Downloaded 55 times










![INPUT REPRESENTATION
dogs → [ d , o , g , s , #d , do , og , gs , s# , #do , dog , ogs , gs#, #dog, dogs, ogs#, #dogs, dogs# ]
(we consider 2K most popular n-graphs only for encoding)
d o g s h a v e o w n e r s c a t s h a v e s t a f f
n-graph
encoding
concatenate
Channels=2K
[words x channels]](https://image.slidesharecdn.com/neuralir-alexandriaworkshop-171018093149/85/Neural-Models-for-Document-Ranking-18-320.jpg)
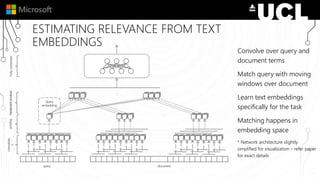

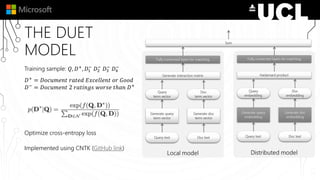



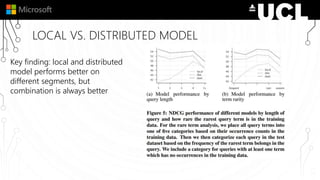
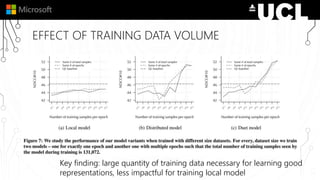





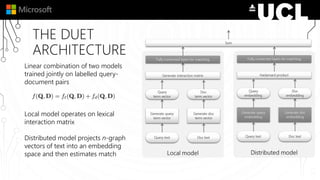
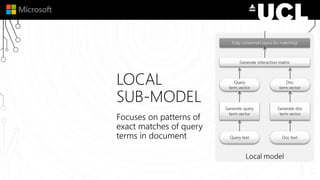
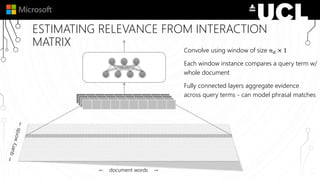
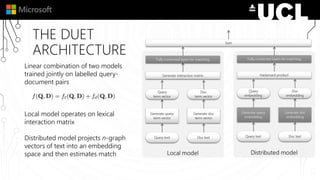
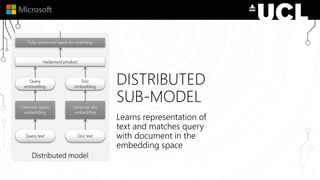
The document discusses a neural model called Duet for ranking documents based on their relevance to a query. Duet uses both a local model that operates on exact term matches between queries and documents, and a distributed model that learns embeddings to match queries and documents in the embedding space. The two models are combined using a linear combination and trained jointly on labeled query-document pairs. Experimental results show Duet performs significantly better at document ranking and other IR tasks compared to using the local and distributed models individually. The amount of training data is also important, with larger datasets needed to learn better representations.



















































![[DSC Europe 24] Sofia Konchakova - Effective Context Tuning Strategies for Re...](https://cdn.slidesharecdn.com/ss_thumbnails/sofiakonchakova-contentmanagementforragsystems-250213223330-c0838a06-thumbnail.jpg?width=640&height=640&fit=bounds)























































