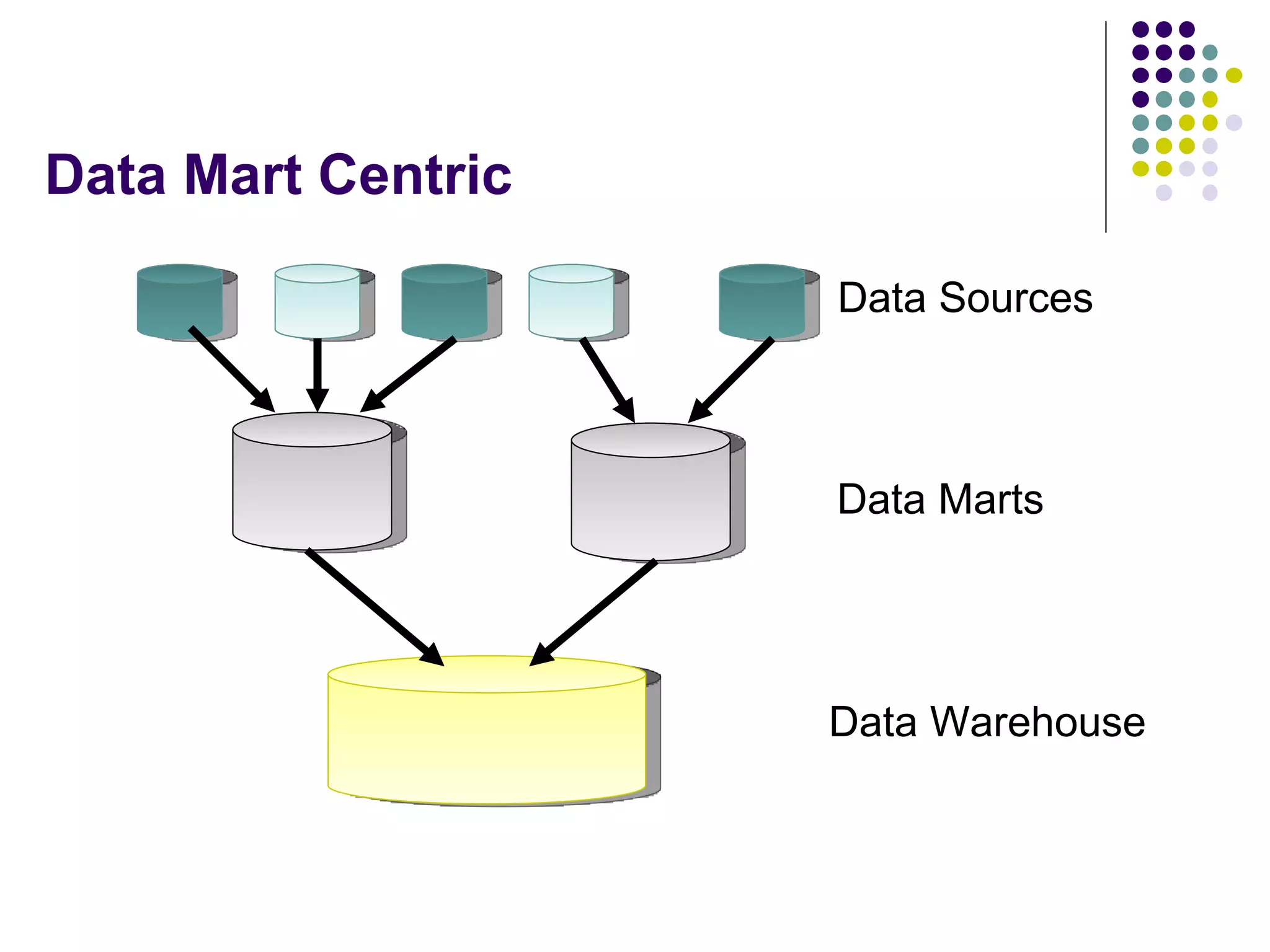
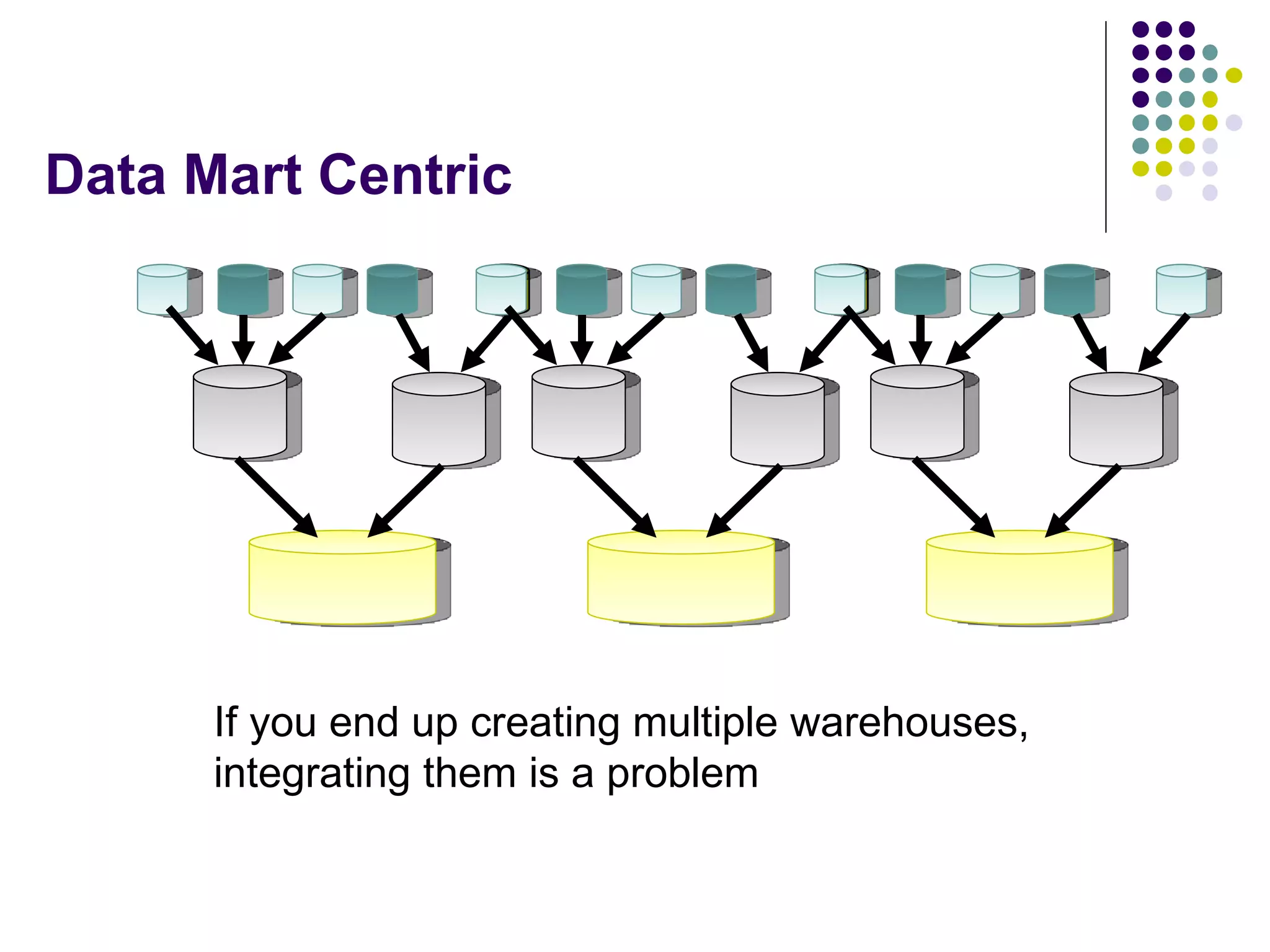
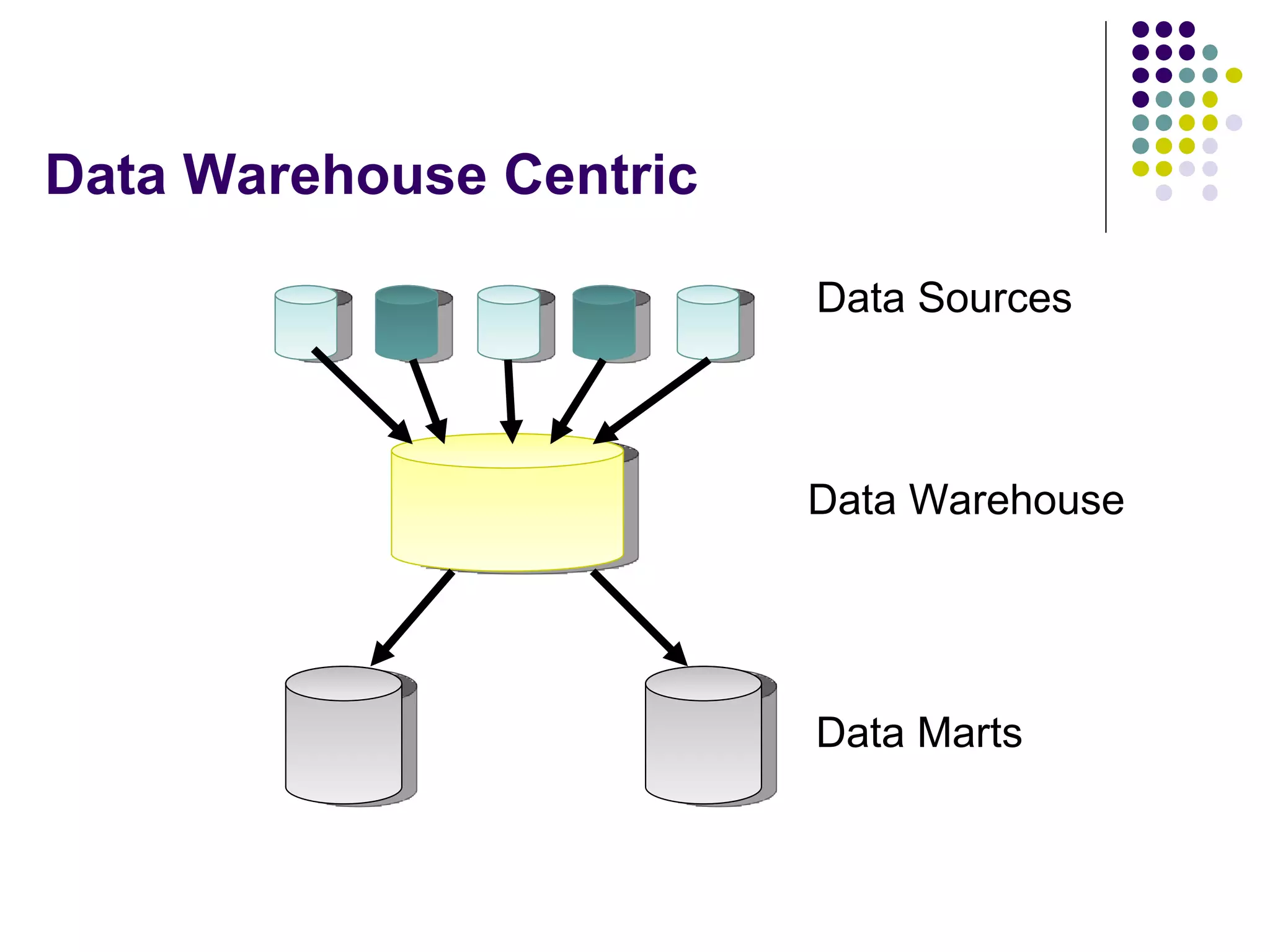
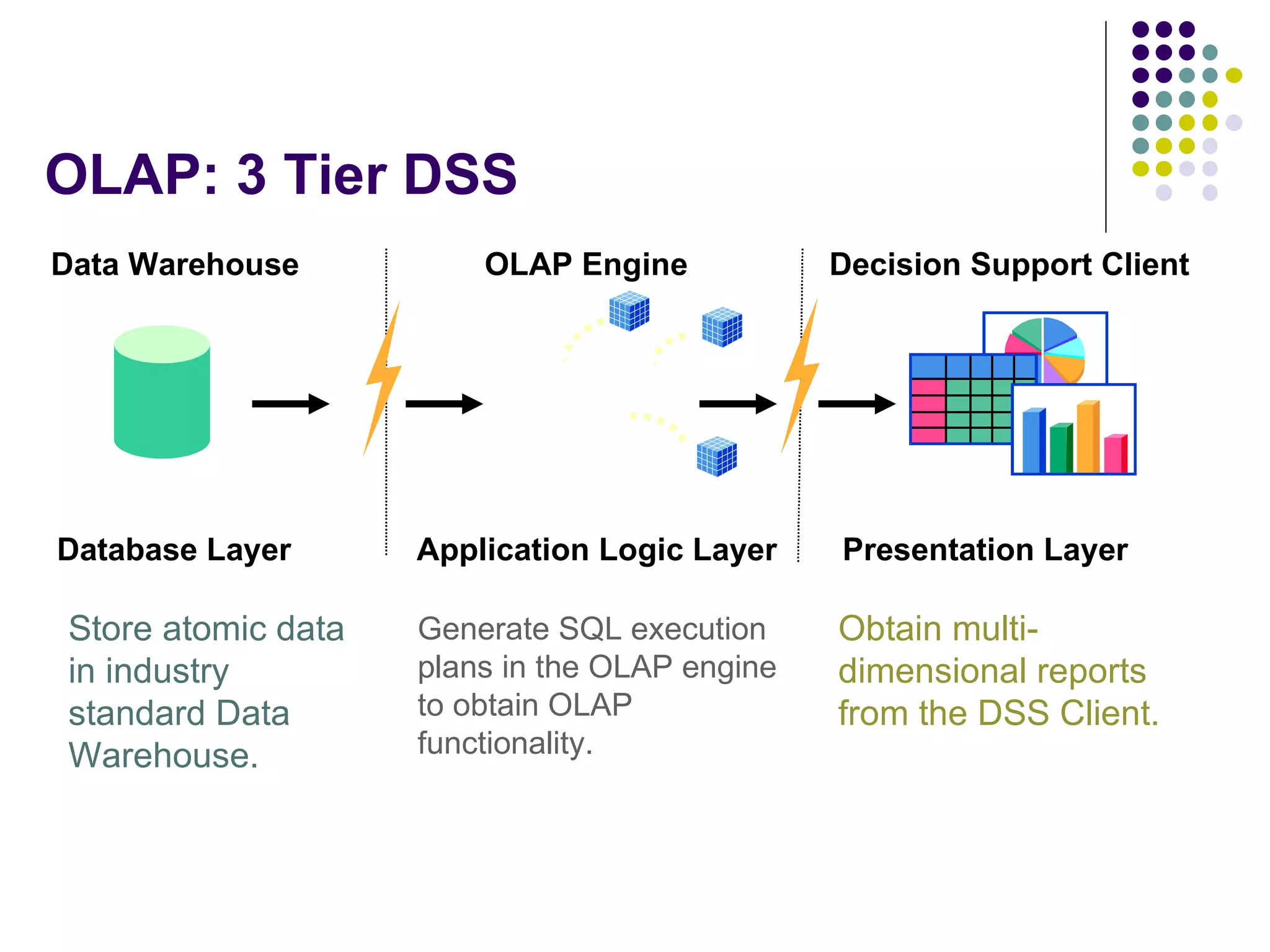
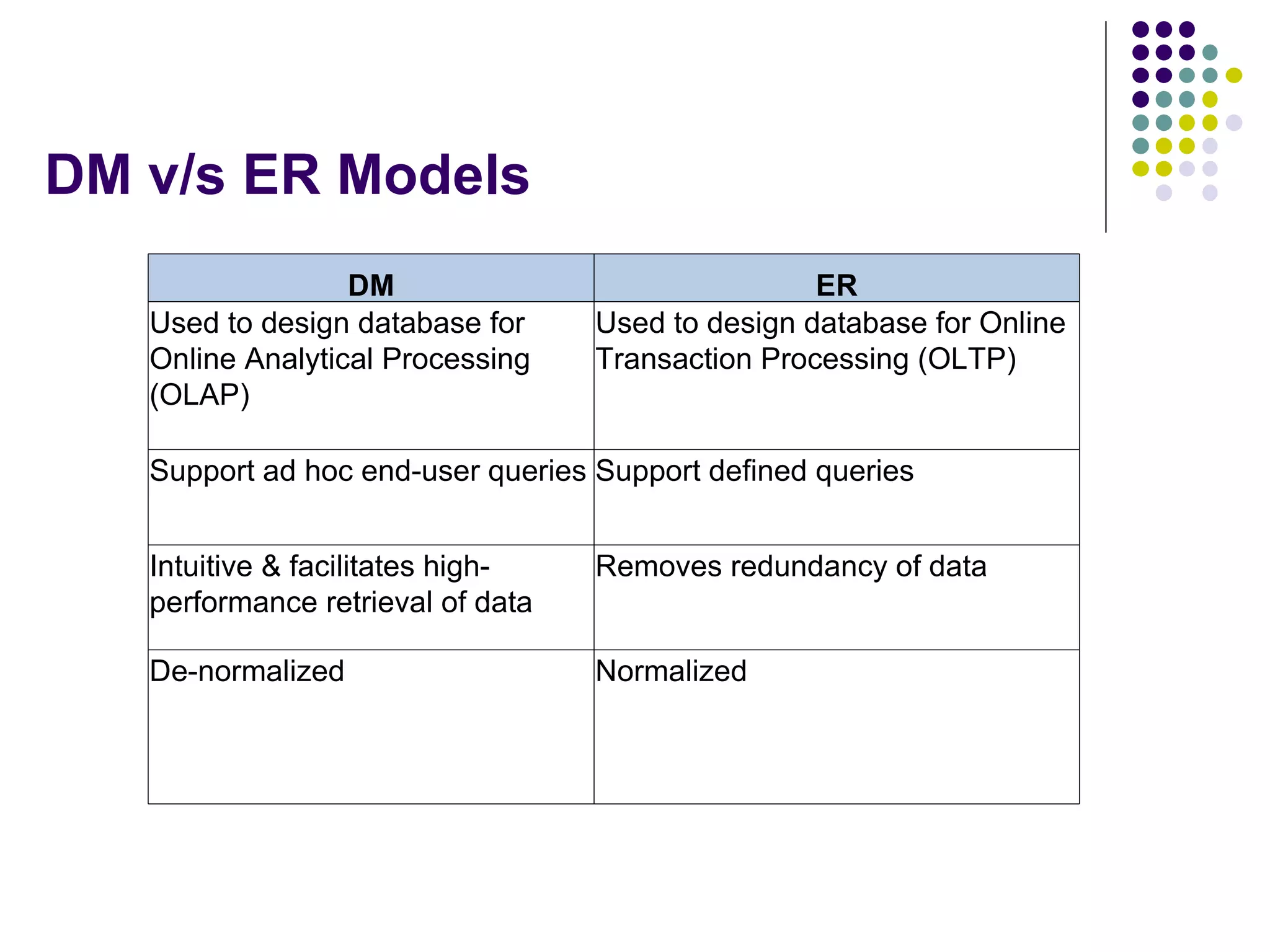
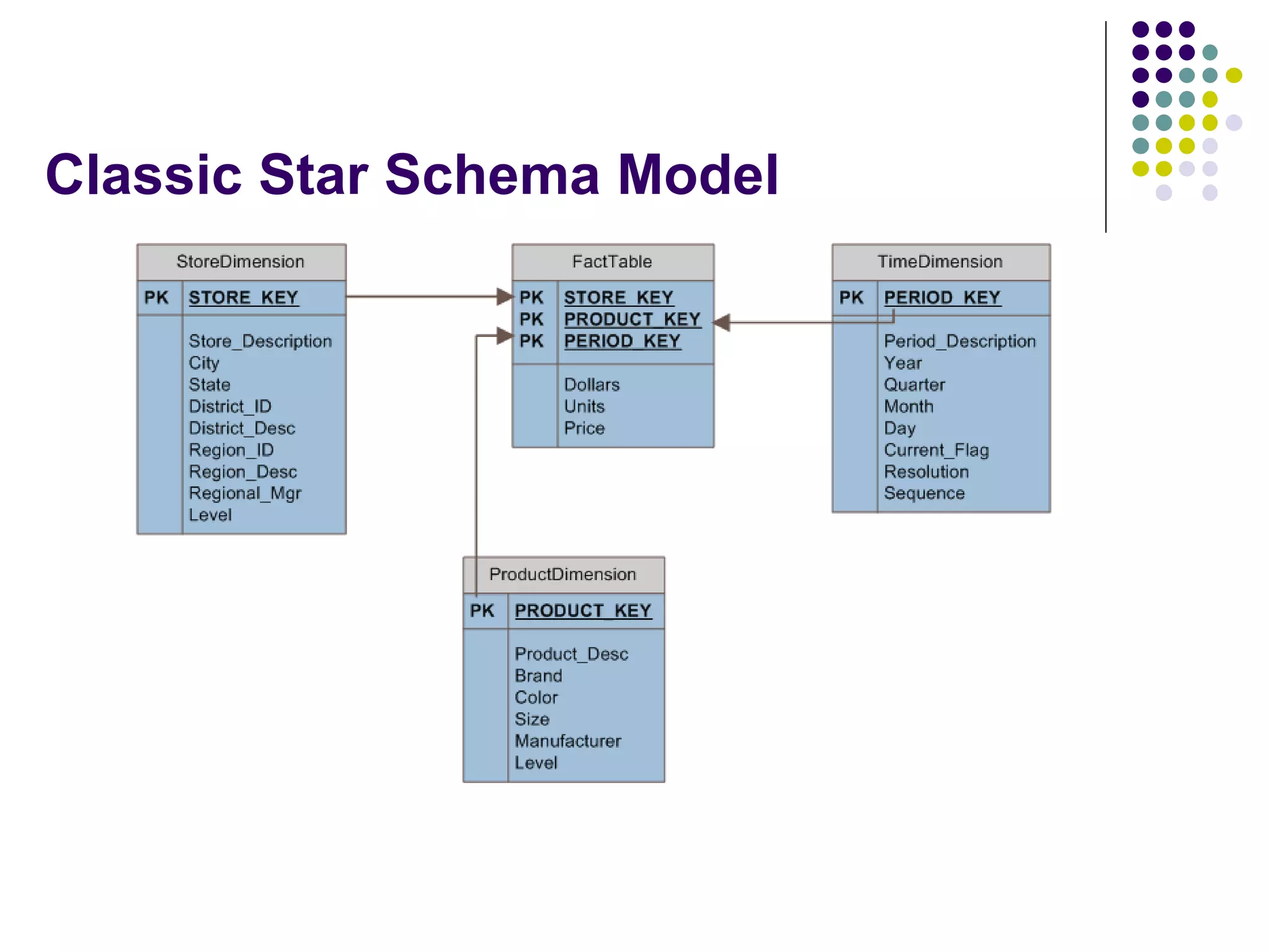
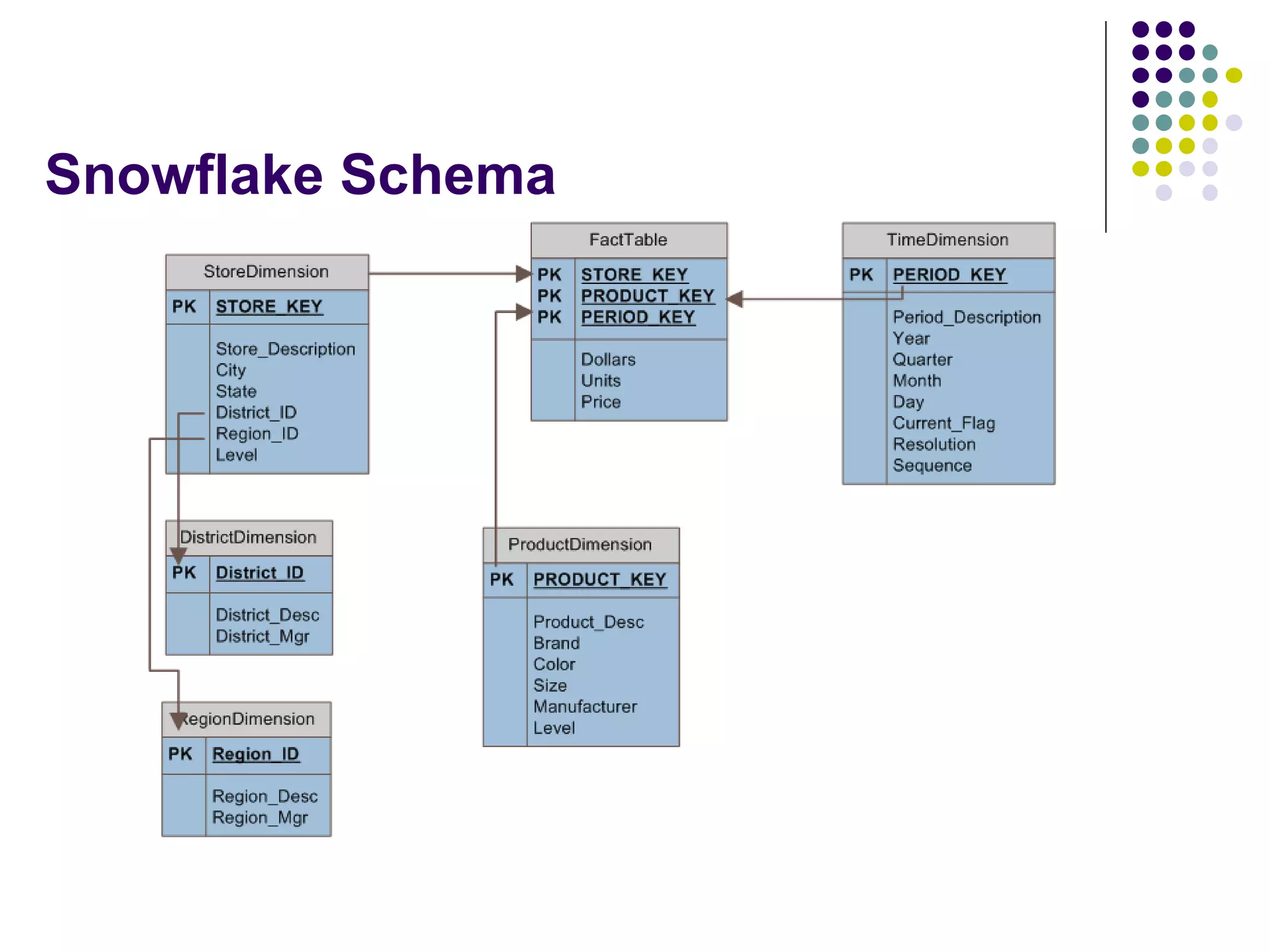
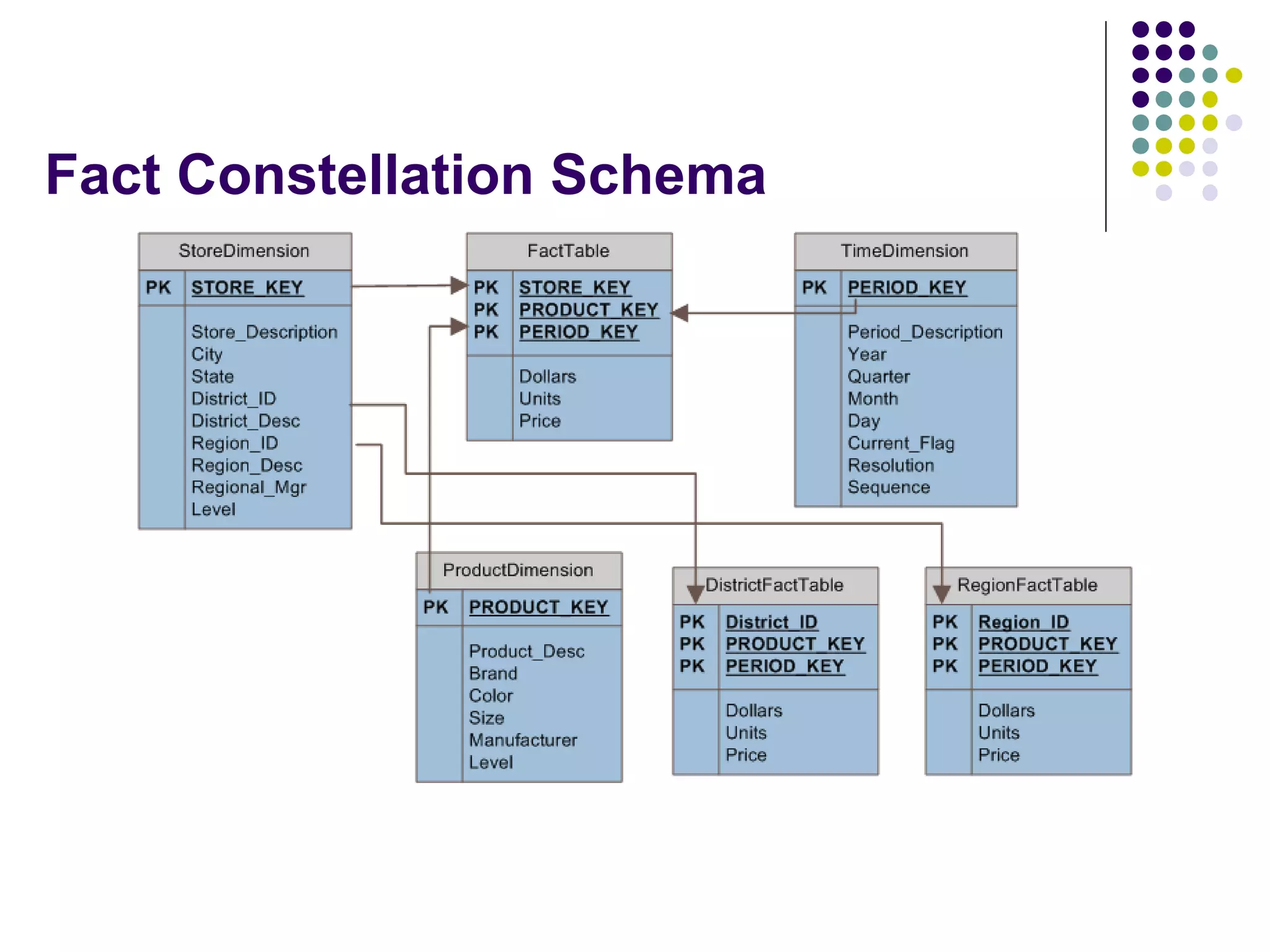
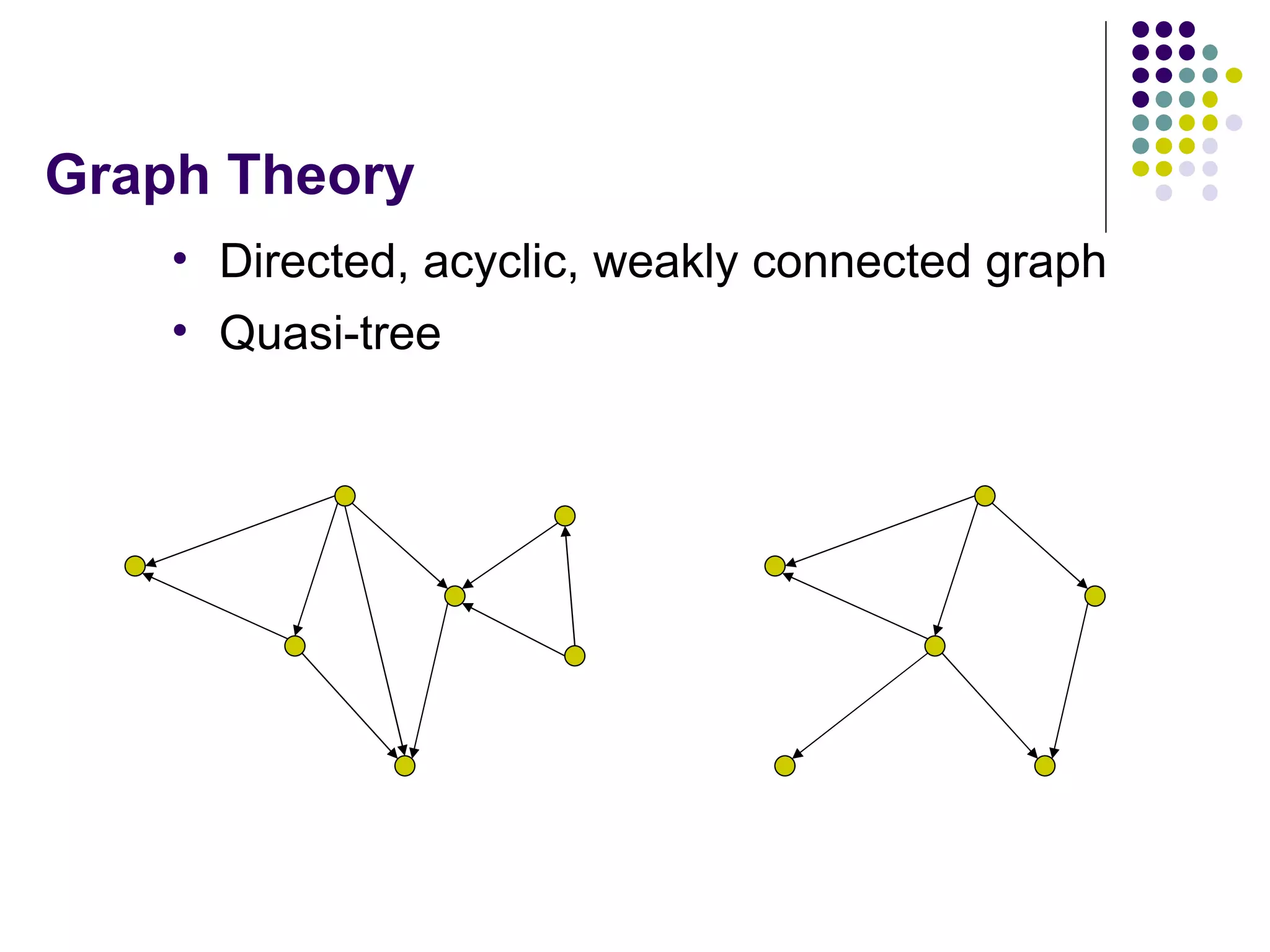
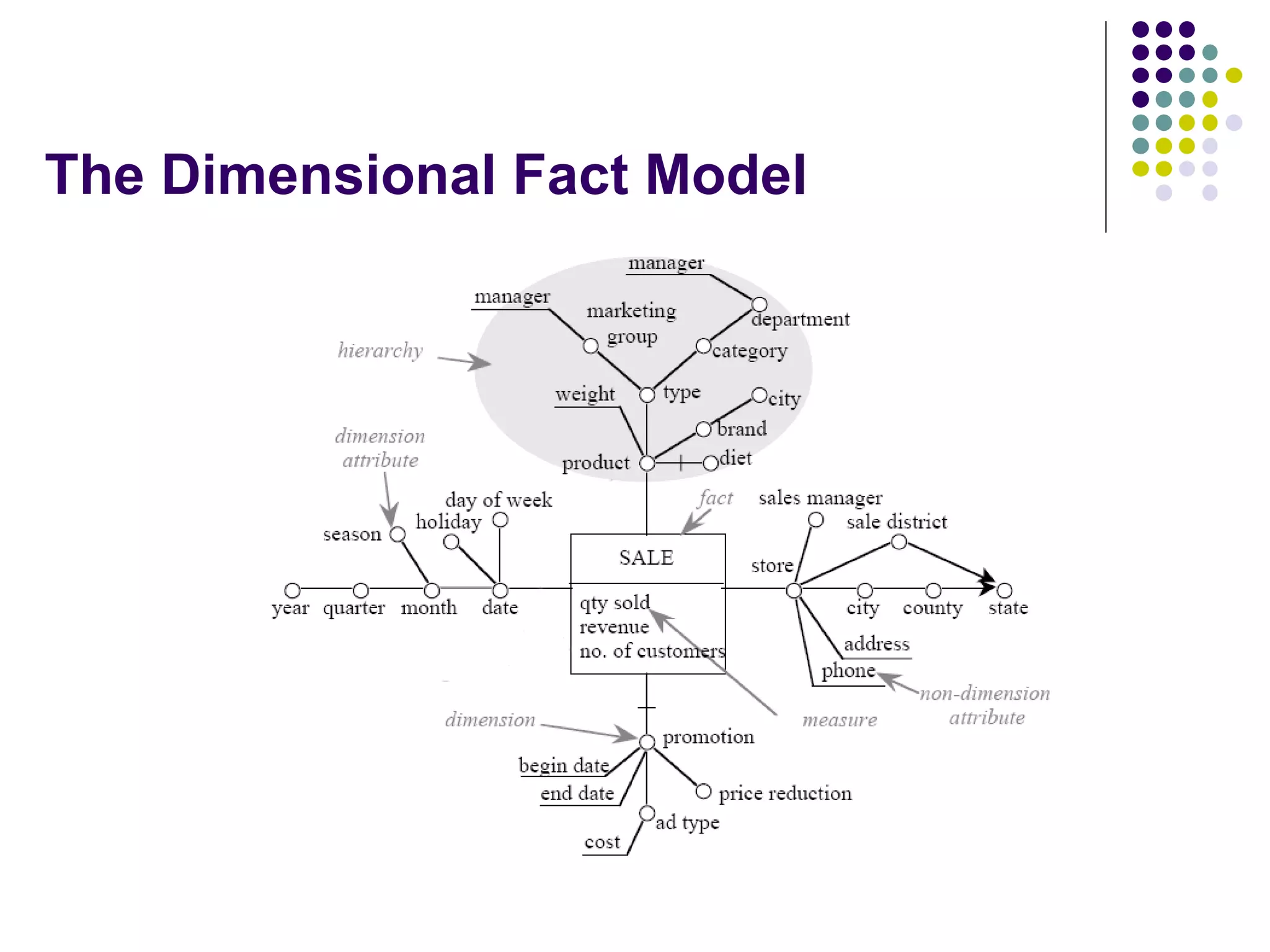
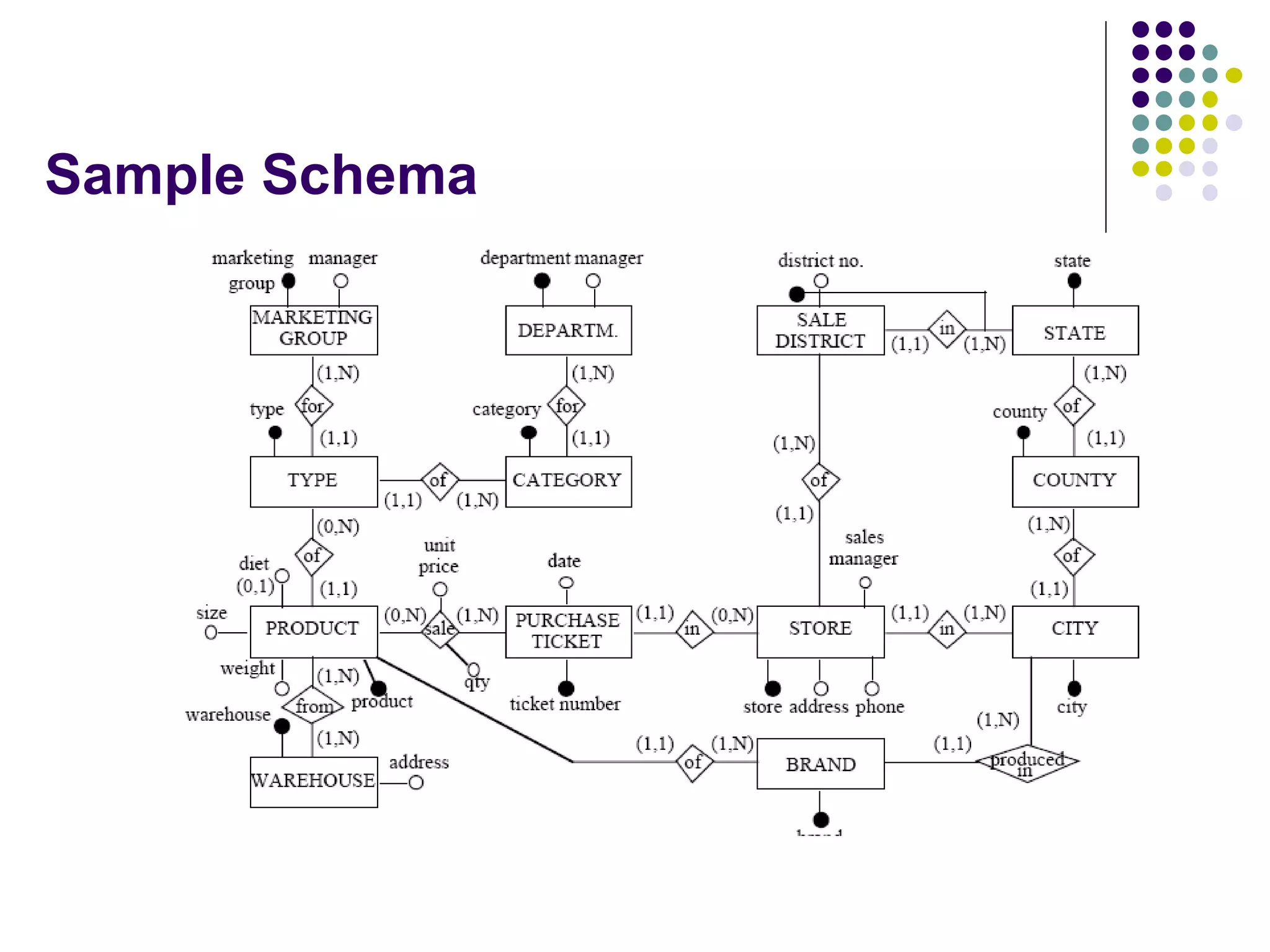
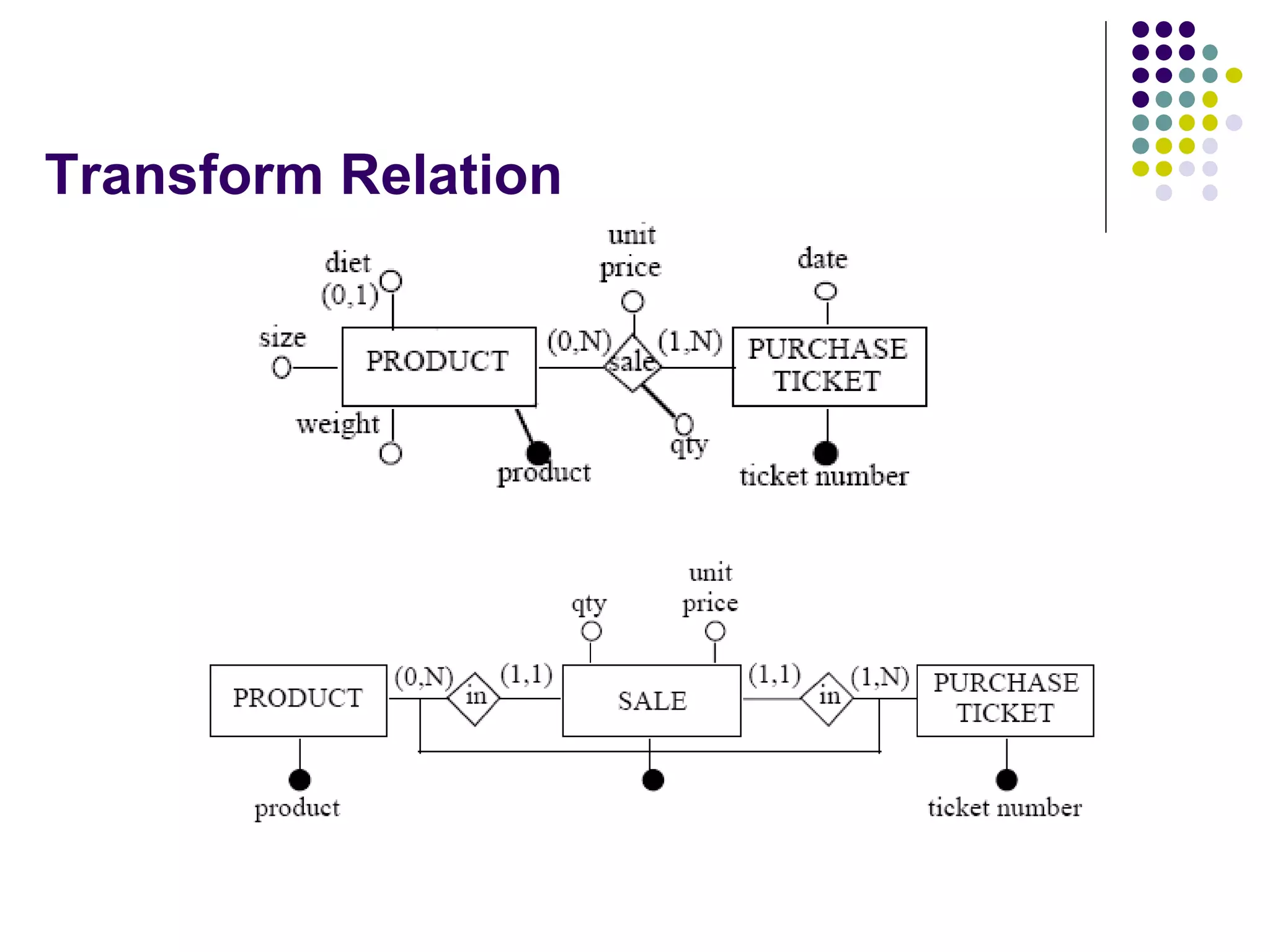
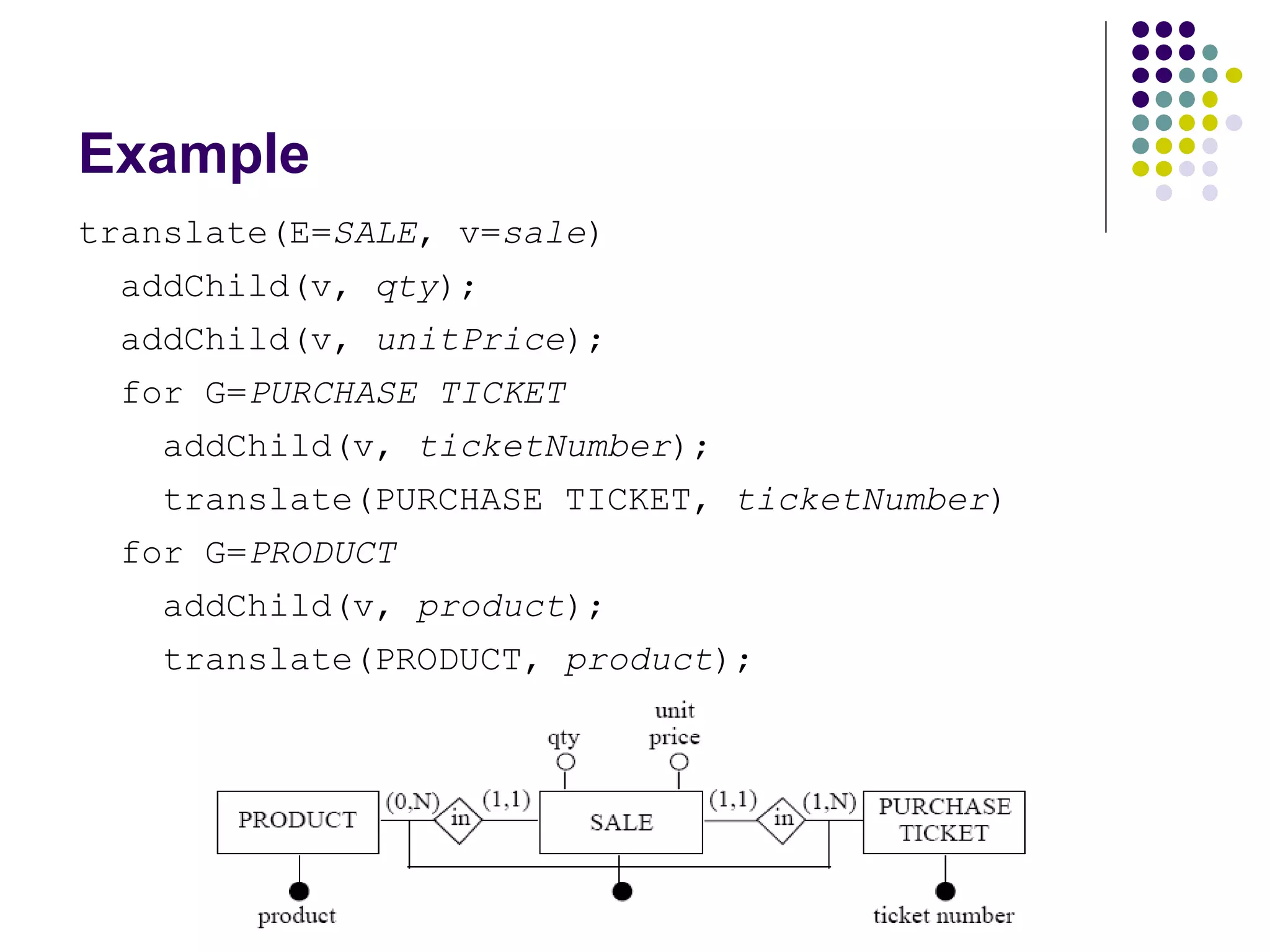
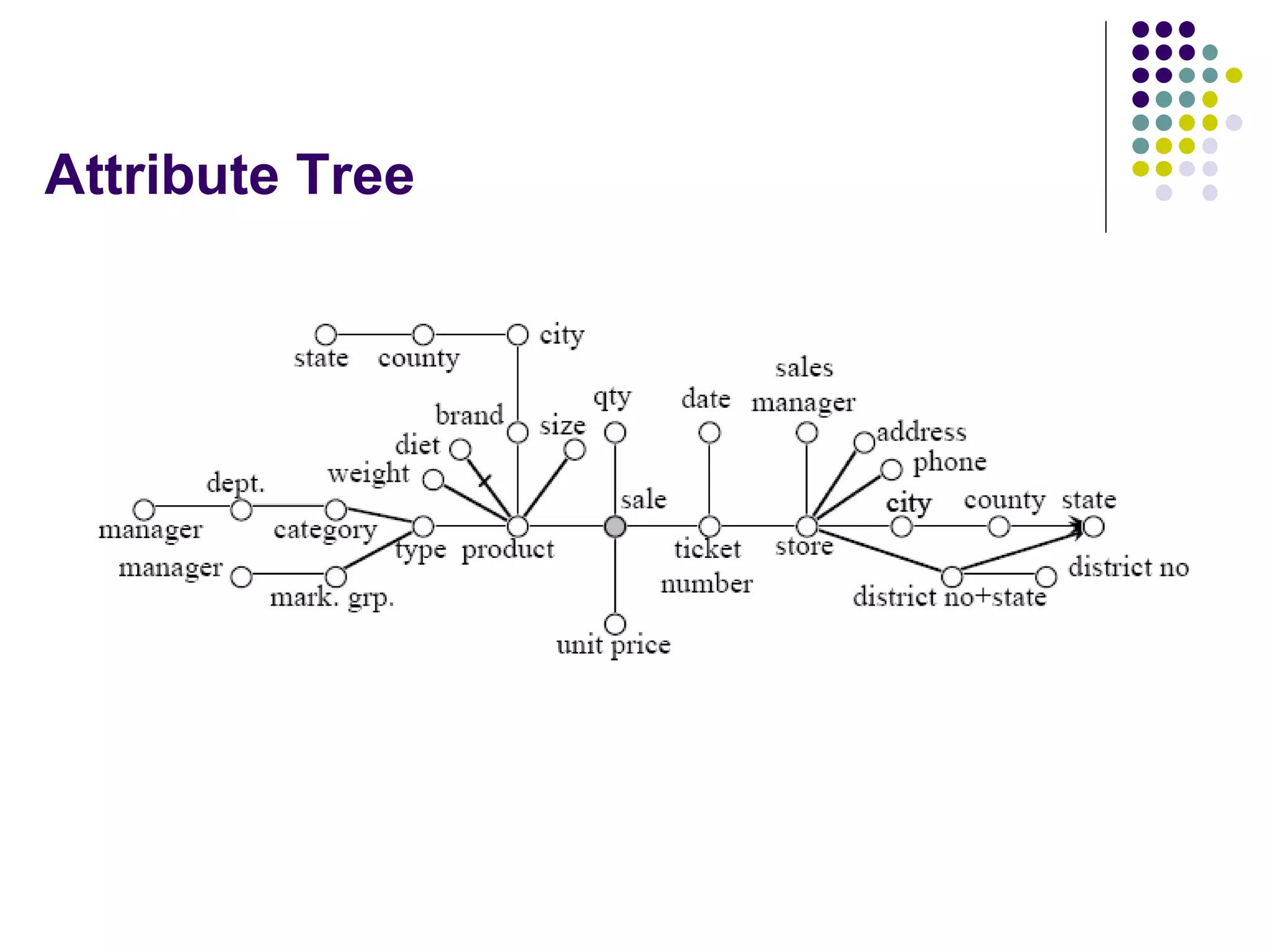
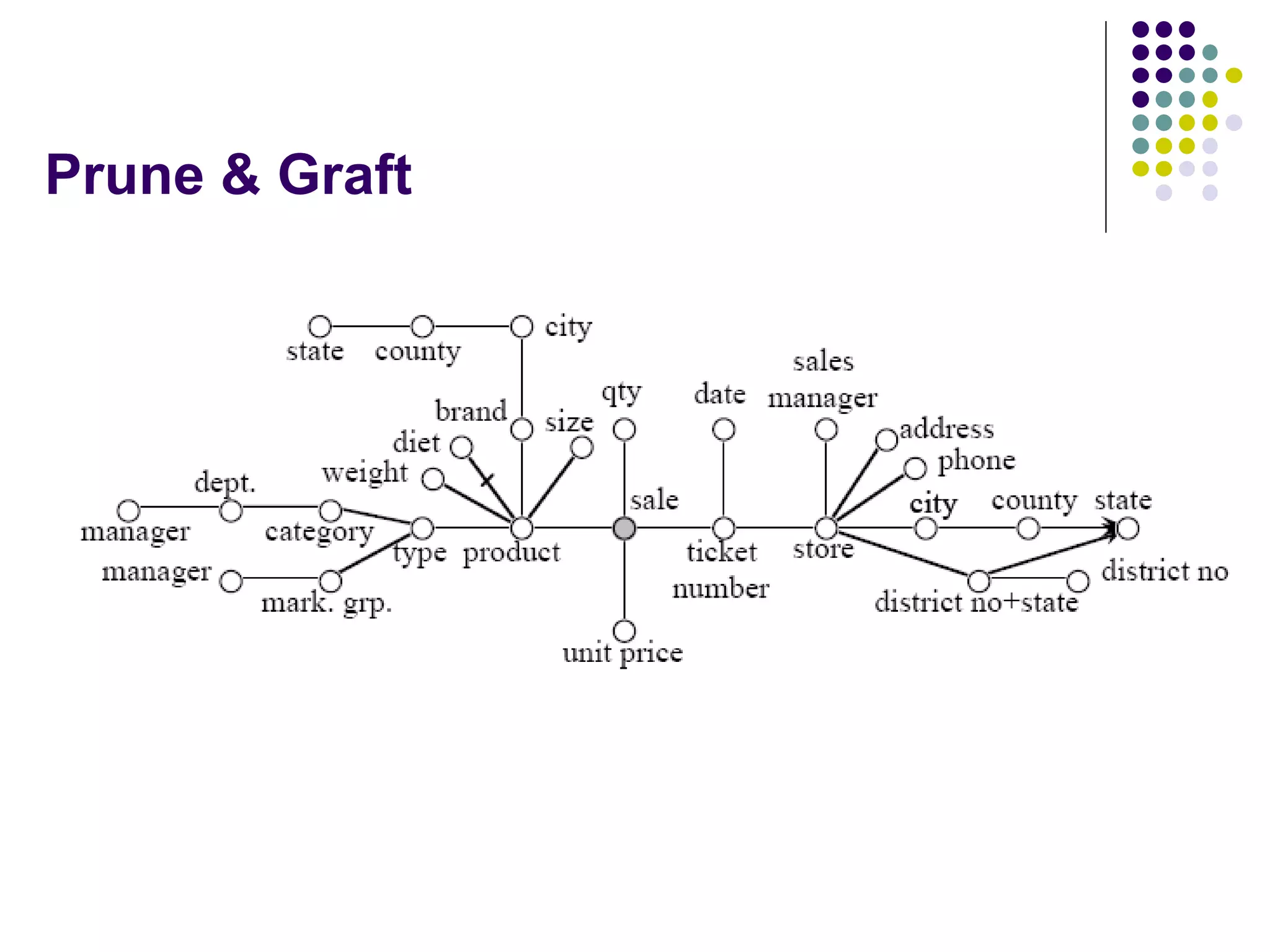
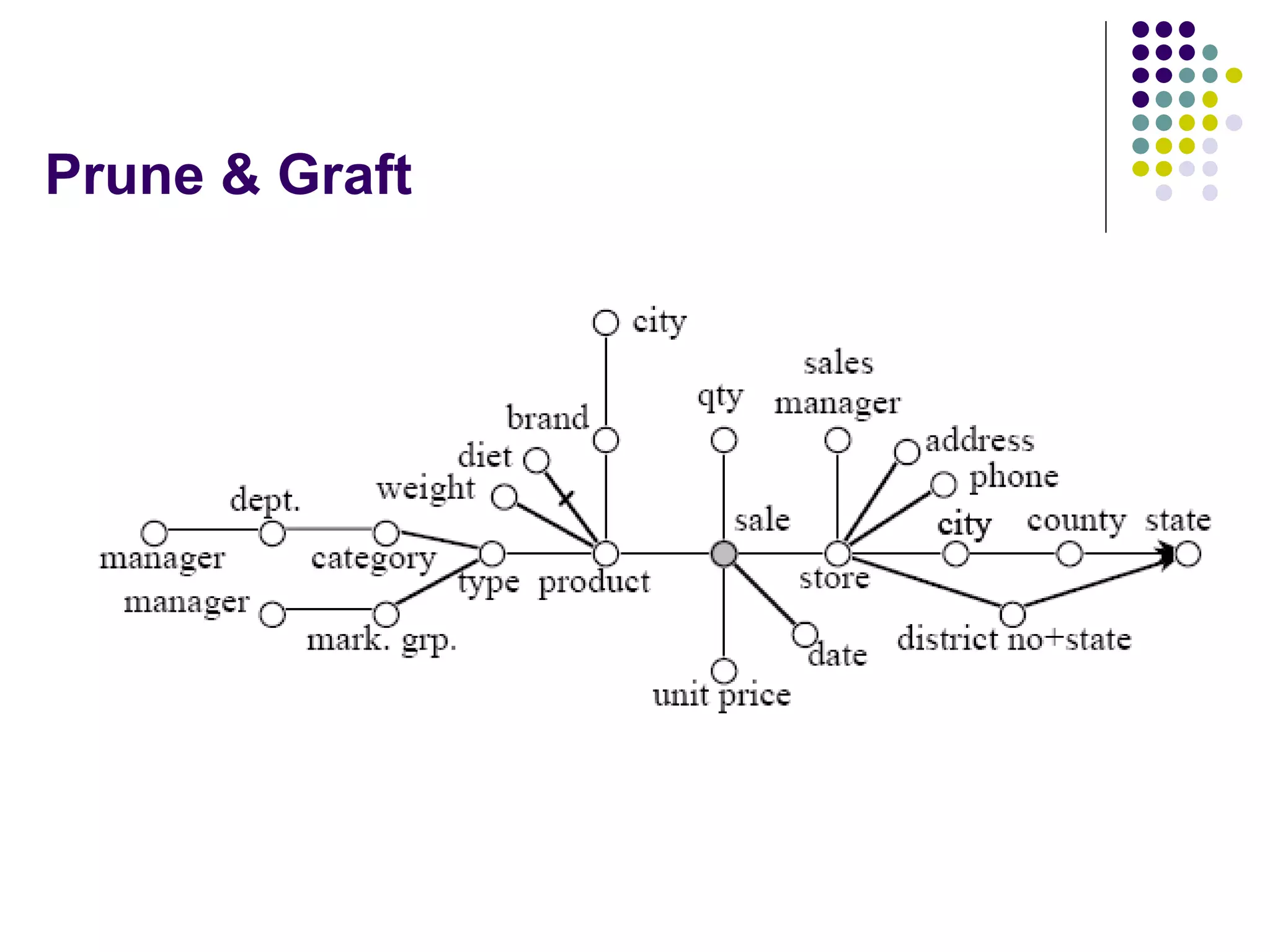
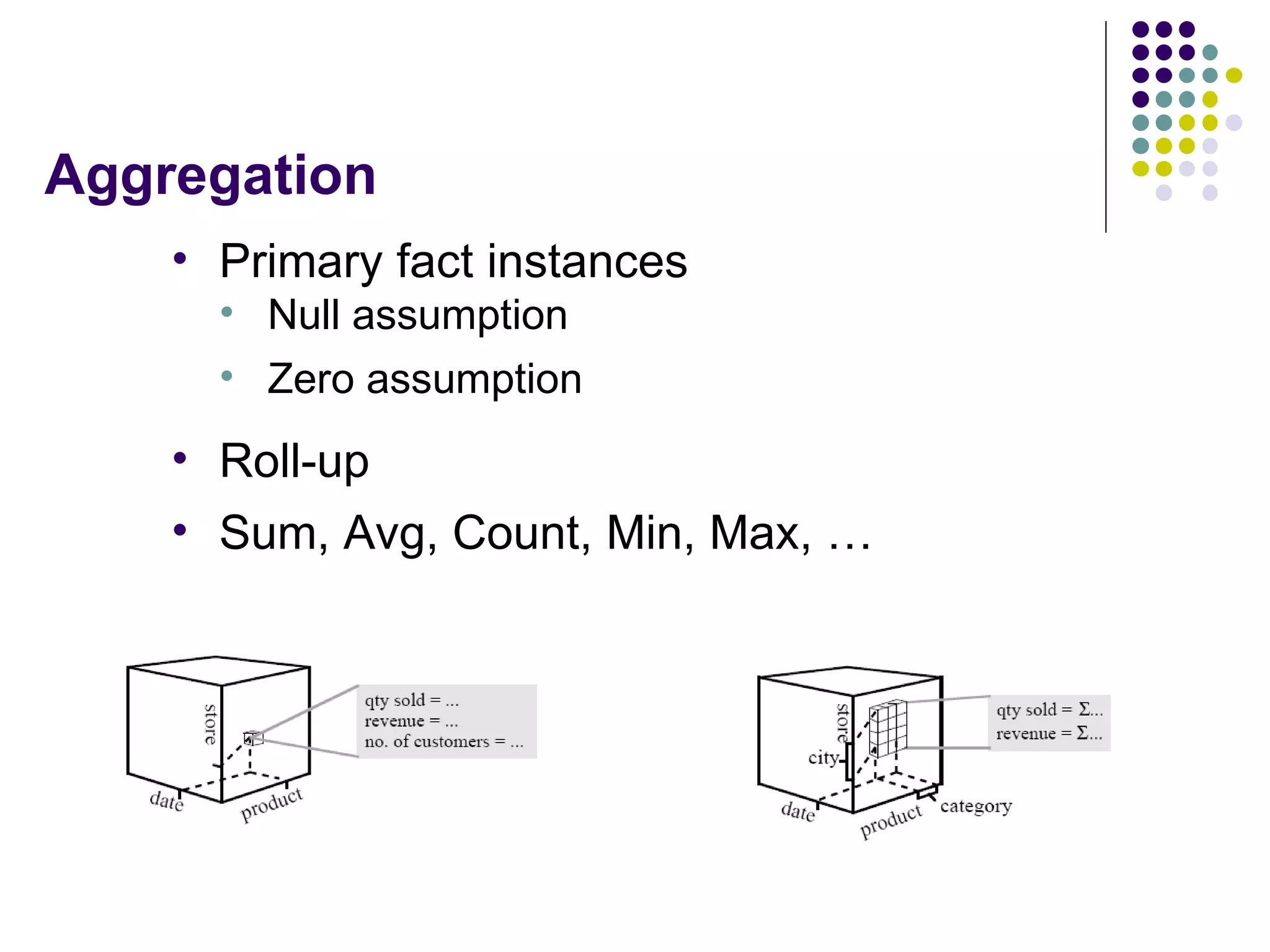
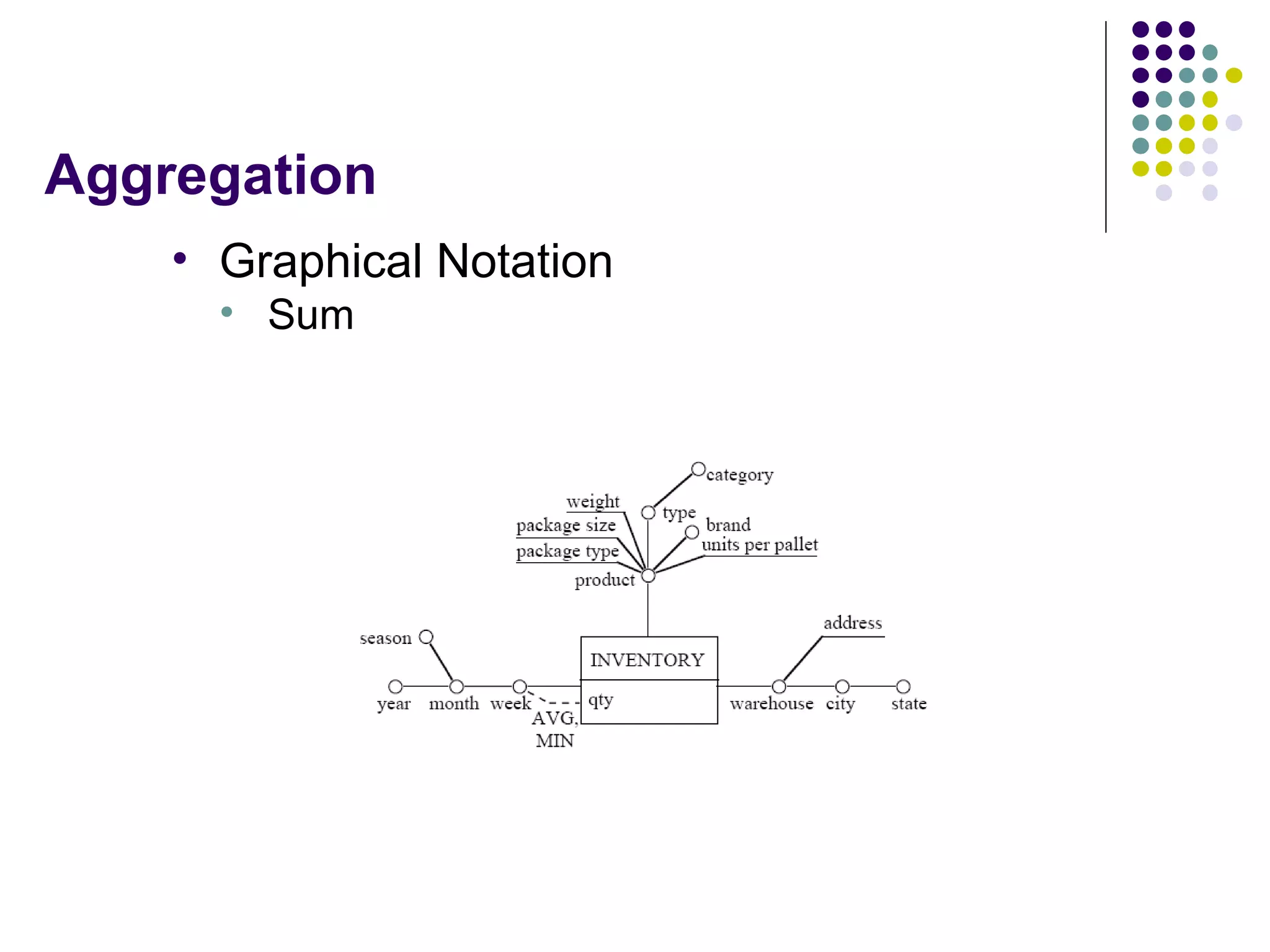
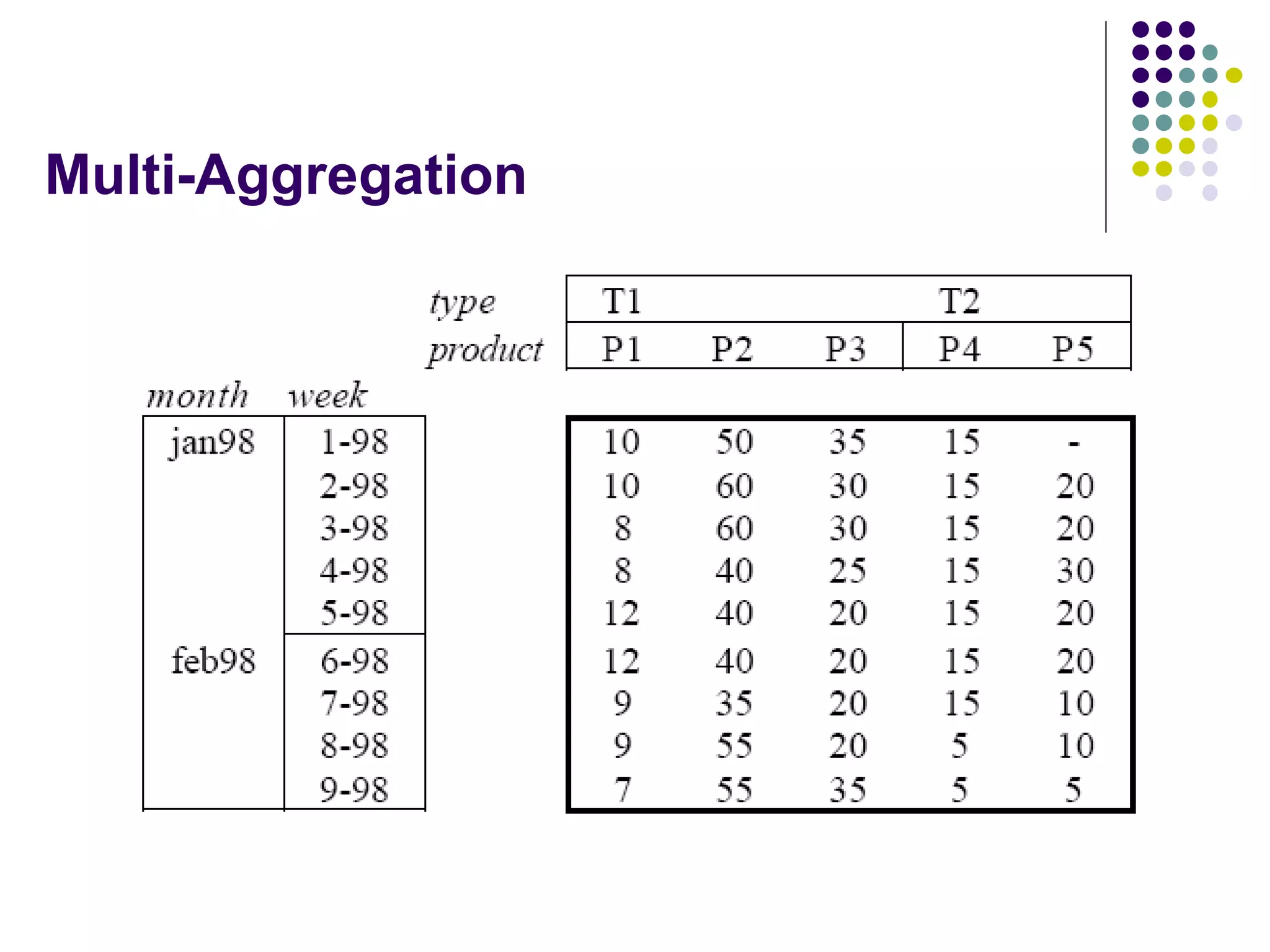
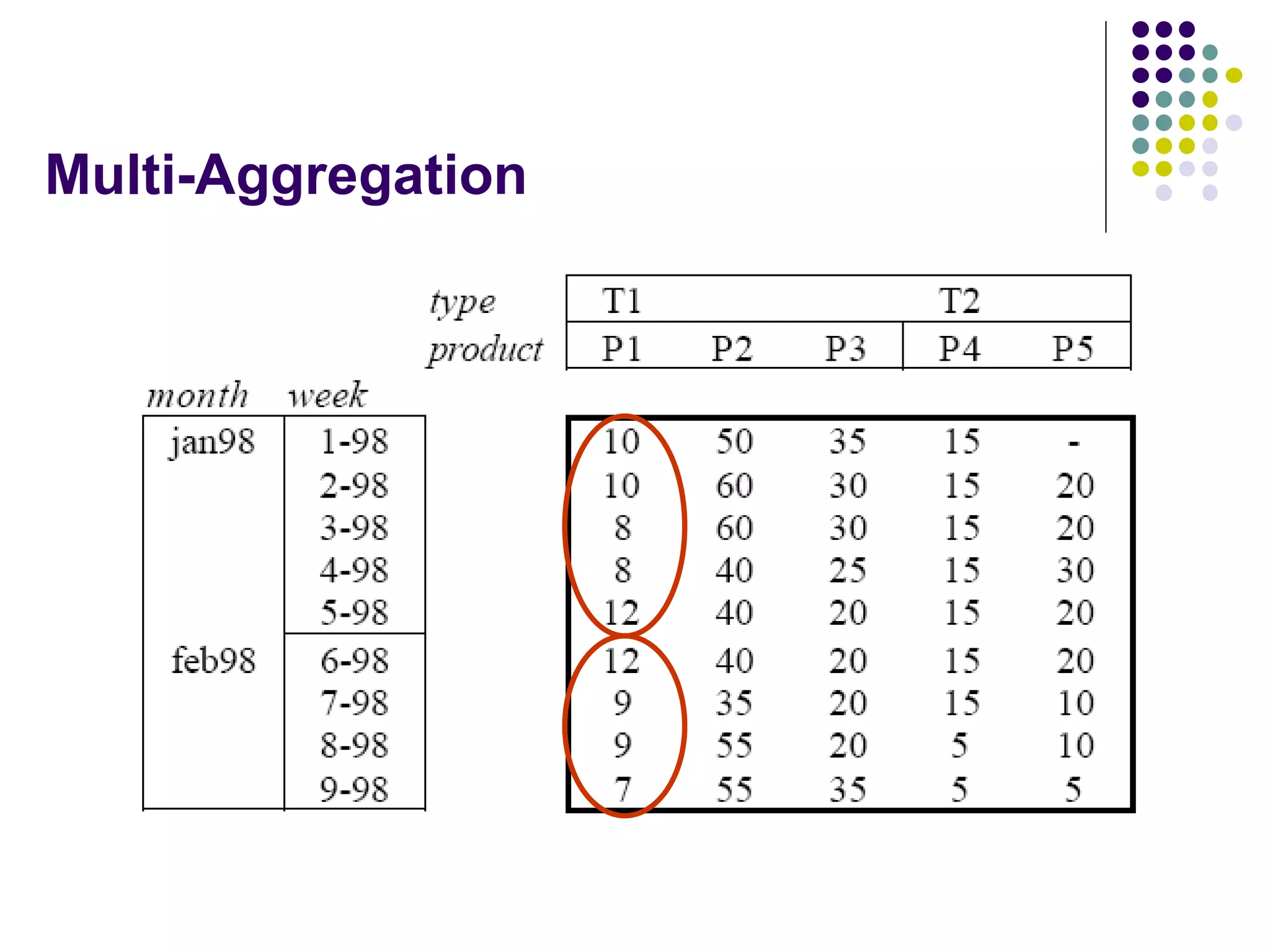
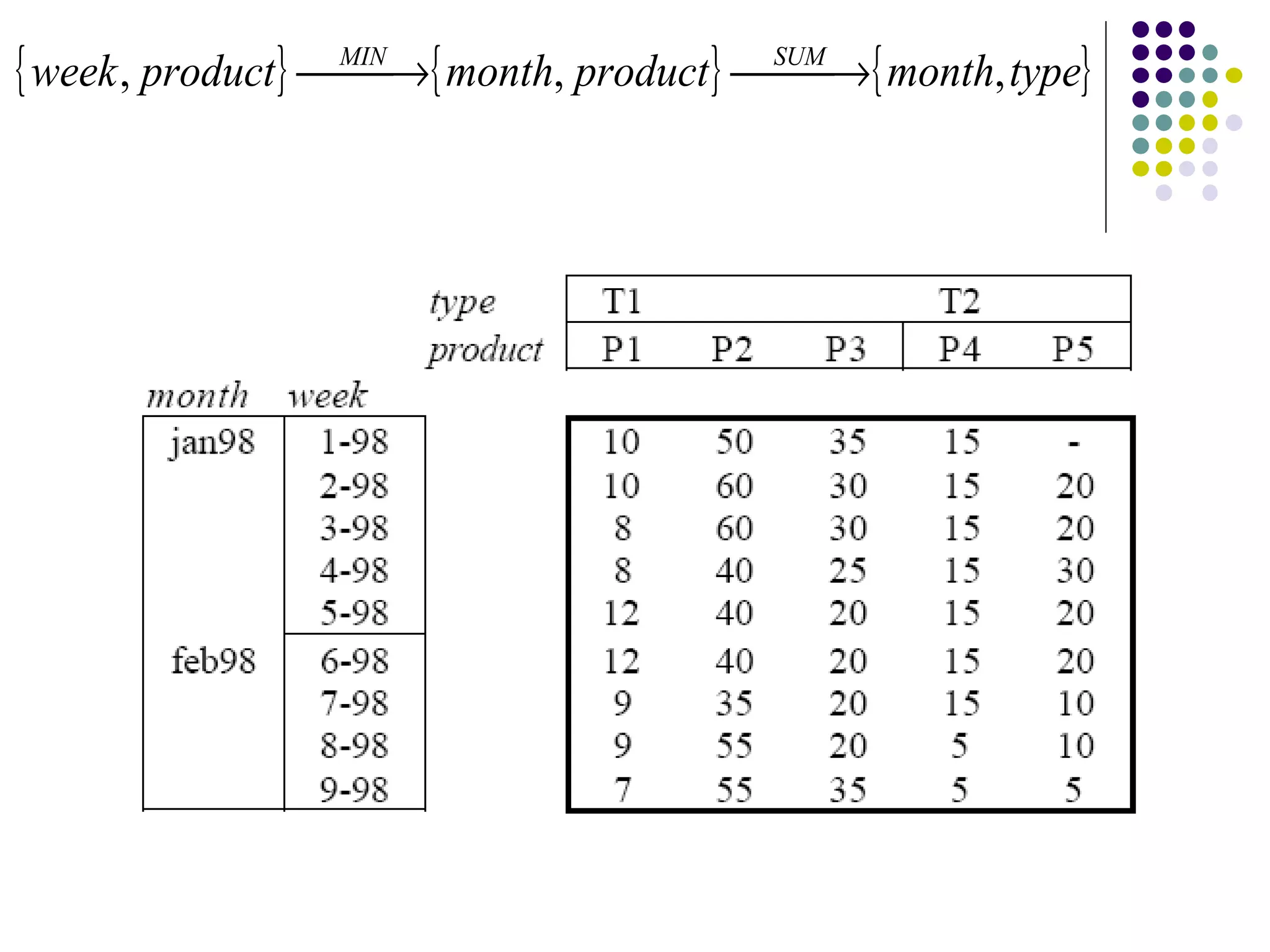
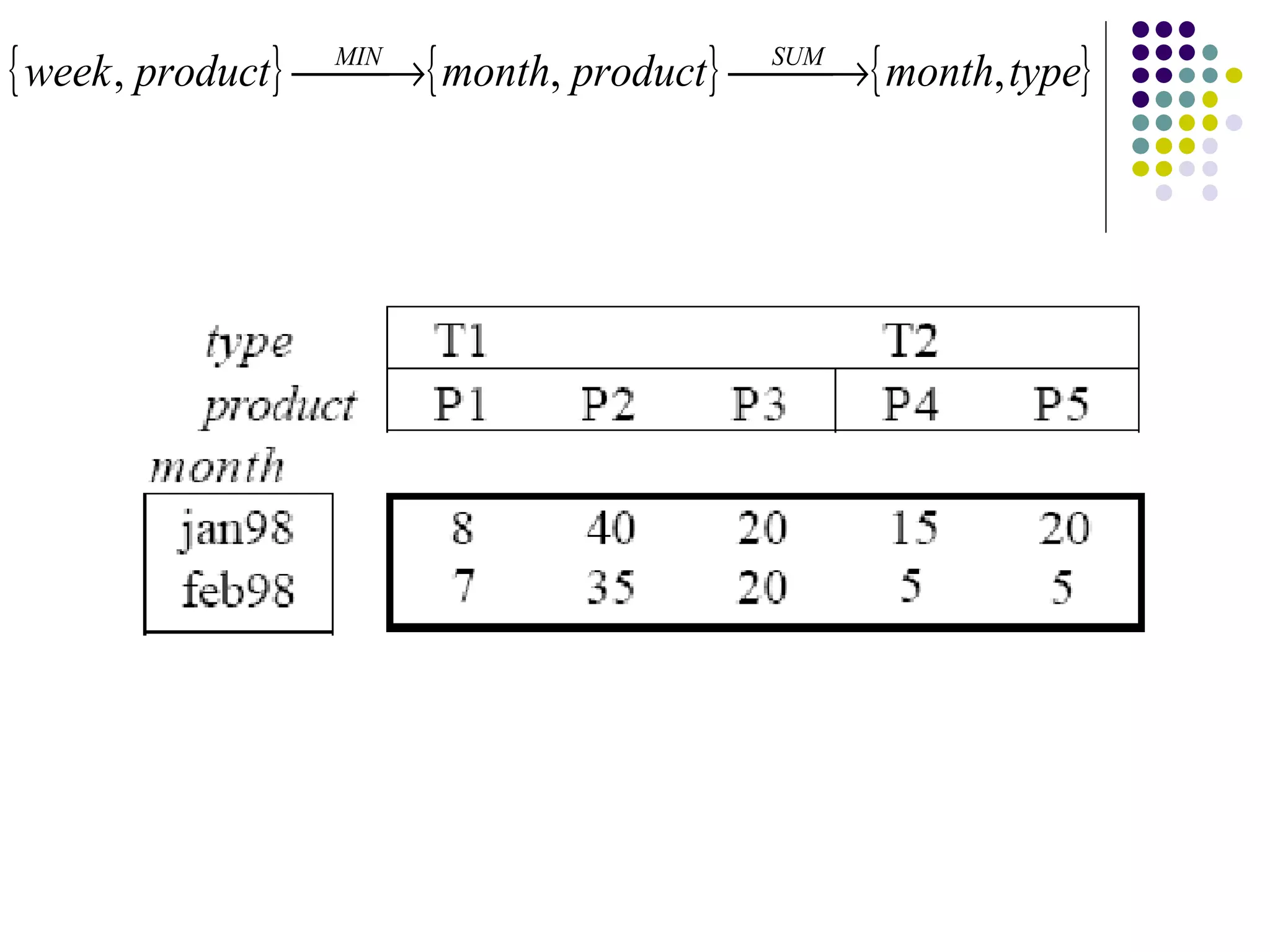
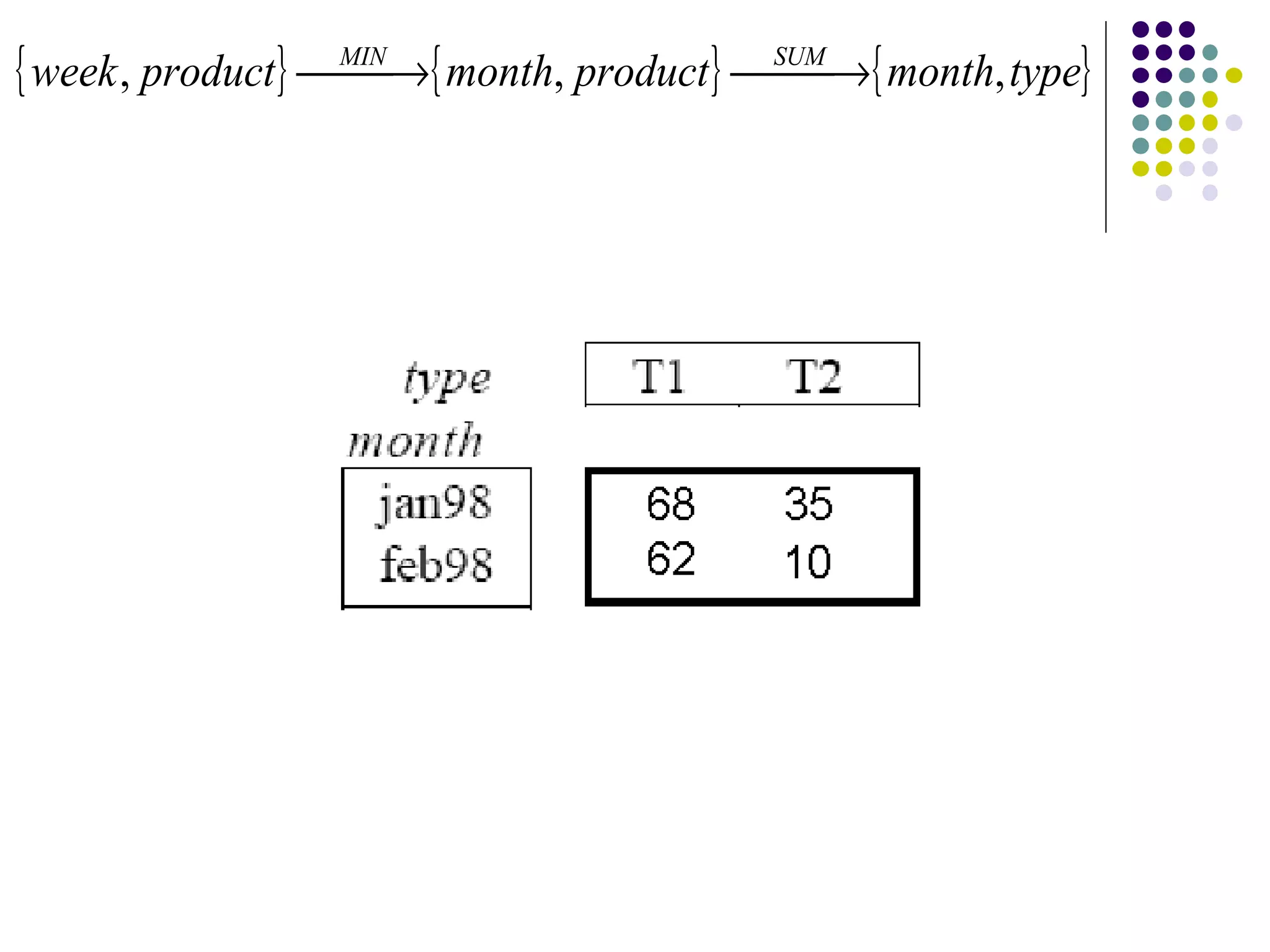
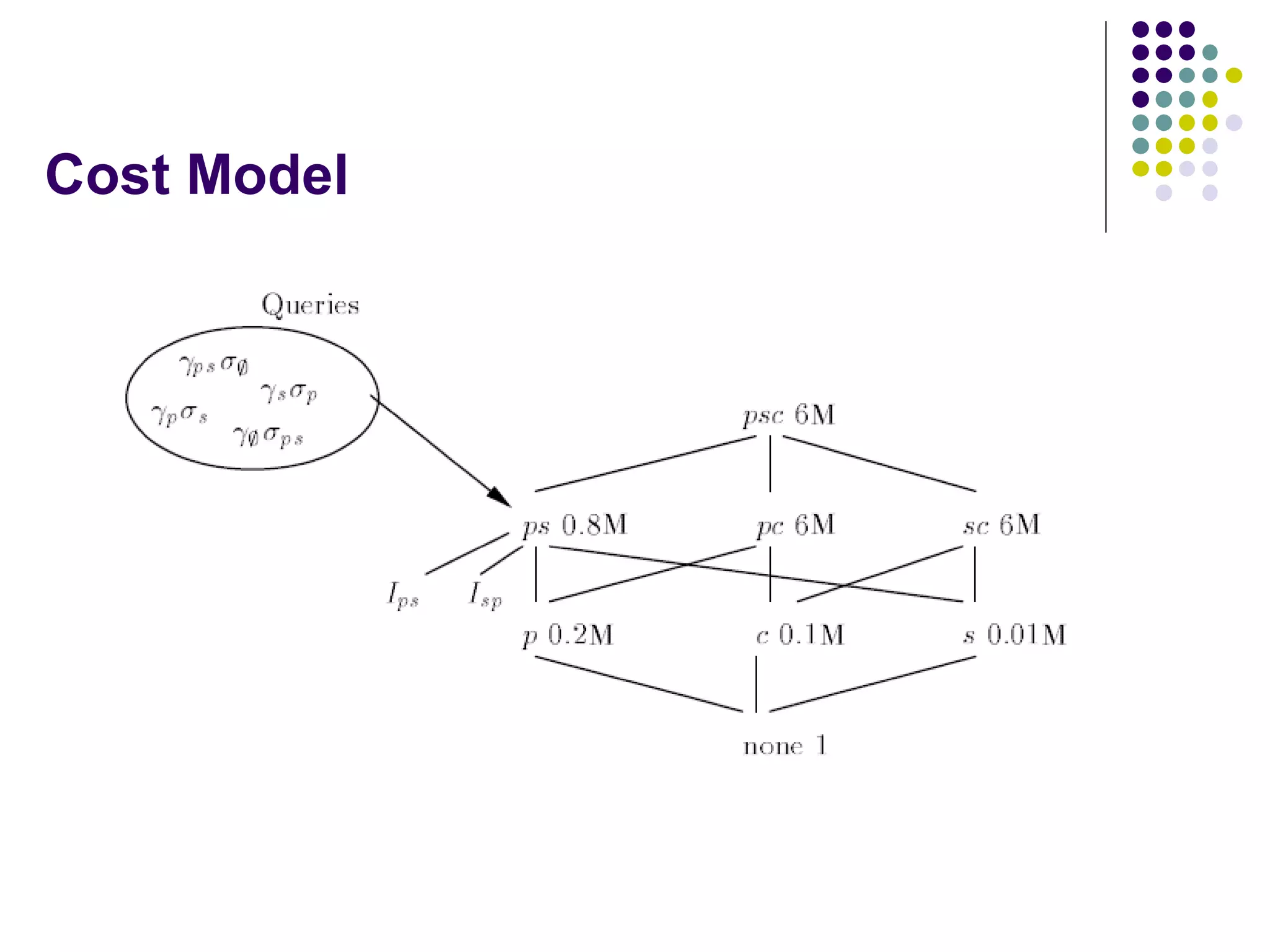
This document provides an overview of data warehousing concepts including dimensional modeling, online analytical processing (OLAP), and indexing techniques. It discusses the evolution of data warehousing, definitions of data warehouses, architectures, and common applications. Dimensional modeling concepts such as star schemas, snowflake schemas, and slowly changing dimensions are explained. The presentation concludes with references for further reading.













































































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
