Download to read offline





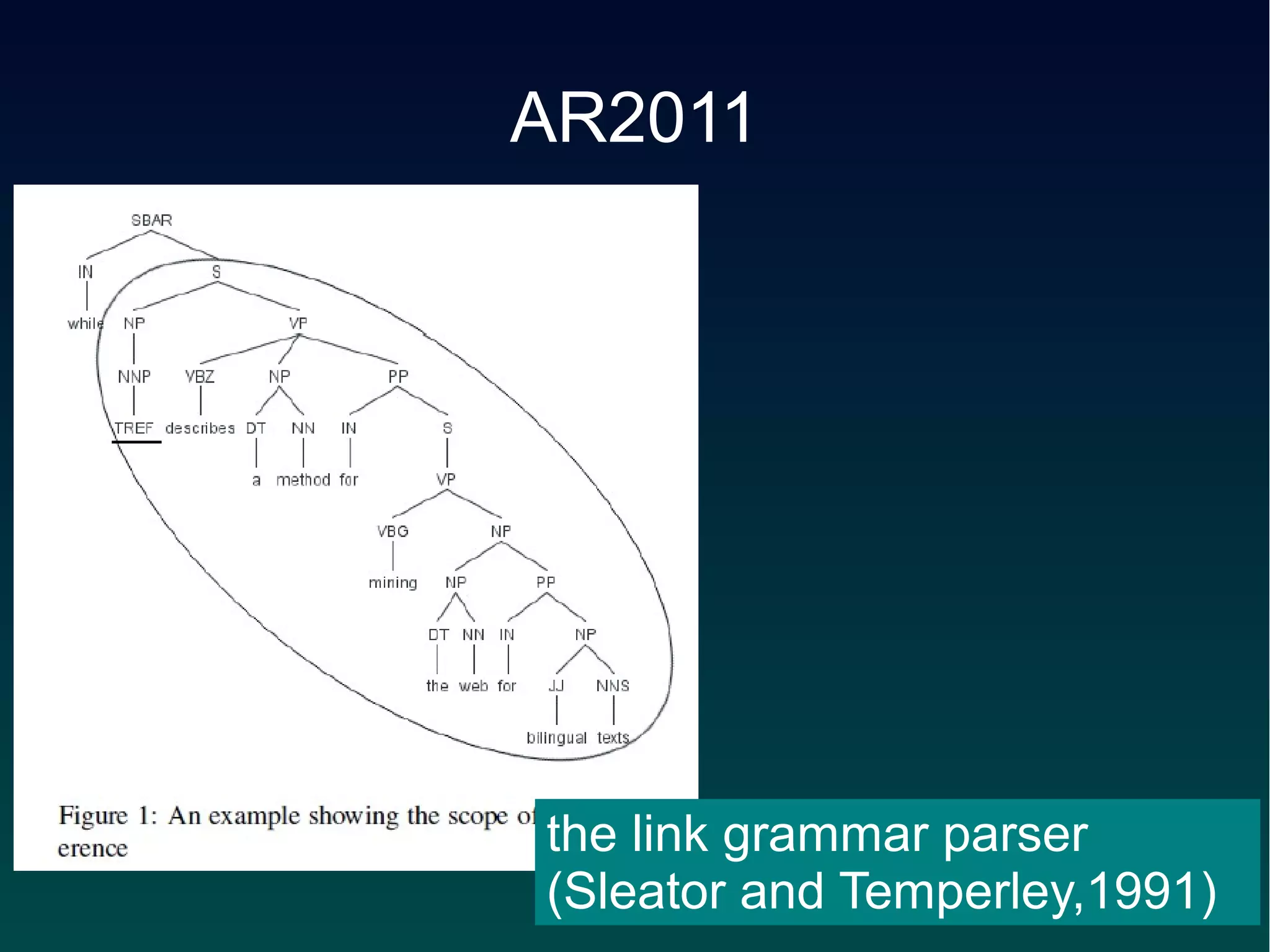
![Approach 3-S1-* (CRF/segment)
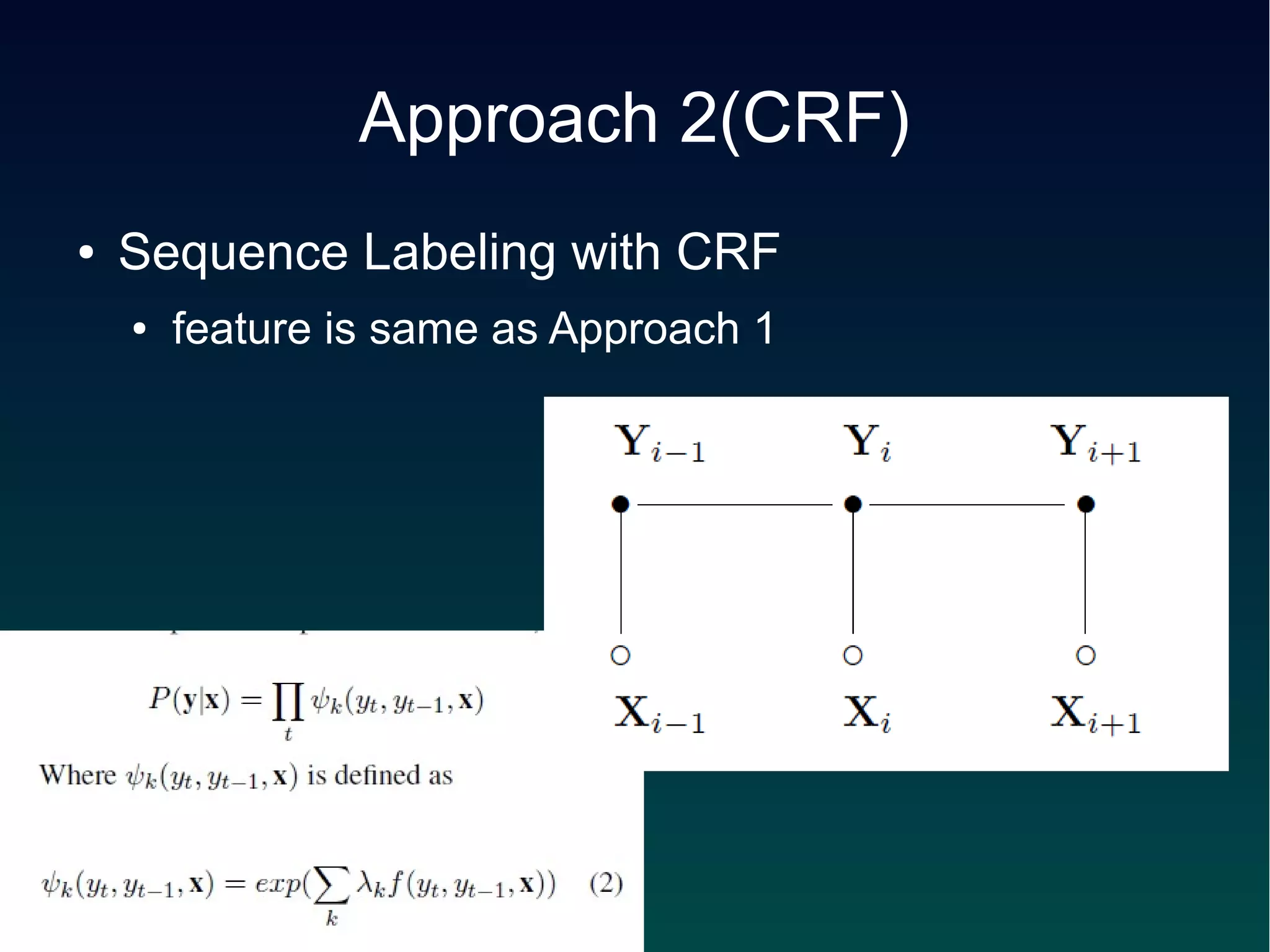
● segmentation (1)
● punctuation marks
● coordination conjunctions
– and, but, for, nor, or, so, yet
● a set of special expressions
– "for example", "for instance", "including", "includes",
"such as", "like", etc.
● [Rerankers have been successfully applied to numerous
NLP tasks such as] [parse selection (GTREF)], [parse
reranking (GREF)], [question-answering (REF)].](https://image.slidesharecdn.com/kameda-citation-121011035139-phpapp01/75/Reference-Scope-Identification-in-Citing-Sentences-7-2048.jpg)
![Approach 3-S2-* (CRF/segment)
● segmentation (2)
● chunking tool
– noun groups
– verb groups
– preposition groups
– adjective groups
– adverb groups
– other parts form segment by themselves
● [To] [score] [the output] [of] [the coreference models], [we]
[employ] [the commonly-used MUC scoring program (REF)]
[and] [the recently-developed CEAF scoring program (TREF)].](https://image.slidesharecdn.com/kameda-citation-121011035139-phpapp01/75/Reference-Scope-Identification-in-Citing-Sentences-8-2048.jpg)
![Approach 3-*-R1,2,3
(CRF/segment)
● R1: majority label of the words it contains
● R2: inside if any word is inside
● R3: outside if any word is outside
● [I O O O O] [I I I] [O O]](https://image.slidesharecdn.com/kameda-citation-121011035139-phpapp01/75/Reference-Scope-Identification-in-Citing-Sentences-9-2048.jpg)





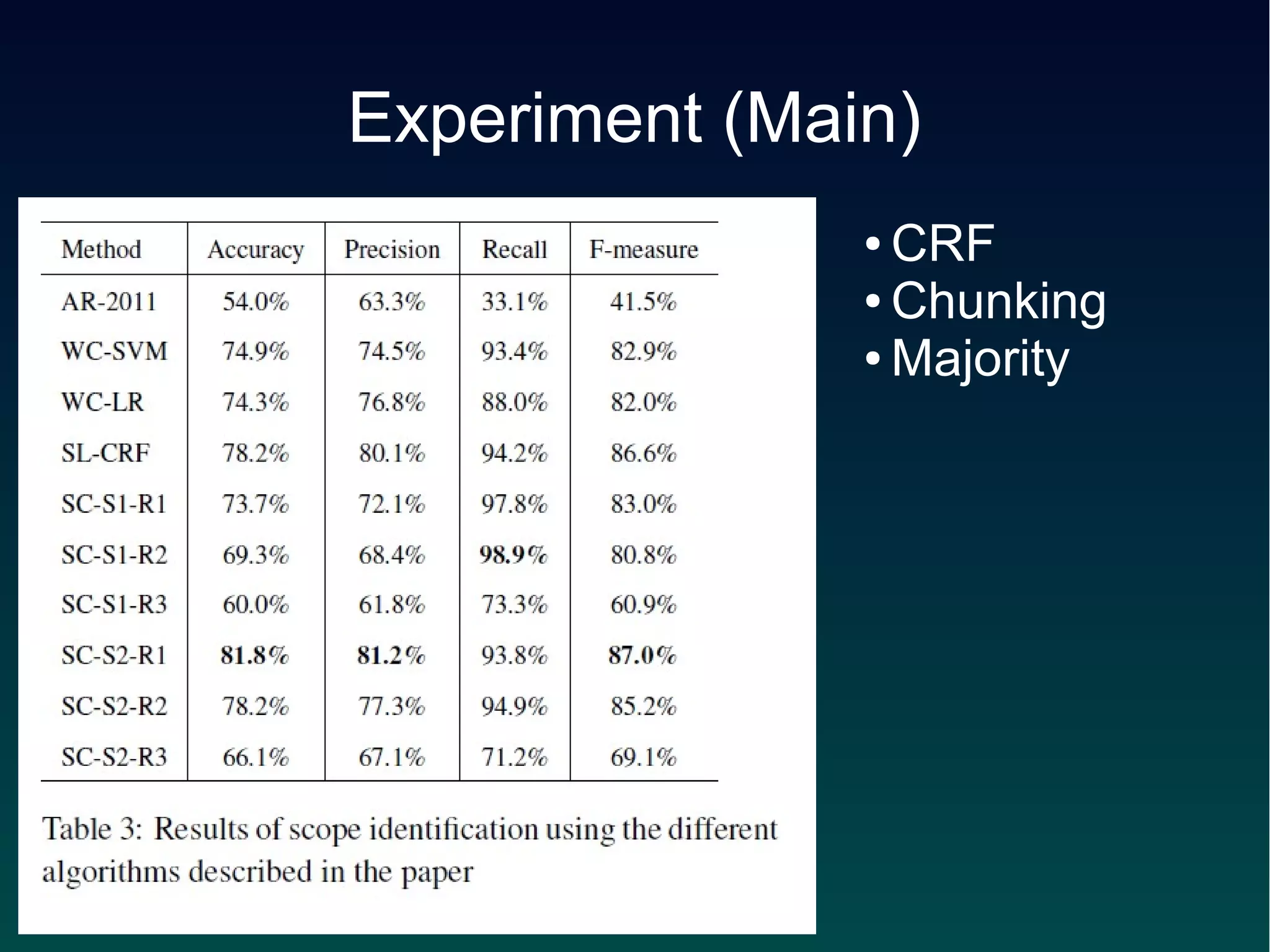

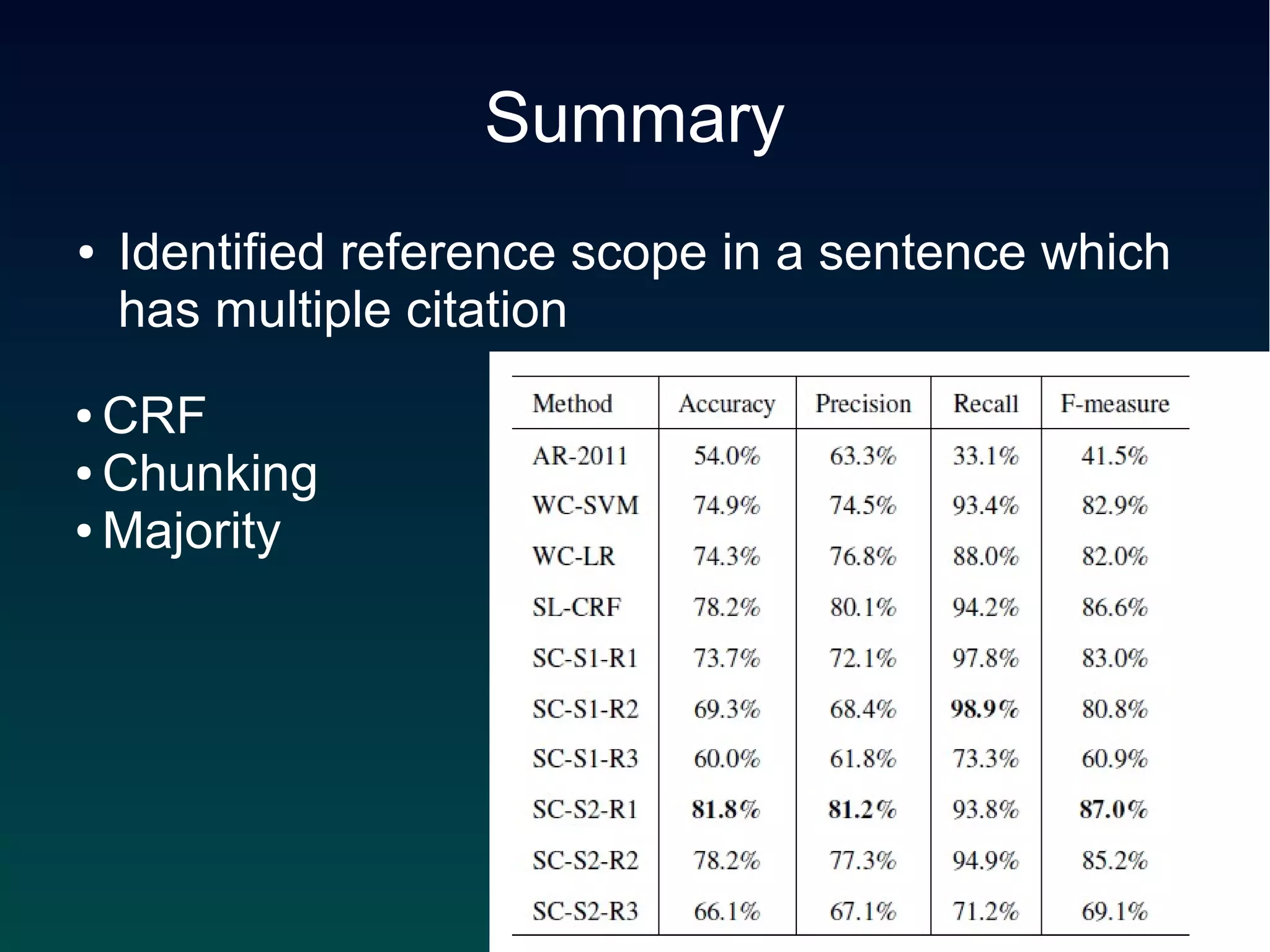
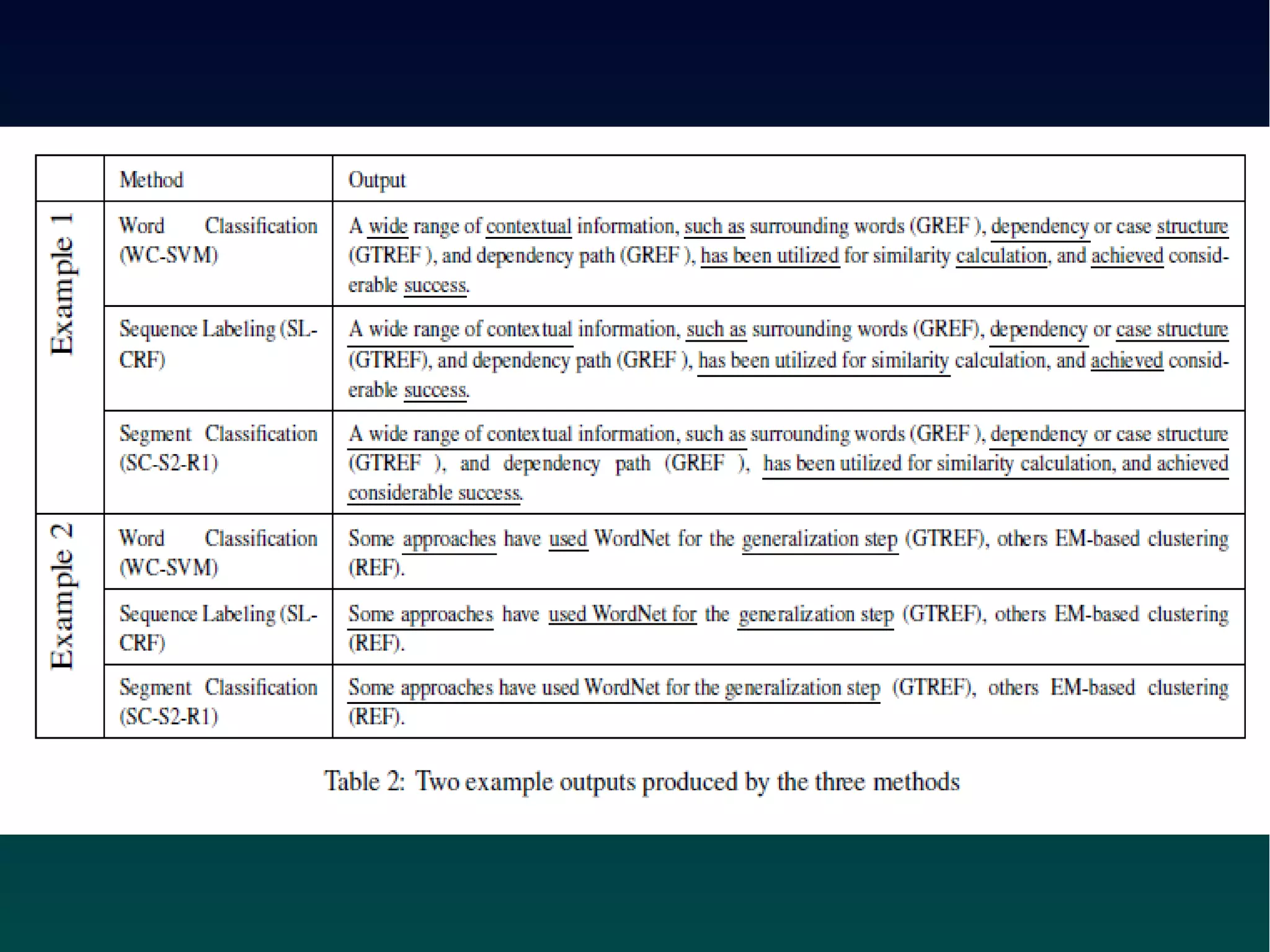

This document describes an approach to identify the scope of references in sentences containing multiple citations. The approach uses a conditional random field (CRF) sequence model with features including distance, position, part-of-speech tags, and syntactic dependencies. It first segments sentences using punctuation and conjunctions, then applies the CRF and a majority voting scheme to label each word as inside or outside the scope. The method achieved over 90% accuracy on a dataset of citations from ACL papers.
![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)







![Fafl notes [2010] (sjbit)](https://cdn.slidesharecdn.com/ss_thumbnails/faflnotes2010sjbit-131208034715-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




































































![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)









