Downloaded 15 times







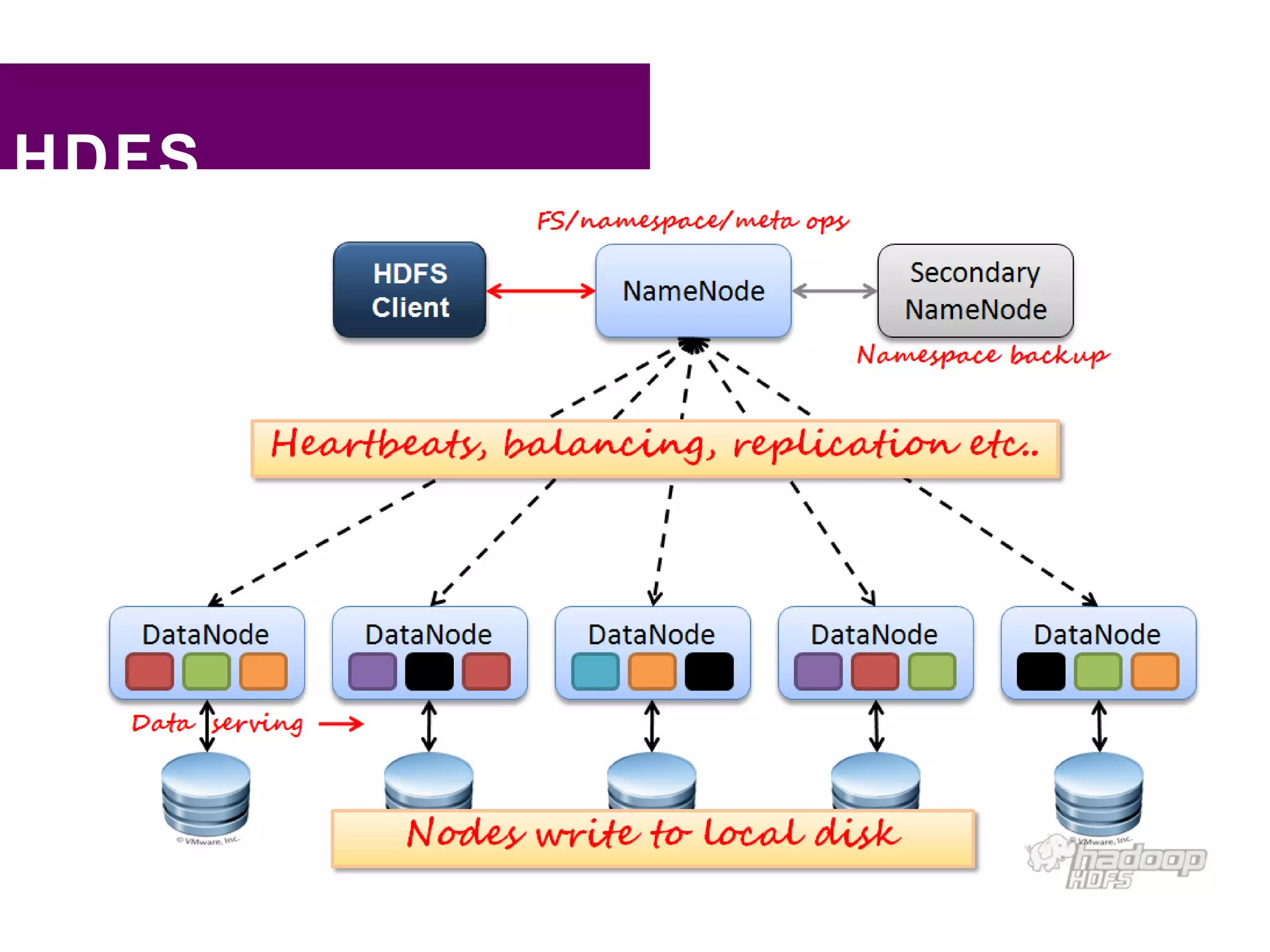
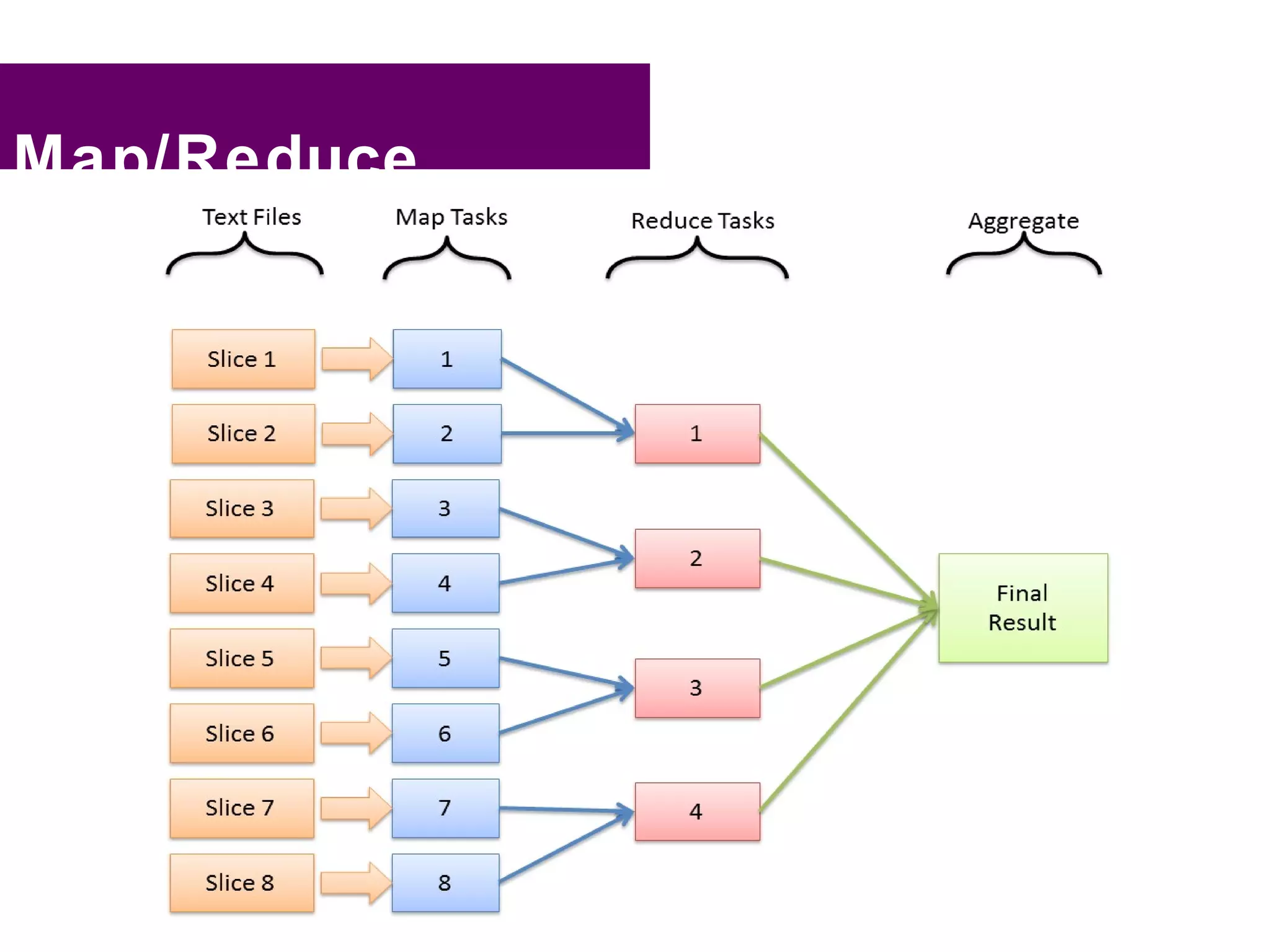






This document provides an overview of big data, Hadoop, and related concepts: - Big data refers to large datasets that cannot be processed efficiently by traditional systems due to their size. Sources include social media, smartphones, machines, and log files. - Hadoop is an open-source framework for distributed storage and processing of large datasets across clusters of commodity hardware. It implements the MapReduce programming model. - Key Hadoop components include HDFS for storage, MapReduce for distributed processing, and related projects like Pig, Hive, HBase, Flume, Oozie, and Sqoop. Companies use Hadoop for applications involving large datasets, such as log analysis, recommendations, and business intelligence




























































