Downloaded 107 times











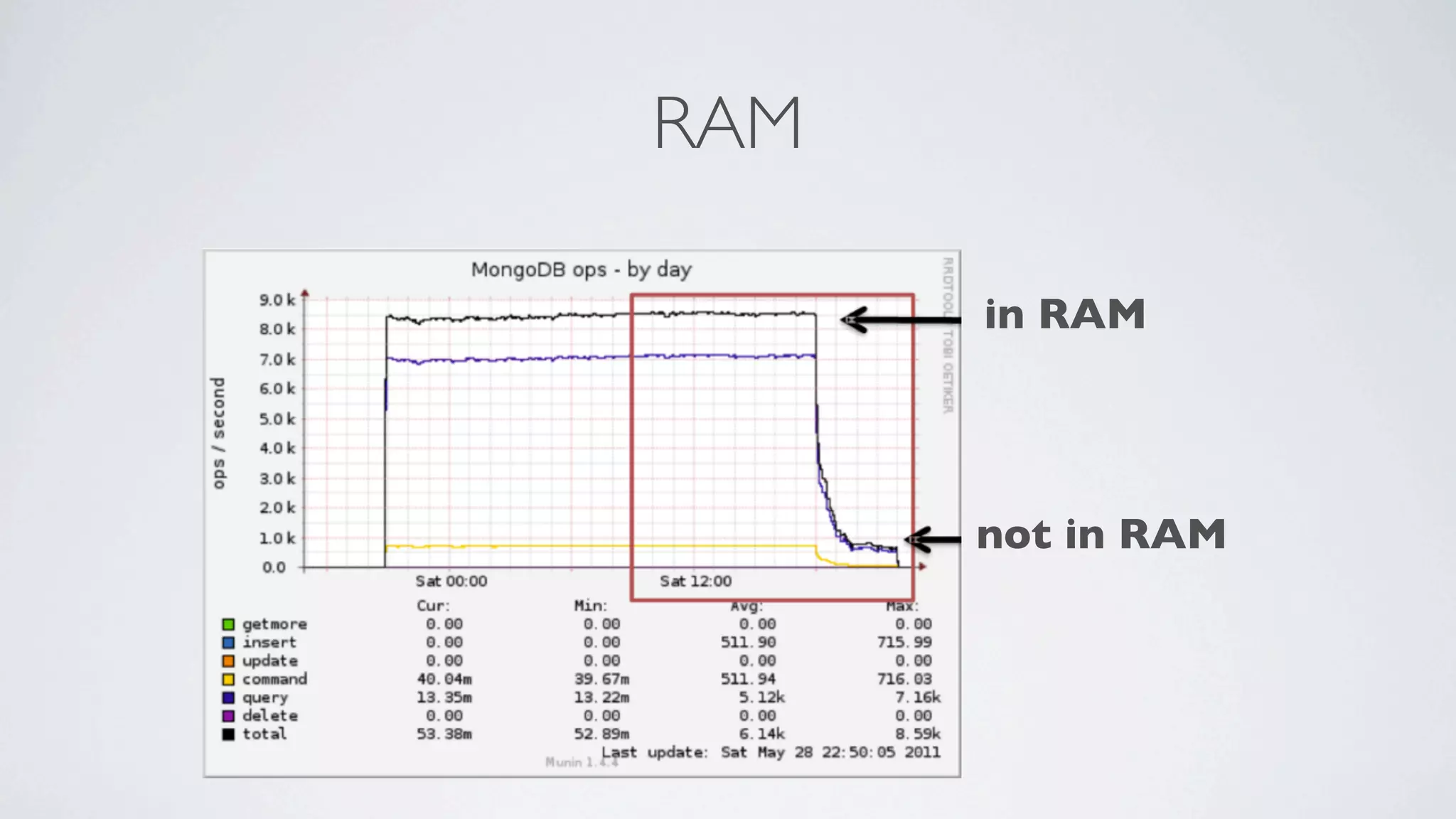






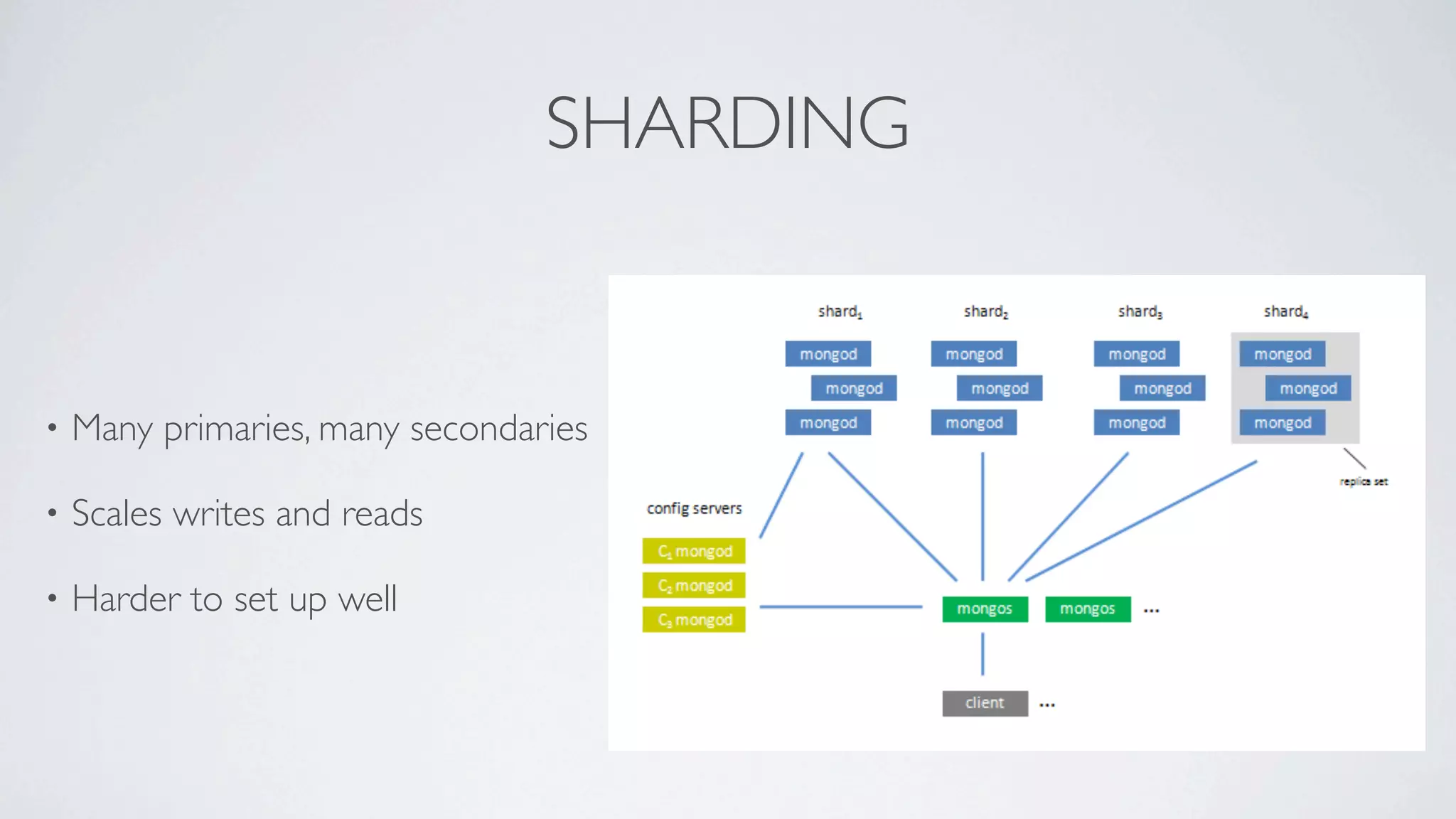












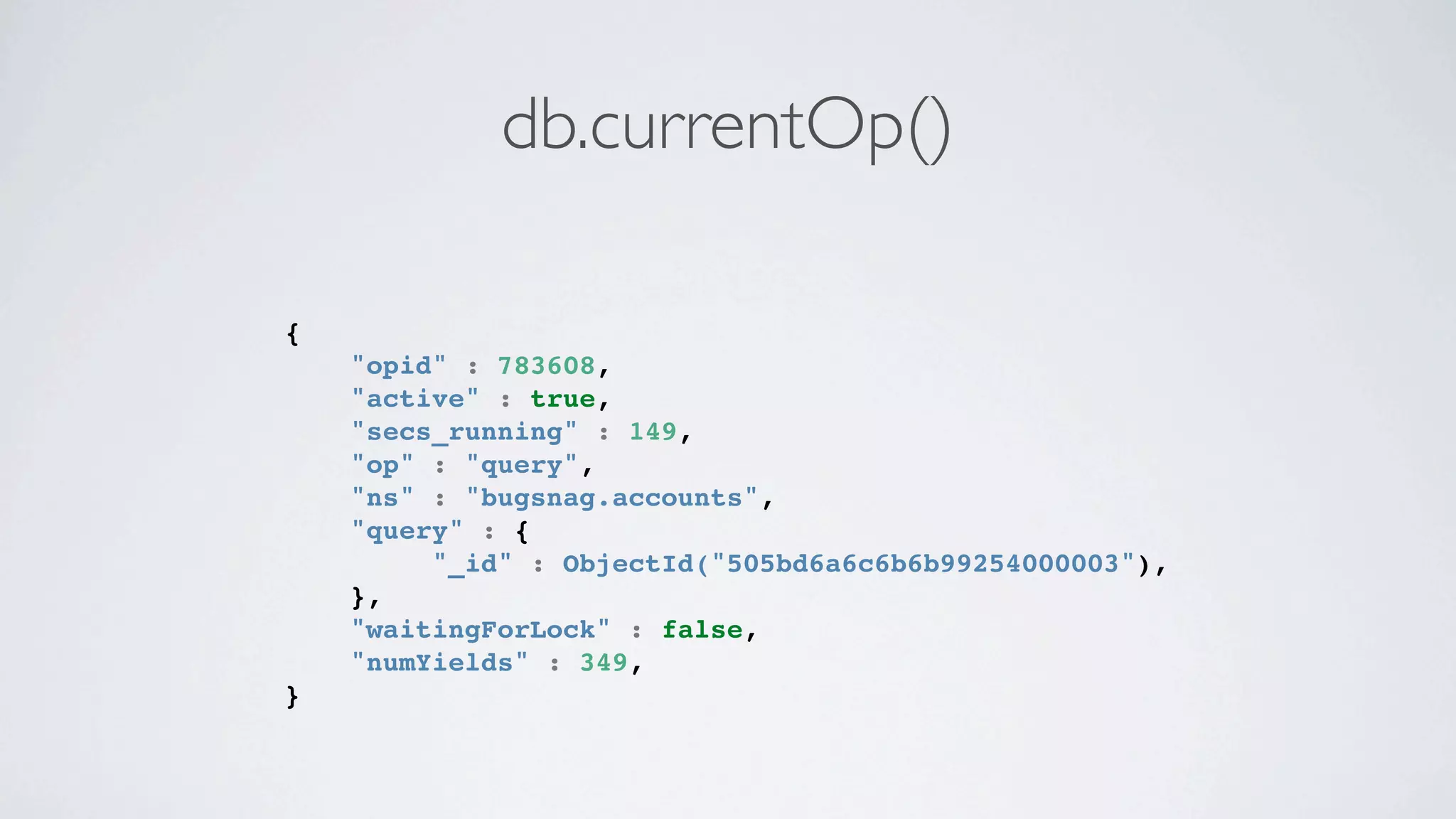



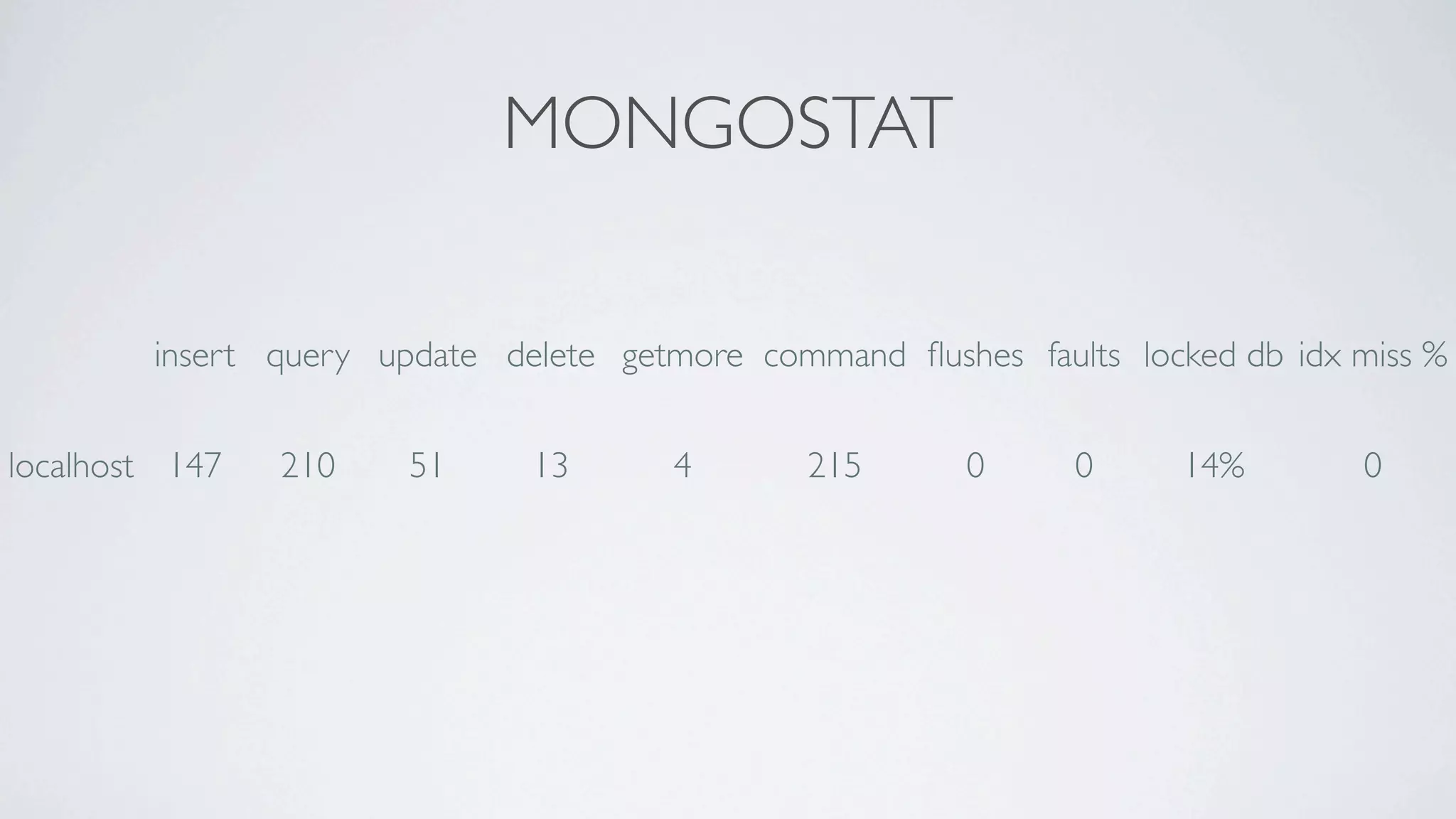

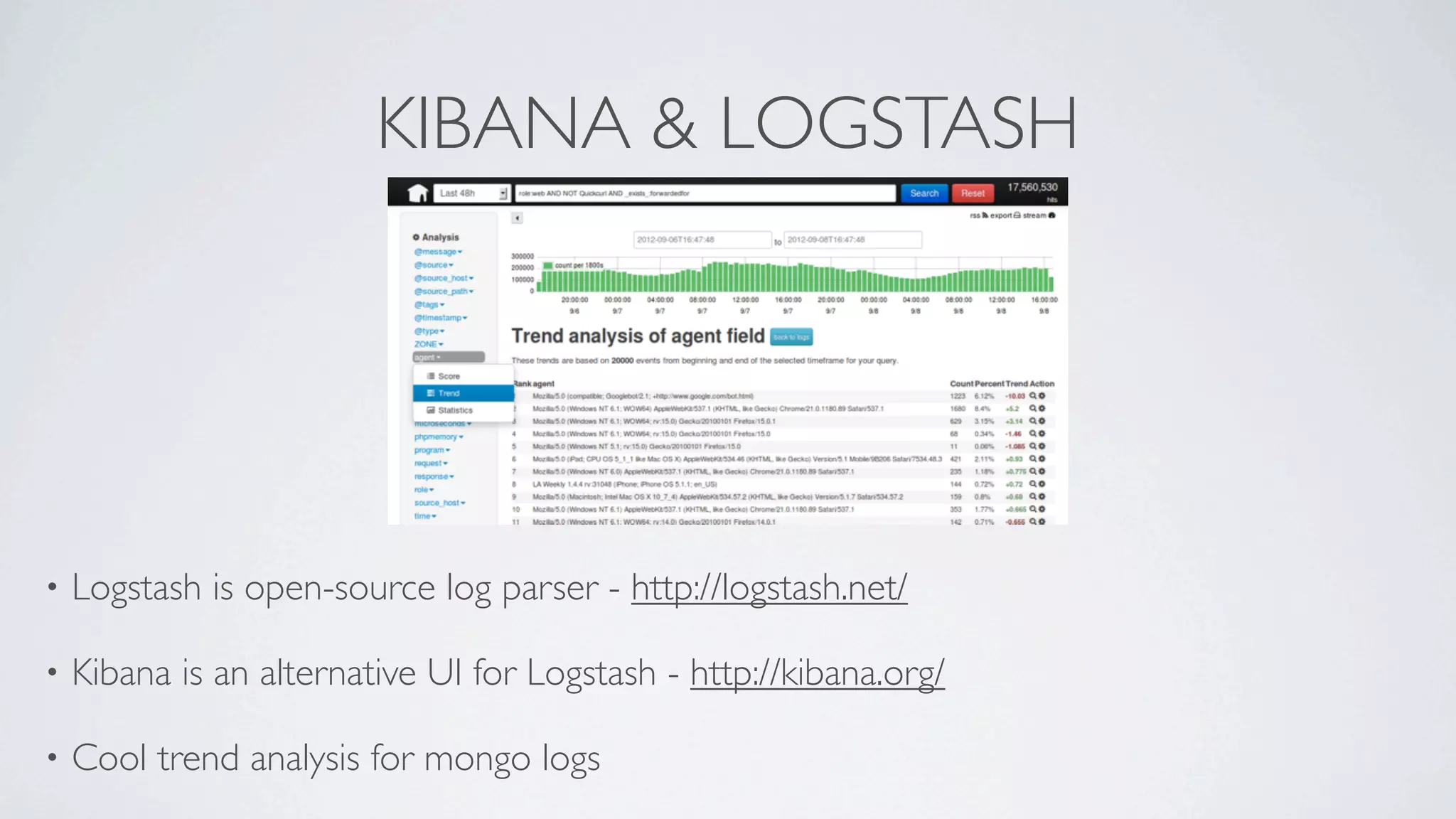


This document discusses scaling MongoDB in the cloud. It covers Simon Maynard's experience using MongoDB at Heyzap and Bugsnag, the pros and cons of MongoDB, when to consider scaling, key resources like RAM and I/O, architectural approaches like replica sets and sharding, schema design techniques, profiling and monitoring tools. Monitoring includes tools like db.currentOp(), db.serverStatus(), db.stats(), mongotop, mongostat, and third party services like MongoDB Monitoring Service (MMS), Kibana and Logstash.



































































