Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
6,738 views
[DL輪読会]Improved Training of Wasserstein GANs
2017/10/16 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Read more
11
Save
Share
Embed
Embed presentation
Download
Downloaded 54 times
1
/ 17
2
/ 17
3
/ 17
4
/ 17
5
/ 17
6
/ 17
7
/ 17
8
/ 17
9
/ 17
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
15
/ 17
16
/ 17
17
/ 17
More Related Content
PDF
[DLHacks 実装]Neural Machine Translation in Linear Time
by
Deep Learning JP
PDF
[DL輪読会]Training RNNs as Fast as CNNs
by
Deep Learning JP
PPTX
[DL Hacks 実装]The Conditional Analogy GAN: Swapping Fashion Articles on People...
by
Deep Learning JP
PDF
[DLHacks 実装]Perceptual Adversarial Networks for Image-to-Image Transformation
by
Deep Learning JP
PDF
[DL輪読会]Deep Recurrent Generative Decoder For Abstractive Text Summarization(E...
by
Deep Learning JP
PDF
[DL輪読会]Energy-based generative adversarial networks
by
Deep Learning JP
PDF
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
PDF
[DL輪読会]Opening the Black Box of Deep Neural Networks via Information
by
Deep Learning JP
[DLHacks 実装]Neural Machine Translation in Linear Time
by
Deep Learning JP
[DL輪読会]Training RNNs as Fast as CNNs
by
Deep Learning JP
[DL Hacks 実装]The Conditional Analogy GAN: Swapping Fashion Articles on People...
by
Deep Learning JP
[DLHacks 実装]Perceptual Adversarial Networks for Image-to-Image Transformation
by
Deep Learning JP
[DL輪読会]Deep Recurrent Generative Decoder For Abstractive Text Summarization(E...
by
Deep Learning JP
[DL輪読会]Energy-based generative adversarial networks
by
Deep Learning JP
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
[DL輪読会]Opening the Black Box of Deep Neural Networks via Information
by
Deep Learning JP
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
[DL輪読会]Improved Training of Wasserstein GANs
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ ImprovedTraining of Wasserstein GANs Jun Hozumi, Matsuo Lab
2.
書誌情報 • TTiittllee:: IImmpprroovveedd
TTrraaiinniinngg ooff WWaasssseerrsstteeiinn GGAANNss – Wasserstein GANの改良版(WGAN-GP) • Authors: Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville – 主にMontreal Institute for Learningの研究者 • Submitted on 31 Mar 2017 • Citations: 60 • 有名論文であるものの、DL Seminarsではまだ誰もやっていなかったので 2
3.
目次 • 復習: GAN,
WGAN • WGANの問題点と特徴 • Gradient Penalty(提案手法のキモ) • WGAN-GP(提案手法) • 実験 • 結論 3
4.
復習: GAN • (通常の)GANは、以下の目的関数を最適化する •
それは元データと出力(x)の分布のJS Divergence(JSD)の最小化に相当 • しかし、勾配消失問題が起こるなどの理由から、その最小化は難しい – JSDが潜在的に連続じゃないから? – 詳 し く は 「 Towards Principled Methods for Training Generative Adversarial Networks」「Wasserstein GAN」を参照 4
5.
復習: WGAN(Wasserstein GAN) •
JSDの代わりに「Earth-Mover Distance」(Wasserstein-1)を採用 • Wasserstein GAN(WGAN)は、以下の目的関数を最適化する – Kantrovich-Rubinstein Dualityを用いて行う • WGANはGが最適化しやすく、目的関数とサンプルの質とが相関する – 学習がうまくできているかを可視化したり比較したりできる 5
6.
復習: WGAN • 1-Lipschitz制約を適用するために、Critic(GANのDiscriminatorに相当)の 重みが[-c,
c]に収まるようWeight Clippingを行う 6 (WGAN論文より)
7.
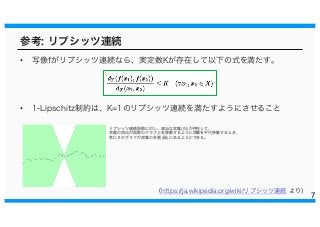
参考: リプシッツ連続 • 写像fがリプシッツ連続なら、実定数Kが存在して以下の式を満たす。 •
1-Lipschitz制約は、K=1のリプシッツ連続を満たすようにさせること 7 (https://ja.wikipedia.org/wiki/リプシッツ連続 より) リプシッツ連続函数に対し、適当な双錐 (白) が存在して、 双錐の頂点が函数のグラフ上を移動するように双錐を平行移動するとき、 常にそのグラフが双錐の外側 (緑) にあるようにできる。
8.
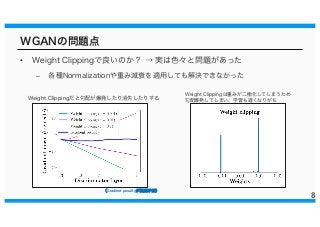
WGANの問題点 • Weight Clippingで良いのか?
→ 実は色々と問題があった – 各種Normalizationや重み減衰を適用しても解決できなかった 8 Weight Clippingだと勾配が爆発したり消失したりする Weight Clippingは重みが二極化してしまうため 勾配爆発してしまい、学習も遅くなりがち ((Gradient penaltyがが提提案案手手法法))
9.
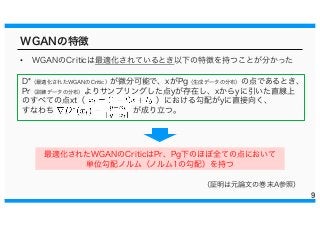
WGANの特徴 • WGANのCriticは最適化されているとき以下の特徴を持つことが分かった 9 D*(最適化されたWGANのCritic)が微分可能で、xがPg(生成データの分布)の点であるとき、 Pr(訓練データの分布)よりサンプリングした点yが存在し、xからyに引いた直線上 のすべての点xt( )における勾配がyに直接向く、 すなわち
が成り立つ。 最適化されたWGANのCriticはPr、Pg下のほぼ全ての点において 単位勾配ノルム(ノルム1の勾配)を持つ (証明は元論文の巻末A参照)
10.
Gradient Penaltyの導入 • 以上を踏まえ、Gradient
Penaltyを導入したWGAN(WGAN-GP)を提案 – (最適化されたWGANの特徴である)「CriticがPr、Pg下のほぼ全ての点に おいてノルム1の勾配を持つ」ように、Lossにペナルティ項を導入する – 元データと生成データとの内分点の勾配ノルムからペナルティを計算する 10
11.
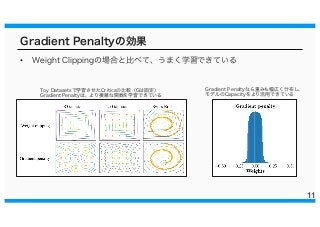
Gradient Penaltyの効果 • Weight
Clippingの場合と比べて、うまく学習できている 11 Gradient Penaltyなら重みも幅広く分布し、 モデルのCapacityをより活用できている Toy Datasetsで学習させたCriticsの比較(Gは固定) Gradient Penaltyは、より複雑な関数を学習できている
12.
提案手法: WGAN-GP • 全体アルゴリズム 12
13.
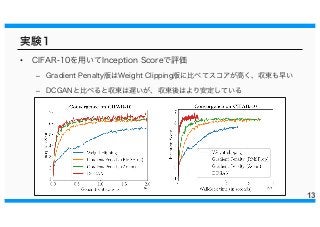
実験1 13 • CIFAR-10を用いてInception Scoreで評価 –
Gradient Penalty版はWeight Clipping版に比べてスコアが高く、収束も早い – DCGANと比べると収束は遅いが、収束後はより安定している
14.
実験2 • 様々な構造下で実験すると、WGAN-GPのみが全パターンで成功 – WGAN-GPの汎用性(ロバストネス) 14
15.
実験3 • 自然文の生成(Character Level)もできる –
Prが離散的でも学習できる(従来のGANではJSDが発散するので失敗する) 15
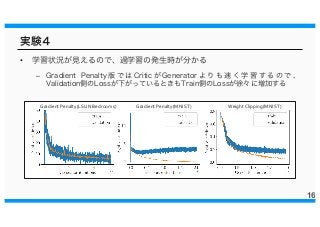
16.
実験4 • 学習状況が見えるので、過学習の発生時が分かる – Gradient
Penalty 版 で は Critic が Generator よ り も 速 く 学 習 す る の で 、 Validation側のLossが下がっているときもTrain側のLossが徐々に増加する 16 Weight Clipping(MNIST)Gradient Penalty(MNIST)Gradient Penalty(LSUN Bedrooms)
17.
結論 • Gradient Penaltyを導入することでWeight
Clippingによって生じていた WGANの欠点を克服し、WGANを様々なGANに適用できるようにした。 • 安定したGANの学習手法を手にしたので、これからは最も良い性能を 引き出せる構造の研究に注力できる。(大量の画像や言語など) 17
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
ImprovedTraining of Wasserstein GANs
Jun Hozumi, Matsuo Lab](https://image.slidesharecdn.com/improvedwganf-171020084239/85/DL-Improved-Training-of-Wasserstein-GANs-1-320.jpg?cb=1508489097)




![復習: WGAN
• 1-Lipschitz制約を適用するために、Critic(GANのDiscriminatorに相当)の
重みが[-c, c]に収まるようWeight Clippingを行う
6
(WGAN論文より)](https://image.slidesharecdn.com/improvedwganf-171020084239/85/DL-Improved-Training-of-Wasserstein-GANs-6-320.jpg?cb=1508489097)






![[DLHacks 実装]Neural Machine Translation in Linear Time](https://cdn.slidesharecdn.com/ss_thumbnails/0925dlhacks-171005051158-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/20171002dlhacks-171002105129-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks 実装]The Conditional Analogy GAN: Swapping Fashion Articles on People...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackscaganimplementation-171114051745-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks 実装]Perceptual Adversarial Networks for Image-to-Image Transformation](https://cdn.slidesharecdn.com/ss_thumbnails/20171017dlhacks-171019082642-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Recurrent Generative Decoder For Abstractive Text Summarization(E...](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dlhacksseki-171106101534-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Energy-based generative adversarial networks](https://cdn.slidesharecdn.com/ss_thumbnails/energy-basedgenerativeadversarialnetworks-171030102253-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Opening the Black Box of Deep Neural Networks via Information](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks10161-171027055615-thumbnail.jpg?width=640&height=640&fit=bounds)



















