
Recommended
More Related Content
What's hot
What's hot (20)
Similar to Regular Expression
Similar to Regular Expression (20)
More from A. S. M. Shafi
More from A. S. M. Shafi (20)
Recently uploaded
Recently uploaded (20)
Regular Expression
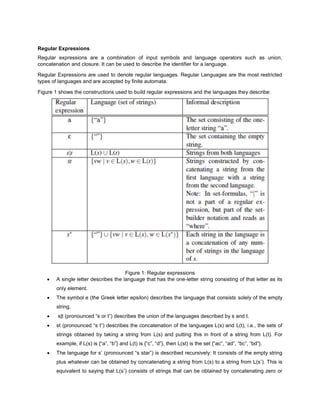
- 1. Regular Expressions Regular expressions are a combination of input symbols and language operators such as union, concatenation and closure. It can be used to describe the identifier for a language. Regular Expressions are used to denote regular languages. Regular Languages are the most restricted types of languages and are accepted by finite automata. Figure 1 shows the constructions used to build regular expressions and the languages they describe: Figure 1: Regular expressions A single letter describes the language that has the one-letter string consisting of that letter as its only element. The symbol e (the Greek letter epsilon) describes the language that consists solely of the empty string. s|t (pronounced “s or t”) describes the union of the languages described by s and t. st (pronounced “s t”) describes the concatenation of the languages L(s) and L(t), i.e., the sets of strings obtained by taking a string from L(s) and putting this in front of a string from L(t). For example, if L(s) is {“a”, “b”} and L(t) is {“c”, “d”}, then L(st) is the set {“ac”, “ad”, “bc”, “bd”}. The language for s* (pronounced “s star”) is described recursively: It consists of the empty string plus whatever can be obtained by concatenating a string from L(s) to a string from L(s*). This is equivalent to saying that L(s*) consists of strings that can be obtained by concatenating zero or
- 2. more (possibly different) strings from L(s). If, for example, L(s) is {“a”, “b”} then L(s_) is {“”, “a”, “b”, “aa”, “ab”, “ba”, “bb”, “aaa”, . . . }, i.e., any string (including the empty) that consists entirely of a’s and b’s. As defined, regular expressions often contain unnecessary pairs of parentheses. We may drop certain pairs of parentheses if we adopt the conventions that: a) The unary operator * has highest precedence and is left associative. b) Concatenation has second highest precedence and is left associative. c) | has lowest precedence and is left associative. Under these conventions, for example, we may replace the regular expression a|ab* by a|(a(b*)). Example: Let Σ = {a, b}. 1. The regular expression a1 b denotes the language {a, b}. 2. (a| b) (alb) denotes {aa, ab, ba, bb), the language of all strings of length two over the alphabet Σ. Another regular expression for the same language is aa|ab|ba| bb. 3. a* denotes the language consisting of all strings of zero or more a's, that is, {∊, a, aa, aaa, . . . }. 4. (alb)* denotes the set of all strings consisting of zero or more instances of a or b, that is, all strings of a's and b's: {∊, a, b, aa, ab, ba, bb, aaa, . . .}. Another regular expression for the same language is (a*b*)*. 5. ala*b denotes the language {a, b, ab, aab,aaab,. . .), that is, the string a and all strings consisting of zero or more a's and ending in b. Figure 2: Some algebraic properties of regular expressions
- 3. Regular Definition A regular definition gives names to certain regular expressions and uses those names in other regular expressions. Here is a regular definition for the set of Pascal identifiers that is define as the set of strings of letter and digits beginning with a letters. letter → A | B | . . . | Z | a | b | . . . | z digit → 0 | 1 | 2 | . . . | 9 id → letter (letter | digit)* The regular expression id is the pattern for the Pascal identifier token and defines letter and digit. Where letter is a regular expression for the set of all upper-case and lower case letters in the alphabet and digit is the regular for the set of all decimal digits.