Download as PDF, PPTX






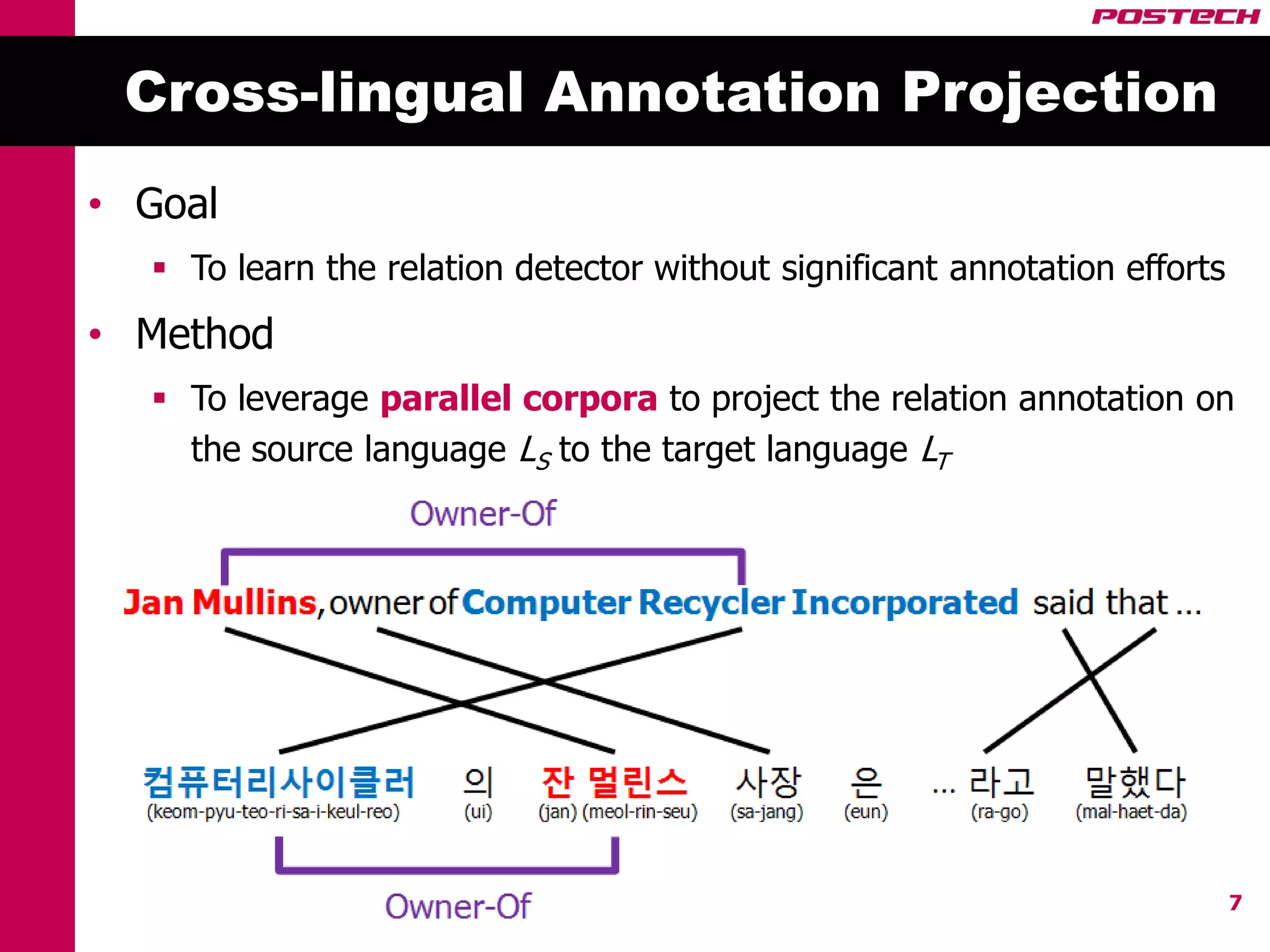

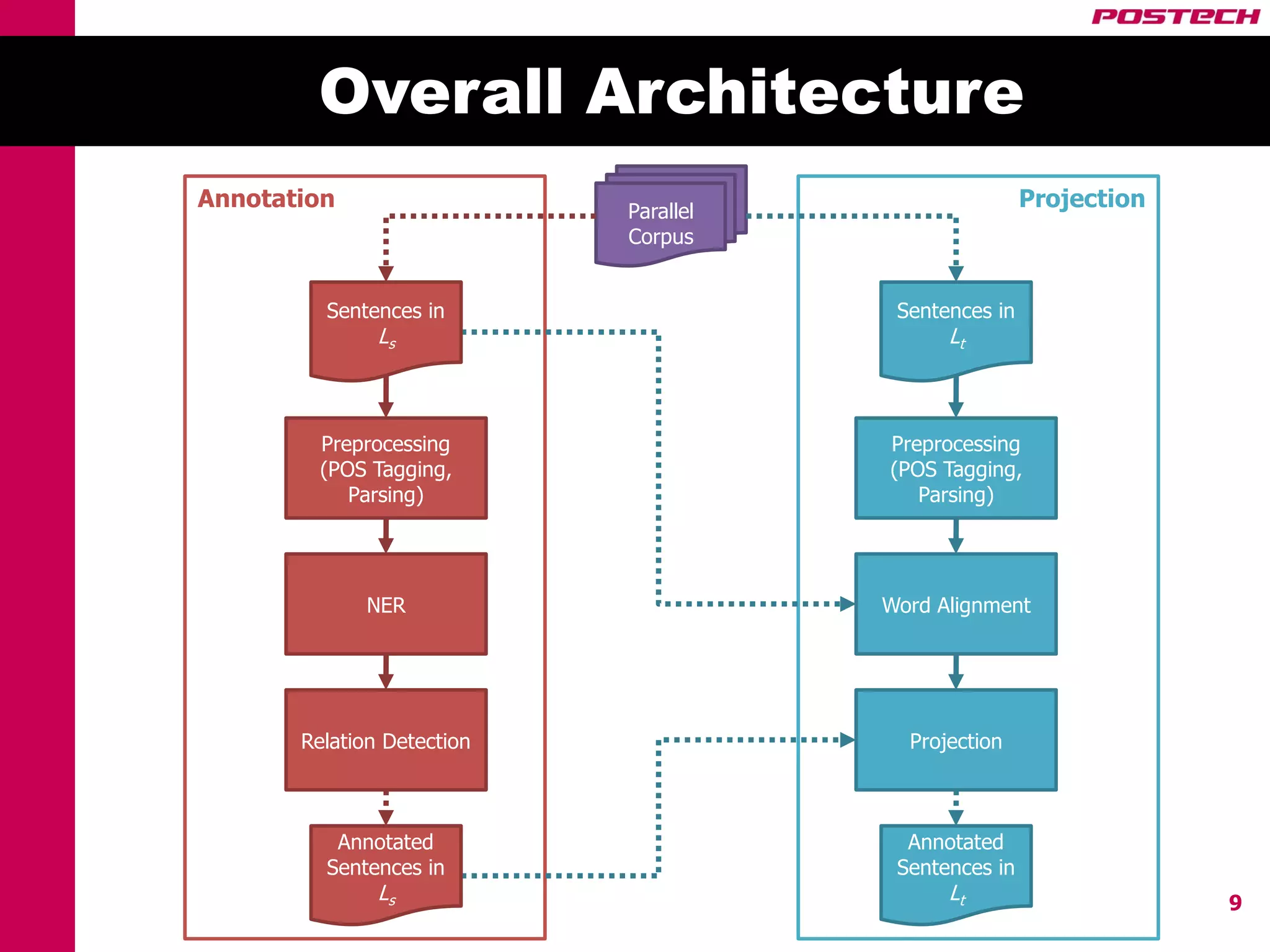



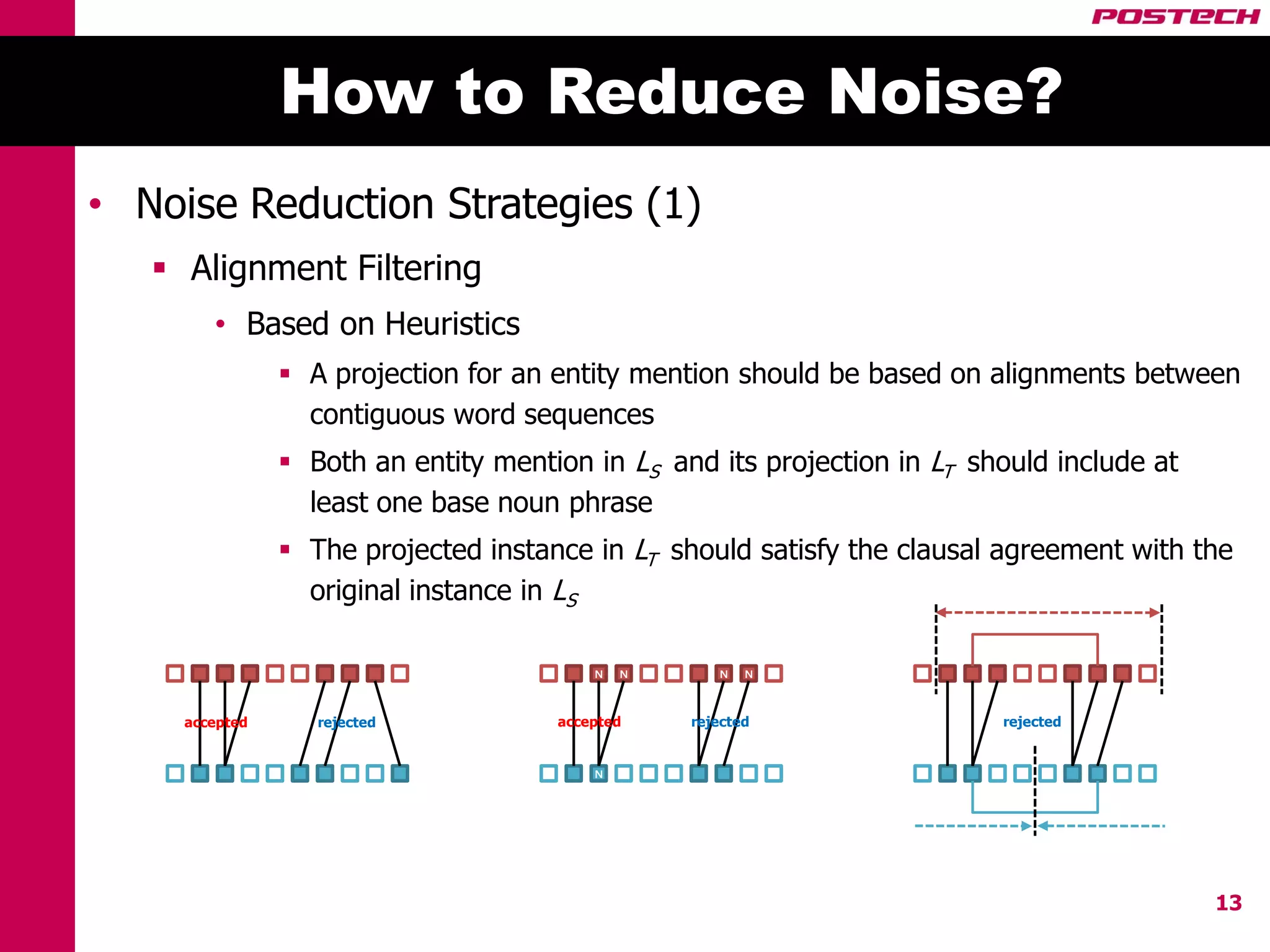









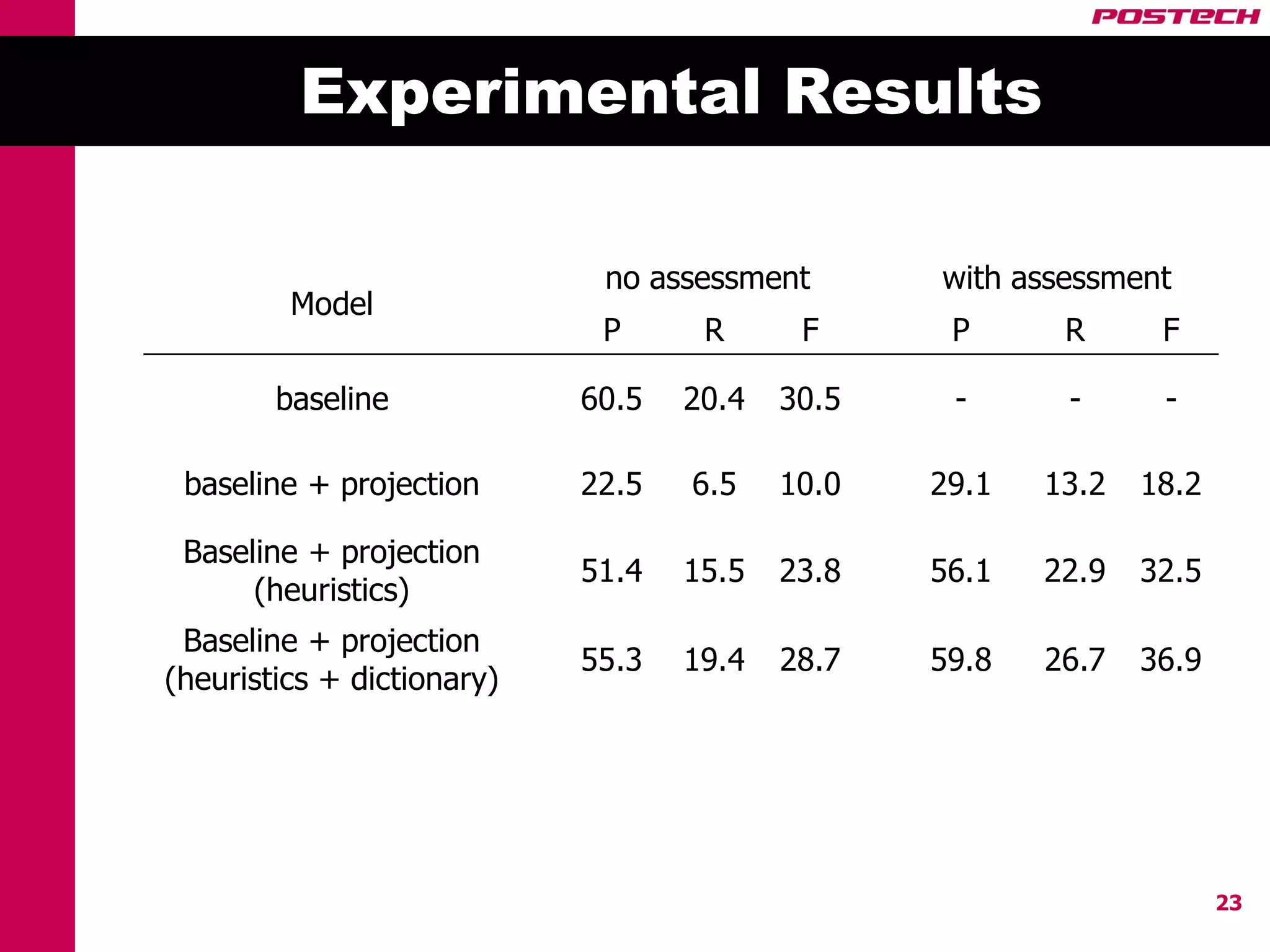
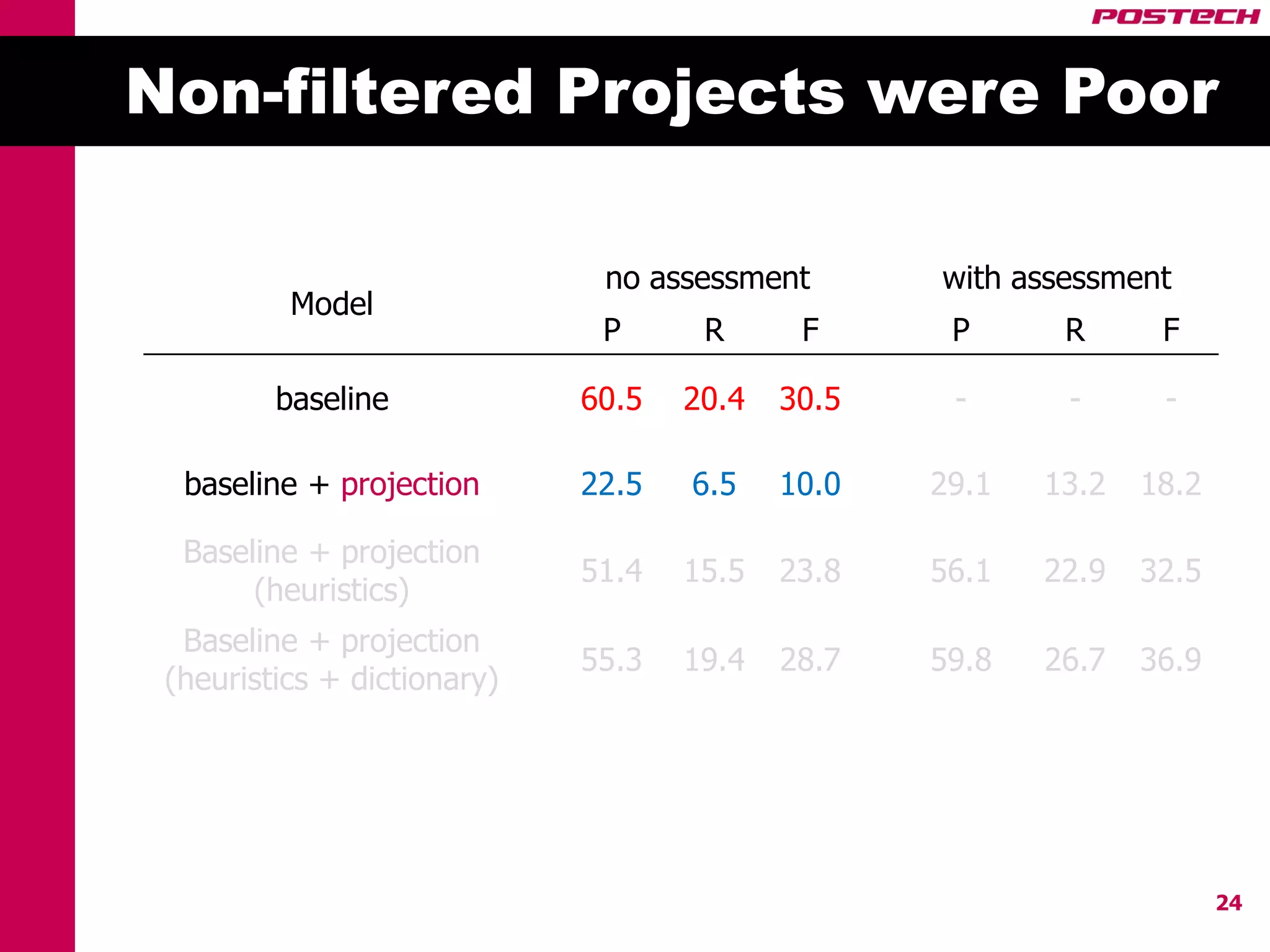
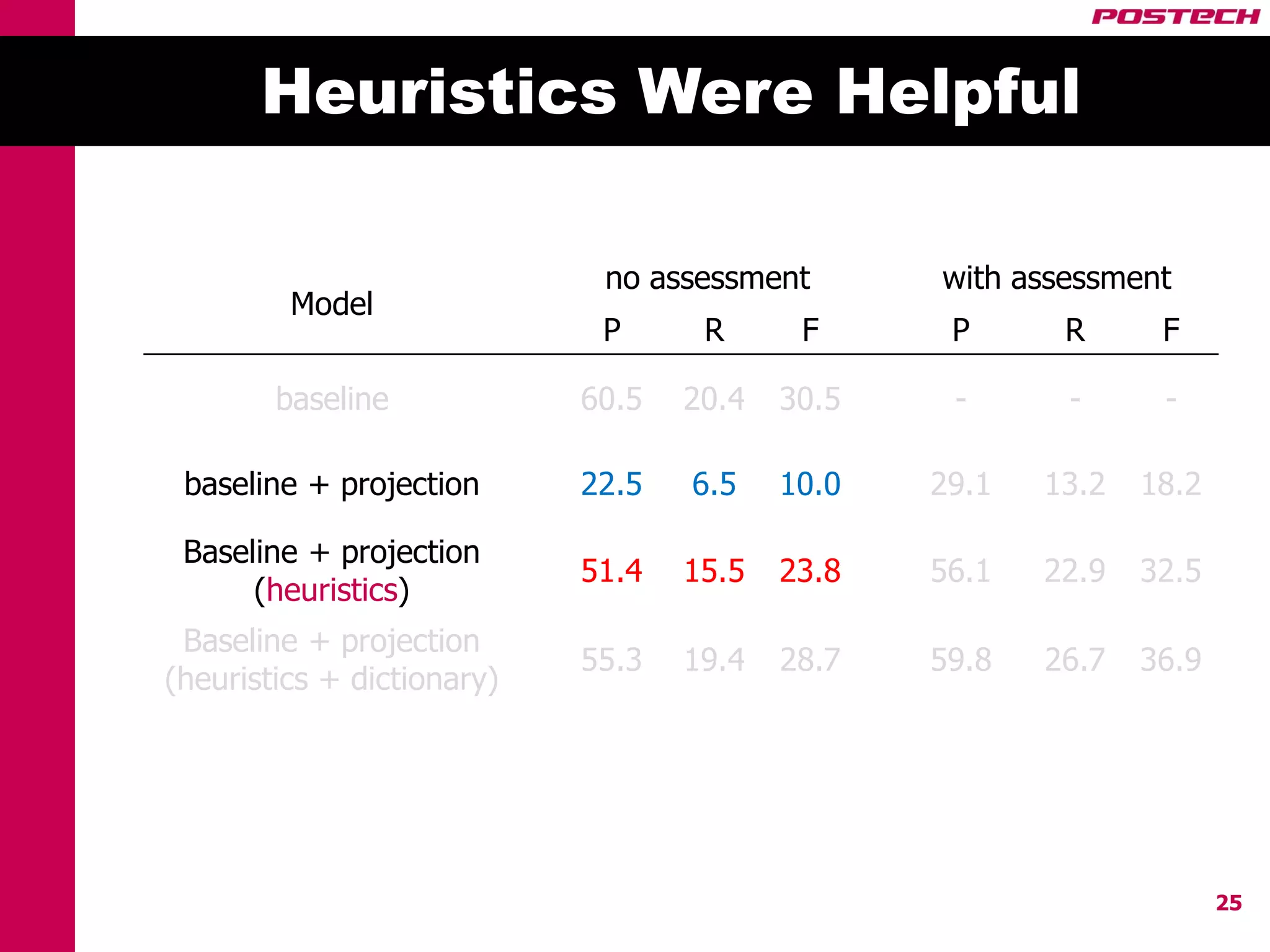
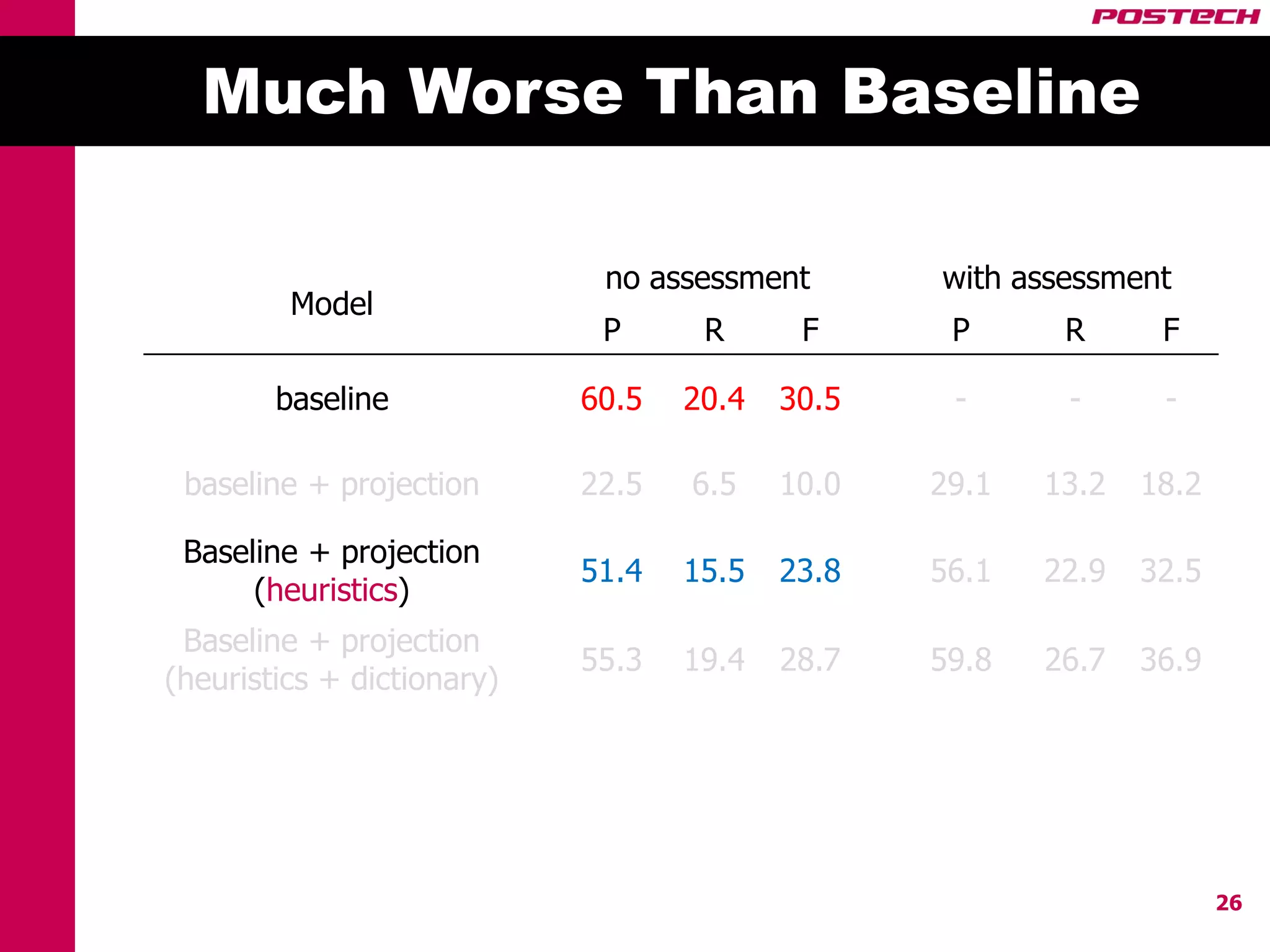
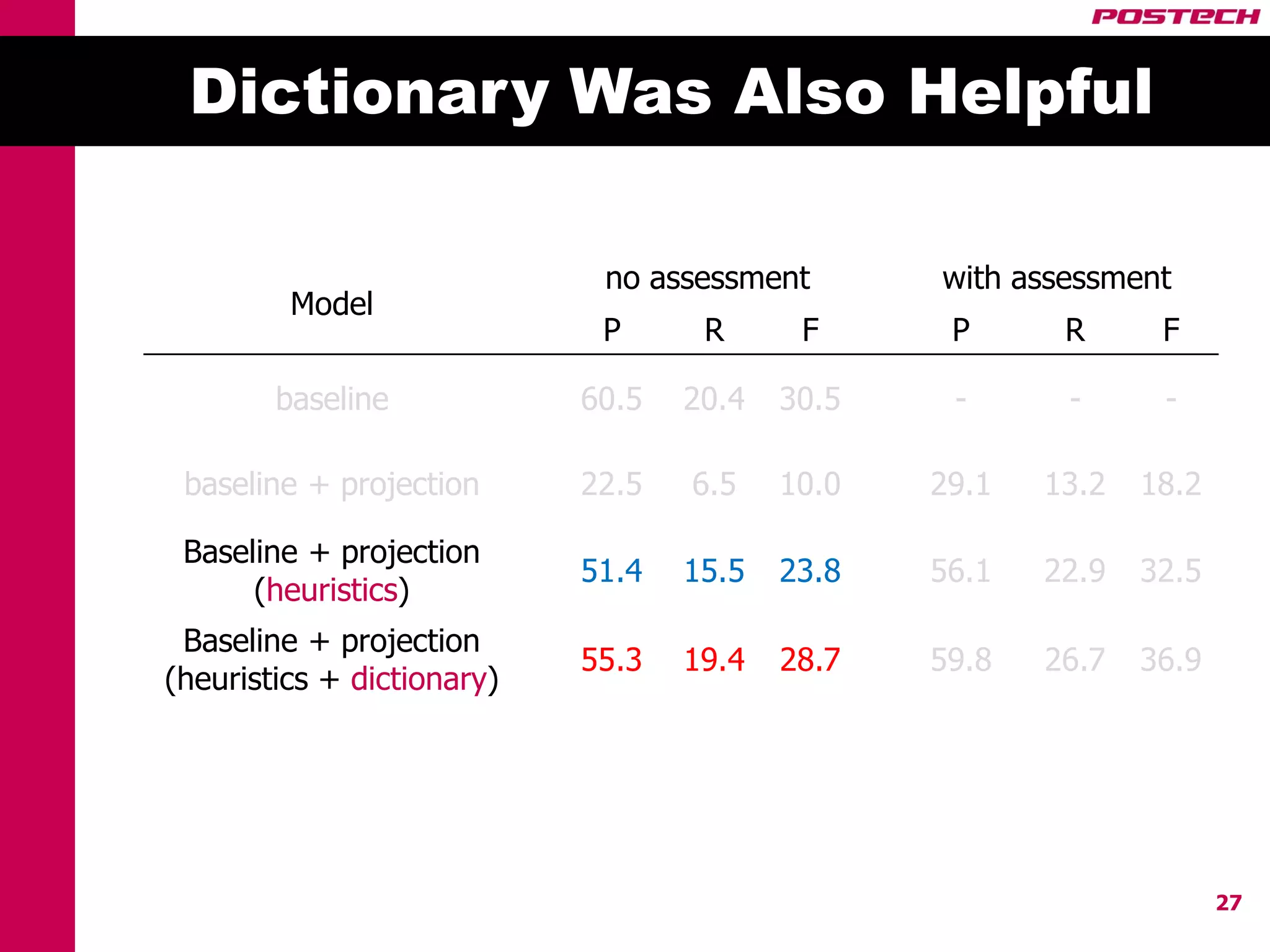
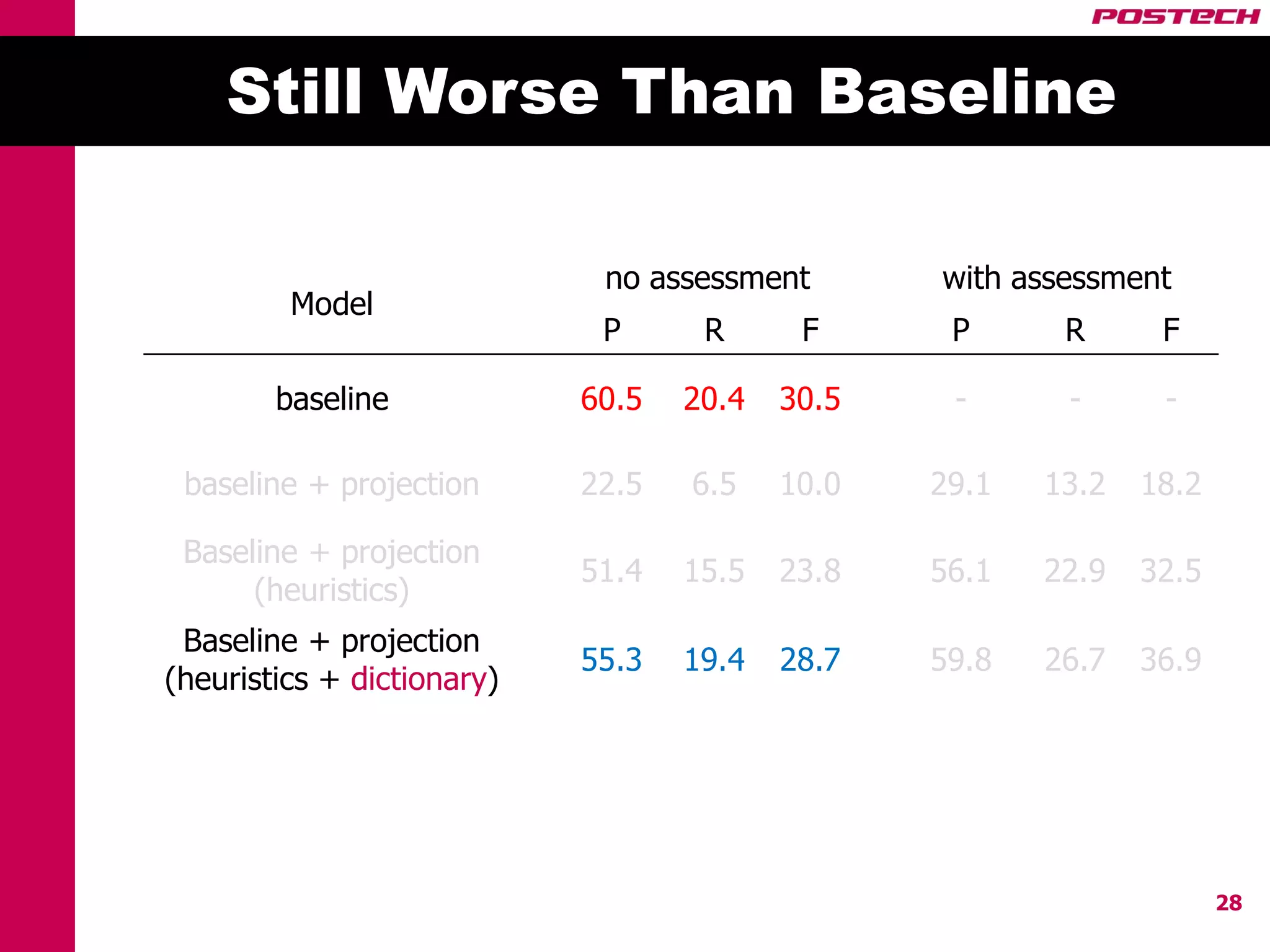
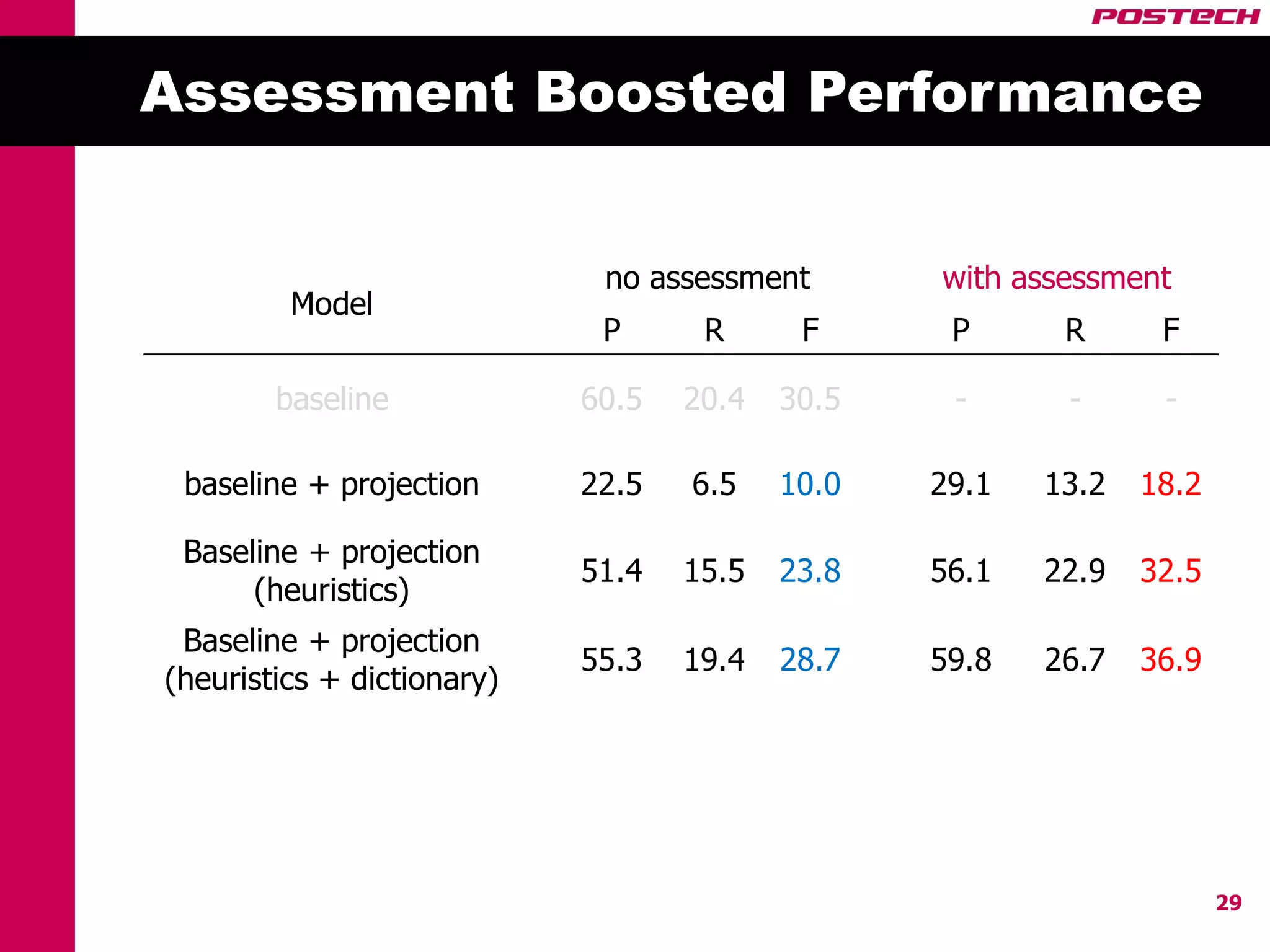





This document describes a method for cross-lingual annotation projection to detect relations in a target language without extensive annotation efforts. It projects relation annotations from a source language to a target language using word alignments from a parallel corpus. It introduces strategies to reduce noise from the projection process, including alignment filtering based on heuristics, alignment correction using a bilingual dictionary, and instance selection based on relation detection confidence scores. The method is evaluated on projecting relation annotations from English to Korean sentences.

















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)









