Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takuya Akiba
PDF, PPTX
33,117 views
乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩-
MinHash, b-bit MinHash, HyperLogLog, Odd Sketch, HIP Estimator の解説です.
Technology
◦
Read more
86
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 37
2
/ 37
3
/ 37
4
/ 37
5
/ 37
6
/ 37
7
/ 37
8
/ 37
9
/ 37
10
/ 37
11
/ 37
12
/ 37
13
/ 37
14
/ 37
15
/ 37
16
/ 37
17
/ 37
18
/ 37
Most read
19
/ 37
20
/ 37
Most read
21
/ 37
22
/ 37
23
/ 37
24
/ 37
25
/ 37
Most read
26
/ 37
27
/ 37
28
/ 37
29
/ 37
30
/ 37
31
/ 37
32
/ 37
33
/ 37
34
/ 37
35
/ 37
36
/ 37
37
/ 37
More Related Content
PDF
スペクトラルグラフ理論入門
by
irrrrr
PDF
R言語による アソシエーション分析-組合せ・事象の規則を解明する-(第5回R勉強会@東京)
by
Koichi Hamada
PDF
スペクトラル・クラスタリング
by
Akira Miyazawa
PDF
BERT+XLNet+RoBERTa
by
禎晃 山崎
PDF
第10回 配信講義 計算科学技術特論A(2021)
by
RCCSRENKEI
PDF
はじめてのパターン認識 第5章 k最近傍法(k_nn法)
by
Motoya Wakiyama
PPTX
劣モジュラ最適化と機械学習 3章
by
Hakky St
PDF
BERT入門
by
Ken'ichi Matsui
スペクトラルグラフ理論入門
by
irrrrr
R言語による アソシエーション分析-組合せ・事象の規則を解明する-(第5回R勉強会@東京)
by
Koichi Hamada
スペクトラル・クラスタリング
by
Akira Miyazawa
BERT+XLNet+RoBERTa
by
禎晃 山崎
第10回 配信講義 計算科学技術特論A(2021)
by
RCCSRENKEI
はじめてのパターン認識 第5章 k最近傍法(k_nn法)
by
Motoya Wakiyama
劣モジュラ最適化と機械学習 3章
by
Hakky St
BERT入門
by
Ken'ichi Matsui
What's hot
PDF
プログラムを高速化する話
by
京大 マイコンクラブ
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
合成変量とアンサンブル:回帰森と加法モデルの要点
by
Ichigaku Takigawa
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
by
Takuya Akiba
PDF
大規模グラフ解析のための乱択スケッチ技法
by
Takuya Akiba
PDF
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
ZIP
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
PDF
直交領域探索
by
okuraofvegetable
PDF
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
PDF
3分でわかる多項分布とディリクレ分布
by
Junya Saito
PDF
線形計画法入門
by
Shunji Umetani
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PPTX
強化学習における好奇心
by
Shota Imai
PPTX
Chokudai search
by
AtCoder Inc.
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
初めてのグラフカット
by
Tsubasa Hirakawa
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PDF
Quine・難解プログラミングについて
by
mametter
プログラムを高速化する話
by
京大 マイコンクラブ
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
合成変量とアンサンブル:回帰森と加法モデルの要点
by
Ichigaku Takigawa
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
by
Takuya Akiba
大規模グラフ解析のための乱択スケッチ技法
by
Takuya Akiba
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
直交領域探索
by
okuraofvegetable
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
3分でわかる多項分布とディリクレ分布
by
Junya Saito
線形計画法入門
by
Shunji Umetani
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
強化学習における好奇心
by
Shota Imai
Chokudai search
by
AtCoder Inc.
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
深層学習の数理
by
Taiji Suzuki
初めてのグラフカット
by
Tsubasa Hirakawa
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
Quine・難解プログラミングについて
by
mametter
Similar to 乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩-
PDF
ウェーブレット木の世界
by
Preferred Networks
PPT
lsh
by
Shunsuke Aihara
PDF
RedisのBitCountとHyperLogLogを使用した超高速Unique User数集計
by
tmatsuura
PDF
ZDD入門-お姉さんを救う方法
by
nishio
PDF
PFI Seminar 2012/03/15 カーネルとハッシュの機械学習
by
Preferred Networks
PDF
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PPTX
2015年12月PRMU研究会 対応点探索のための特徴量表現
by
Mitsuru Ambai
PDF
K-means hashing (CVPR'13) とハッシング周り
by
Yusuke Uchida
PDF
[アルゴリズムイントロダクション勉強会] ハッシュ
by
Rei Takami
PDF
Ibisml2011 06-20
by
Yasuo Tabei
PDF
Mining of massive datasets chapter3
by
Maruyama Tetsutaro
PDF
すごいHaskell読書会 第六章 発表資料
by
Hiromasa Ohashi
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
PDF
PFI Christmas seminar 2009
by
Preferred Networks
PDF
Deep Sketch Hashing
by
Kai Katsumata
PDF
データマイニング勉強会3
by
Yohei Sato
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
PDF
Cvpr2011 reading-tsubosaka
by
正志 坪坂
PDF
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010)
by
Koji Matsuda
ウェーブレット木の世界
by
Preferred Networks
lsh
by
Shunsuke Aihara
RedisのBitCountとHyperLogLogを使用した超高速Unique User数集計
by
tmatsuura
ZDD入門-お姉さんを救う方法
by
nishio
PFI Seminar 2012/03/15 カーネルとハッシュの機械学習
by
Preferred Networks
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
2015年12月PRMU研究会 対応点探索のための特徴量表現
by
Mitsuru Ambai
K-means hashing (CVPR'13) とハッシング周り
by
Yusuke Uchida
[アルゴリズムイントロダクション勉強会] ハッシュ
by
Rei Takami
Ibisml2011 06-20
by
Yasuo Tabei
Mining of massive datasets chapter3
by
Maruyama Tetsutaro
すごいHaskell読書会 第六章 発表資料
by
Hiromasa Ohashi
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
PFI Christmas seminar 2009
by
Preferred Networks
Deep Sketch Hashing
by
Kai Katsumata
データマイニング勉強会3
by
Yohei Sato
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
Cvpr2011 reading-tsubosaka
by
正志 坪坂
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010)
by
Koji Matsuda
More from Takuya Akiba
PDF
プログラミングコンテストでの乱択アルゴリズム
by
Takuya Akiba
PDF
プログラミングコンテストでの動的計画法
by
Takuya Akiba
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
by
Takuya Akiba
PDF
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
PDF
平面グラフと交通ネットワークのアルゴリズム
by
Takuya Akiba
PDF
大規模グラフアルゴリズムの最先端
by
Takuya Akiba
PDF
プログラミングコンテストでのデータ構造
by
Takuya Akiba
PPTX
分散深層学習 @ NIPS'17
by
Takuya Akiba
PDF
Cache-Oblivious データ構造入門 @DSIRNLP#5
by
Takuya Akiba
PDF
大規模ネットワークの性質と先端グラフアルゴリズム
by
Takuya Akiba
PDF
TCO15 Algorithm Round 2C 解説
by
Takuya Akiba
PDF
Learning Convolutional Neural Networks for Graphs
by
Takuya Akiba
PDF
ACM-ICPC 世界大会 2015 問題 K "Tours" 解説
by
Takuya Akiba
プログラミングコンテストでの乱択アルゴリズム
by
Takuya Akiba
プログラミングコンテストでの動的計画法
by
Takuya Akiba
プログラミングコンテストでのデータ構造 2 ~動的木編~
by
Takuya Akiba
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
平面グラフと交通ネットワークのアルゴリズム
by
Takuya Akiba
大規模グラフアルゴリズムの最先端
by
Takuya Akiba
プログラミングコンテストでのデータ構造
by
Takuya Akiba
分散深層学習 @ NIPS'17
by
Takuya Akiba
Cache-Oblivious データ構造入門 @DSIRNLP#5
by
Takuya Akiba
大規模ネットワークの性質と先端グラフアルゴリズム
by
Takuya Akiba
TCO15 Algorithm Round 2C 解説
by
Takuya Akiba
Learning Convolutional Neural Networks for Graphs
by
Takuya Akiba
ACM-ICPC 世界大会 2015 問題 K "Tours" 解説
by
Takuya Akiba
乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩-
1.
乱択データ構造の最新事情 -MinHash と HyperLogLog
の最近の進歩- 東京大学 情報理工学研究科 D2 秋葉 拓哉 (@iwiwi) 2014/05/29 @ PFI セミナー
2.
背景 誰もが大量の集合・特徴ベクトルを処理したい! • 文章 →
単語の集合 (bag of words) • 商品 → 購買者 • 画像データ → 局所特徴量 (SIFT, SURF, …) • …… 色々したいが,そのまま処理するのは困難 • データが大きすぎる • 遅すぎる 1
3.
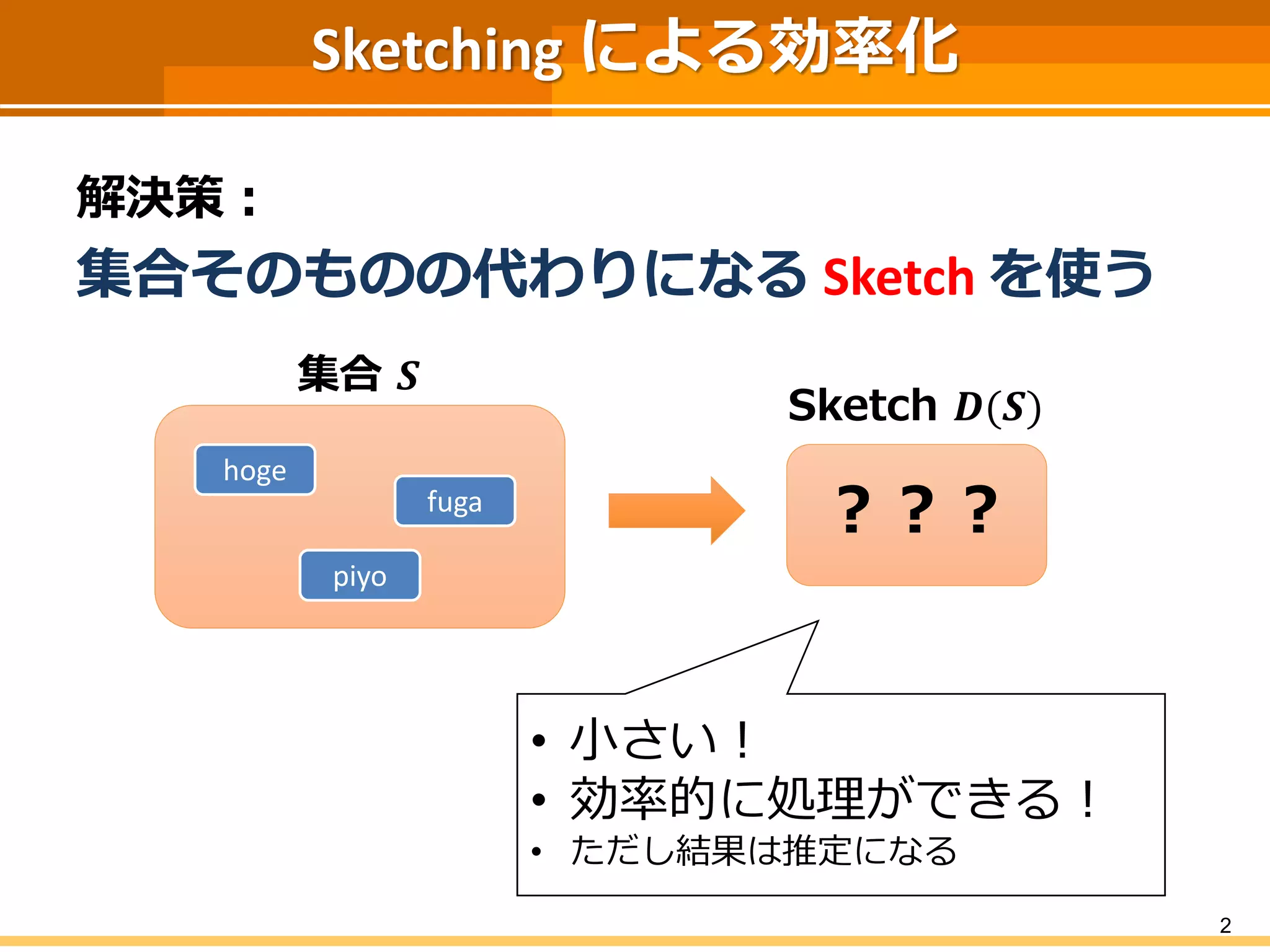
Sketching による効率化 解決策: 集合そのものの代わりになる Sketch
を使う 2 Sketch 𝑫(𝑺) 集合 𝑺 hoge piyo fuga ??? • 小さい! • 効率的に処理ができる! • ただし結果は推定になる
4.
3 今日の話:集合 Sketching の最新技術 1.
MinHash Sketches 入門 • 基礎的かつ強力な手法である MinHash を復習 (以降の話も両方 MinHash の派生系) 2. Odd Sketches による Jaccard 係数推定の進歩 • まず,現在よく用いられている 𝒃-bit MinHash を紹介 • 類似性が高い際 𝑏-bit MinHash が劣化する問題を解消 [Mitzenmacher-Pagh-Pham, WWW’14] 3. HIP Estimator による集合異なり数推定の進歩 • まず,現在よく用いられている HyperLogLog Counter を紹介 • 要素挿入時の情報を用い精度を改善,誤差 1.08/ 𝑚 → 0.87/ 𝑚 [Cohen, PODS’14] WWW’14 Best Paper!
5.
1. Min-wise Hashing
入門 ※ この部分は岡野原さんの 2011 年の解説をベースにさせてもらっています http://research.preferred.jp/2011/02/minhash/ 4
6.
Jaccard 係数 集合の類似度として Jaccard
係数を考えます 集合 𝑺 𝟏 と 𝑺 𝟐 の Jaccard 係数: 𝐽 𝑆1, 𝑆2 = 𝑆1 ∩ 𝑆2 |𝑆1 ∪ 𝑆2| 具体的な場面 • 文章の類似検索,重複検出 • 商品の推薦 集合の Jaccard 係数を推定したい気持ちになって下さい 5
7.
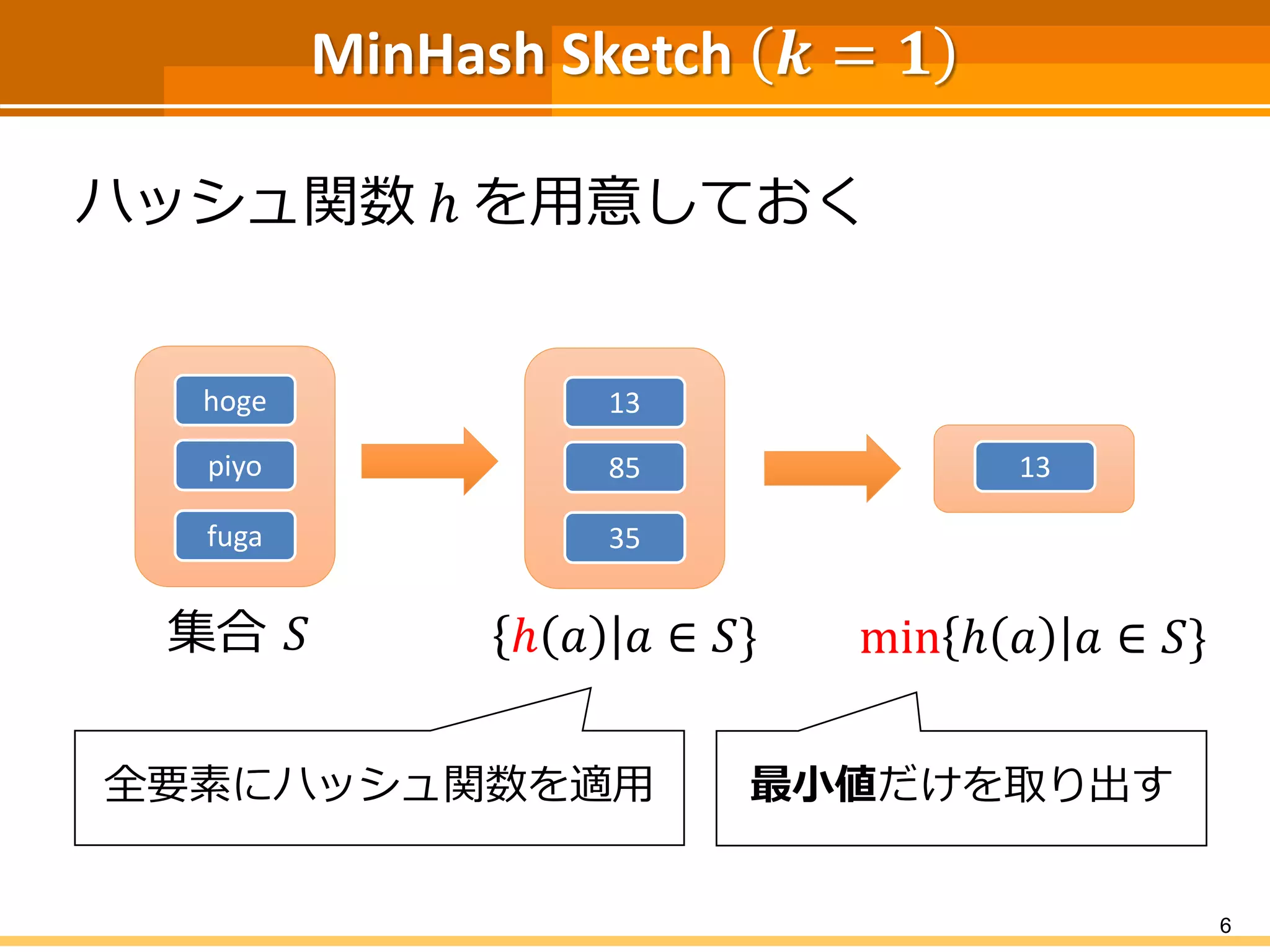
MinHash Sketch 𝒌
= 𝟏 ハッシュ関数 ℎ を用意しておく 6 集合 𝑆 hoge piyo fuga ℎ 𝑎 𝑎 ∈ 𝑆} 13 85 35 min ℎ 𝑎 𝑎 ∈ 𝑆} 13 全要素にハッシュ関数を適用 最小値だけを取り出す
8.
Jaccard 係数推定の基礎 重要な性質 Pr min
ℎ 𝑎 |𝑎 ∈ 𝑆1 = min ℎ 𝑏 |𝑏 ∈ 𝑆2 = 𝐽 𝑆1, 𝑆2 2 つの集合のハッシュ値の min が一致する確率は Jaccard 係数に等しい! ※ハッシュ関数は完全にランダムに振る舞うと仮定 7 𝑆1 の Sketch 𝑆2 の Sketch
9.
Jaccard 係数推定の基礎 なぜ? 具体例で考えてみます. •
𝑆1 = 2,5,7,9 , 𝑆2 = 1,2,4,7,10 𝑆1 ∩ 𝑆2 = 2,7 .例えば 2 で一致する場合とは? • arg min ℎ 𝑎 |𝑎 ∈ 𝑆1 = 2 ⇔ {2,5,7,9} で 2 が最強 • arg min ℎ 𝑏 |𝑏 ∈ 𝑆2 = 2 ⇔ {1,2,4,7,10} で 2 が最強 条件を合わせると, • 2 で一致 ⇔ 1,2,4,5,7,9,10 = 𝑆1 ∪ 𝑆2 中で 2 が最強 一致するのは 7 でも良く,このように,要は 𝑆1 ∪ 𝑆2 中で最強のものが 𝑆1 ∩ 𝑆2 のいずれかであればよい. その確率は: S1 ∩ 𝑆2 / S1 ∪ 𝑆2 = 𝐽 𝑆1, 𝑆2 . 8 最強=ハッシュ値が最低
10.
𝒌-min MinHash Sketch あとはこれを
𝑘 個並べると……! 𝒌-min MinHash Sketch • 異なる 𝑘 個のハッシュ関数 ℎ1, ℎ2, … , ℎ 𝑘 を用意 • それぞれについてさっきの min を計算&保存 Jaccard 係数の推定 • 「一致した数 / 𝑘」により 𝐽 𝑆1, 𝑆2 を推定 推定値は unbiased (不偏) また分散は 𝐽 1 − 𝐽 / 𝑘 になることが示せる 9
11.
MinHash Family こんな感じでハッシュ関数の最小値に注目する Sketching の手法が一般に
MinHash と呼ばれる. (Jaccard 係数推定以外のことも色々できる.) MinHash のバリエーション • 𝑘 個の並べ方 – 𝑘-min Sketch (OddSketch はコレ) – 𝑘-partition Sketch (HyperLogLog はコレ) – Bottom-𝑘 Sketch (最近の All-Distances Sketches はコレ) • ハッシュ値の使い方 – Full Ranks (さっきのやつはコレ) – 𝑏-bit MinHash (Jaccard 係数でよく使われているヤツ) – Base-𝑏 Ranks (HyperLogLog は Base-2 Ranks) – …… 10
12.
2. Odd Sketches
による Jaccard 係数推定の進歩 [Mitzenmacher-Pagh-Pham, WWW’14] 11
13.
𝒃-bit MinHash MinHash の改善できそうなところ •
さっきの MinHash ではハッシュ値をそのまま保存 • 各々に 32bit (or 64bit) も使うと個数 𝑘 をあまり増やせない • 衝突を覚悟してもハッシュ値を小さくして,その分 𝑘 を 増やしてはどうか? 𝒃-bit MinHash [Li-König, WWW’10] • 異なる 𝑘 個のハッシュ関数 ℎ1, ℎ2, … , ℎ 𝑘 を用意 • それぞれについてさっきの min を計算 • ハッシュ値の下位 𝑏 bit のみを保存 (データサイズは 𝑘𝑏 bit になる) 12 𝑏 = 1 という極端な場合が 実は一番性能が良かったり
14.
𝒃-bit MinHash による
Jaccard 係数推定 Jaccard 係数の推定: 𝐽 = 𝑛/𝑘 − 2−𝑏 1 −2−𝑏 と推定すれば良い (𝑛=一致箇所数) 一致確率にハッシュ値の衝突を加味して解析 • 各箇所の一致確率は 𝐽 + 1 − 𝐽 2−𝑏 • 𝐽 + 1 − 𝐽 2−𝑏 × 𝑘 = 𝑛 として解くと上が得られる 推定値は unbiased (不偏) また分散は 1−𝐽 𝑘 𝐽 + 1 2 𝑏−1 になることが示せる 13
15.
𝒃-bit MinHash が微妙な時 特に高い類似度の推定に興味がある時 𝒃-bit
MinHash は実は微妙 なぜ? • 類似度 𝐽 が 1 に近い時,2 つのスケッチはほぼ同じ • 異なっている若干のビット数で,1 との差を見積もる • つまり,1 との差を表現するのは全体のごく一部 そのような状況は少なくない • 類似度 Top-10 を表示したい(→ 高い類似度のアイテムの精度が重要) • Web ページの重複検出等で 𝐽 > 0.9 かを判定したい 14
16.
𝒃-bit MinHash が微妙な時 •
類似度 𝐽 が 1 に近い時,2 つのスケッチはほぼ同じ • 異なっている若干のビット数で,1 との差を見積もる • つまり,1 との差を表現するのは全体のごく一部 15 [Figure 1, Mitzenmacher+, WWW’14]
17.
Odd Sketches そこで高い類似度での精度を重視し改善するのが Odd Sketches
[Mitzenmacher-Pagh-Pham, WWW’14] 着想 • XOR を活用する • 共通部分を打ち消させる • 異なっている部分の情報だけを綺麗に得る
18.
Odd Sketches Odd Sketches
[Mitzenmacher-Pagh-Pham, WWW’14] • まず集合の要素を 𝑘-min MinHash で 𝑘 個選ぶ • 𝑛 bit のビットベクトル 𝑠 を用意,最初は全箇所 0 • 選ばれてる各要素 𝑎 について,𝑠 ℎ′ 𝑎 を反転する 𝑘 と 𝑛 がパラメータ.ℎ′: 値域 [1, 𝑛] のハッシュ関数を別途用意 17 集合 𝑆 hoge piyo fuga 1 piyo 2 hoge 𝑘-min MinHash 𝑘 = 2 0 1 0 0 1 0 Odd Sketch 𝑛 = 6
19.
Odd Sketches ※注意:実際には元の集合からいきなり Odd
Sketches を計算するので はなく,集合の 𝑘-min MinHash Sketch の Odd Skech を計算します. (擬似コードの 𝑆 は既に 𝑘-min MinHash Sketch) 18
20.
Odd Sketches による
Jaccard 係数の推定 𝐽 = 1 + 𝑛 4𝑘 ln 1 − 2 × Popcount odd 𝑆1 ⨂odd 𝑆2 𝑛 導出 • E MinHash 𝑘 𝑆1 Δ MinHash 𝑘 𝑆2 = 2𝑘 1 − 𝐽 • ポアソン分布への近似により E 𝑠𝑖 = 1−𝑒−2𝑚/𝑛 2 , E[Popcount] = 𝑛 1−𝑒−2𝑚/𝑛 2 • これを適当に解くと上が得られる 精度保証 • 実は Biased (だけど bias は 1 以下) • この式自体の分散等のカッチリした bound は今のところ無い 論文中では良いパラメータ仮定の元で精度が良さそうな根拠を並べている. 実際にはパラメータも実験により決めており,このへんは若干イケてない. 19 XOR 1 の数 S1の Odd Sketch 対称差 𝑚 = MinHash 𝑘 𝑆1 Δ MinHash 𝑘 𝑆2
21.
Odd Sketches が得をする感覚的説明 20 [Figure
1-2, Mitzenmacher+, WWW’14]
22.
実験結果 他,論文中では実際の応用に組み込んでの結果なども示されてます. 21 [Mitzenmacher+, WWW’14]
23.
3. HyperLogLog による 集合異なり数推定の進歩 [Cohen,
PODS’14] 22
24.
集合異なり数の計算 集合異なり数 (distinct counting) •
重複を取り除き,異なるものの数を数えたい • 例:[1, 3, 5, 1, 2, 3, 2] → {1, 2, 3, 5} → 4 具体的な場面 • ウェブページのユニークビジター数 • 単語の DF (document frequency) の計算 (tf-idf) 23
25.
集合異なり数の計算 計算が “意外と” 難しい •
既に全データある (batch) → sort して unique かける • 少しずつ来る (stream) → set を用意して放り込む どちらも線形のメモリを使ってしまう. ユニークビジター数を監視したいとすると…… • 各ページについて set を用意? • 各ページに線形のメモリは,メモリを使いすぎでは? そこでやはり Sketching の出番! 現在最もよく使われているのが HyperLogLog Counter! [Flajolet+, AOFA’07] 24
26.
HyperLogLog のインパクト Google • PowerDrill
(data analysis platform) にて使われている [Hall+, VLDB’12] • その際行った改良についての論文も出ている [Heule+, EDBT’13] Twitter • Algebird (Abstract algebra library for Scala) に入っている https://github.com/twitter/algebird/search?q=hyperloglog&ref=cmdform Redis (open source key-value store) • データタイプとして HyperLogLog が選べる http://antirez.com/news/75 25
27.
HyperLogLog (𝒌 =
𝟏) HyperLogLog も MinHash の一種,ただし ハッシュ値を Base-2 Ranks で扱う Base-2 Ranks • 𝑎 ∈ 𝑆 の Base-2 rank 𝜚ℎ 𝑎 ≔ ℎ 𝑎 の先頭の 0 の数 • 例:ℎ 𝑎 = 00010101010 ⋯ → 𝜚ℎ 𝑎 = 3 HyperLogLog 𝒌 = 𝟏 • 𝑝 = max 𝜚ℎ 𝑎 | 𝑎 ∈ 𝑆 を計算 • 2 𝑝 として推定 26 3個 一般に base-𝑏 rank は − log 𝑏 ℎ(𝑎) 𝑛 (ℎ の値域を [1, n] として) 大きいヤツが珍しいので max を覚える 𝑝 以上になるのは 確率 2−𝑝 なので的な
28.
HyperLogLog (𝒌 >
𝟏) Jaccard 係数の時同様, 𝑘 個並べて推定を強化する. ただし,今回は入力を 𝒌 個に分割する. HyperLogLog [Flajolet+, AOFA’07] • 𝑘 = 2 𝑏 個のバケット 𝑀 𝑖 を用意 • ハッシュ値 ℎ 𝑎 の先頭 𝑏 bit でバケットに振り分け • 各バケットで,Base-2 rank の max を保存 集合異なり数の推定 • 各バケットで推定値を計算 • それらの normalized bias corrected harmonic mean を取る (式は若干大変なので論文を見て下さい) 27 ハッシュ値は勿論先頭 𝑏 bit を 捨てたものを使う
29.
HyperLogLog 28 [Figure 2, Flajolet+,
AOFA’07]
30.
HyperLogLog の理論的な性能 精度 • 相対誤差は
1.04/ 𝑘,CV (NRMSE) は 1.08/ 𝑘 • 定数確率で 1 ± 𝜀 近似するために必要な空間は 𝑂 𝜀−2 log log 𝑛 + log 𝑛 スペース • 各 𝑀 𝑖 の保存は 5 bit とかそんなもので良い → 5𝑘 bit これは near-optimal であるらしい. (漸近的性能はこれ以上の大幅な改善はできなさそう,ということ) 29 LogLog の名前を冠する所以
31.
HyperLogLog の問題点 実は,値が大きくならないと滅茶苦茶 30 [Figure 2,
Heule+, EDBT’13]
32.
値が小さい時の対策 アルゴリズムを組み合わせる • Linear Counting
[Whang+, TODS’09] など 無理やり直す [Heule+, EDBT’13] • 右図のような巨大な表を前計算 (Google PowerDrill にはこれが組み込まれている) 美しくない! 31
33.
HIP Estimator Historic Inverse
Probability Estimator [Cohen, PODS’14] • 値が小さい時も推定が正確になる • 漸近的な精度も大きく向上 着想 • HyperLogLog は near-optimal だったのでは? • データ構造の最終状態から直接推定値を得るという仮定 • 最終状態だけでなく,計算途中の全ての状態を加味する とどうか? 32 素晴らしい!
34.
HyperLogLog with HIP
Estimator 33 [Figure 4, Cohen, PODS’14] データ構造に集合を流しこみつつ 最初から数の集計も進める バケットを更新する度に 「この状況でここが更新される確率」 を使って集計値に加算する
35.
HIP Estimator 仕組み&理論値 動作原理はシンプル •
一般論:確率 𝑝 で発生 → 発生までの回数の期待値は 1/𝑝 • これに基づき,スケッチ値がそこで更新される条件付き 確率を考え,その逆数を足していけば良い 理論的解析 • CV (NRMSE) 3/4𝑘 ≈ 0.866/ 𝑘 (← HLL は 1.08/ 𝑘) • 0.56 倍のレジスタ数で同じ精度 – カウンタ 𝑐 も新しく覚えておくことを加味しても優れている HyperLogLog 以外でも,MinHash の変化を用いる時は常に適用可能 (例:All-Distances Sketches) 34 Historic Inverse Probability と呼ばれる所以
36.
実験結果 35 [Figure 3, Cohen,
PODS’14]
37.
まとめ 背景 • 大量の集合を皆が扱いたい時代 • そのための基礎技術としての集合
Sketching を紹介 基礎 • 全ての基本:MinHash • Jaccard 係数推定: 𝒃-bit MinHash • 集合異なり数推定:HyperLogLog 最新 • Jaccard 係数推定(高類似度):Odd Sketches • 集合異なり数推定:HIP Estimator 36
Download


![3
今日の話:集合 Sketching の最新技術
1. MinHash Sketches 入門
• 基礎的かつ強力な手法である MinHash を復習
(以降の話も両方 MinHash の派生系)
2. Odd Sketches による Jaccard 係数推定の進歩
• まず,現在よく用いられている 𝒃-bit MinHash を紹介
• 類似性が高い際 𝑏-bit MinHash が劣化する問題を解消
[Mitzenmacher-Pagh-Pham, WWW’14]
3. HIP Estimator による集合異なり数推定の進歩
• まず,現在よく用いられている HyperLogLog Counter を紹介
• 要素挿入時の情報を用い精度を改善,誤差 1.08/ 𝑚 → 0.87/ 𝑚
[Cohen, PODS’14]
WWW’14 Best Paper!](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-4-2048.jpg)






![2. Odd Sketches による
Jaccard 係数推定の進歩
[Mitzenmacher-Pagh-Pham, WWW’14]
11](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-12-2048.jpg)
![𝒃-bit MinHash
MinHash の改善できそうなところ
• さっきの MinHash ではハッシュ値をそのまま保存
• 各々に 32bit (or 64bit) も使うと個数 𝑘 をあまり増やせない
• 衝突を覚悟してもハッシュ値を小さくして,その分 𝑘 を
増やしてはどうか?
𝒃-bit MinHash [Li-König, WWW’10]
• 異なる 𝑘 個のハッシュ関数 ℎ1, ℎ2, … , ℎ 𝑘 を用意
• それぞれについてさっきの min を計算
• ハッシュ値の下位 𝑏 bit のみを保存
(データサイズは 𝑘𝑏 bit になる)
12
𝑏 = 1 という極端な場合が
実は一番性能が良かったり](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-13-2048.jpg)


![𝒃-bit MinHash が微妙な時
• 類似度 𝐽 が 1 に近い時,2 つのスケッチはほぼ同じ
• 異なっている若干のビット数で,1 との差を見積もる
• つまり,1 との差を表現するのは全体のごく一部
15
[Figure 1, Mitzenmacher+, WWW’14]](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-16-2048.jpg)
![Odd Sketches
そこで高い類似度での精度を重視し改善するのが
Odd Sketches [Mitzenmacher-Pagh-Pham, WWW’14]
着想
• XOR を活用する
• 共通部分を打ち消させる
• 異なっている部分の情報だけを綺麗に得る](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-17-2048.jpg)
![Odd Sketches
Odd Sketches [Mitzenmacher-Pagh-Pham, WWW’14]
• まず集合の要素を 𝑘-min MinHash で 𝑘 個選ぶ
• 𝑛 bit のビットベクトル 𝑠 を用意,最初は全箇所 0
• 選ばれてる各要素 𝑎 について,𝑠 ℎ′ 𝑎 を反転する
𝑘 と 𝑛 がパラメータ.ℎ′: 値域 [1, 𝑛] のハッシュ関数を別途用意
17
集合 𝑆
hoge
piyo
fuga
1 piyo
2 hoge
𝑘-min MinHash
𝑘 = 2
0 1 0 0 1 0
Odd Sketch
𝑛 = 6](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-18-2048.jpg)

![Odd Sketches による Jaccard 係数の推定
𝐽 = 1 +
𝑛
4𝑘
ln 1 −
2 × Popcount odd 𝑆1 ⨂odd 𝑆2
𝑛
導出
• E MinHash 𝑘 𝑆1 Δ MinHash 𝑘 𝑆2 = 2𝑘 1 − 𝐽
• ポアソン分布への近似により E 𝑠𝑖 =
1−𝑒−2𝑚/𝑛
2
, E[Popcount] = 𝑛
1−𝑒−2𝑚/𝑛
2
• これを適当に解くと上が得られる
精度保証
• 実は Biased (だけど bias は 1 以下)
• この式自体の分散等のカッチリした bound は今のところ無い
論文中では良いパラメータ仮定の元で精度が良さそうな根拠を並べている.
実際にはパラメータも実験により決めており,このへんは若干イケてない.
19
XOR
1 の数
S1の Odd Sketch
対称差
𝑚 = MinHash 𝑘 𝑆1 Δ MinHash 𝑘 𝑆2](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-20-2048.jpg)
![Odd Sketches が得をする感覚的説明
20
[Figure 1-2, Mitzenmacher+, WWW’14]](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-21-2048.jpg)
![実験結果
他,論文中では実際の応用に組み込んでの結果なども示されてます.
21
[Mitzenmacher+, WWW’14]](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-22-2048.jpg)
![3. HyperLogLog による
集合異なり数推定の進歩
[Cohen, PODS’14]
22](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-23-2048.jpg)
![集合異なり数の計算
集合異なり数 (distinct counting)
• 重複を取り除き,異なるものの数を数えたい
• 例:[1, 3, 5, 1, 2, 3, 2] → {1, 2, 3, 5} → 4
具体的な場面
• ウェブページのユニークビジター数
• 単語の DF (document frequency) の計算 (tf-idf)
23](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-24-2048.jpg)
![集合異なり数の計算
計算が “意外と” 難しい
• 既に全データある (batch) → sort して unique かける
• 少しずつ来る (stream) → set を用意して放り込む
どちらも線形のメモリを使ってしまう.
ユニークビジター数を監視したいとすると……
• 各ページについて set を用意?
• 各ページに線形のメモリは,メモリを使いすぎでは?
そこでやはり Sketching の出番!
現在最もよく使われているのが HyperLogLog Counter!
[Flajolet+, AOFA’07]
24](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-25-2048.jpg)
![HyperLogLog のインパクト
Google
• PowerDrill (data analysis platform) にて使われている [Hall+, VLDB’12]
• その際行った改良についての論文も出ている [Heule+, EDBT’13]
Twitter
• Algebird (Abstract algebra library for Scala) に入っている
https://github.com/twitter/algebird/search?q=hyperloglog&ref=cmdform
Redis (open source key-value store)
• データタイプとして HyperLogLog が選べる
http://antirez.com/news/75
25](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-26-2048.jpg)
![HyperLogLog (𝒌 = 𝟏)
HyperLogLog も MinHash の一種,ただし
ハッシュ値を Base-2 Ranks で扱う
Base-2 Ranks
• 𝑎 ∈ 𝑆 の Base-2 rank 𝜚ℎ 𝑎 ≔ ℎ 𝑎 の先頭の 0 の数
• 例:ℎ 𝑎 = 00010101010 ⋯ → 𝜚ℎ 𝑎 = 3
HyperLogLog 𝒌 = 𝟏
• 𝑝 = max 𝜚ℎ 𝑎 | 𝑎 ∈ 𝑆 を計算
• 2 𝑝
として推定
26
3個
一般に base-𝑏 rank は
− log 𝑏
ℎ(𝑎)
𝑛
(ℎ の値域を [1, n] として)
大きいヤツが珍しいので
max を覚える
𝑝 以上になるのは
確率 2−𝑝
なので的な](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-27-2048.jpg)
![HyperLogLog (𝒌 > 𝟏)
Jaccard 係数の時同様, 𝑘 個並べて推定を強化する.
ただし,今回は入力を 𝒌 個に分割する.
HyperLogLog [Flajolet+, AOFA’07]
• 𝑘 = 2 𝑏 個のバケット 𝑀 𝑖 を用意
• ハッシュ値 ℎ 𝑎 の先頭 𝑏 bit でバケットに振り分け
• 各バケットで,Base-2 rank の max を保存
集合異なり数の推定
• 各バケットで推定値を計算
• それらの normalized bias corrected harmonic mean を取る
(式は若干大変なので論文を見て下さい)
27
ハッシュ値は勿論先頭 𝑏 bit を
捨てたものを使う](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-28-2048.jpg)
![HyperLogLog
28
[Figure 2, Flajolet+, AOFA’07]](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-29-2048.jpg)

![HyperLogLog の問題点
実は,値が大きくならないと滅茶苦茶
30
[Figure 2, Heule+, EDBT’13]](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-31-2048.jpg)
![値が小さい時の対策
アルゴリズムを組み合わせる
• Linear Counting [Whang+, TODS’09] など
無理やり直す [Heule+, EDBT’13]
• 右図のような巨大な表を前計算
(Google PowerDrill にはこれが組み込まれている)
美しくない!
31](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-32-2048.jpg)
![HIP Estimator
Historic Inverse Probability Estimator
[Cohen, PODS’14]
• 値が小さい時も推定が正確になる
• 漸近的な精度も大きく向上
着想
• HyperLogLog は near-optimal だったのでは?
• データ構造の最終状態から直接推定値を得るという仮定
• 最終状態だけでなく,計算途中の全ての状態を加味する
とどうか?
32
素晴らしい!](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-33-2048.jpg)
![HyperLogLog with HIP Estimator
33
[Figure 4, Cohen, PODS’14]
データ構造に集合を流しこみつつ
最初から数の集計も進める
バケットを更新する度に
「この状況でここが更新される確率」
を使って集計値に加算する](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-34-2048.jpg)

![実験結果
35
[Figure 3, Cohen, PODS’14]](https://image.slidesharecdn.com/2014-05-29pfi-140529061052-phpapp01/75/MinHash-HyperLogLog-36-2048.jpg)



























![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)










![[アルゴリズムイントロダクション勉強会] ハッシュ](https://cdn.slidesharecdn.com/ss_thumbnails/random-171021132555-thumbnail.jpg?width=640&height=640&fit=bounds)























