Sakata Masatoshi
PPTX
Tokyo r30 anova
by
Takashi Minoda
PPTX
R in life science2
by
Yoshiki Tomita
PDF
עיצוב ויזואלי של מידע ליזי כהן שיעור 2
by
lizicohen
PPTX
Risk assessment
by
Hussnia Wali
1 3.分散分析 anova
by
logics-of-blue
1 2.t検定
by
logics-of-blue
ランダムフォレスト
by
Kinki University
1 1.はじめに
by
logics-of-blue
エニグマ暗号とは何だったのか
by
Takahiro (Poly) Horikawa
「生物統計学」演習問題集
by
Keiji Miura
第4回関東ゼロからはじめるR言語勉強会(t検定を勉強してみよう)
by
Iida Keisuke
第三回統計学勉強会@東大駒場
by
Daisuke Yoneoka
3.9 - same sport, different school
by
Vasili K Andrews
Creative activities week 2
by
HCEfareham
Horror themes:narratives
by
Hussnia Wali
Historia de la tegnologia arquitectura maya
by
'Gene Cardenas
基本統計量について
by
wada, kazumi
2013年度秋学期 統計学 第13回「不確かな測定の不確かさを測る ― 不偏分散とt分布」
by
Akira Asano
New World of Work
by
Albert Esplugas
胃と腸10月号2011
by
Sakata Masatoshi
Tokyo r30 anova
by
Takashi Minoda
R in life science2
by
Yoshiki Tomita
עיצוב ויזואלי של מידע ליזי כהן שיעור 2
by
lizicohen
Risk assessment
by
Hussnia Wali
Similar to T検定と相関分析概要
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PDF
傾向スコアの概念とその実践
by
Yasuyuki Okumura
PPTX
項目反応理論による尺度運用
by
Yoshitake Takebayashi
PDF
統計学における相関分析と仮説検定の基本的な考え方とその実践
by
id774
PDF
有意性と効果量について しっかり考えてみよう
by
Ken Urano
PDF
Analysis of clinical trials using sas 勉強用 isseing333
by
Issei Kurahashi
PPTX
生物系研究者のための統計講座
by
RIKEN, Medical Sciences Innovation Hub Program (MIH)
PPTX
Darm3(samplesize)
by
Yoshitake Takebayashi
PPTX
R言語による簡便な有意差の検出と信頼区間の構成
by
Toshiyuki Shimono
PDF
統計処理環境Rで学ぶ 言語研究のための統計入門
by
corpusling
PPTX
Rゼミ 3
by
tarokun3
PDF
R-study-tokyo02
by
Yohei Sato
PDF
第6章 2つの平均値を比較する - TokyoR #28
by
horihorio
PDF
統計的因果推論の理論と実践 ch9 交互作用項のある共分散分析
by
YasutoTerasawa
PPT
K090 仮説検定
by
t2tarumi
PDF
1 4
by
englishteacher_net
PPTX
What is a T-test?
by
YanoLabLT
PDF
2019年度春学期 統計学 第14回 分布についての仮説を検証するー検定 (2019. 7. 18)
by
Akira Asano
PDF
Eureka agora tech talk 20170829
by
Shinnosuke Ohkubo
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
傾向スコアの概念とその実践
by
Yasuyuki Okumura
項目反応理論による尺度運用
by
Yoshitake Takebayashi
統計学における相関分析と仮説検定の基本的な考え方とその実践
by
id774
有意性と効果量について しっかり考えてみよう
by
Ken Urano
Analysis of clinical trials using sas 勉強用 isseing333
by
Issei Kurahashi
生物系研究者のための統計講座
by
RIKEN, Medical Sciences Innovation Hub Program (MIH)
Darm3(samplesize)
by
Yoshitake Takebayashi
R言語による簡便な有意差の検出と信頼区間の構成
by
Toshiyuki Shimono
統計処理環境Rで学ぶ 言語研究のための統計入門
by
corpusling
Rゼミ 3
by
tarokun3
R-study-tokyo02
by
Yohei Sato
第6章 2つの平均値を比較する - TokyoR #28
by
horihorio
統計的因果推論の理論と実践 ch9 交互作用項のある共分散分析
by
YasutoTerasawa
K090 仮説検定
by
t2tarumi
1 4
by
englishteacher_net
What is a T-test?
by
YanoLabLT
2019年度春学期 統計学 第14回 分布についての仮説を検証するー検定 (2019. 7. 18)
by
Akira Asano
Eureka agora tech talk 20170829
by
Shinnosuke Ohkubo
T検定と相関分析概要
1.
2016年度 行動科学実験実習 ―t 検定と相関分析― 2016年10月31日 北海道大学
行動科学実験実習(第1ターム) 担当:山田(TF) 1
2.
有意性検定について ちょっとおさらい 2
3.
統計=法則性の数量的な表現 • ある現象についての傾向や関係を、数値を用い て表現する • 数値を用いることで「程度」が分かる! この間のTOEIC かなりできた! この間のTOEIC 850点だった! •
85%正答した! • TOEIC受験者の平均 点より高く、上位 10%に入っている! • “かなり”ってどの位? • 例えばほかの人と比 べてどのくらい良く できた? 比較可能! 3
4.
有意性検定とは • 有意性検定 • 帰無仮説
(H0) と対立仮説 (H1) 否定したい仮説 検証したい仮説 4
5.
“有意である”とは? • 有意確率 (p)=正しいはずの帰無仮説を棄却す る確率 •
H0: A大学とB大学のTOEICスコアに差はない • H1: A大学とB大学のTOEICスコアに差がある • p < .05 で、A大学とB大学のスコアに有意差あり → H0が正しいにも関わらず棄却する可能性は5% TOEICスコア 700点 TOEICスコア 550点 5
6.
t 検定 (t
- Test) ―集団の平均の違いを検討 6
7.
t 検定とは? • その平均値の差は偶然の誤差範囲か? •
同じ集団 (例:日本人) であっても、そのデータに は散らばり (誤差) が存在する • 例:平均身長 • ある集団の中にも、身長はさまざま • たまたま持ってきた標本集団が、実際の母平均より も高い (低い) 方に偏ることはしばしばある 7
8.
誤差を数値化する • t 値 •
2つの集団の平均値がどのくらいずれているかを数 値化する示標 • 平均の標準誤差で割る=標準化 → 平均0, 分散1の正規分布をとるように値を変換 8 集団Aの平均 集団Bの平均 平均の標準誤差 BA BA XX BA XX XX t
9.
t 検定=t 値のズレは偶然か? •
t 値=2つの集団の平均値のズレ • 集団A, Bの平均値のズレは、単なる偶然なのか、あ るいは意味のある違いなのか? 90 + t- t
10.
意味のない誤差を見分ける • 集団Aと集団Bが等しい (=同じ母集団)
場合… • 2つの集団A, Bの違いは単なる偶然に過ぎない 100 + t- t 2つの集団が等しいなら、 t 値は95%この範囲に収まる
11.
何%なら“意味がある”? • 有意確率 (5%) •
集団A, Bの平均値がズレる確率は5%以下 110 両側
12.
何%なら“意味がある” ? • 有意確率
(5%) • 両側検定:差の方向が未定 • 片側検定:差の方向を予測済み 120 片側
13.
具体例 13 誰かと一緒にいる人の方が、 沢山寄付してくれる気がする…
14.
具体例 • H0(帰無仮説) • 誰かと一緒にいても寄付額は変わらない •
H1(対立仮説) • 誰かと一緒にいると寄付額が増える • 片側測定 • 実験計画 • 友人と一緒にいる人、または一人でいる人を対象に 募金活動を行う (参加者間要因) 14
15.
具体例 • 誰かと一緒にいる人 (N
= 15) • 平均寄付額 800円, SD = 34.56 • 一人でいる人 (N = 15) • 平均寄付額 500円, SD = 21.03 • 条件を独立変数, 寄付額を従属変数とした t 検 定を行った結果… t (28) = 3.59, p =.02 15 標準化した 集団間の平均のズレ BA BA XX BA XX XX t 条件 (他者あり・なし) 𝑑𝑓 = 𝑛1 − 1 + 𝑛2 − 1
16.
レポートでの書き方 16 誰かと一緒にいる条件 (M =
800, SD = 34.56) と一人の 条件 (M = 500, SD = 21.03) で寄付額が増加するかを検 証するため、他者が傍にいるかを独立変数、寄付額を従 属変数とする対応のない t 検定を行ったところ、有意差 がみられた (t (28) = 3.59, p = .02)。 このことから、誰かと一緒にいる方が、一人の時よりも 有意に寄付額が多いことが分かった。
17.
レポートでの書き方 17 誰かと一緒にいる条件 (M =
800, SD = 34.56) と一人の 条件 (M = 500, SD = 21.03) で寄付額が増加するかを検 証するため、他者が傍にいるかを独立変数、寄付額を従 属変数とする対応のない t 検定を行ったところ、有意差 がみられた (t (28) = 3.59, p = .02)。 このことから、誰かと一緒にいる方が、一人の時よりも 有意に寄付額が多いことが分かった。 ポイント① 記述統計量を含め、統計量はきっちり書く
18.
レポートでの書き方 18 誰かと一緒にいる条件 (M =
800, SD = 34.56) と一人の 条件 (M = 500, SD = 21.03) で寄付額が増加するかを検 証するため、他者が傍にいるかを独立変数、寄付額を従 属変数とする対応のない t 検定を行ったところ、有意差 がみられた (t (28) = 3.59, p = .02)。 このことから、誰かと一緒にいる方が、一人の時よりも 有意に寄付額が多いことが分かった。 ポイント② 分析の目的、独立変数と従属変数を明確にする ポイント③ どんな検定を行ったかをしっかり明記する
19.
レポートでの書き方 19 誰かと一緒にいる条件 (M =
800, SD = 34.56) と一人の 条件 (M = 500, SD = 21.03) で寄付額が増加するかを検 証するため、他者が傍にいるかを独立変数、寄付額を従 属変数とする対応のない t 検定を行ったところ、有意差 がみられた (t (28) = 3.59, p = .02)。 このことから、誰かと一緒にいる方が、一人の時よりも 有意に寄付額が多いことが分かった。 ポイント➃ 結果の方向性を明確に示し、分かりやすく言い換える
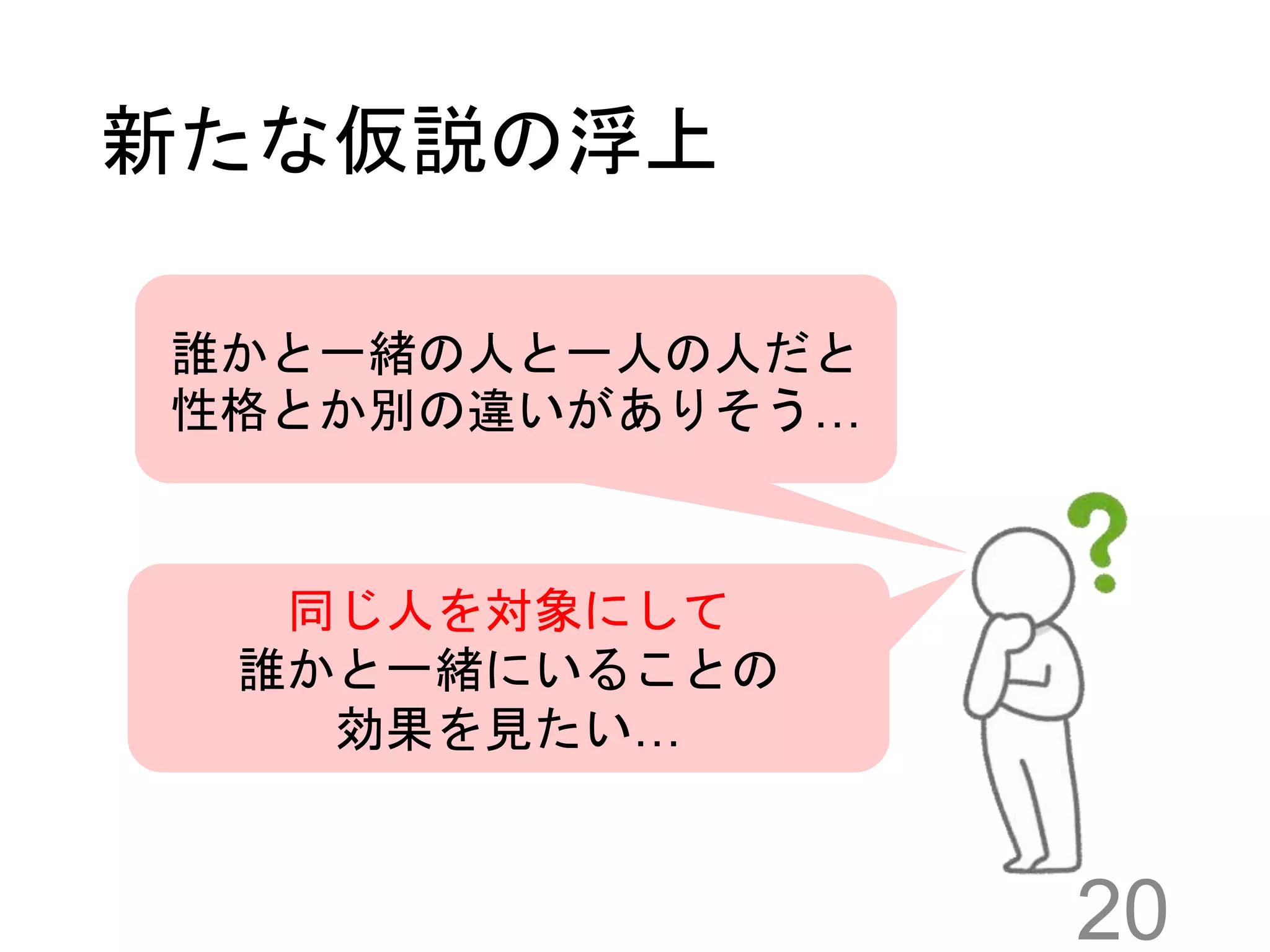
20.
新たな仮説の浮上 20 誰かと一緒の人と一人の人だと 性格とか別の違いがありそう… 同じ人を対象にして 誰かと一緒にいることの 効果を見たい…
21.
具体例 • H0(帰無仮説) • 誰かと一緒にいても募金額は変わらない •
H1(対立仮説) • 誰かと一緒にいると募金額が増える • 片側測定 • 実験計画 • 友人と一緒に寄付してもらう条件と、一人で寄付し てもらう条件を作り、同じ人でも条件間で寄付額に 差が出るかを検証する (参加者内要因) 21
22.
具体例 • 参加者は計15名 • 誰かと一緒にいる条件 •
平均寄付額 900円, SD = 87.56 • 一人でいる条件 • 平均寄付額 650円, SD = 37.03 22 対応無しのt検定を そのままやればOK?
23.
対応のあるデータ=ペア • 対応のないデータでは平均の差をとった • 対応のあるデータでは…? •
対応するデータをペアにして、ペアごとに各条 件下でのデータの差分をとる 23 D D tD 各ペア内の得点差の平均 標準誤差でスコアを標準化
24.
具体例 • 誰かと一緒にいる条件 • 平均寄付額
900円, SD = 87.56 • 一人でいる条件 • 平均寄付額 650円, SD = 37.03 • 条件を独立変数, 寄付額を従属変数とした t 検 定を行った結果… t (14) = 2.95, p = .01 24 𝑑𝑓 = 𝑛 − 1 (n = サンプルサイズ)
25.
レポートでの書き方 25 誰かと一緒にいる条件 (M =
900, SD = 87.56) と一人の 条件 (M = 650, SD = 37.37) で寄付額が増加するかを検 証するため、他者が傍にいるかを独立変数、寄付額を従 属変数とする対応のある t 検定を行ったところ、有意差 がみられた (t (14) = 9.95, p = .01)。 このことから、誰かと一緒にいる方が、一人の時よりも 有意に寄付額が高いことが分かった。
26.
ちなみに… • もし有意差がなかった場合… 26 誰かと一緒にいる条件 (M
= 900, SD = 87.56) と一人の 条件 (M = 650, SD = 37.37) で寄付額が増加するかを検 証するため、他者が傍にいるかを独立変数、寄付額を従 属変数とする対応のある t 検定を行ったところ、有意差 がみられた (t (14) = 9.95, p = ns.)。 このことから、誰かと一緒にいる方が、一人の時よりも 有意に寄付額が高いことが分かった。 Non significant (有意ではない)の略
27.
対応あり or なし? 27 •
検定力 • H0 が誤りであることを正しく棄却できる確率 → 正しく有意差を検出できる確率 • 検定力=1 − 𝛽 • 第1種のエラー (α):差がないのに見誤る確率 • 第2種のエラー (β):差があるのに見過ごす確率 対応ありデータは第2種のエラーを回避できる! → 検定力が高い!
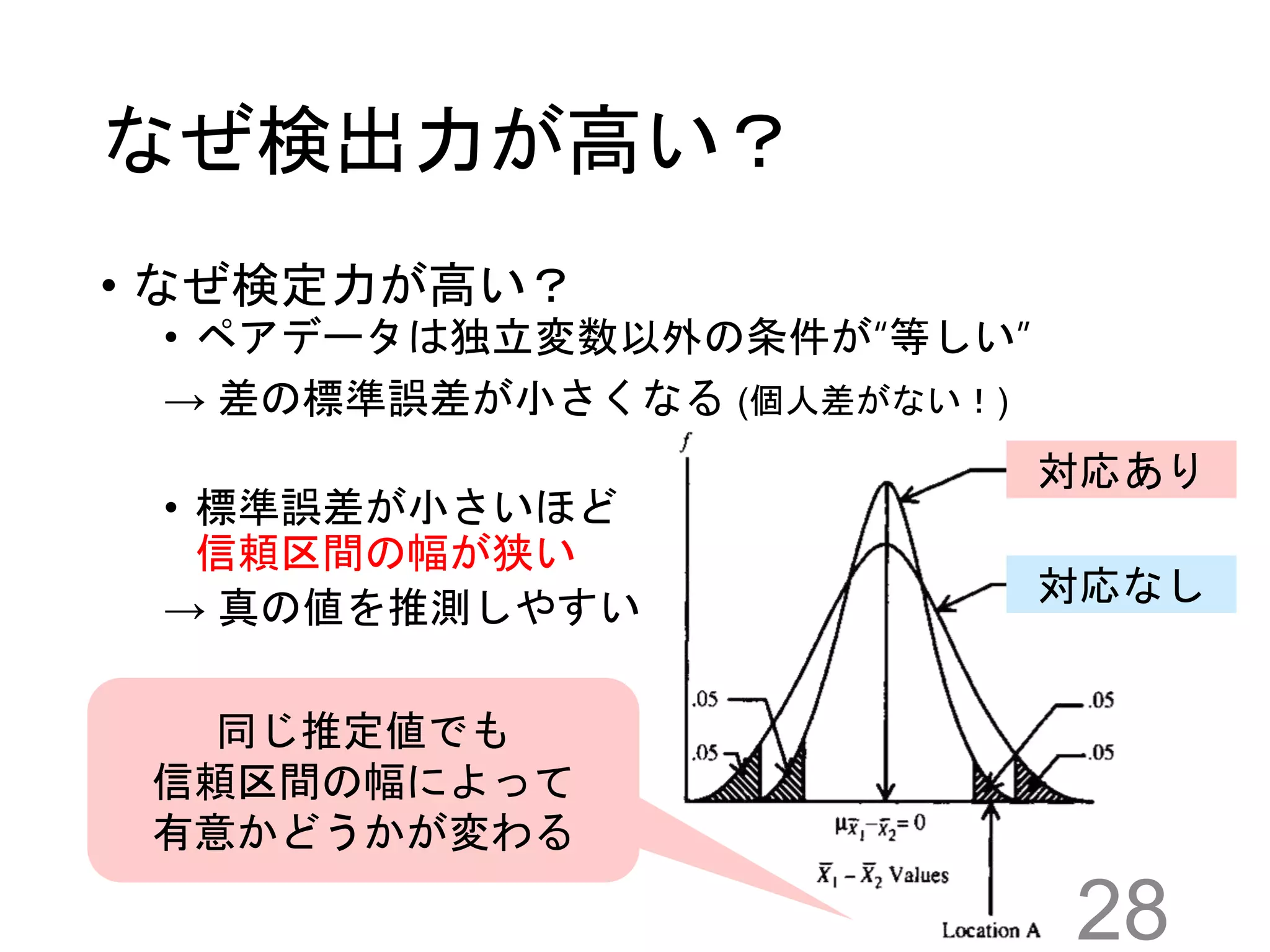
28.
なぜ検出力が高い? • なぜ検定力が高い? • ペアデータは独立変数以外の条件が“等しい” →
差の標準誤差が小さくなる (個人差がない!) • 標準誤差が小さいほど 信頼区間の幅が狭い → 真の値を推測しやすい 28 対応あり 対応なし 同じ推定値でも 信頼区間の幅によって 有意かどうかが変わる
29.
対応あり or なし? 29 •
対応ありデータの短所 • 順序効果が出やすい(同一参加者内) → 先にやった条件が 後の条件に影響する →疲労度、慣れ • 完全にマッチするペアの作成が困難(異なる参加者 間でのペア)
30.
相関分析 (Correlation analysis) 30
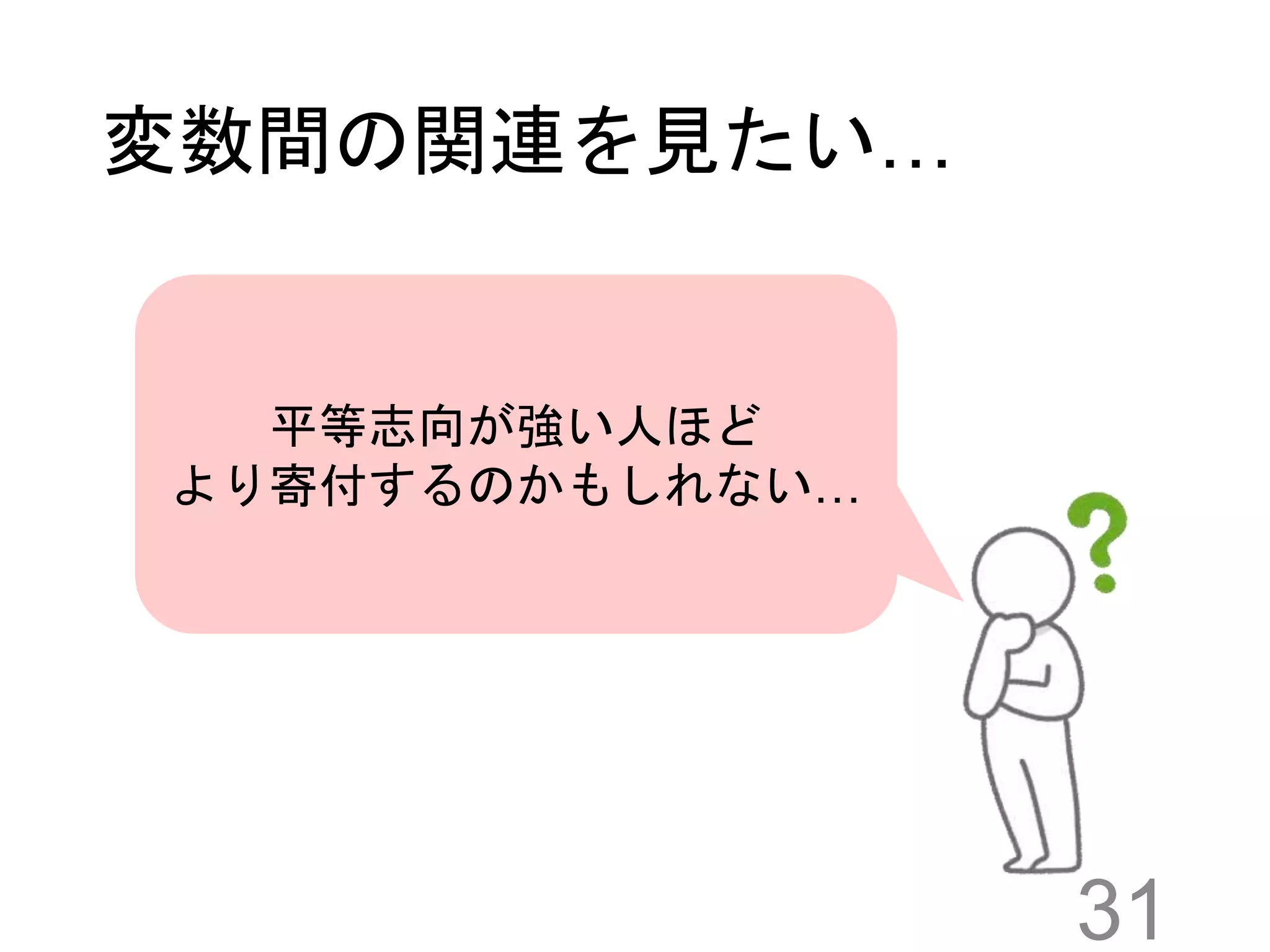
31.
変数間の関連を見たい… 31 平等志向が強い人ほど より寄付するのかもしれない…
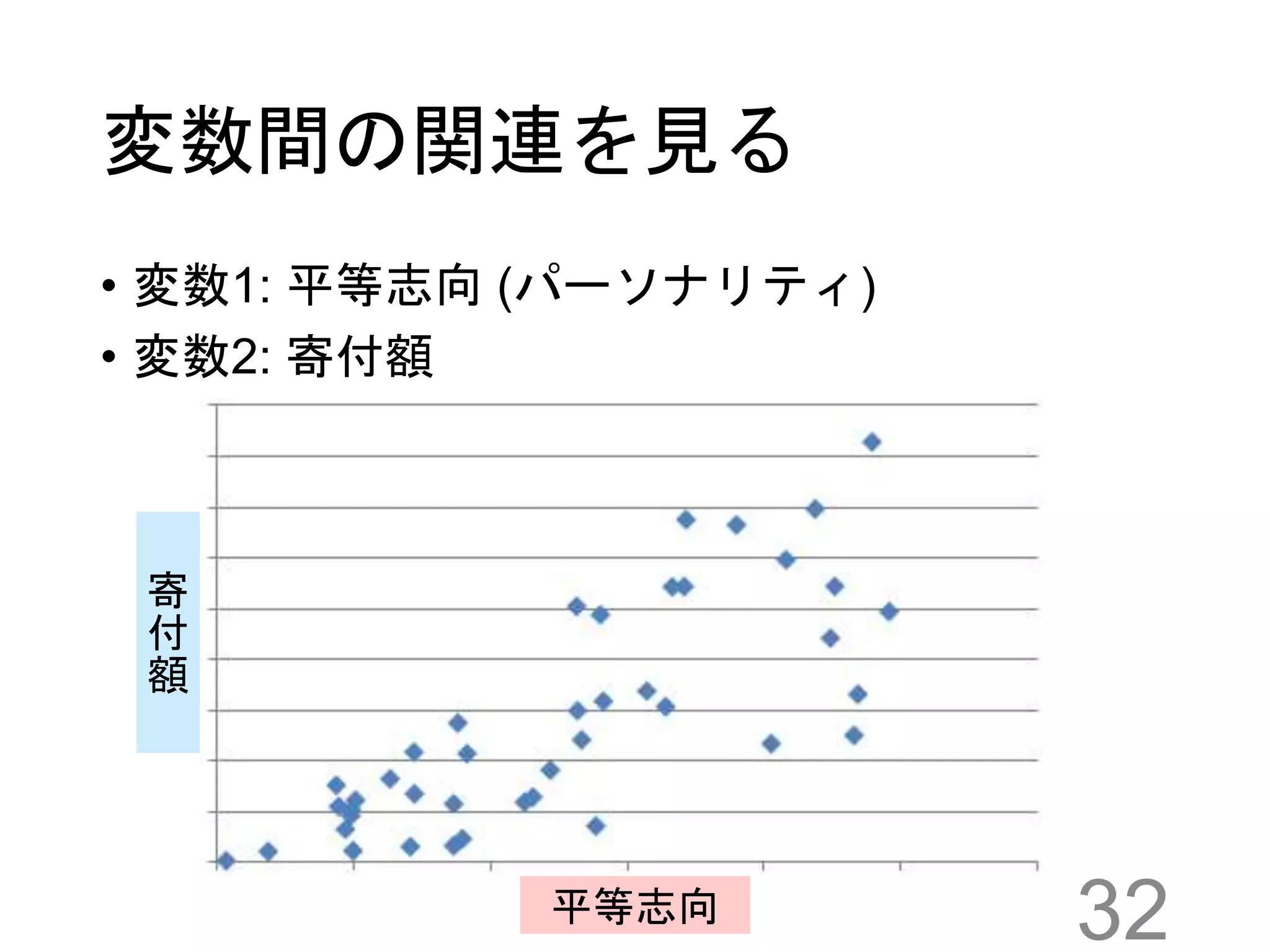
32.
変数間の関連を見る • 変数1: 平等志向
(パーソナリティ) • 変数2: 寄付額 32平等志向 寄 付 額
33.
平等志向の高低でぶつ切り? • 平等志向が高い人はより寄付をする、という関 連があるのかを見たい… • 平等志向の高低±1SDで参加者を分けて分析? •
もったいない! • せっかくリッチなデータがあるのに、データを捨て てしまう… 33
34.
相関分析 (Correlation analysis) •
相関分析 • 変数間の関連を直線的に表現 • 相関分析も t 検定と同じく2つの仮説を検証 • H0: 2つの変数間に関連はない • H1: 2つの変数間に関連がある 34
35.
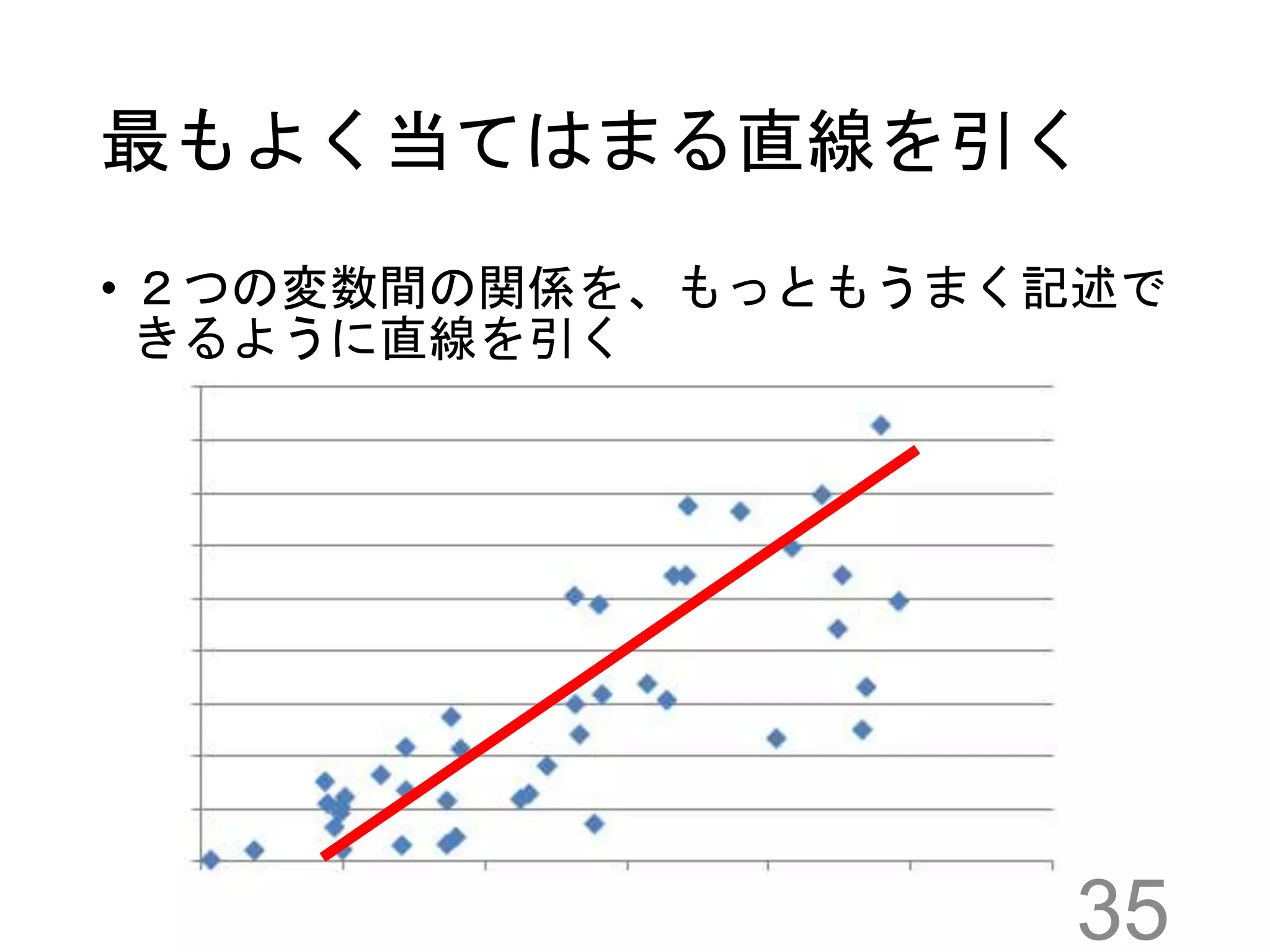
最もよく当てはまる直線を引く • 2つの変数間の関係を、もっともうまく記述で きるように直線を引く 35
36.
相関係数=関連の方向と強さ 36 変数xと母平均 との差 変数yと母平均 との差 変数xと母平均 との差の2乗 変数yと母平均 との差の2乗 𝑖=1 𝑛 (𝑥𝑖 − 𝑥)
(𝑦𝑖 − 𝑦) 𝑖=1 𝑛 (𝑥𝑖 − 𝑥) 2 𝑖=1 𝑛 (𝑦𝑖 − 𝑦) 2
37.
相関係数=関連の方向と強さ 37 𝑖=1 𝑛 (𝑥𝑖 − 𝑥)
(𝑦𝑖 − 𝑦) 𝑖=1 𝑛 (𝑥𝑖 − 𝑥) 2 𝑖=1 𝑛 (𝑦𝑖 − 𝑦) 2 変数xと変数yの 共分散 この値で相関の方向が分かる 標準偏差の積 → 共分散を平均化する → 平均化することで相関の強さが分かる
38.
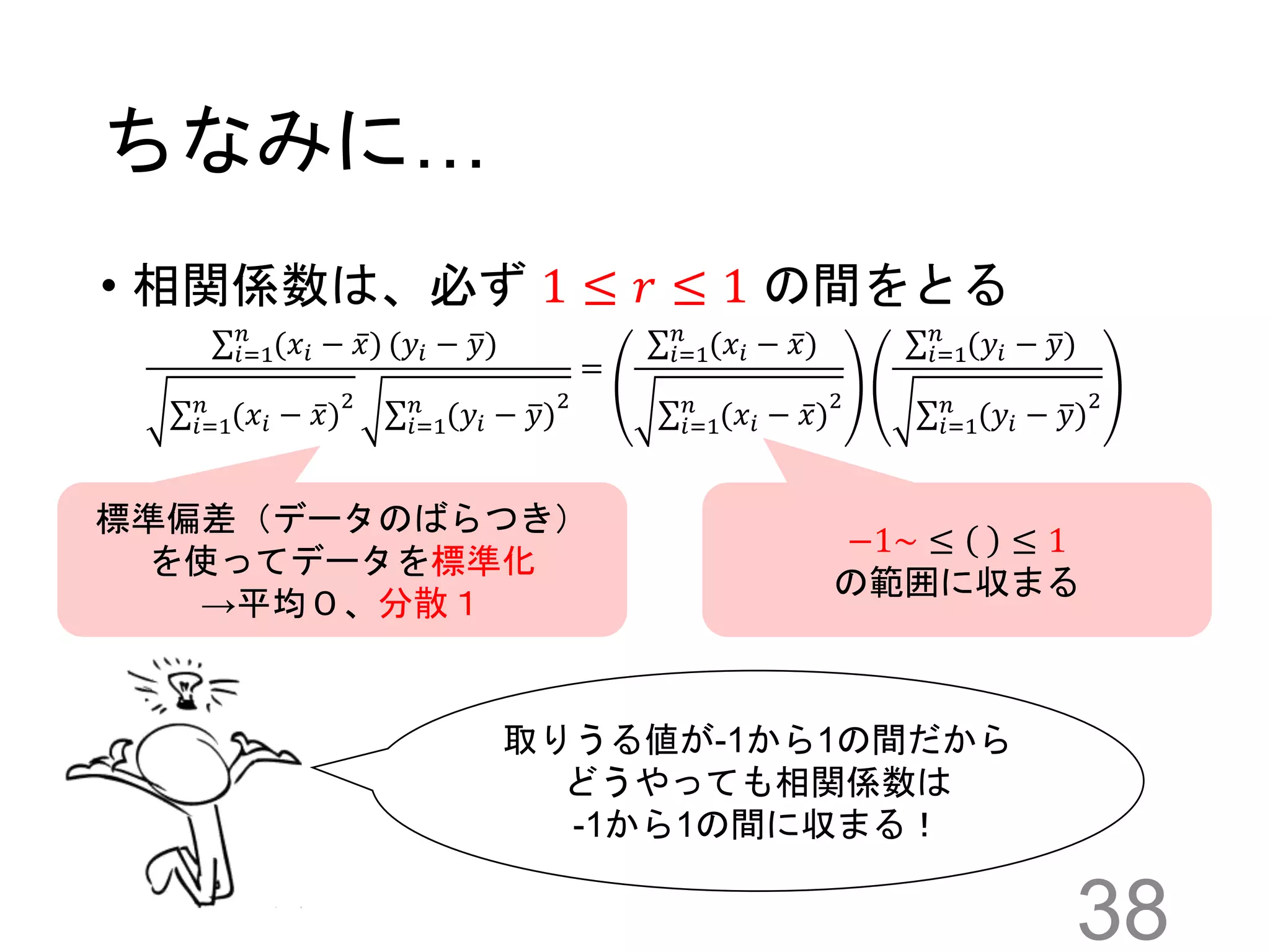
ちなみに… • 相関係数は、必ず 1
≤ 𝑟 ≤ 1 の間をとる 38 𝑖=1 𝑛 (𝑥𝑖 − 𝑥) (𝑦𝑖 − 𝑦) 𝑖=1 𝑛 (𝑥𝑖 − 𝑥) 2 𝑖=1 𝑛 (𝑦𝑖 − 𝑦) 2 = 𝑖=1 𝑛 (𝑥𝑖 − 𝑥) 𝑖=1 𝑛 (𝑥𝑖 − 𝑥) 2 𝑖=1 𝑛 (𝑦𝑖 − 𝑦) 𝑖=1 𝑛 (𝑦𝑖 − 𝑦) 2 標準偏差(データのばらつき) を使ってデータを標準化 →平均0、分散1 取りうる値が-1から1の間だから どうやっても相関係数は -1から1の間に収まる! −1~ ≤ ≤ 1 の範囲に収まる
39.
具体例 • 参加者の平等志向と寄付金の額を調べたところ、 次のようなデータが得られた 39 ID 平等志向
寄付金額 1 7 700 2 3 100 3 8 900 4 2 150 5 6 450 … … …
40.
具体例 • 平等志向と寄付金額の関係について相関分析を 行ったところ… r =
0.83, p = .000000001 40 相関の強さの目安 ⇨ | r | = 0.7~1 かなり強い相関がある ⇨ | r | = 0.4~0.7 やや相関あり ⇨ | r | = 0.2~0.4 弱い相関あり ⇨ | r | = 0~0.2 ほとんど相関なし
41.
レポートでの書き方 41 個人の平等志向と寄付金額の間に関連がみられるかを検 証するため、平等志向と寄付金額について相関分析を 行ったところ、有意な正の相関がみられた (r =
0.83, p < .001)。 このことから、平等志向が高い人は、寄付金額も多めで ある傾向が示された。 ポイント➃…のリマインド 結果の方向性を明確に示し、分かりやすく言い換える ポイント➄ p値が 0.001 以下の場合は、p < .001 と表現する
42.
相関分析を解釈するうえで… • 平等志向と寄付金額が正相関していたとき… • 「平等志向の強さが、多額の寄付を生み出してい る!」といってよいか…? 42 あくまで相関は“関連”でしかない →
因果関係の推論はできない では因果関係の推論には? → 回帰分析 (Regression analysis)
Editor's Notes
#28
検定力:1-β(正しく有意差を検出できる確率) 第1種のエラー(α):実際には差があるのに、差がないとしてしまう確率 第2種のエラー(β):実際には差がないのに、差があるとしてしまう確率
Download