Downloaded 6,295 times























The document outlines strategies for building an effective data warehouse architecture, comparing methodologies such as Kimball and Inmon, and detailing the importance of data warehouses for historical and trend analysis. It covers various components including hardware solutions like Fast Track Data Warehouse and appliances, as well as concepts like ETL vs ELT, surrogate keys, and the significance of SSAS cubes in reporting. Additionally, it emphasizes the need for flexibility in integrating big data solutions with modern cloud technologies and future scalability.
Introduction to effective data warehouse architecture presented by James Serra at a conference.
Overview of related presentations including various data warehouse concepts and Microsoft solutions.
James Serra's extensive experience in business intelligence, consulting, and data management.
Humorous personal story highlighting challenges faced in building a data warehouse.
Agenda outlining key topics including data warehouse definitions, methodologies, and ETL processes.
Clarification on what a data warehouse is not, dispelling common myths about its structure.
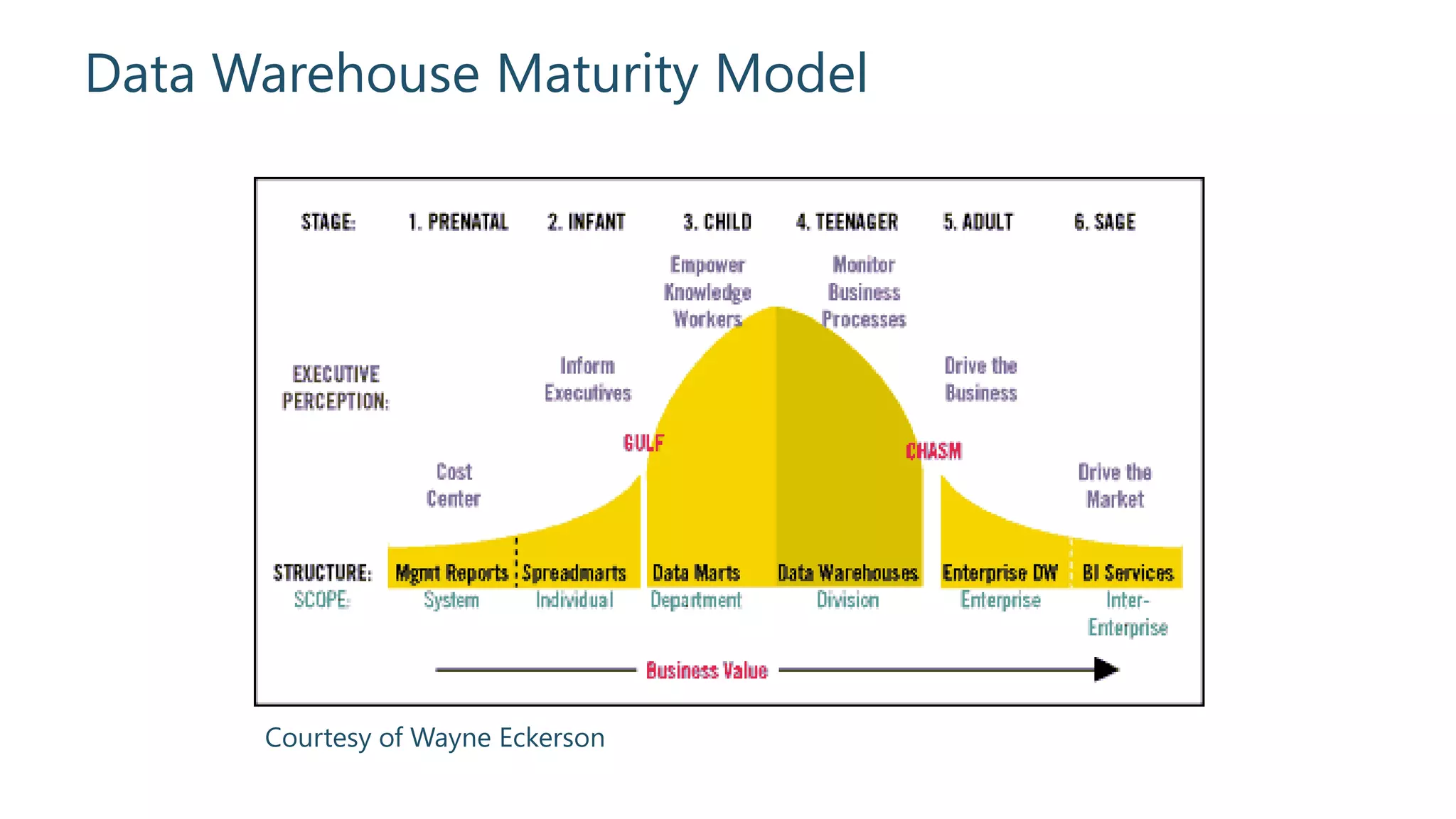
Introduction to the concept of data warehouse maturity as proposed by Wayne Eckerson.
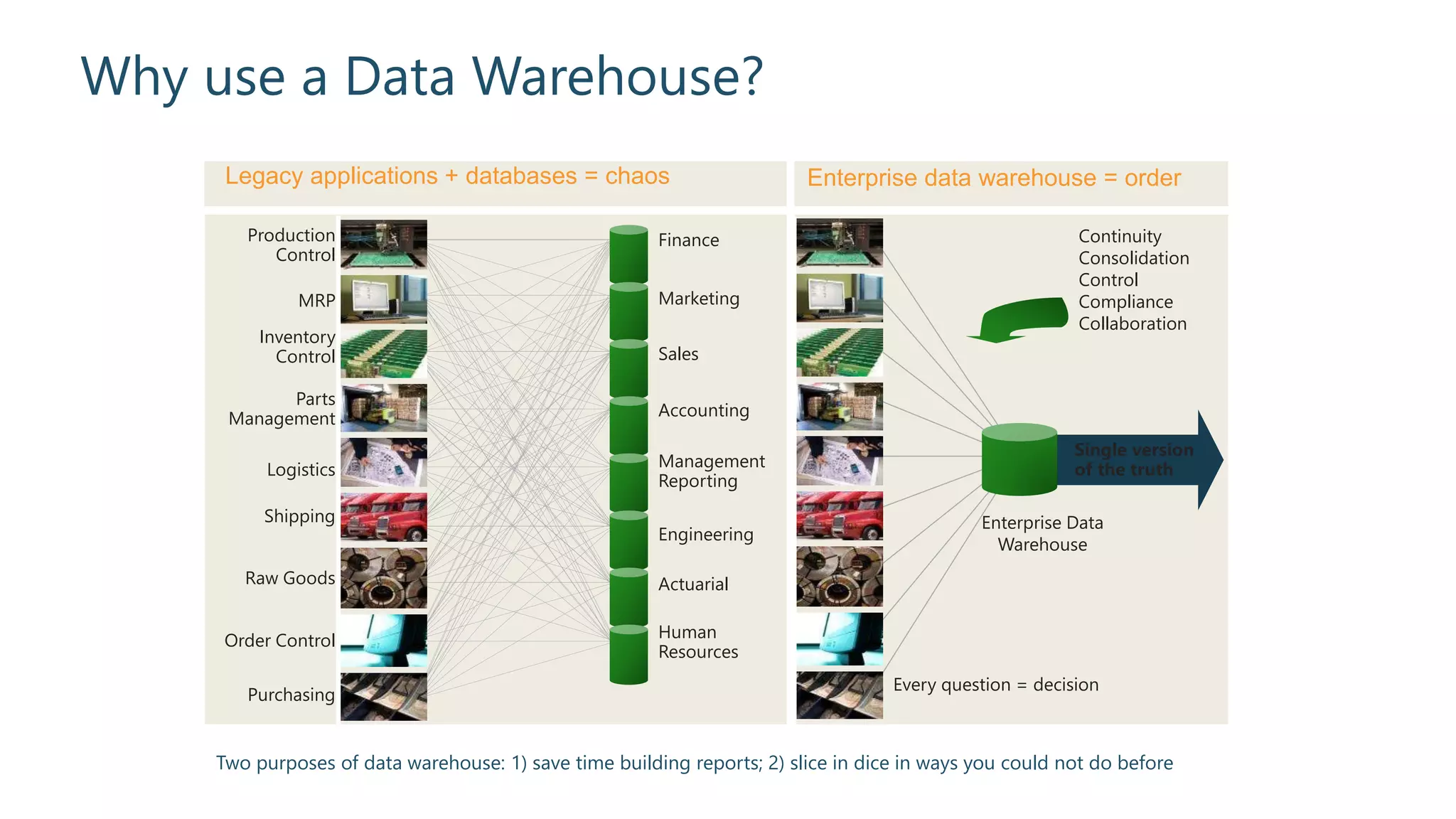
Explanation of data warehouse functions, benefits like historical analysis, and 'single version of truth'.
Discussion of legacy systems, chaos in databases, and the role of an enterprise data warehouse.
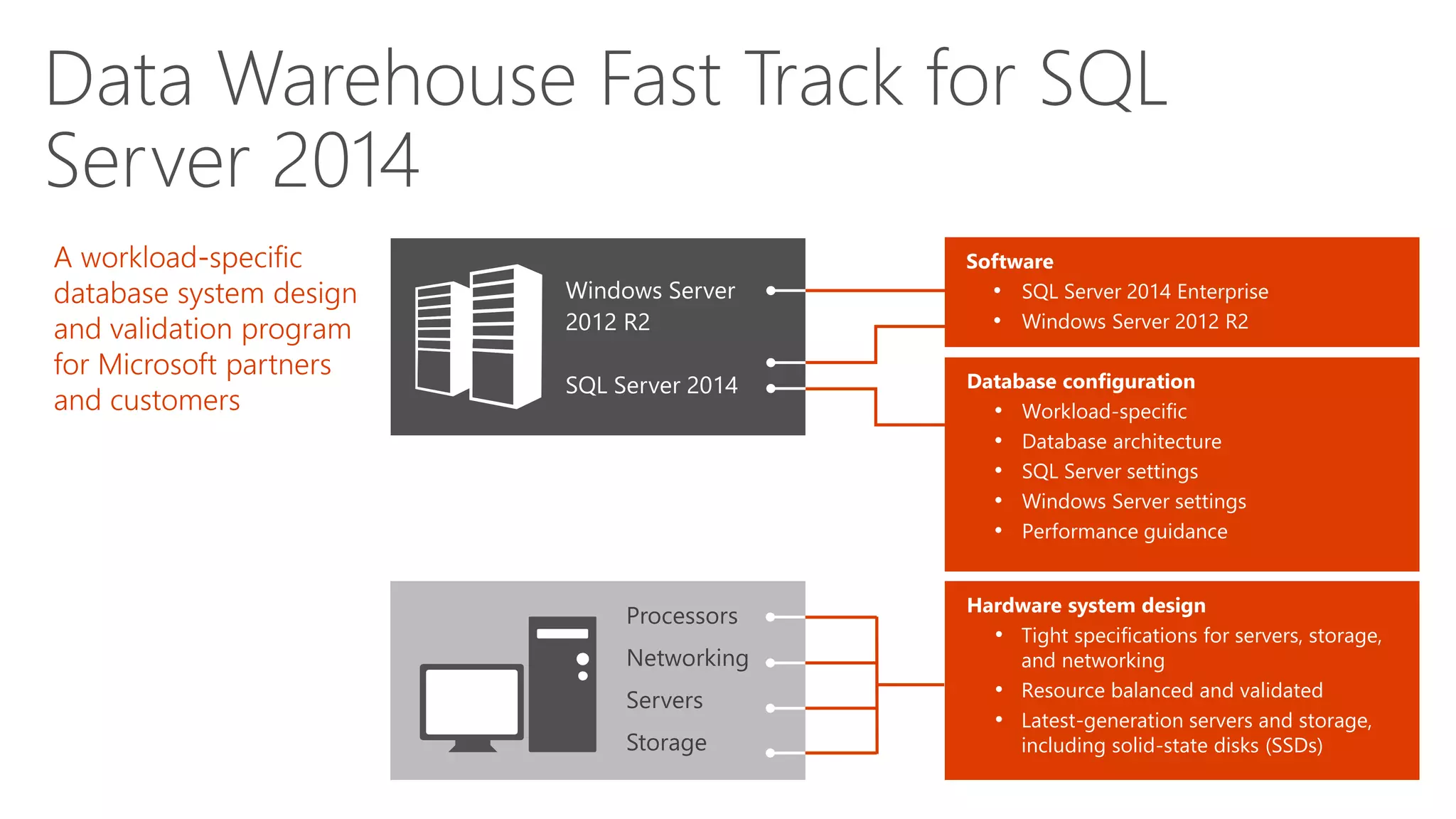
Overview of Fast Track Data Warehouse and Microsoft SQL Server appliances for optimized solutions.
Description of hardware and database configuration specifications for SQL Server 2014.
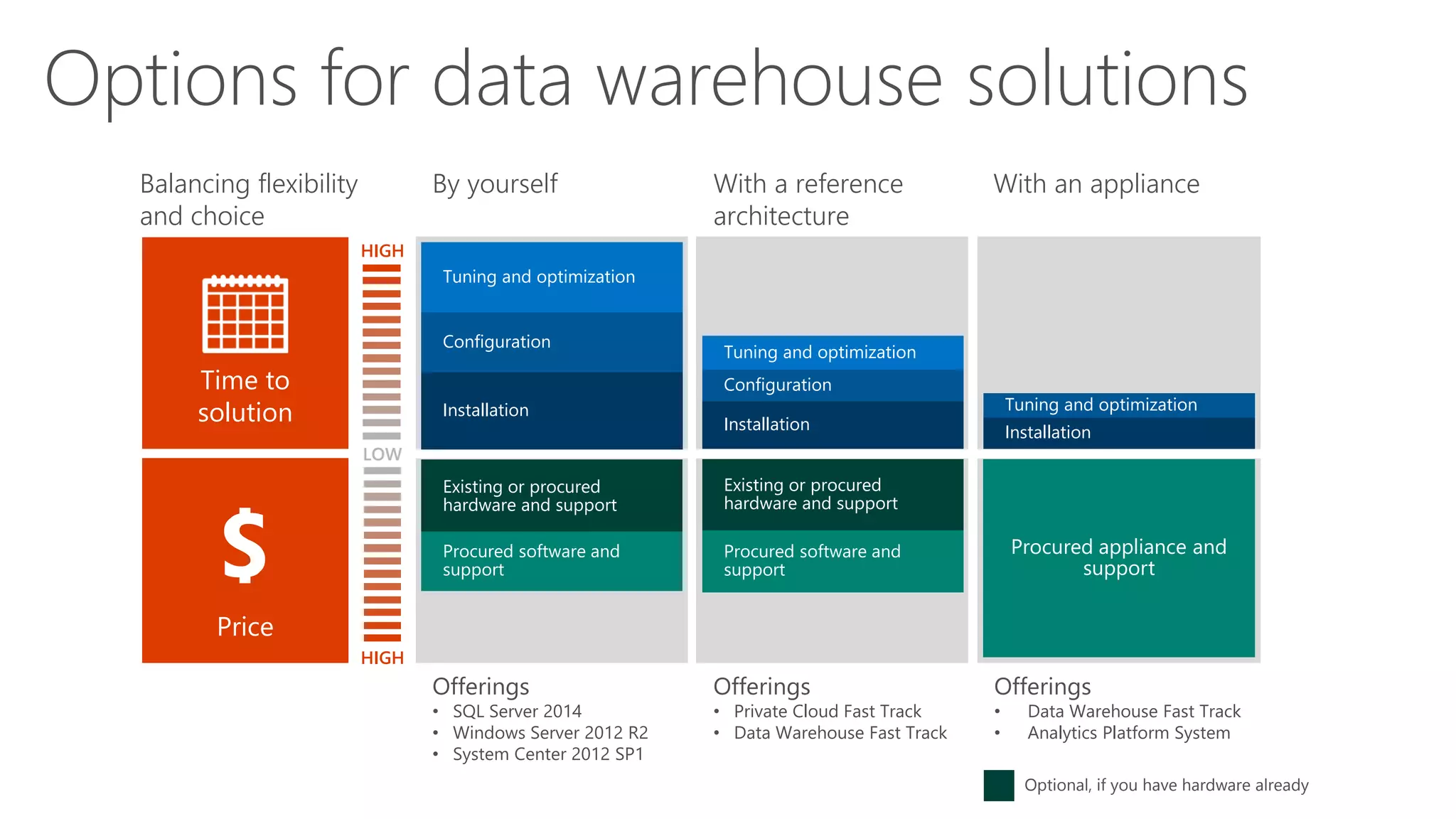
Comparison of different data warehouse solutions from DIY to using appliances.
Key benefits of Fast Track Data Warehouse including flexibility, reduced risk, and faster deployment.
List of vendors providing Fast Track appliances for data warehousing in 2014.
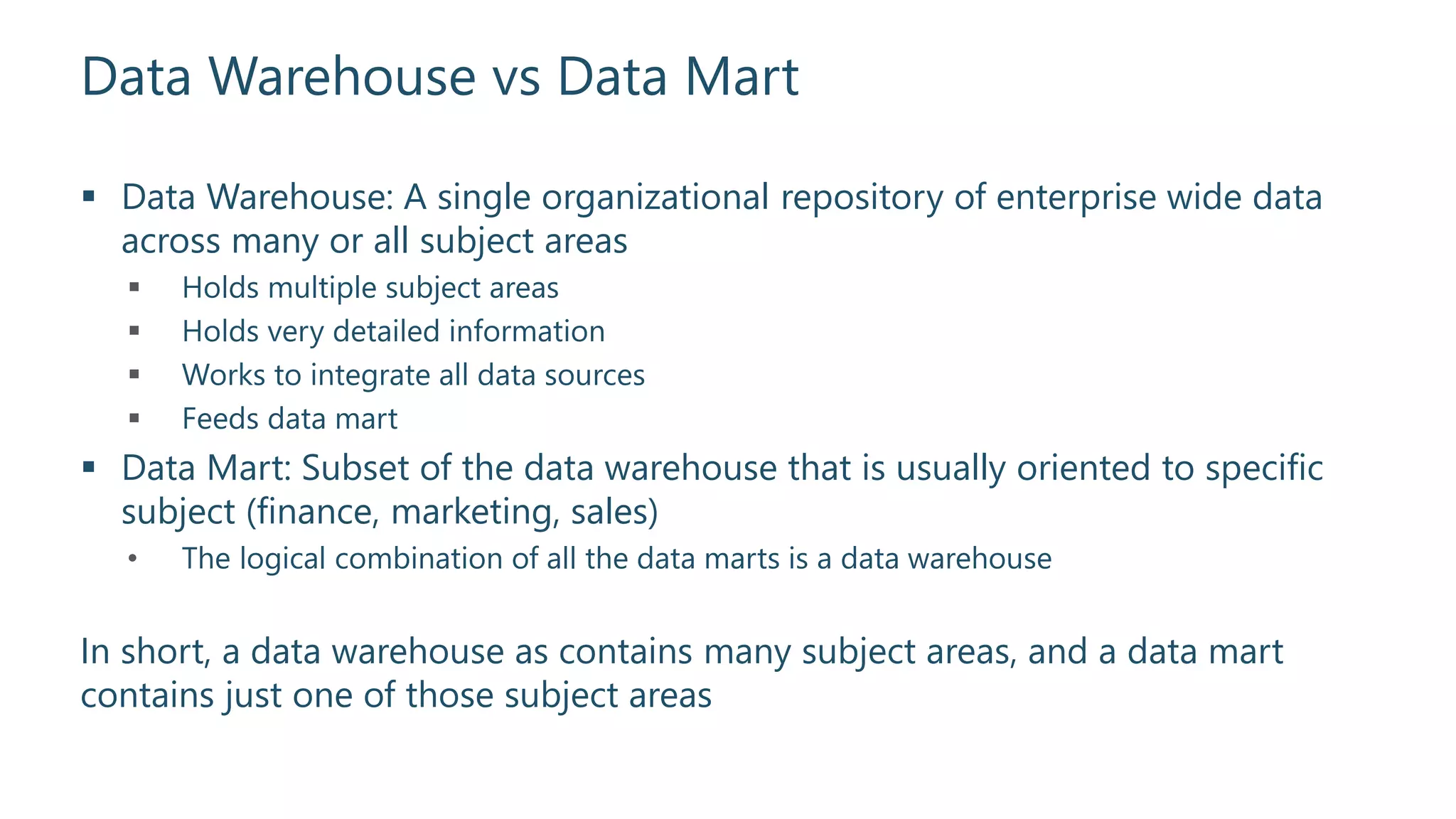
Distinction between a data warehouse and a data mart, including their data scope and integration.
Discussion of the Kimball and Inmon methodologies for data warehouse development.
Common myths about Kimball and Inmon methodologies and clarifications on their approaches.
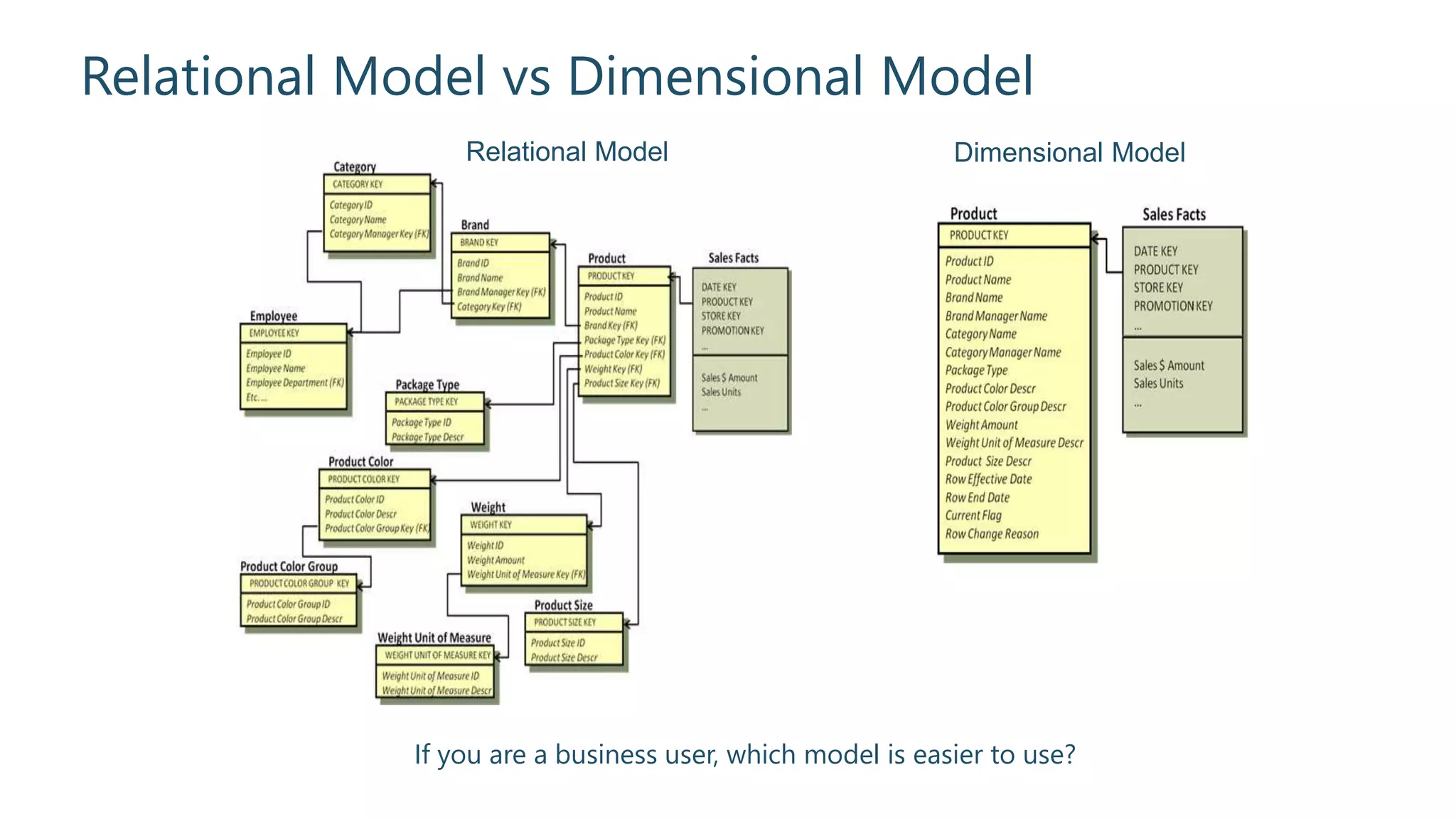
Detailed comparison of relational vs dimensional models including their user-friendliness.
Explains the fundamental paradigms of both methodologies in designing data warehouses.
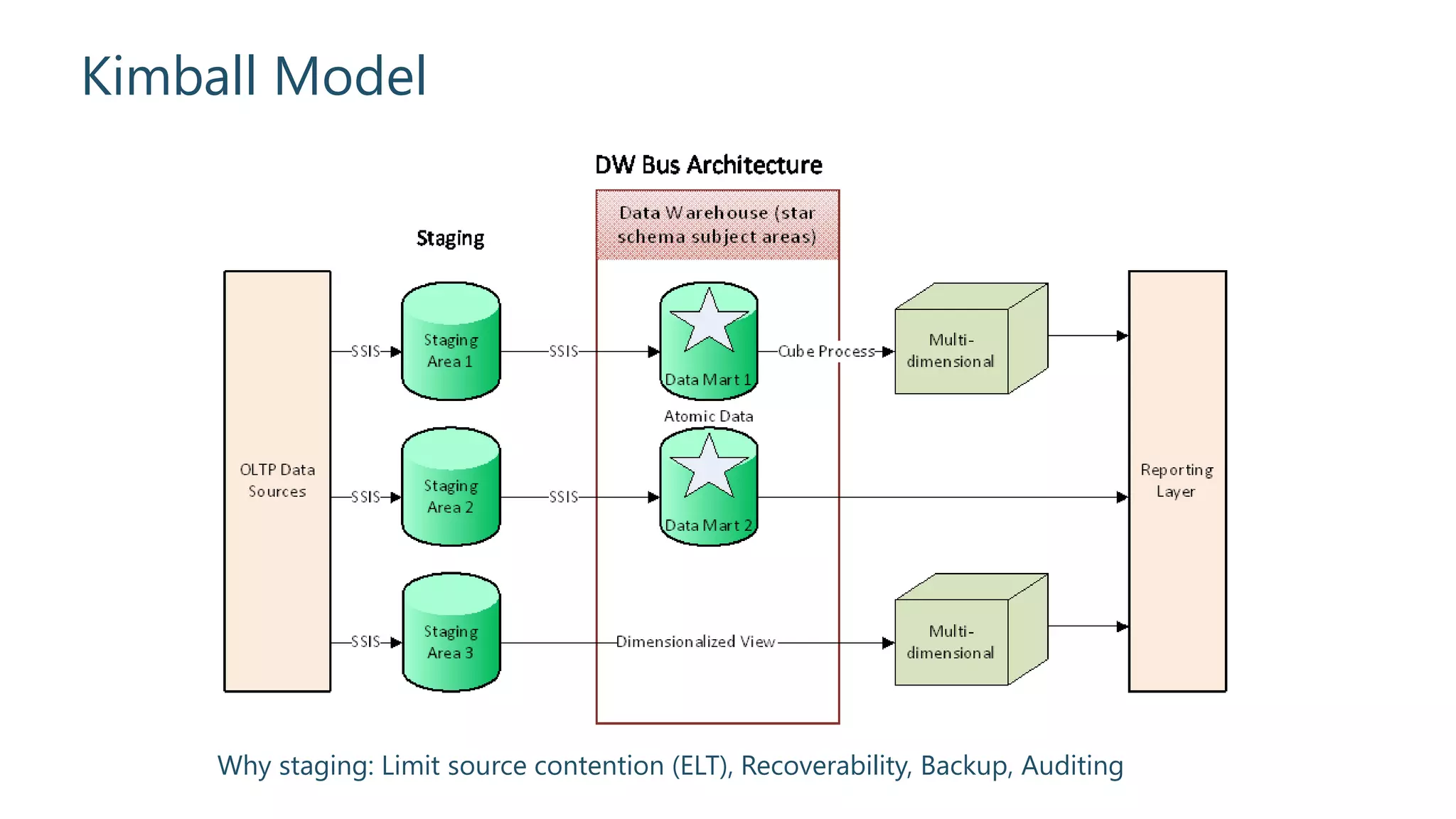
Rationale behind staging in the Kimball methodology for effective data management.
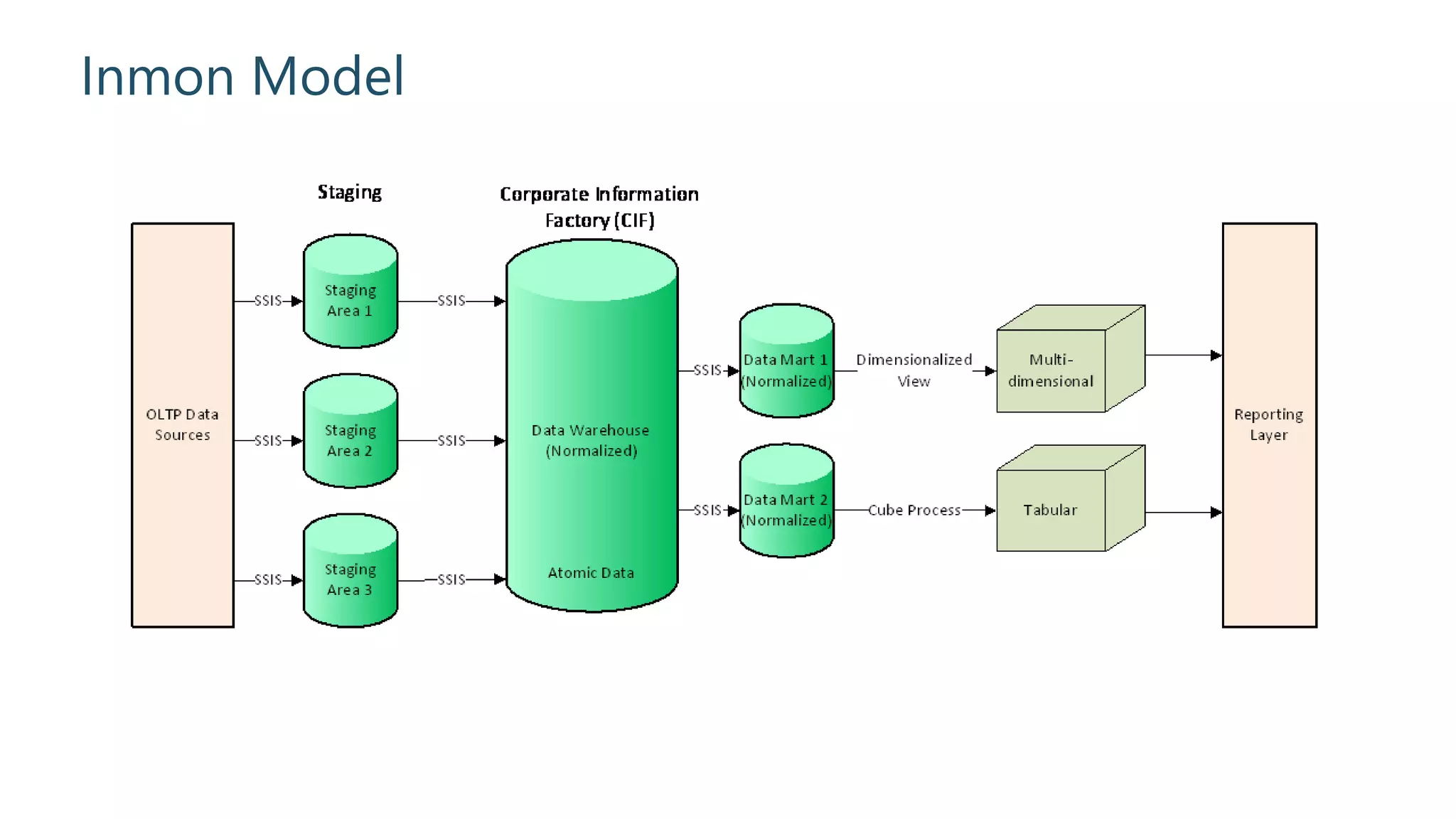
Overview of key concepts and implementation details of the Inmon model.
Key reasons for adopting an enterprise data warehouse for organizational consistency.
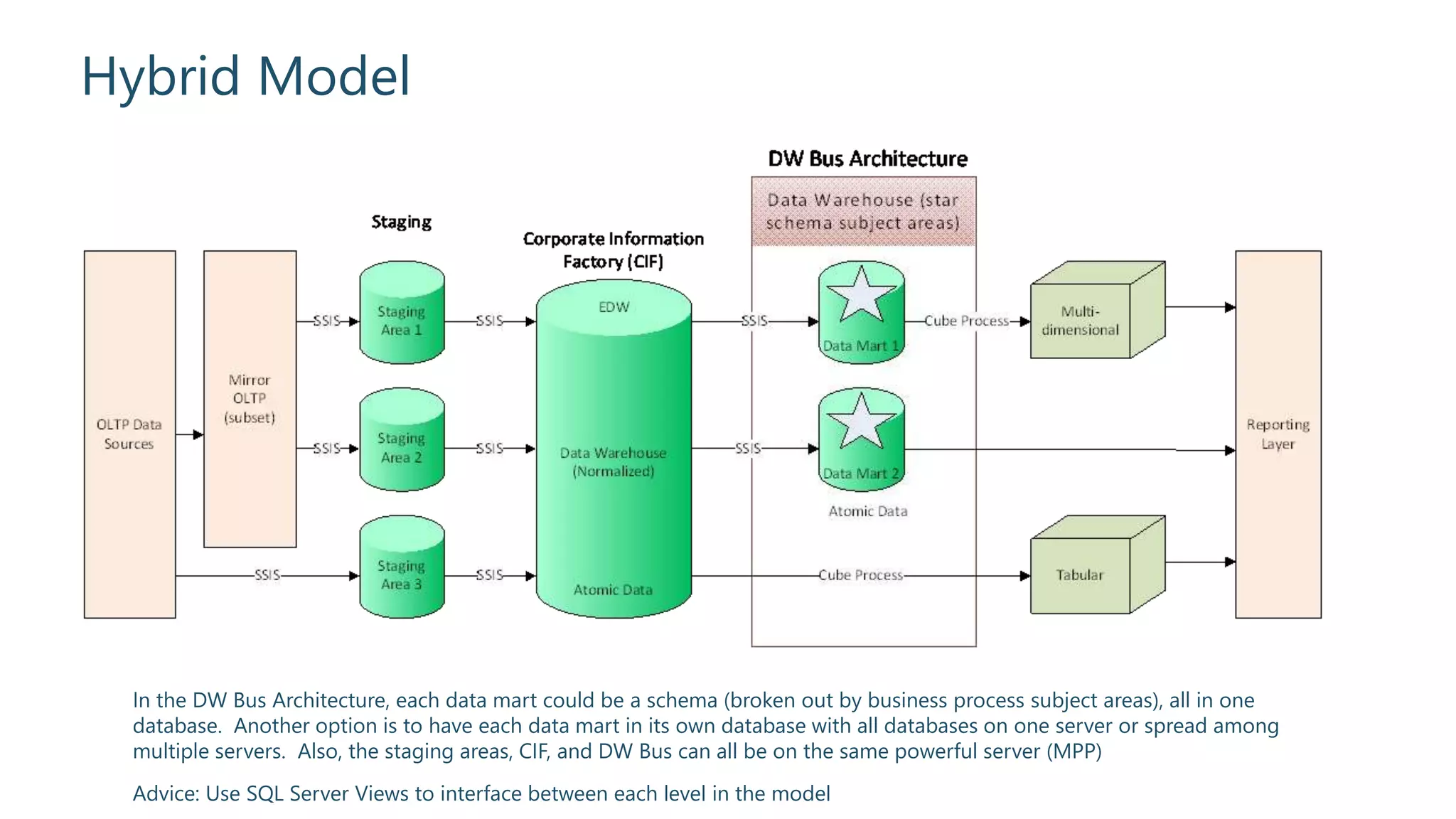
Advice on which model to use, highlighting the benefits of hybrid approaches.
Suggestions for implementing a hybrid architecture with SQL Server Views.
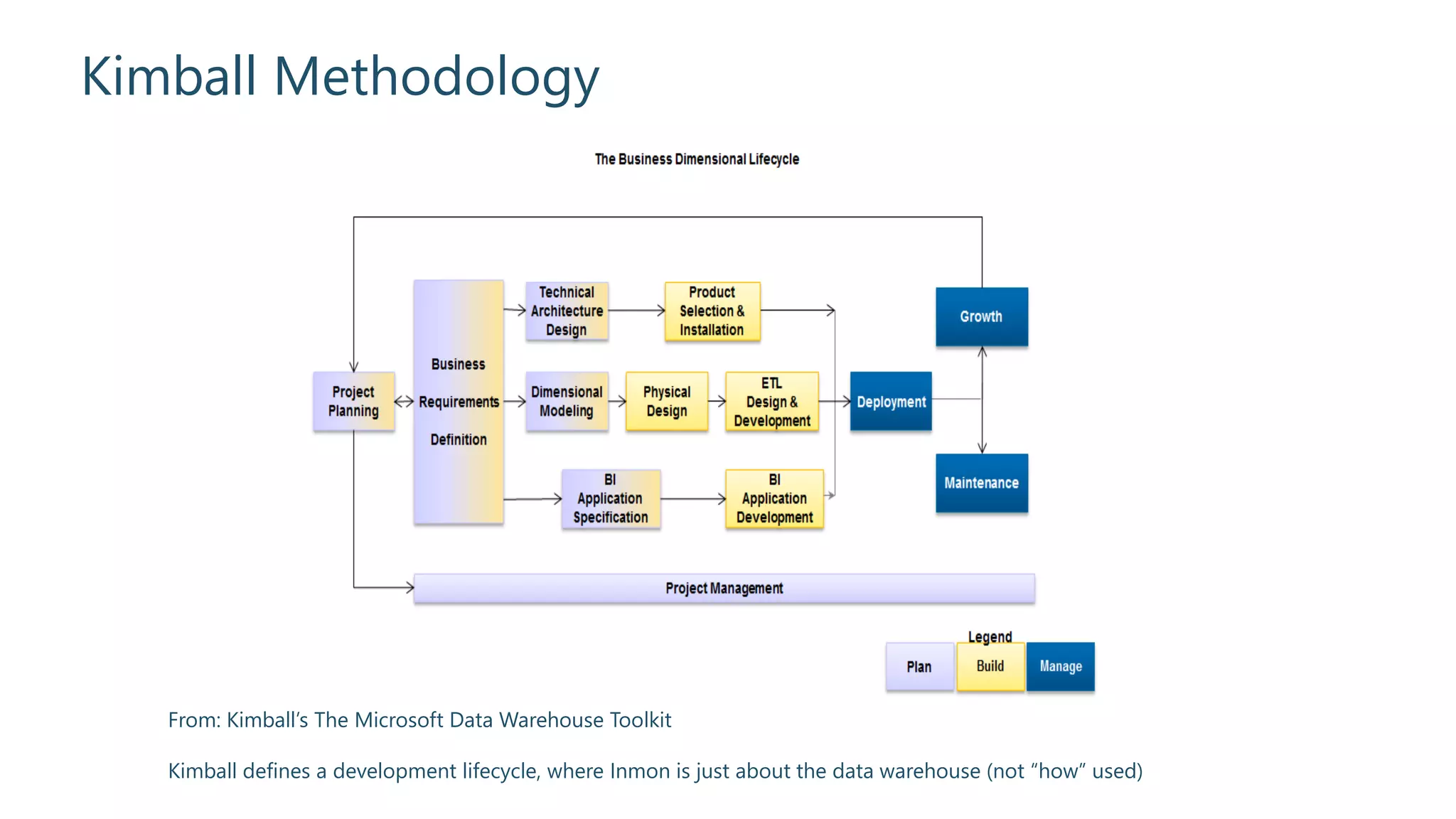
Overview of the development lifecycle in the Kimball methodology.
Techniques for populating a data warehouse including extraction methods and frequency.
Contrast between ETL and ELT processes, their efficiencies, and use cases.
The significance of surrogate keys in data warehouse architecture and their functionality.
Advantages of using SSAS cubes for data reporting and multidimensional analysis.
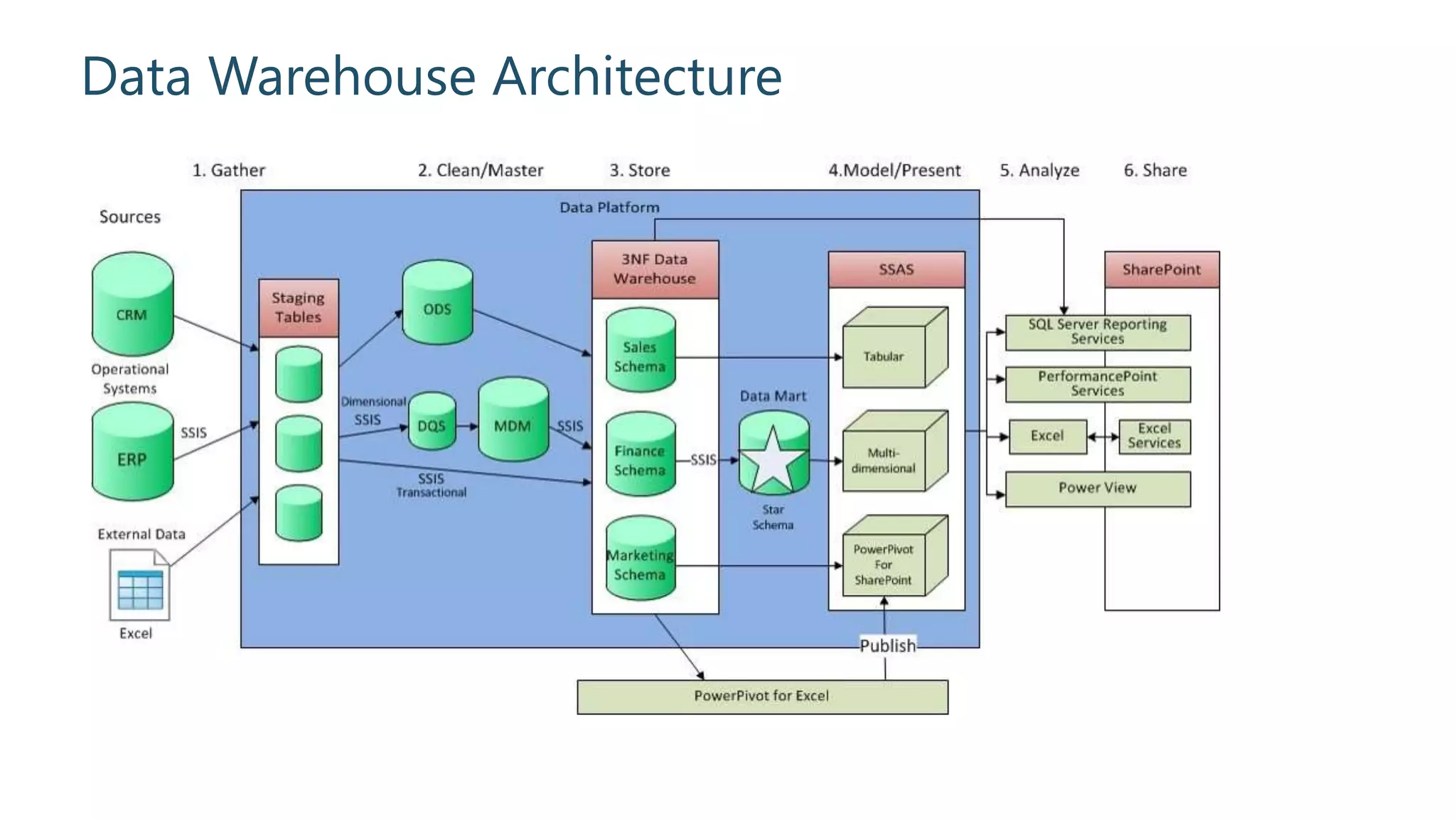
An overview of essential components of data warehouse architecture.
Future-oriented considerations for data warehousing, highlighting Microsoft’s APS.
List of resources related to data warehousing and methodologies for further learning.
Invitation for audience questions and discussion, providing contact information.








































![[Ebooks PDF] download Building the Data Warehouse 3rd Edition W. H. Inmon fu...](https://cdn.slidesharecdn.com/ss_thumbnails/24784-241224030338-65617874-thumbnail.jpg?width=640&height=640&fit=bounds)














































