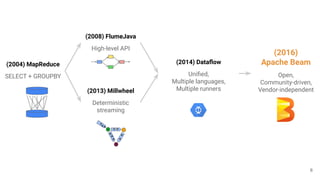
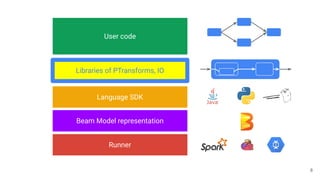
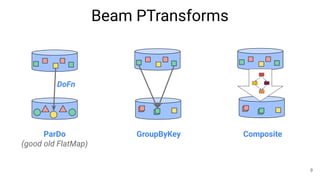
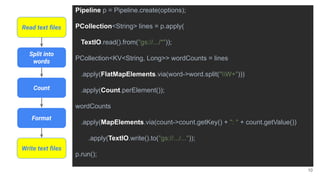
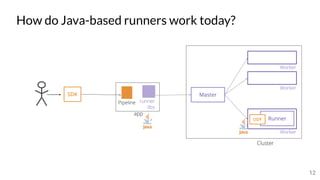
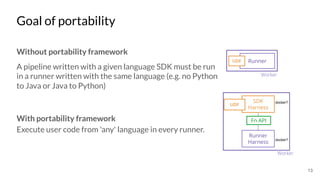
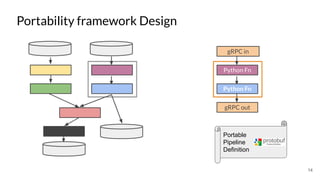
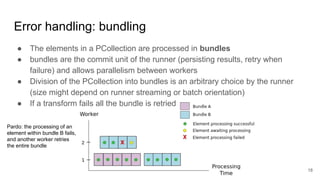
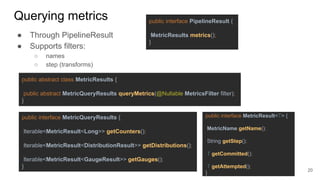
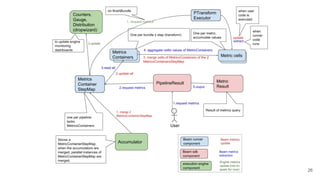
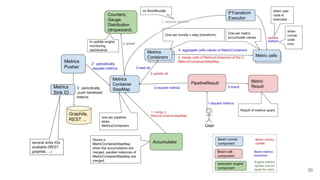
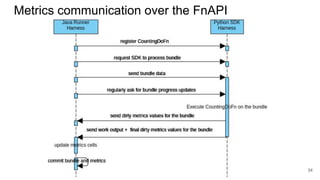
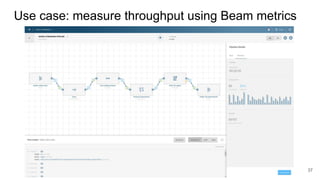
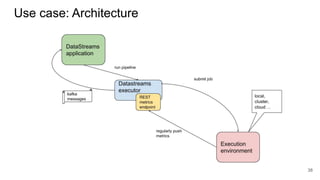
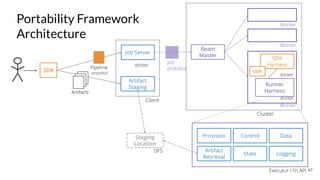
The document discusses the Apache Beam framework and its universal metrics, highlighting how metrics can be defined and collected across various execution engines. It elaborates on the different types of metrics (counters, gauges, distributions) that can be utilized by pipeline authors, the mechanism of extracting these metrics, and the importance of portability in metric collection. The presentation also touches on current developments and future work regarding compatibility with different runners and expanded metric capabilities.