Recommended
PDF
SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~
PDF
【メタサーベイ】基盤モデル / Foundation Models
PDF
PDF
PDF
PDF
PPTX
MS COCO Dataset Introduction
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
PDF
PDF
【DL輪読会】Code as Policies: Language Model Programs for Embodied Control
PDF
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
PDF
【DL輪読会】Poisoning Language Models During Instruction Tuning Instruction Tuning...
PDF
PDF
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
PPTX
[DL輪読会]Graph R-CNN for Scene Graph Generation
PDF
PDF
PPTX
[DL輪読会]GQNと関連研究,世界モデルとの関係について
PDF
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
PPTX
【DL輪読会】Reward Design with Language Models
PPTX
【DL輪読会】"Instant Neural Graphics Primitives with a Multiresolution Hash Encoding"
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
PDF
【DL輪読会】NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics vi...
PPTX
【輪読会】Learning Continuous Image Representation with Local Implicit Image Funct...
PPTX
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
PPTX
【論文紹介】Distributed Representations of Sentences and Documents
More Related Content
PDF
SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~
PDF
【メタサーベイ】基盤モデル / Foundation Models
PDF
PDF
PDF
PDF
PPTX
MS COCO Dataset Introduction
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
What's hot
PDF
PDF
【DL輪読会】Code as Policies: Language Model Programs for Embodied Control
PDF
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
PDF
【DL輪読会】Poisoning Language Models During Instruction Tuning Instruction Tuning...
PDF
PDF
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
PPTX
[DL輪読会]Graph R-CNN for Scene Graph Generation
PDF
PDF
PPTX
[DL輪読会]GQNと関連研究,世界モデルとの関係について
PDF
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
PPTX
【DL輪読会】Reward Design with Language Models
PPTX
【DL輪読会】"Instant Neural Graphics Primitives with a Multiresolution Hash Encoding"
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
PDF
【DL輪読会】NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics vi...
PPTX
【輪読会】Learning Continuous Image Representation with Local Implicit Image Funct...
Similar to NIPS2013読み会: Distributed Representations of Words and Phrases and their Compositionality
PPTX
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
PPTX
【論文紹介】Distributed Representations of Sentences and Documents
PPTX
Neural word embedding as implicit matrix factorization の論文紹介
PDF
Distributed Representations of Words and Phrases and their Compositionally
PDF
PDF
GeneratingWikipedia_ICLR18_論文紹介
PDF
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
PDF
Learning Image Embeddings using Convolutional Neural Networks for Improved Mu...
PDF
ACL読み会@PFI �“How to make words with vectors: Phrase generation in distributio...
PDF
PDF
PPTX
Machine Learning Seminar (5)
PDF
A scalable probablistic classifier for language modeling: ACL 2011 読み会
PPTX
dont_count_predict_in_acl2014
PDF
PDF
PDF
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
PPTX
PPTX
More from Yuya Unno
PDF
PDF
NIP2015読み会「End-To-End Memory Networks」
PDF
PDF
PDF
PDF
PDF
Chainerのテスト環境とDockerでのCUDAの利用
PDF
PDF
PDF
PDF
PDF
最先端NLP勉強会�“Learning Language Games through Interaction”�Sida I. Wang, Percy L...
PDF
PDF
PDF
PDF
PDF
PDF
PDF
ベンチャー企業で言葉を扱うロボットの研究開発をする
PDF
NIPS2013読み会: Distributed Representations of Words and Phrases and their Compositionality 1. 2. 3. 4. 5. 6. 7. Hierarchical Softmax (HS) [Morin+05]
ルートからw
までの全ノー
ドで積をとる
りんご
n3
n1
n2
みかん
カレー
ラーメン
各ノードのベ
クトル
σ(x)=1/(1 + exp(-x))
l
l
単語で⽊木を作り、ルートからその単語までの各ノードの
ベクトルと内積をとり、そのシグモイドの積にする
計算量量が単語数の対数時間になる
7
8. 9. Negative Sampling (NEG) (提案⼿手法1)
log P(wo|wI) =
l
l
NCEをもっとサボった上式を使う
∑の中の期待値計算は、k個のサンプルを取って近似する
l
l
データが少ない時は5~20個、多ければ2~5個で充分
P(w)として、1-gram頻度度の3/4乗に⽐比例例させたときが
⼀一番良良かった
9
10. 11. 12. 13. 14. 15. 16. 参考⽂文献
l
l
l
[Mikolov+13] Tomas Mikolov, Kai Chen, Greg
Corrado, and Jeffrey Dean. Efficient estimation of
word representations in vector space. ICLR 2013.
[Morin+05] Frederic Morin and Yoshua Bengio.
Hierarchical probabilistic neural network language
model. AISTATS 2005.
[Gutmann+12] Michael U. Gutmann and Aapo
Hyvarinen. Noise-Contrastive Estimation of
Unnormalized Statistical Models, with Applications
to Natural Image Statistics. JMLR 2012.
16



![word2vec [Mikolov+13]
l
l
各単語の「意味」を表現するベクトルを作るはなし
vec(Berlin) – vec(German) + vec(France) と⼀一番近い単
語を探したら、vec(Paris)だった
l
ベクトルの作り⽅方は次のスライドで説明
Paris!!
France
German
Berlin
4](https://image.slidesharecdn.com/20140123nips2013-distributed-representation-140122215049-phpapp01/75/NIPS2013-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality-4-2048.jpg)
![Skip gramモデル[Mikolov+13]の⽬目的関数
l
⼊入⼒力力コーパス: w1, w2, …, wT (wiは単語)
これを最
⼤大化
cは文脈サイズで5くらい
vwは単語wを表現するようなベクトル(適当な次元)で、
これらを推定したい
5](https://image.slidesharecdn.com/20140123nips2013-distributed-representation-140122215049-phpapp01/75/NIPS2013-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality-5-2048.jpg)
![問題点
l
語彙数が多すぎて∑の計算が⼤大変
l
l
W = 105 ~ 107
いかに効率率率よく計算をサボるかがこの論論⽂文の主題
6
[Mikolov+13]より](https://image.slidesharecdn.com/20140123nips2013-distributed-representation-140122215049-phpapp01/75/NIPS2013-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality-6-2048.jpg)
![Hierarchical Softmax (HS) [Morin+05]
ルートからw
までの全ノー
ドで積をとる
りんご
n3
n1
n2
みかん
カレー
ラーメン
各ノードのベ
クトル
σ(x)=1/(1 + exp(-x))
l
l
単語で⽊木を作り、ルートからその単語までの各ノードの
ベクトルと内積をとり、そのシグモイドの積にする
計算量量が単語数の対数時間になる
7](https://image.slidesharecdn.com/20140123nips2013-distributed-representation-140122215049-phpapp01/75/NIPS2013-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality-7-2048.jpg)
![Noise Contrastive Estimation (NCE) [Gutmann
+12]
l
l
本題から外れるので割愛
Softmaxによる分布を近似するらしい
8](https://image.slidesharecdn.com/20140123nips2013-distributed-representation-140122215049-phpapp01/75/NIPS2013-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality-8-2048.jpg)


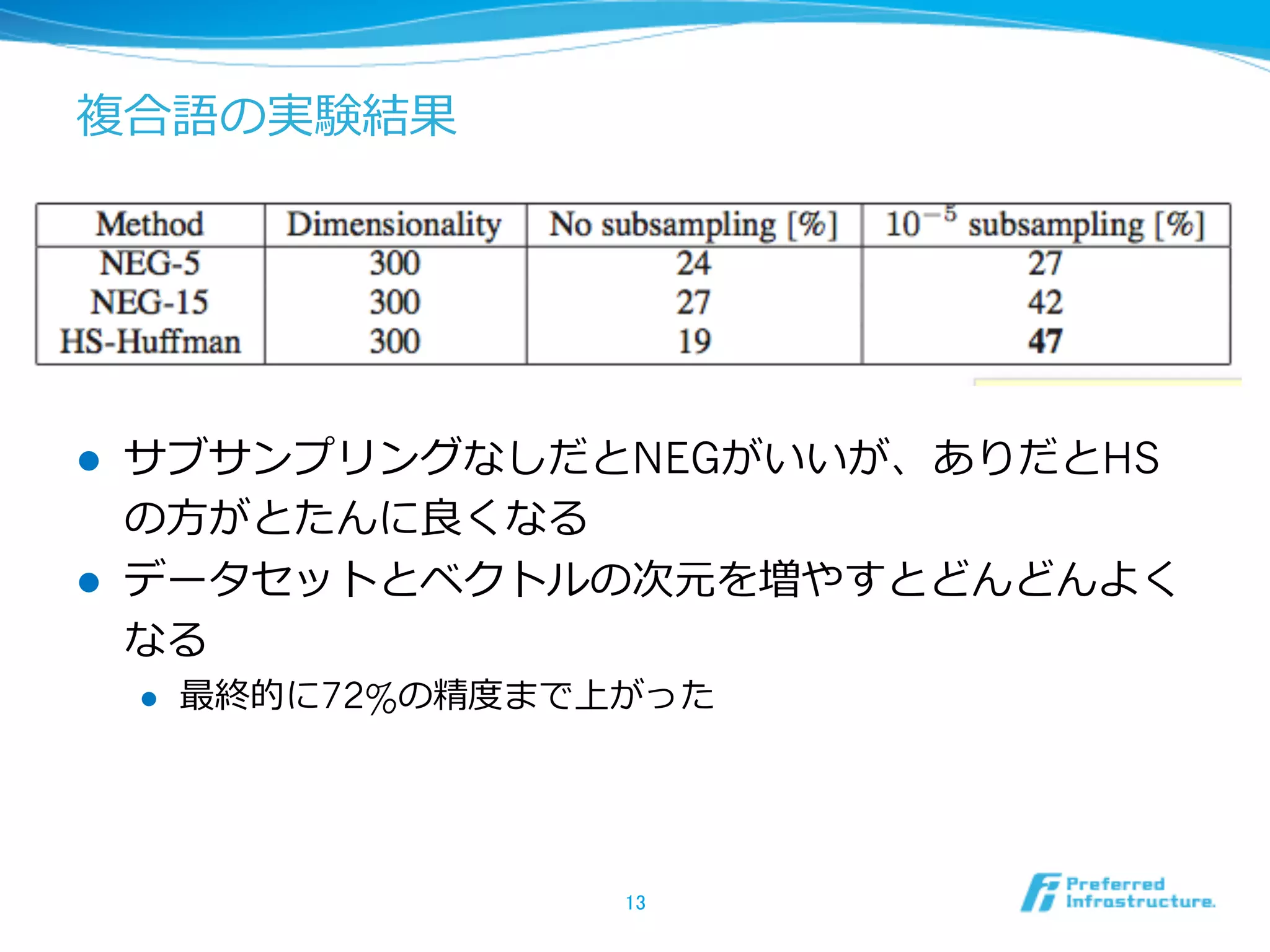
![実験結果
l
[Mikolov+13]でやったanalogical reasoning taskで評価
l
l
l
vec(Berlin) – vec(Germany) + vec(France)の近傍探索索で
vec(Paris)を⾒見見つける
NEGがHierarchical SoftmaxやNCEよりも⾼高精度度
サブサンプリングも効果的
小さい方がいい
11
大きい方がいい](https://image.slidesharecdn.com/20140123nips2013-distributed-representation-140122215049-phpapp01/75/NIPS2013-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality-11-2048.jpg)



![参考⽂文献
l
l
l
[Mikolov+13] Tomas Mikolov, Kai Chen, Greg
Corrado, and Jeffrey Dean. Efficient estimation of
word representations in vector space. ICLR 2013.
[Morin+05] Frederic Morin and Yoshua Bengio.
Hierarchical probabilistic neural network language
model. AISTATS 2005.
[Gutmann+12] Michael U. Gutmann and Aapo
Hyvarinen. Noise-Contrastive Estimation of
Unnormalized Statistical Models, with Applications
to Natural Image Statistics. JMLR 2012.
16](https://image.slidesharecdn.com/20140123nips2013-distributed-representation-140122215049-phpapp01/75/NIPS2013-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality-16-2048.jpg)

![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)









































