엔터프라이즈의 IT 환경
•현재 엔터프라이즈 IT 환경은
빅데이터를 적용하기 어려운 환경
IT 기획 및 관리 중심, 실행은 아웃 소싱(BAD)
IT 자회사가 관리 및 실행(BAD)
주요 운영/개발은 직접 수행, 일부 외주(GOOD)
대부분 직접 수행(GOOD)
5.
빅데이터 프로젝트의 성공요소
• 분석 결과 가치 > 분석 비용
• 무엇을 분석할 것인가에 대한 고민
• 지속적인 분석 결과 개선 활동(튜닝)
• IT 부서가 아닌 실제 데이터 사용부서가 주도
• !잘 작성된 프로젝트 계획서
• 실행할 수 있는 기술력
6.
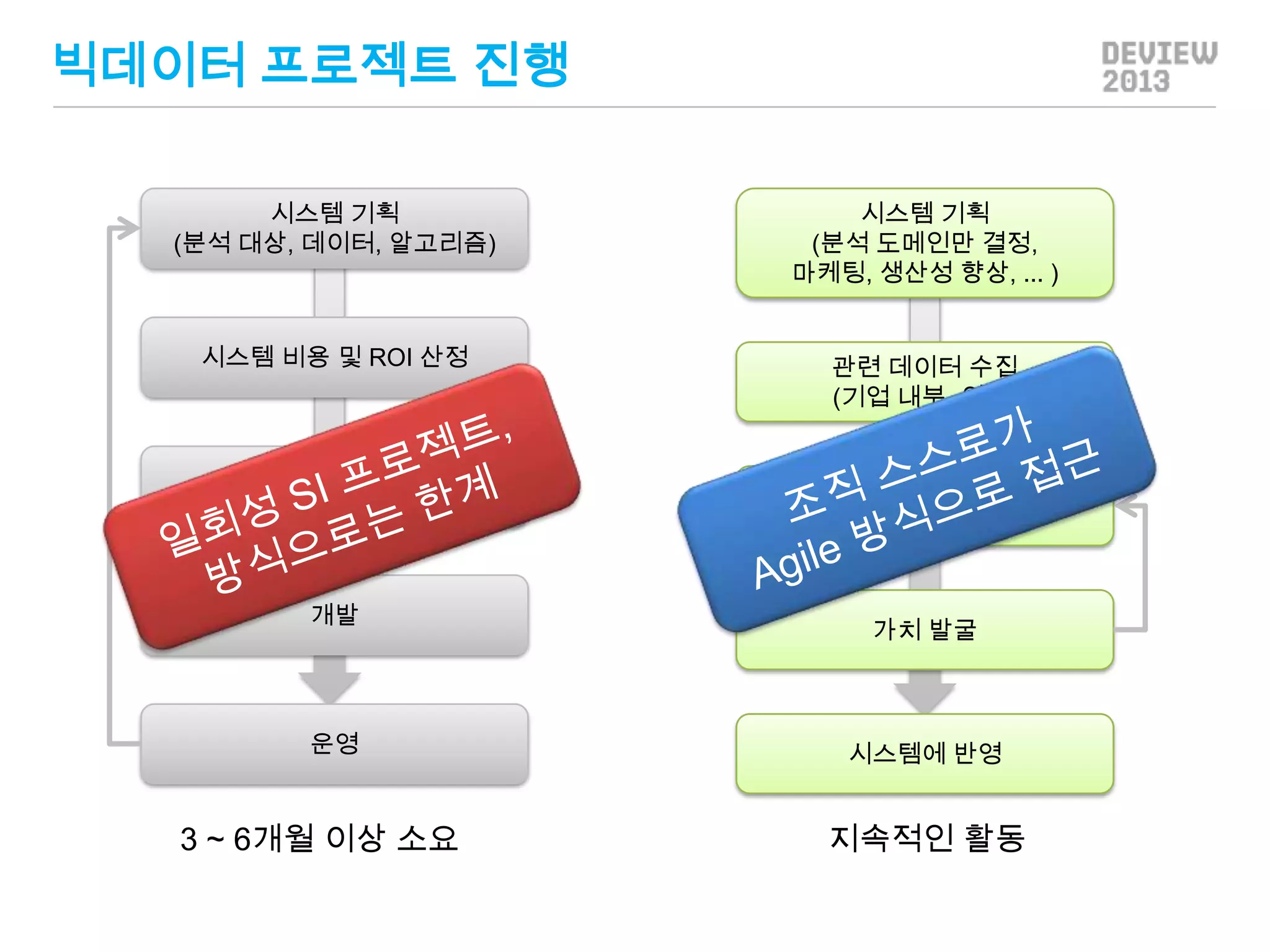
빅데이터 프로젝트 진행
시스템기획
(분석 대상, 데이터, 알고리즘)
시스템 기획
(분석 도메인만 결정,
마케팅, 생산성 향상, ... )
시스템 비용 및 ROI 산정
관련 데이터 수집
(기업 내부, 외부)
업체 선정
개발
운영
3 ~ 6개월 이상 소요
데이터 가지고 놀기
가치 발굴
시스템에 반영
지속적인 활동
7.
결론!!!
• 기존의 데이터분석과 현재의 빅데이터의 가
장 큰 차이는
• 데이터 크기도 아니고, 종류도 아니고, 속도
도 아닌
• 기업 스스로 데이터를 적극적으로 이용
해서 제품 개발, 서비스 기능, 마케팅 등에 차
별화되고 경쟁 우위에 있는 무기를 가지는 것.
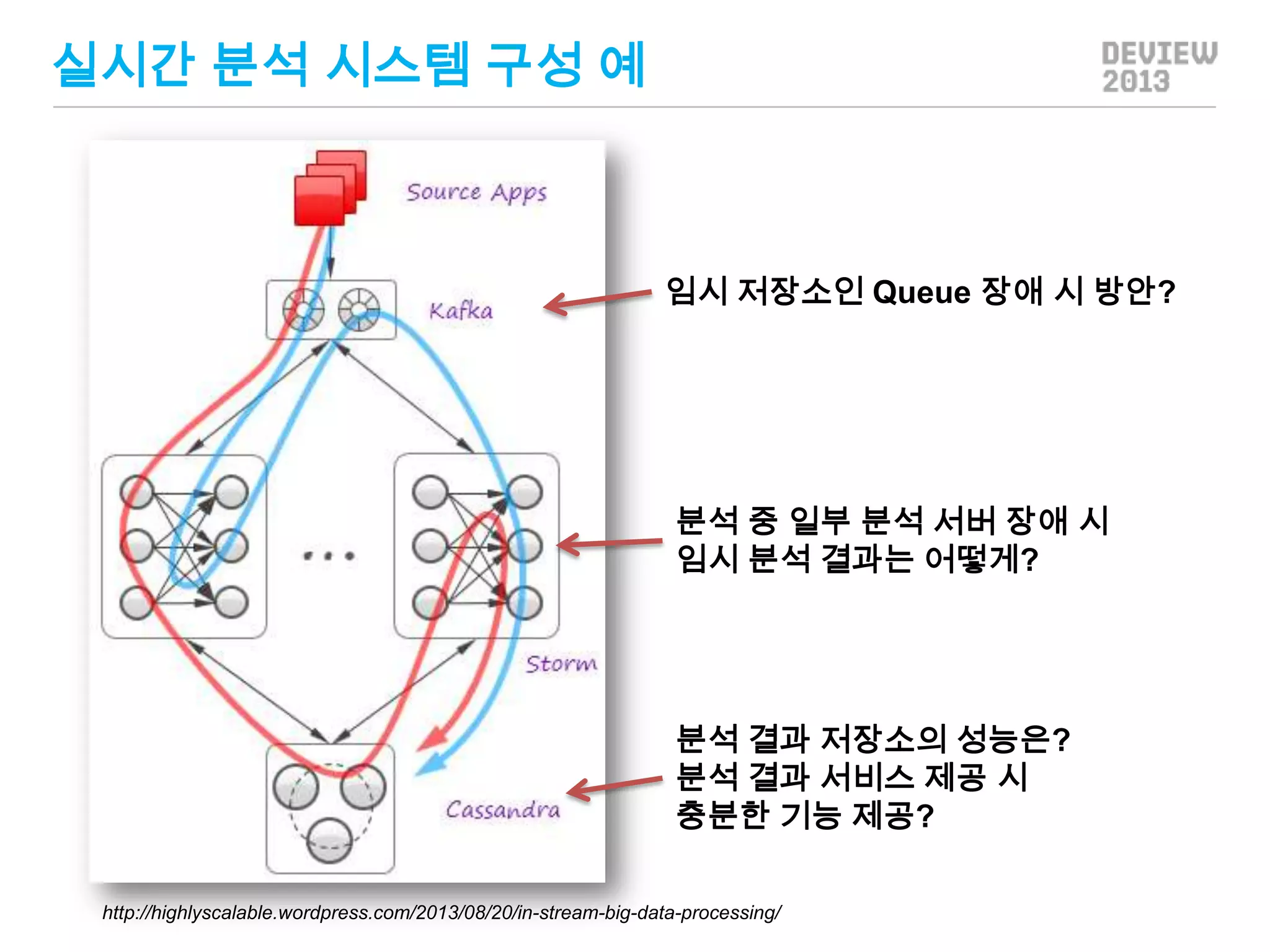
실시간 분석 시스템구성 예
임시 저장소인 Queue 장애 시 방안?
분석 중 일부 분석 서버 장애 시
임시 분석 결과는 어떻게?
분석 결과 저장소의 성능은?
분석 결과 서비스 제공 시
충분한 기능 제공?
http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/
13.
실시간 분석 어려움#1
• 중복, 유실, 성능 모두를 만족시키기 어려움
• 이중화된 큐와 체크 포인팅 기능이 핵심
• 체크 포인팅을 자주 하면 성능 저하
• 가끔 하면 데이터 유실이 높아짐
• 성능
• 대량의 데이터, 분석의 복잡성(다양한 메타 데이터와 연
계 등)
• 운영 관리
• 무정지로 운영 되어야 함
• 프로그램 배포
• 분석 결과 저장
• 저장 주기, 체크 포인트
• 저장소 성능, 기능
14.
실시간 분석 어려움#2
• 시간 관리
• 분산된 환경의 시간 동기화
• Time window 동기화
• Data time vs. System time
• 분석 로직 구현
• SQL 기반
• 프로그램 기반
• 플랫폼들의 조합
• Flume, Storm, Kafka 등
• 각각은 HA 등에 대한 기능 제공, But 조합 시 불협화음
• 서버 사이징
• Agent/Collelctor 댓수 비율, CPU/Network 등
15.
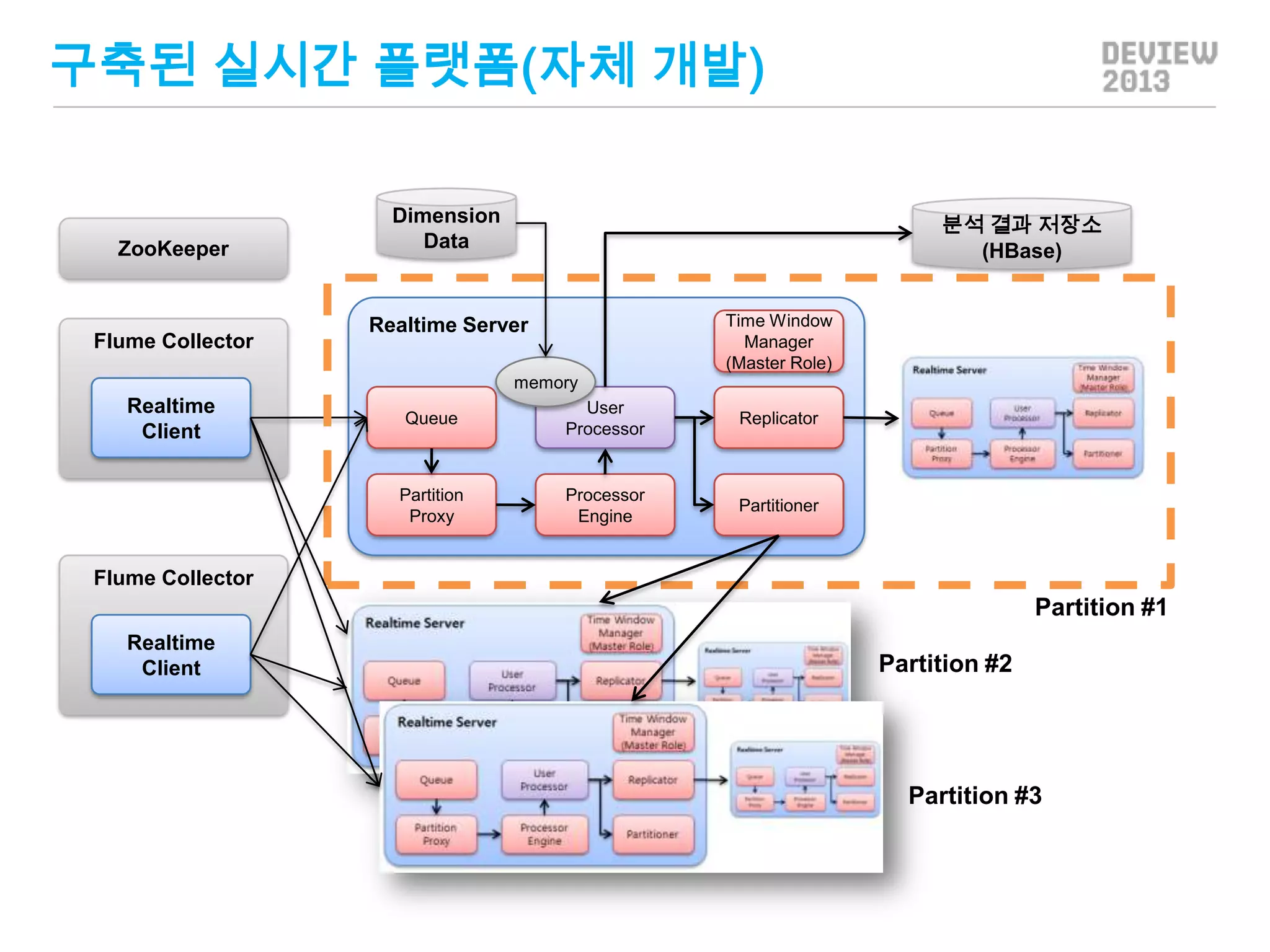
구축된 실시간 플랫폼(자체개발)
ZooKeeper
Flume Collector
Dimension
Data
분석 결과 저장소
(HBase)
Time Window
Manager
(Master Role)
Realtime Server
memory
Realtime
Client
Queue
User
Processor
Replicator
Partition
Proxy
Processor
Engine
Partitioner
Flume Collector
Partition #1
Realtime
Client
Partition #2
Partition #3
16.
특징 #1
• 고정된크기의 클러스터 파티션
• 데이터 파티션 처리 쉬운 장점
• 서버 추가/제거 단점은 Shell 명령을 통해 실행
• 파티션 이중화
• 하나의 파티션은 두 개의 서버가 담당(Master/Slave)
• 분산 실시간 분석에 필요한 다양한 모듈 기본 제공
• 분산된 서버들 사이에 동기화된 Flush 기능
• Time 동기화 기능, Esper 연계 모듈
• WorkGroup
• 하나의 분석을 수행하기 위해서는 여러 개의 분석 모듈이
연결 되어야 함.
• 하나의 클러스터로 여러 개의 분석 업무를 동시에 수행
17.
특징 #2
• 자체개발
• 공개된 실시간 분석 솔루션은 다음 기능 제공
• 데몬 서버, 데이터 송수신 RPC
• 프로그램 모델, 데이터 파티셔닝, Queue와 연동
• 활용 가능한 조각 모음은 대부분 오픈 소스로 나와 있음
• RPC: Thrift, Avro, Protobuf, Netty
• Event, Cluster Membership, Synchronization:
ZooKeeper
• Query Processing: Esper
• Queue: Kafka, RabbitMQ, ZeroMQ
18.
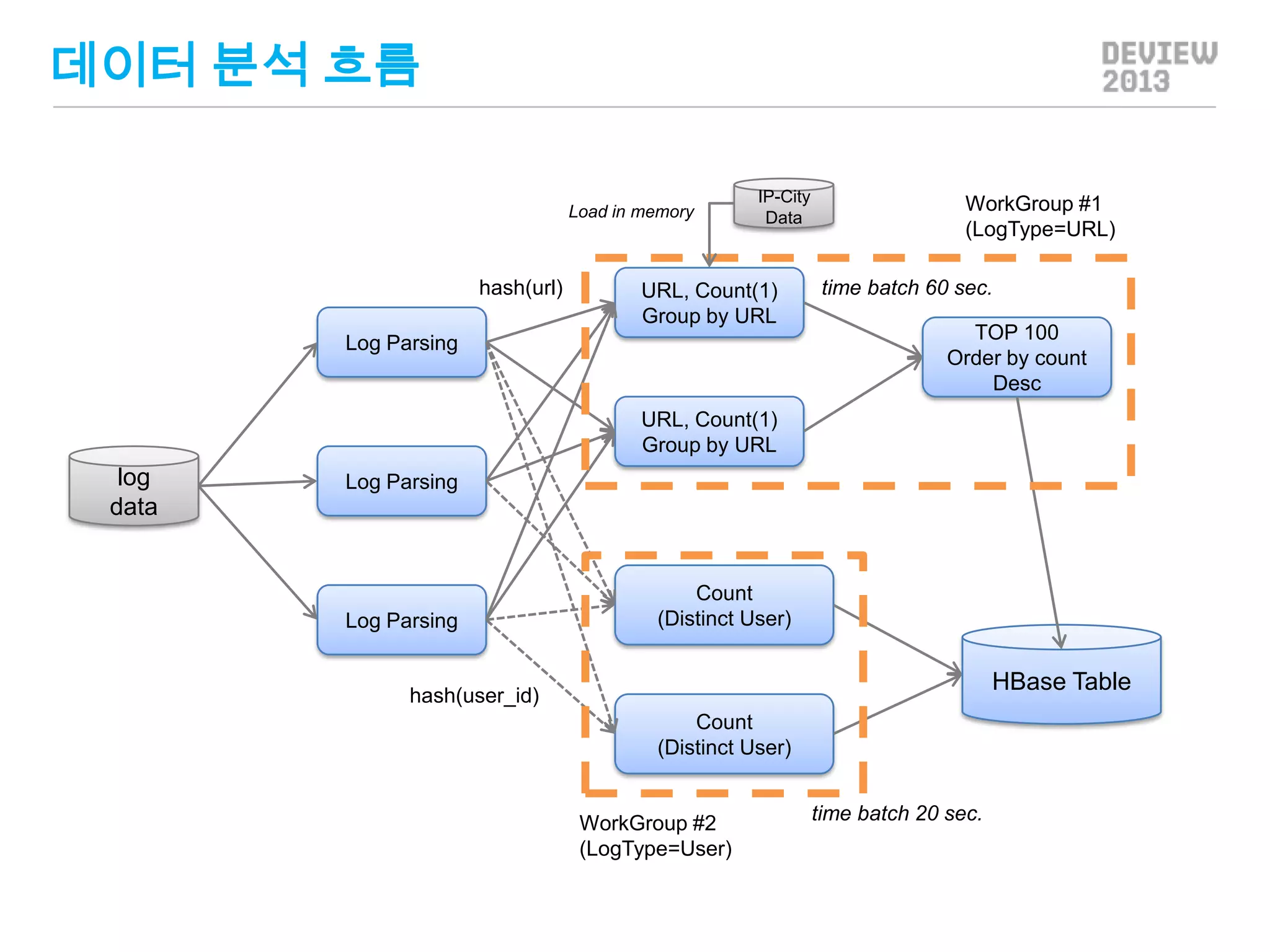
데이터 분석 흐름
Loadin memory
hash(url)
IP-City
Data
URL, Count(1)
Group by URL
Log Parsing
WorkGroup #1
(LogType=URL)
time batch 60 sec.
TOP 100
Order by count
Desc
URL, Count(1)
Group by URL
log
data
Log Parsing
Log Parsing
Count
(Distinct User)
HBase Table
hash(user_id)
Count
(Distinct User)
WorkGroup #2
(LogType=User)
time batch 20 sec.
19.
결론
• 실시간 분석은대세이지만 많은 난관이 존재
• 고객의 요구(정합성, 안정성 모두 만족 등)
• 메타 정보(JOIN) 처리 성능
• 운영의 어려움(항상 데이터가 흘러 다님)
• 분석 대상 데이터의 속성, 분석 로직 등에 따라 적절한
플랫폼 선택
• 플랫폼은 기본만 제공
• 많은 것을 그 위에 만들어야 함
• 적절한 플랫폼이 없으면 만드는 것도 방법
보안 데이터 분석
데이터를수집해서
통합 저장소에 저장한 다음
분석을 통해서 보안 위협을 찾아내고
모델을 만들어서
실시간 감지 및 대응 시스템에 적용해서
보안 공격에 대비한다
이 과정을 지속적으로 반복하면서 더 강력하고
지능적인 모델을 만들어서 변화하는 보안 위협
에 대응한다
22.
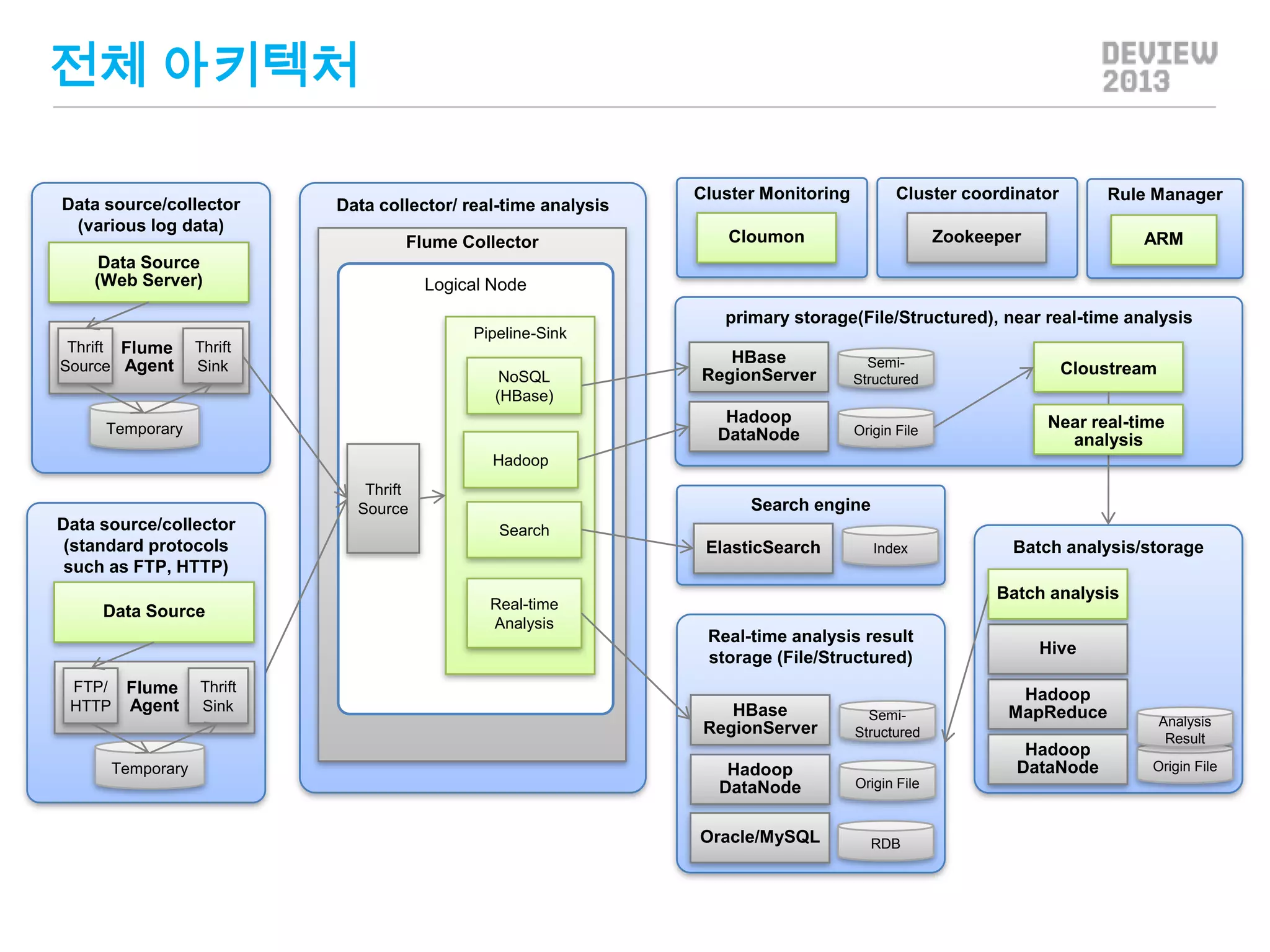
전체 아키텍처
Data source/collector
(variouslog data)
Data collector/ real-time analysis
Flume Collector
Data Source
(Web Server)
Cluster Monitoring
Cluster coordinator
Rule Manager
Zookeeper
ARM
Cloumon
Logical Node
primary storage(File/Structured), near real-time analysis
Thrift Flume
Source Agent
Pipeline-Sink
Thrift
Sink
Temporary
HBase
RegionServer
SemiStructured
Cloustream
Hadoop
DataNode
NoSQL
(HBase)
Origin File
Near real-time
analysis
Hadoop
Thrift
Source
Data source/collector
(standard protocols
such as FTP, HTTP)
Data Source
FTP/ Flume
HTTP Agent
Temporary
Thrift
Sink
Search engine
Search
ElasticSearch
Real-time
Analysis
Index
Batch analysis/storage
Batch analysis
Real-time analysis result
storage (File/Structured)
HBase
RegionServer
SemiStructured
Hive
Hadoop
MapReduce
Hadoop
DataNode
Hadoop
DataNode
Origin File
Oracle/MySQL
RDB
Analysis
Result
Origin File
23.
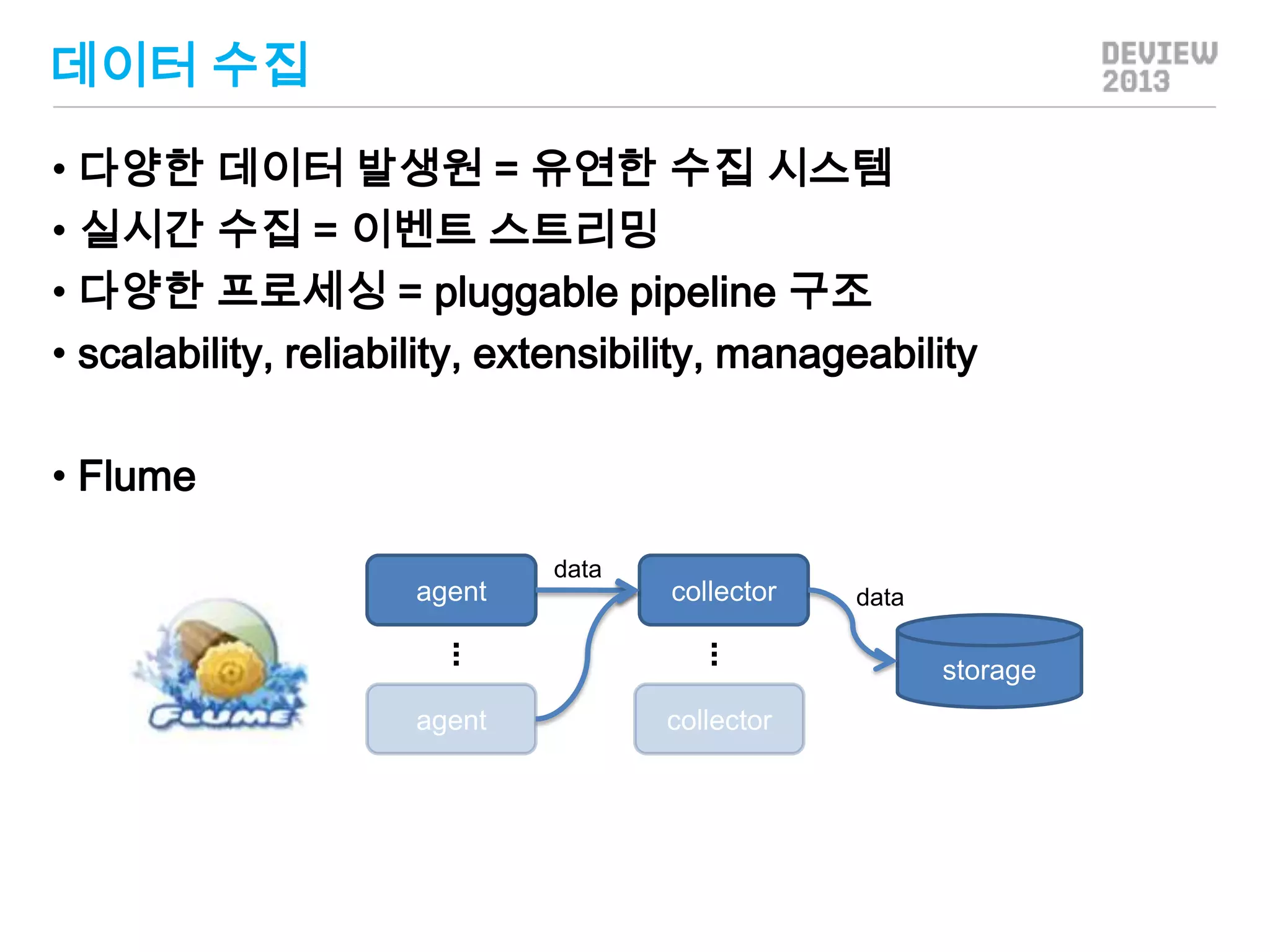
데이터 수집
• 다양한데이터 발생원 = 유연한 수집 시스템
• 실시간 수집 = 이벤트 스트리밍
• 다양한 프로세싱 = pluggable pipeline 구조
• scalability, reliability, extensibility, manageability
• Flume
agent
data
collector
.
.
.
.
agent
collector
data
storage
24.
실시간 데이터 수집#1
• Flume OG 사용
• 중앙 집중 관리 기능이 우수(NG에 비해)
• 도입 당시 NG는 성숙된 상태가 아니었음
• Tailing이 쉽지 않음
• 기본 제공 Tailer는 실제 업무 적용에 한계
• 기존 운영 장비 부하 최소(CPU/Network 등)
• CPU 5%이하, Memory 32MB 이하
• Checkpoint 관리 기능
• Agent 재 시작 시 Throttling 기능
• Network 대역 모두 사용 문제
• Rolling File에 대한 인식
• Windows 2000 Server?
25.
실시간 데이터 수집#2
• 다양한 프로토콜 및 장비 지원
• TCP, Syslog, SNMP 등
• Linux, AIX, HP-UX, Solaris, Windows
• 유실/중복/성능 모두 만족하기 어려움
• Collector 이중화
• Agent -> Collector -> 저장소까지 저장 후 ACK(성능 저
하)
• 데이터 수집이 잘되고 있는지 모니터링 어려움
• Component(Agent, Switch, Collector, 저장소 등) 모니터
링 구성 필요 -> 어려움
• 개발 외부적인 사항이 더 큰 어려움
• 방화벽 해제
• Agent 설치에 대한 거부감
26.
대용량 데이터 검색
•요구사항
• 전체 수집 데이터(수백GB/일), 누적 6개월 보관, 응답속도
는 10 ~ 30초 이내
• 현실은?
• 상용 솔루션은 고가의 비용, 라이선스가 트래픽 중심
• 일반적인 검색 솔루션(오픈소스 솔루션 포함)은 서비스에
맞춰져 있어 대용량, 장기간 데이터 보관에는 취약
• 아이디어
• 검색 클러스터 이중화
• 최근 데이터 인덱스/검색용 -> Native ElasticSearch
• 과거 대용량 데이터 보관/검색용 -> ElasticSearch for
Hadoop
27.
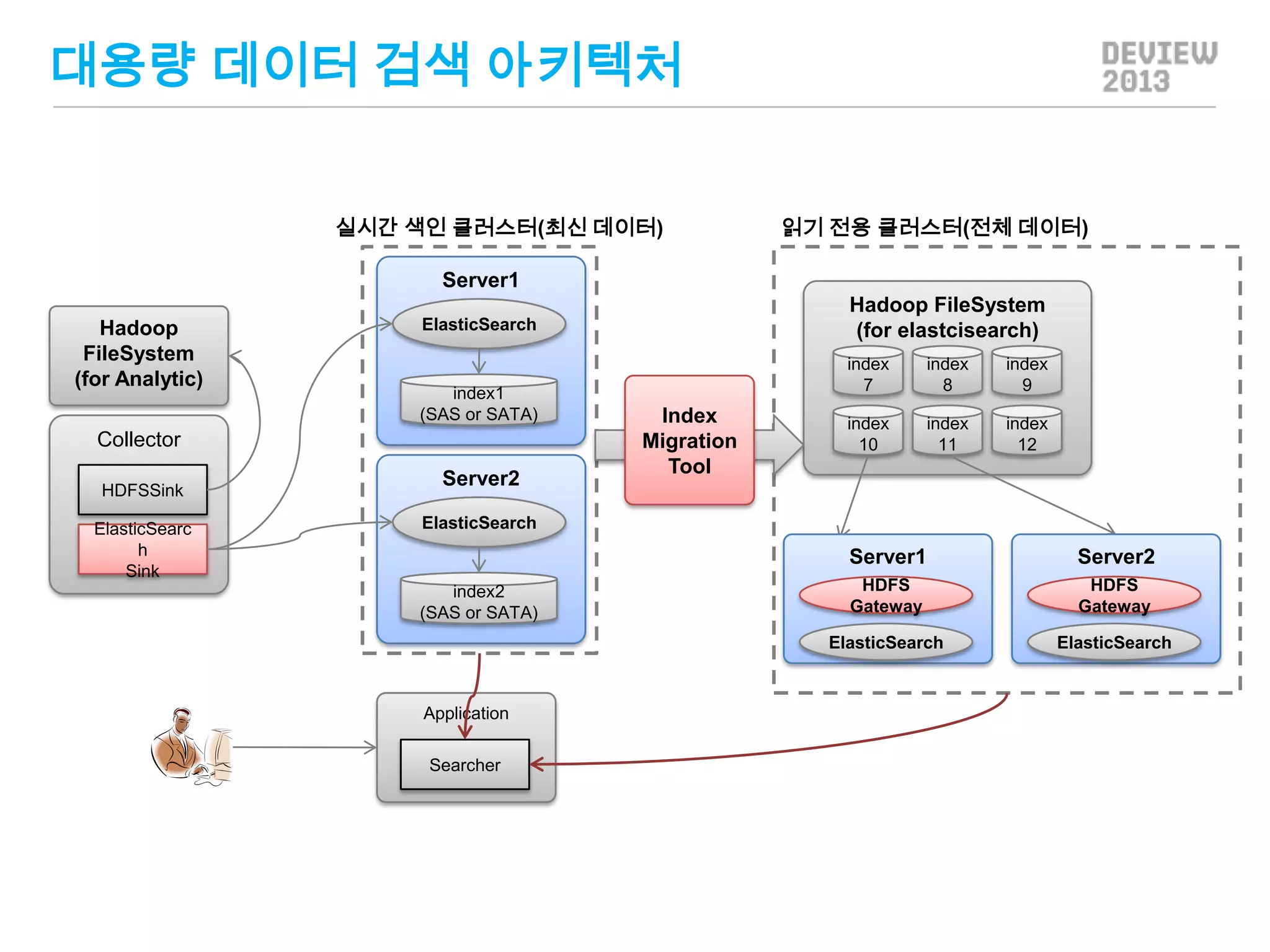
대용량 데이터 검색아키텍처
실시간 색인 클러스터(최신 데이터)
읽기 전용 클러스터(전체 데이터)
Server1
Hadoop
FileSystem
(for Analytic)
index1
(SAS or SATA)
Collector
HDFSSink
ElasticSearc
h
Sink
Hadoop FileSystem
(for elastcisearch)
ElasticSearch
Server2
index
7
Index
Migration
Tool
index
8
index
9
index
10
index
11
index
12
ElasticSearch
Server1
Application
Searcher
HDFS
Gateway
HDFS
Gateway
ElasticSearch
index2
(SAS or SATA)
Server2
ElasticSearch
Challenges
• 도메인 이해의어려움
• AATCTATA AATCTATA AATCTATA …
• 수 많은 알고리즘 및 수식
• Maxam-Gilbert sequencing
• R-Tree
• 다양한 Data format
• FASTA, SAM, BAM, SNP, CNV, Inversion
Large InDel, Small InDel
• 대용량 레코드 저장과 검색 (Read only)
31.
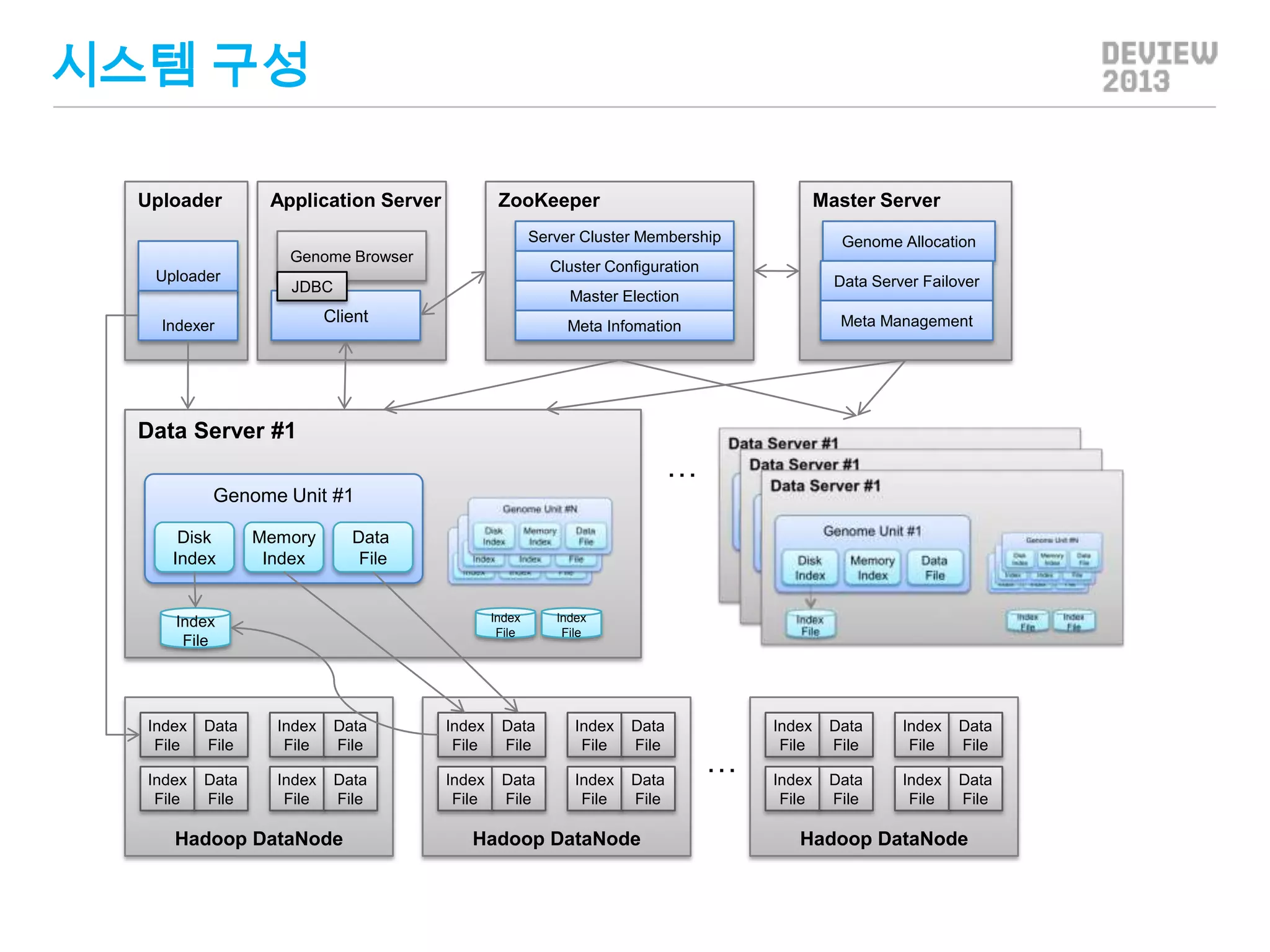
시스템 구성
Uploader
Application Server
ZooKeeper
MasterServer
Server Cluster Membership
Genome Browser
Uploader
Data Server Failover
JDBC
Master Election
Client
Indexer
Genome Allocation
Cluster Configuration
Meta Management
Meta Infomation
Data Server #1
…
Genome Unit #1
Disk
Index
Memory
Index
Data
File
Index
File
Index
File
Index
File
Index
File
Data
File
Index
File
Data
File
Index
File
Data
File
Index
File
Data
File
Index
File
Data
File
Index
File
Data
File
Index
File
Data
File
Index
File
Data
File
Hadoop DataNode
Hadoop DataNode
…
Index
File
Data
File
Index
File
Data
File
Index
File
Data
File
Index
File
Data
File
Hadoop DataNode
32.
결론
• Hadoop을 이용하여
•대용량 데이터를 저장하면서도
• 저장된 데이터를 1 ~ 2 ms 이내에 조회할 수 있는
시스템을 구성할 수 있다.
프로젝트 조직 구성
•기획자
• 분석 룰 구성 및 데이터 검증
• 결과 데이터 이용 서비스 기획 반영
• 아키텍처
• 대부분의 시스템 구성 및 데이터 관리 체계를 알고 있음
• 직접 개발에 참여, 개발도 잘함
• 개발자
• 대부분의 분석 룰 개발 업무를 수행
• 시스템 운영자
• Hadoop 클러스터 설치 및 운영
• 관리자
• 데이터 검증에 적극 참여
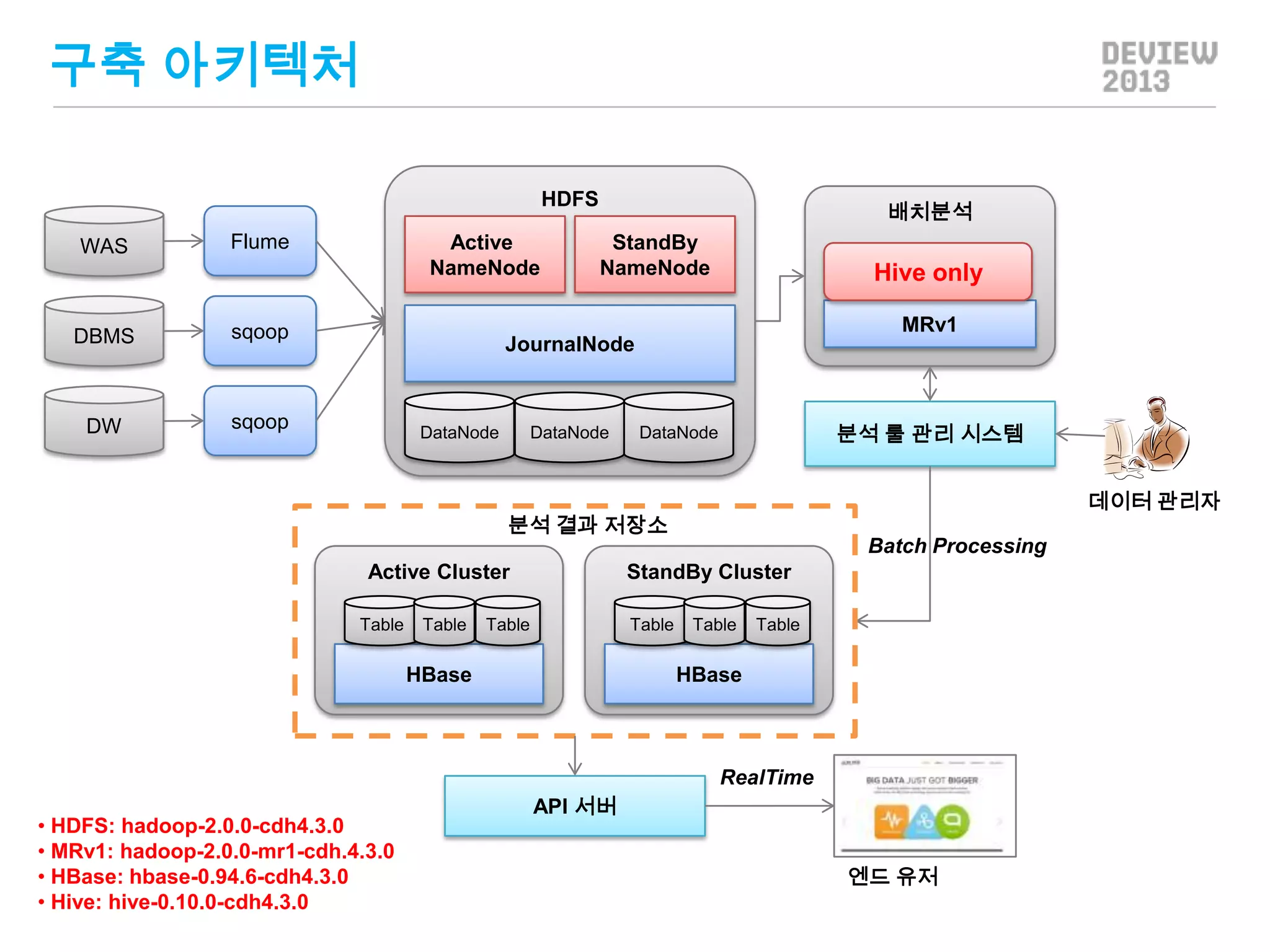
분석 룰 관리시스템 #1
너무 많은 구현 대상 Hive 질의
그 많은 질의를 다 만들 것인가?
질의 내 반복되는 패턴 분석
상속 관계가 형성되는 질의
파라미터만 변경되는 질의
질의를 쉽게 만들고, 재사용할 수 있는 방법
은?
39.
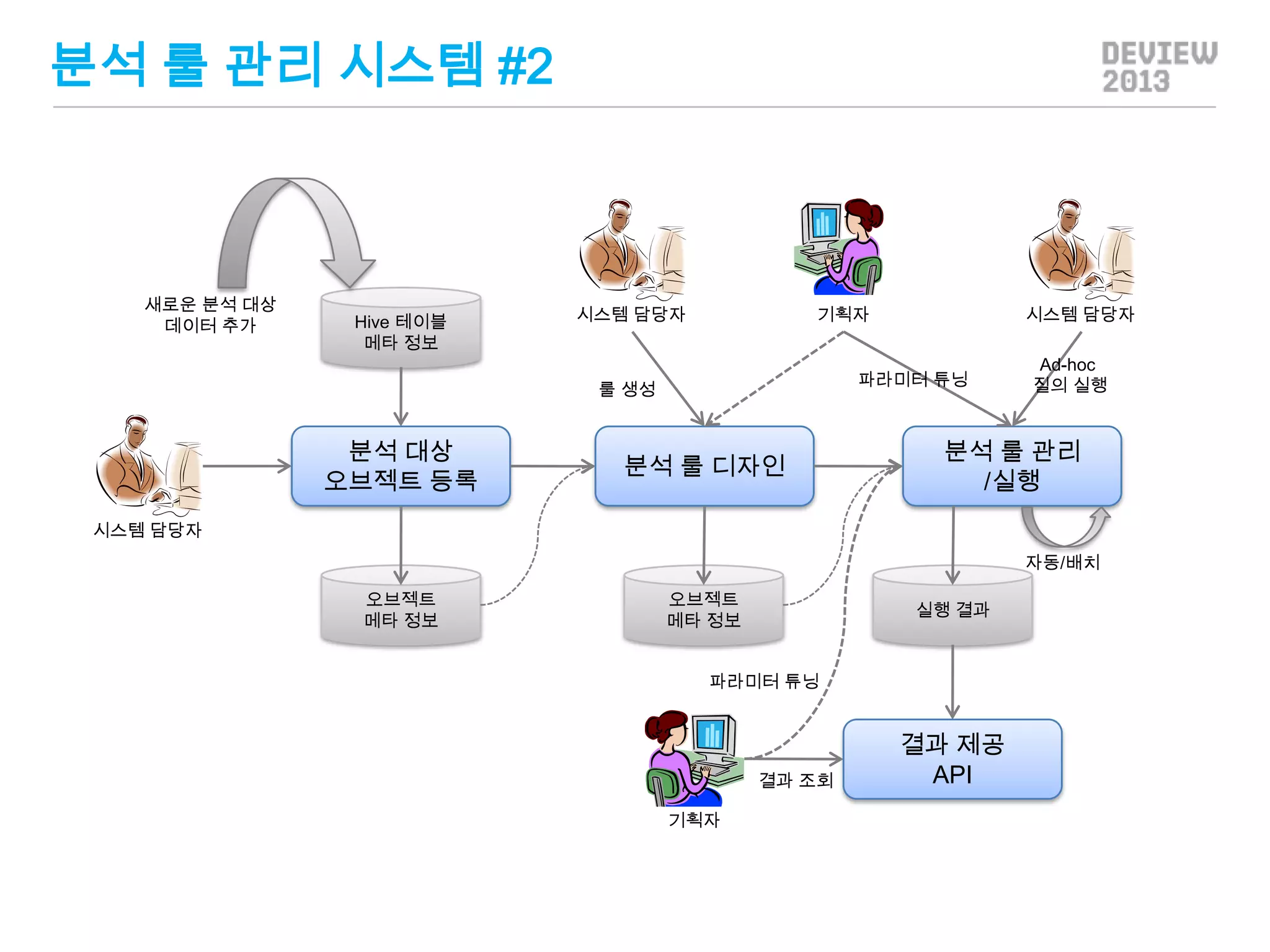
분석 룰 관리시스템 #2
새로운 분석 대상
데이터 추가
Hive 테이블
메타 정보
시스템 담당자
기획자
파라미터 튜닝
룰 생성
분석 대상
오브젝트 등록
시스템 담당자
분석 룰 디자인
Ad-hoc
질의 실행
분석 룰 관리
/실행
시스템 담당자
자동/배치
오브젝트
메타 정보
오브젝트
메타 정보
실행 결과
파라미터 튜닝
결과 조회
기획자
결과 제공
API
40.
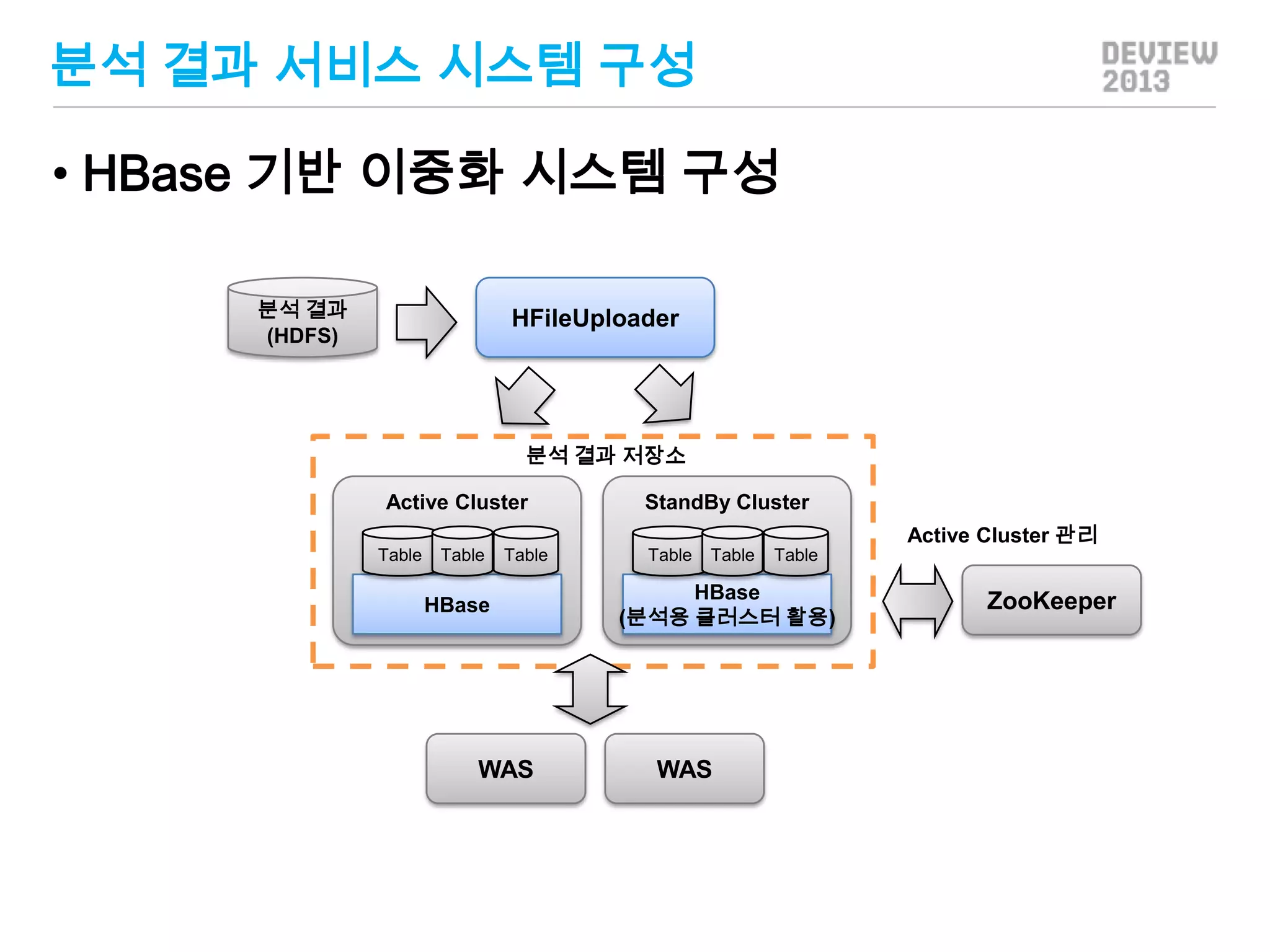
분석 결과 서비스
•해결해야 될 문제
• 분석 결과 데이터가 너무 크다.
• 사용자 * 제품 수 * 일자 * 분석 룰 개수
• 분석 결과 입력은 어떻게?
• 일반 사용자 대상 서비스이기 때문에 안정적 운
영
• 조회 성능도 좋아야 함
41.
분석 결과 서비스시스템 구성
• HBase 기반 이중화 시스템 구성
분석 결과
(HDFS)
HFileUploader
분석 결과 저장소
Active Cluster
StandBy Cluster
Active Cluster 관리
Table
Table
Table
HBase
WAS
Table
Table
Table
HBase
(분석용 클러스터 활용)
WAS
ZooKeeper
42.
추진과정 #1
• Stage1
•DW 학습에 의한 기대 심리
• 빅데이터 특성을 고려하지 않은 요구사항
• Agile 방식으로 분석 수행
• 개발팀/운영팀 교육 및 실습
• Stage2
• 빅데이터 특성을 고려한 요구사항
• 데이터 분석 기간에 대한 현업의 이해
• Stage1 결과 공유에 따른 현업 관심 증가
43.
추진과정 #2
• Stage3
•엔드 유저용 라이브 서비스 오픈
• 빅데이터를 이용한 서비스 기획 요건 급증
• 개발팀/운영팀 기술 성숙도 증가
44.
1년 협업해서
이제 기본구성
http://si.wsj.net/public/resources/images/OB-UA904_0805bo_G_20120805170407.jpg
http://runtokorea.com/wp-content/uploads/2013/02/1218_boston-marathon-2.jpg
































![Chorus - Distributed Operating System [ case study ]](https://cdn.slidesharecdn.com/ss_thumbnails/chorus-171117082036-181113144303-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[Bespin Global 파트너 세션] 분산 데이터 통합 (Data Lake) 기반의 데이터 분석 환경 구축 사례 - 베스핀 글로벌 장익...](https://cdn.slidesharecdn.com/ss_thumbnails/session5-datalakebaseddataanalyticsenvironmentimplementationcaseexamplebespinglobal-190903082707-thumbnail.jpg?width=640&height=640&fit=bounds)
![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)



















