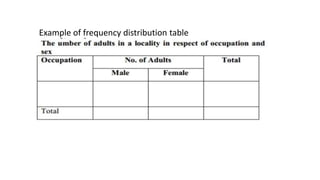
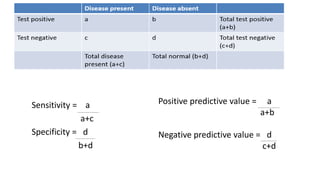
This document provides an overview of key concepts in statistics. It discusses how statistics is used to collect, organize, summarize, present, and analyze numerical data to derive valid conclusions. It defines common statistical terminology like data, quantitative vs. qualitative data, measures of central tendency (mean, median, mode), measures of variability (range, standard deviation), the normal distribution curve, and coefficient of variation. The document also explains common statistical tests like the z-test, t-test, ANOVA, chi-square test and concepts like sensitivity and specificity. Overall, the document serves as a high-level introduction to foundational statistical methods and analyses.