







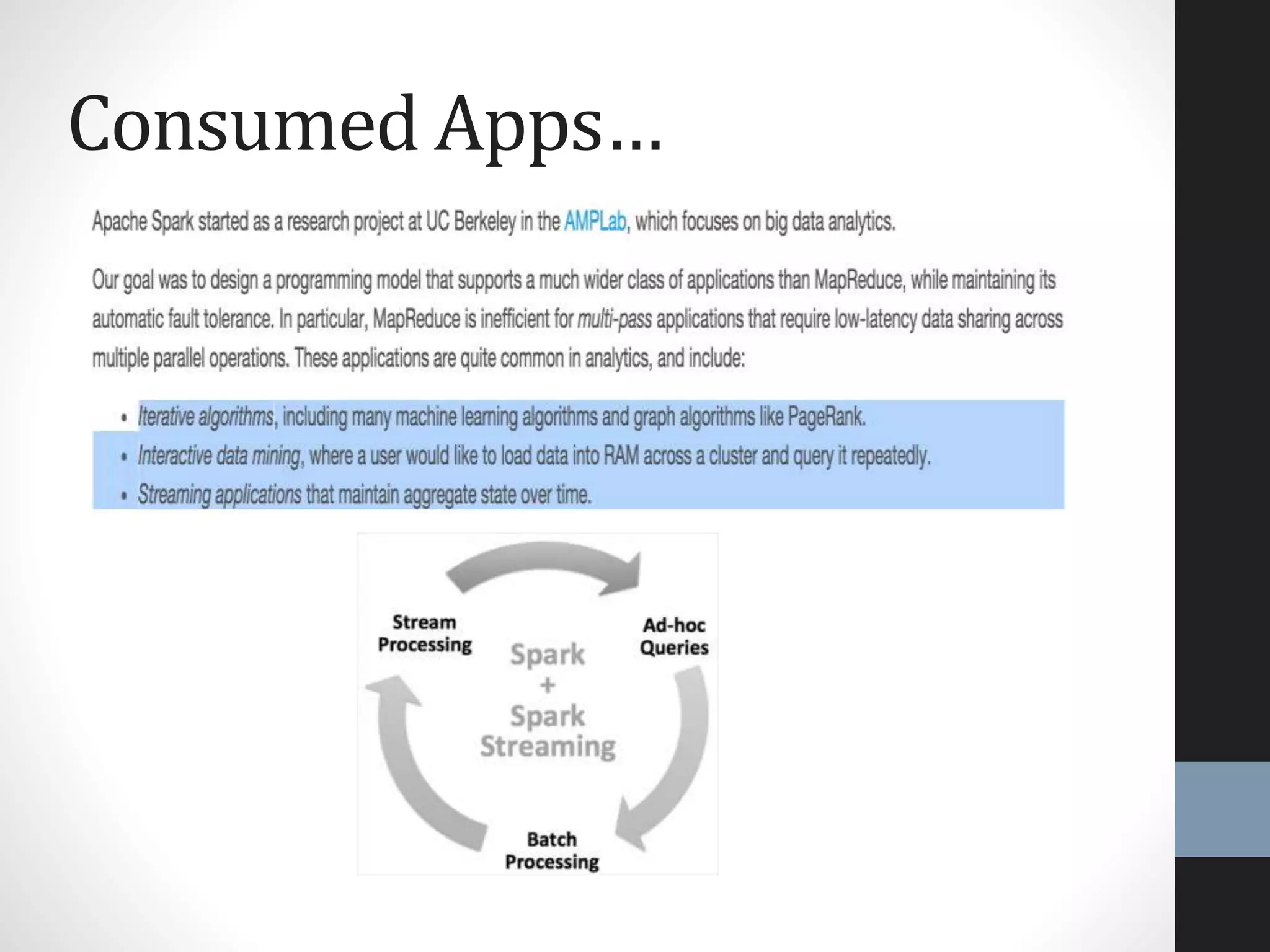

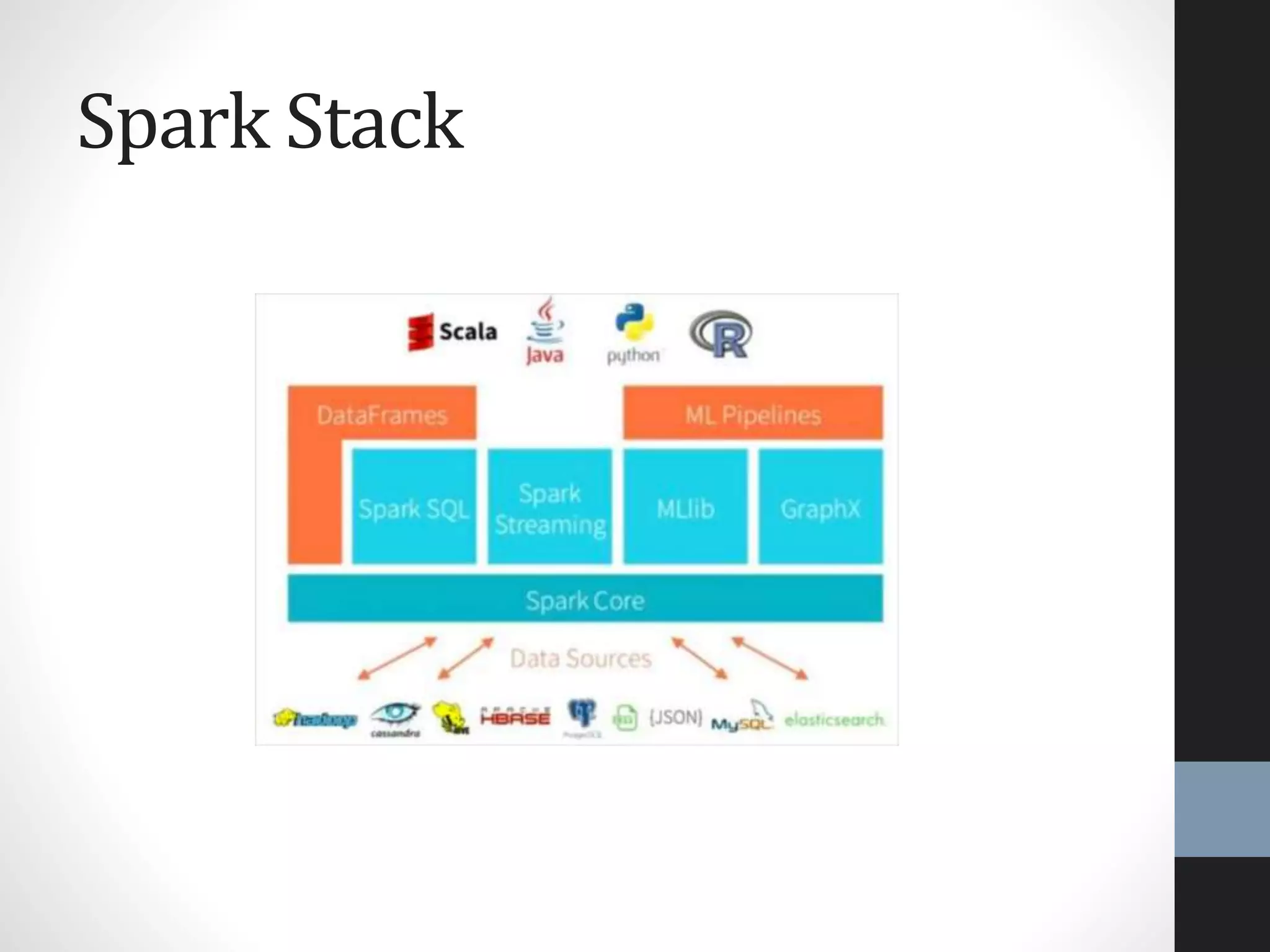
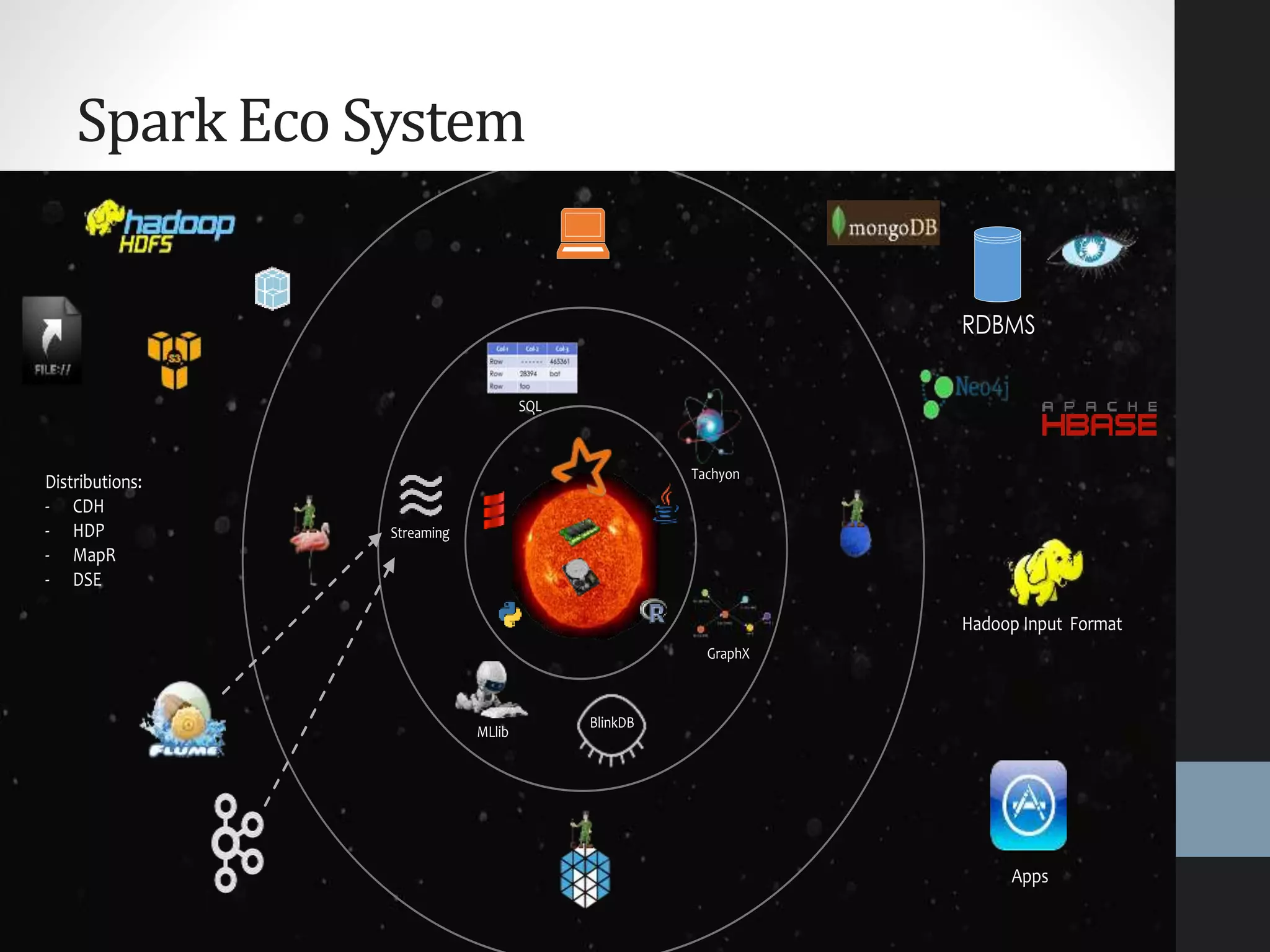
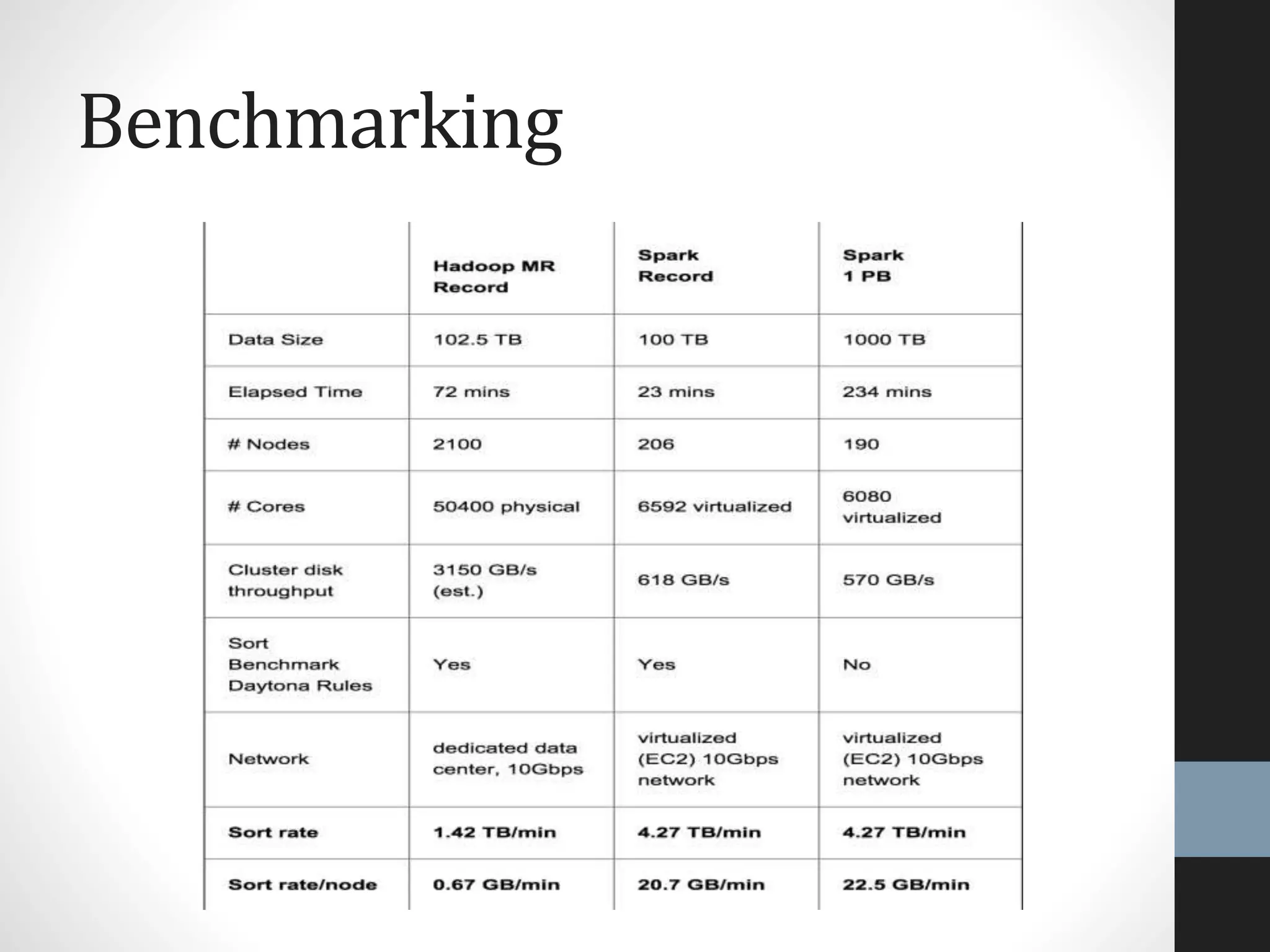

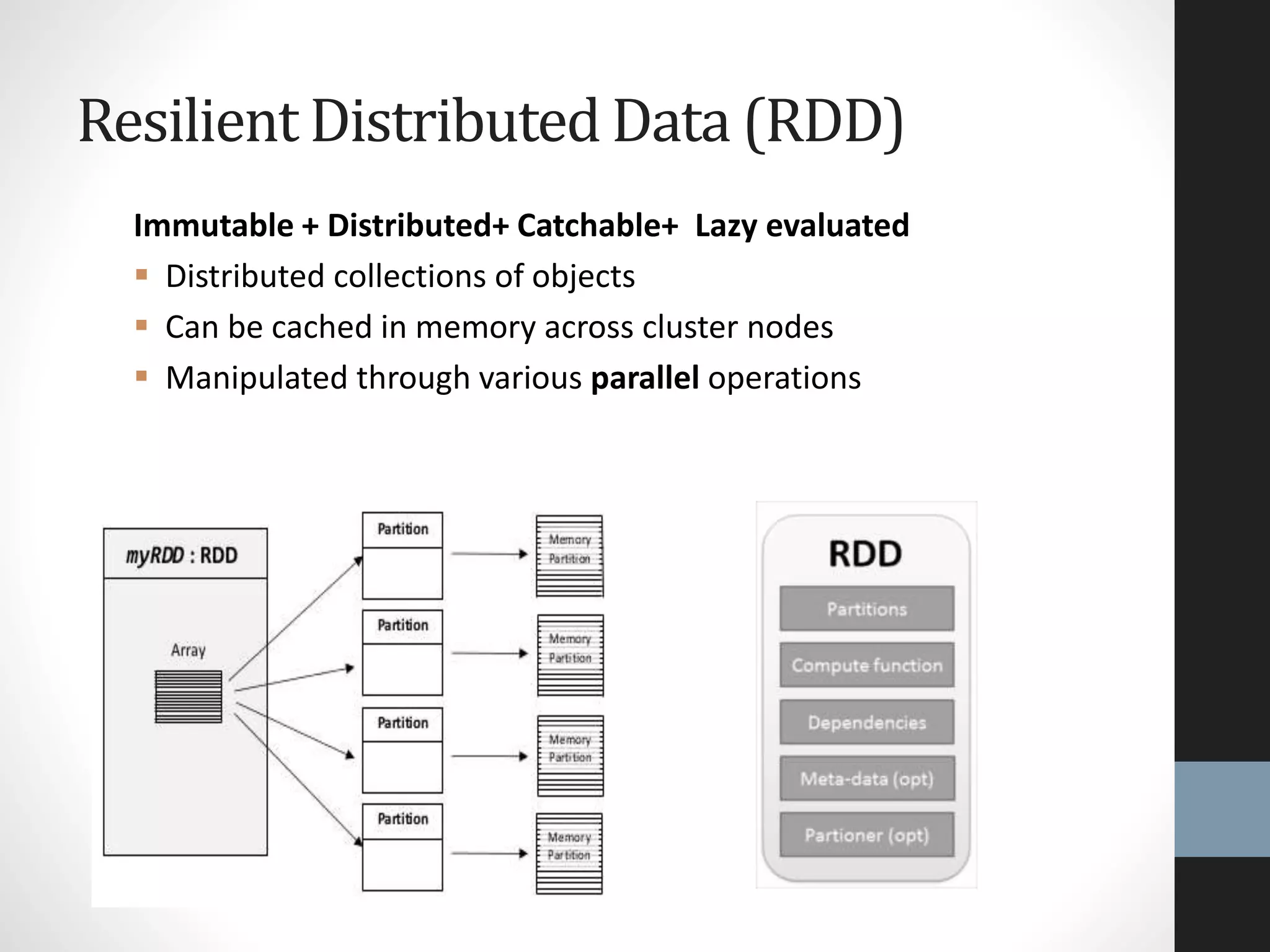
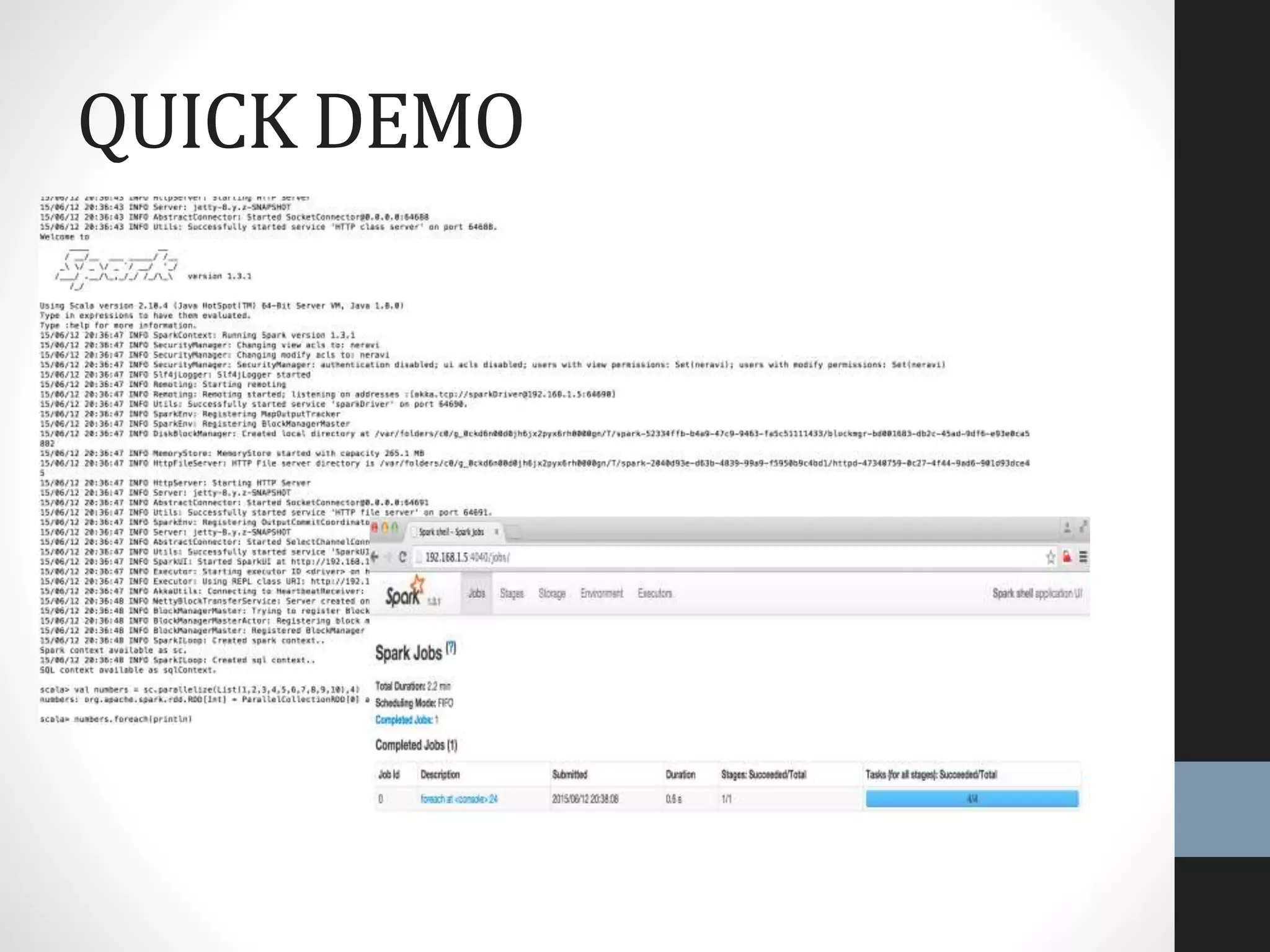
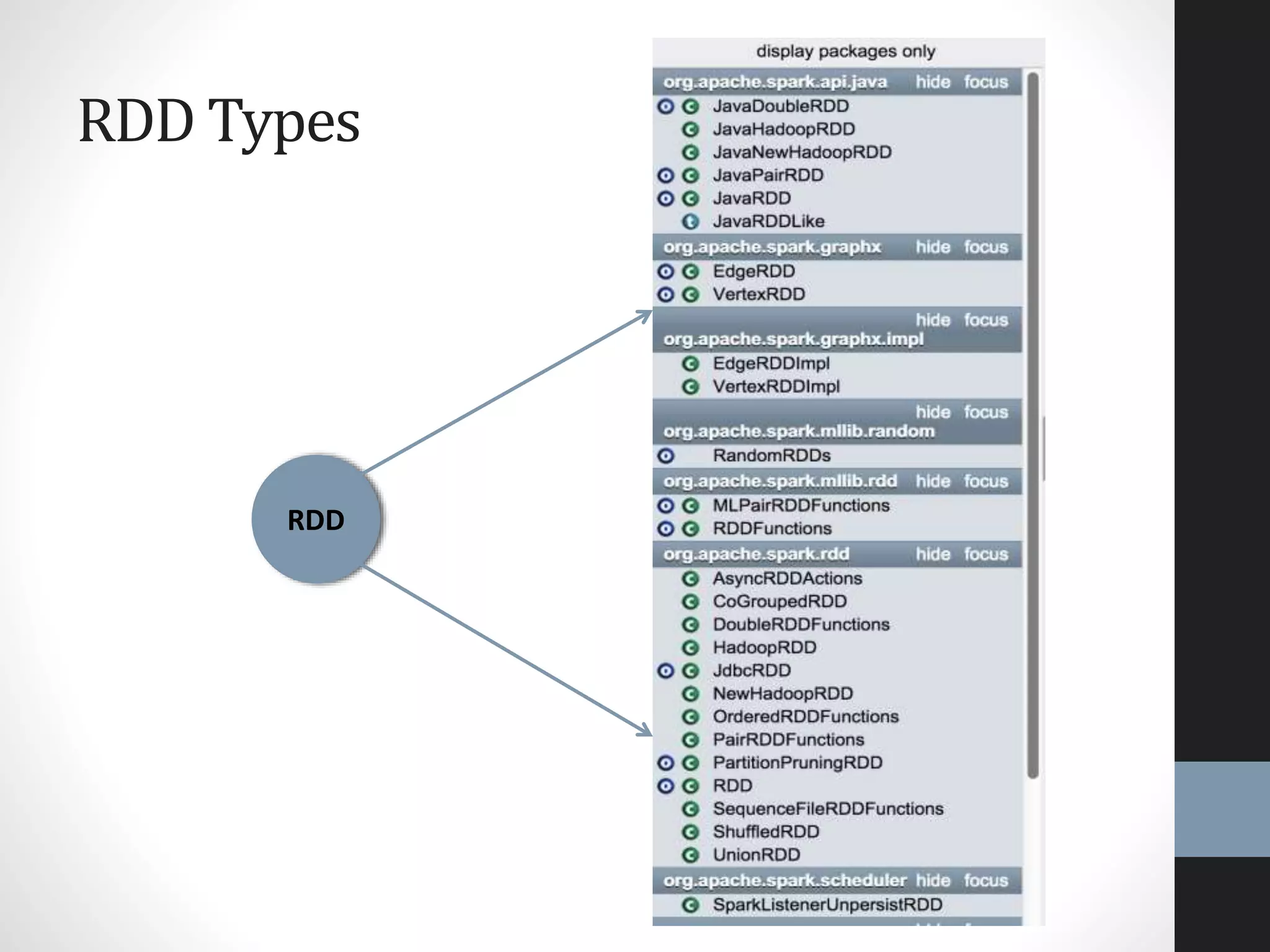
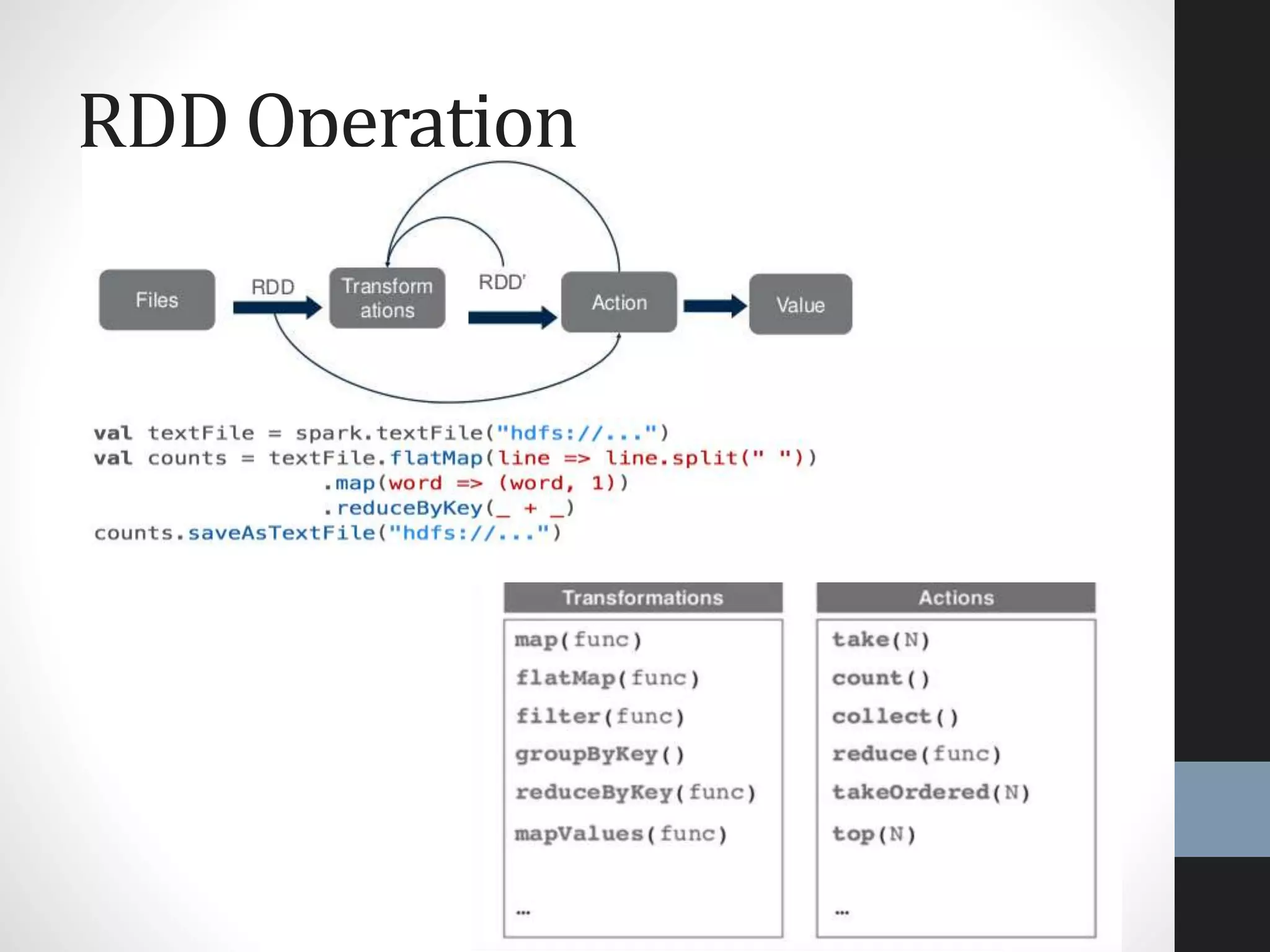

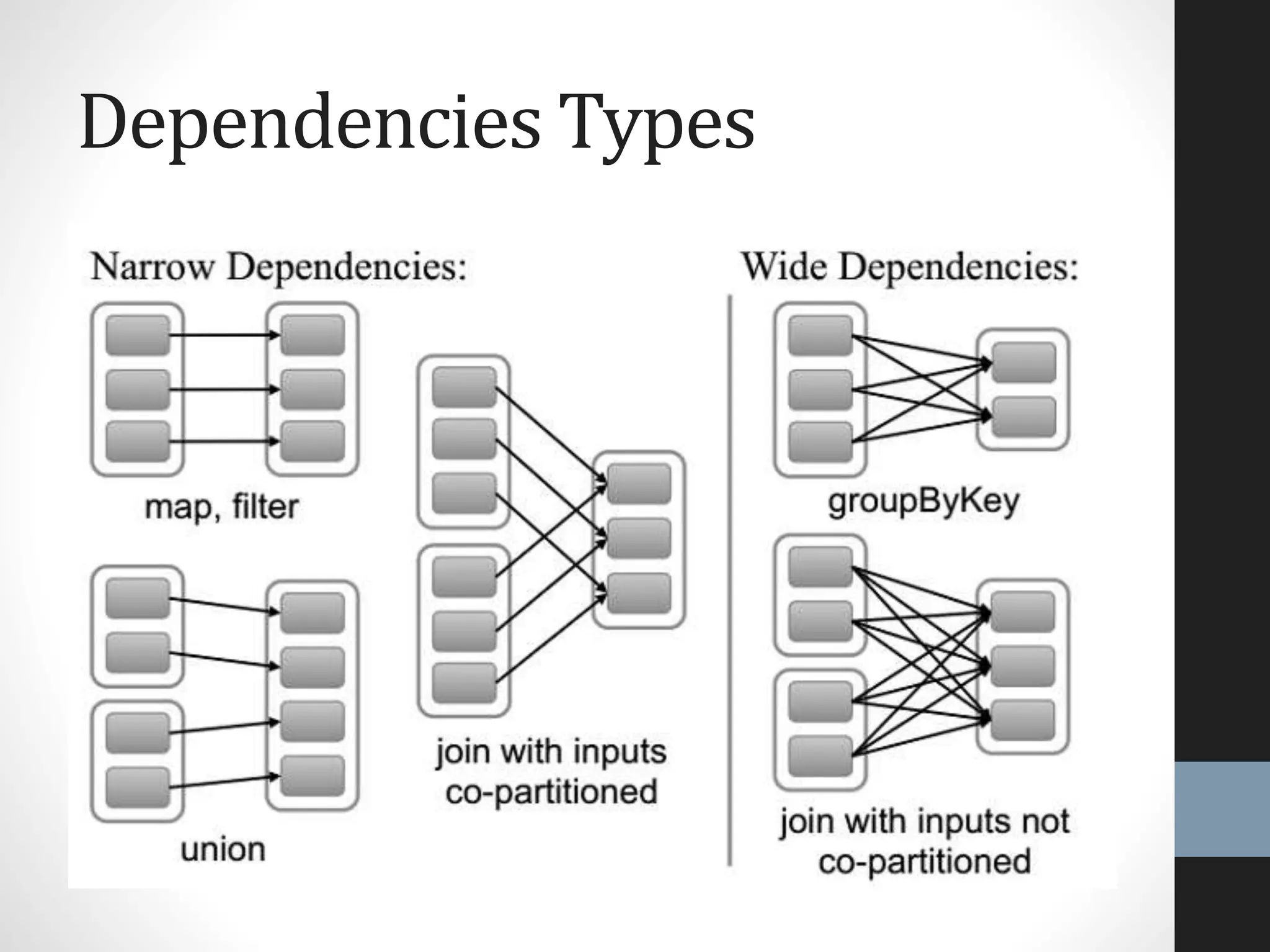



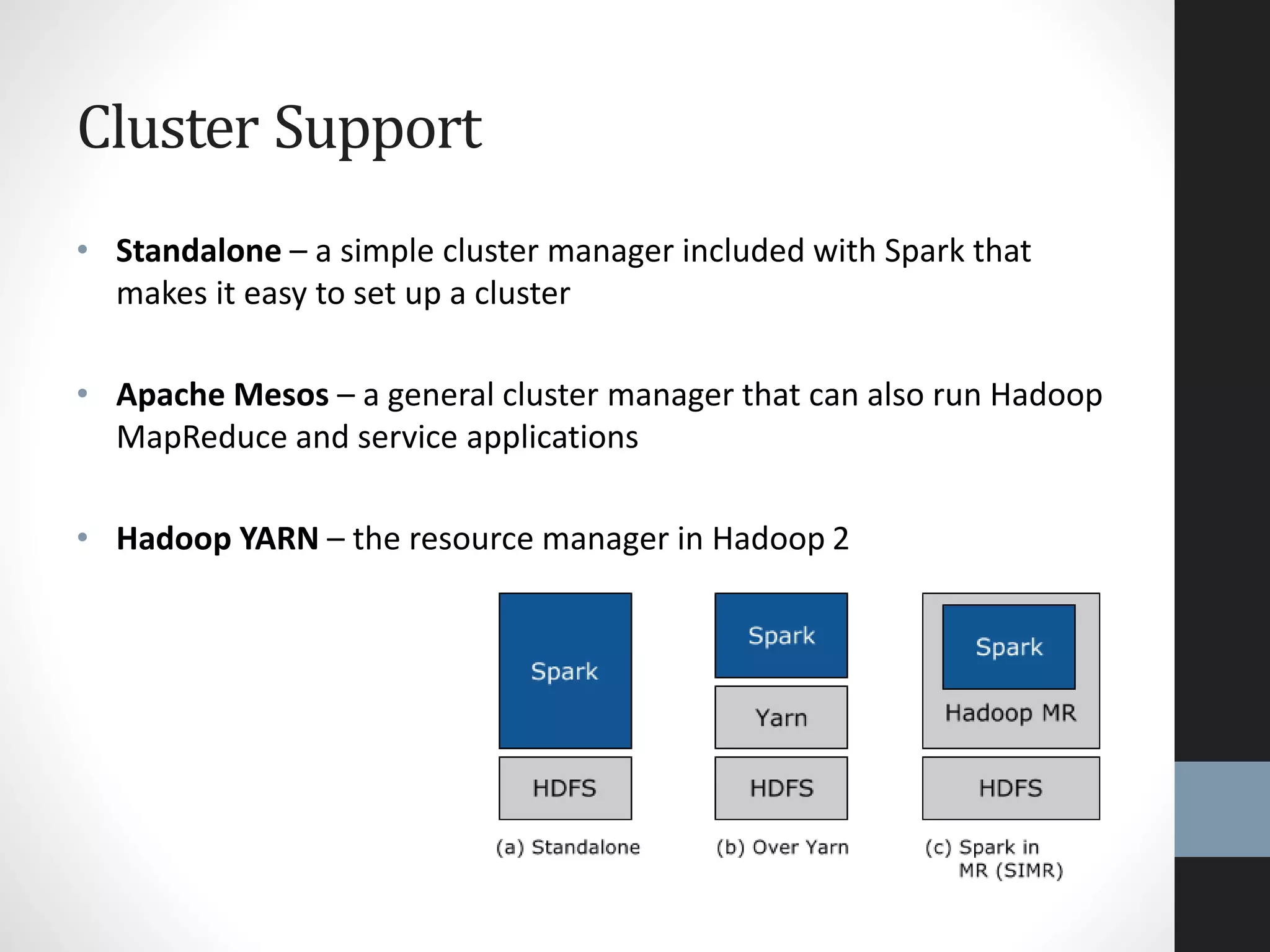
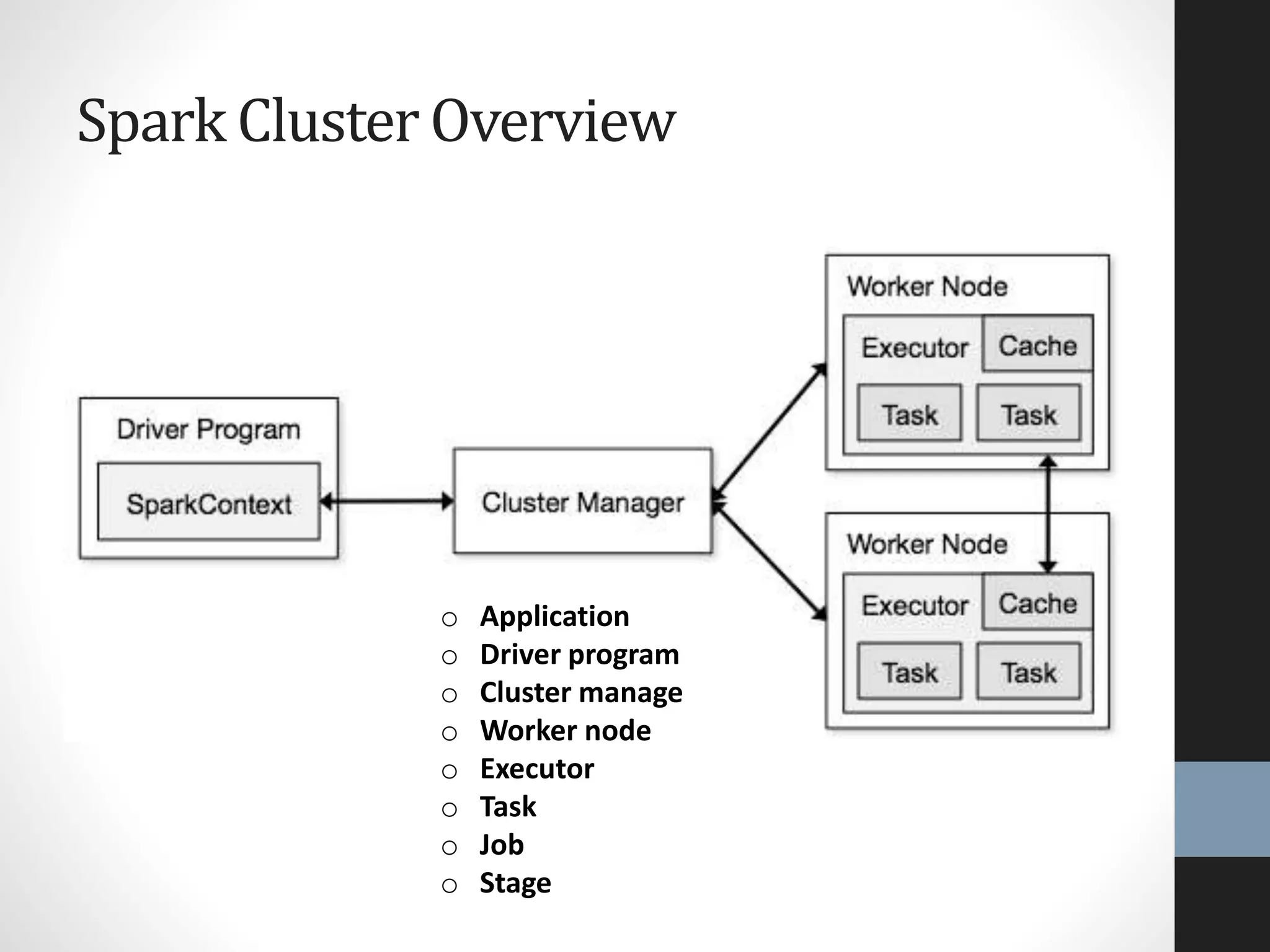
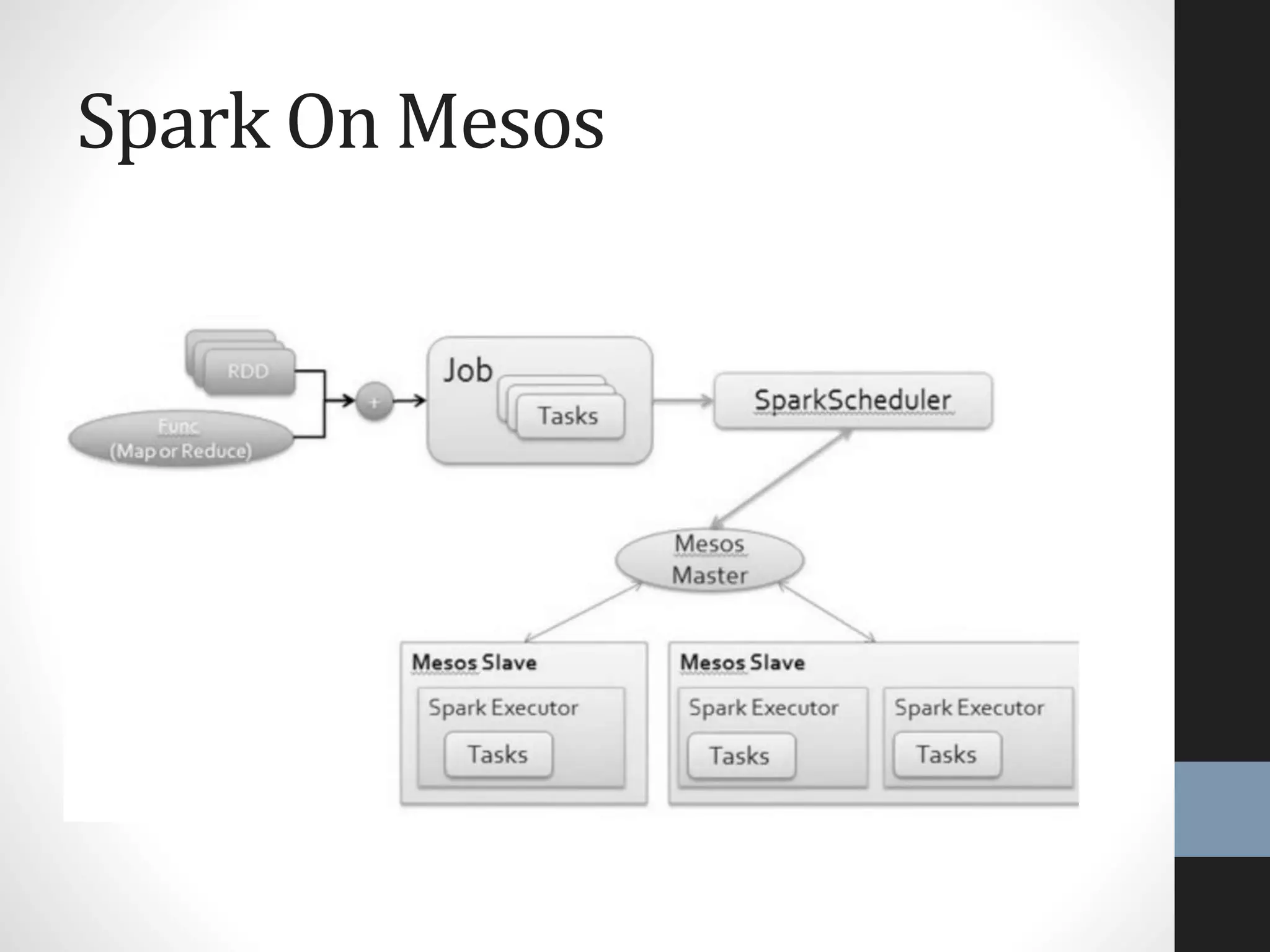
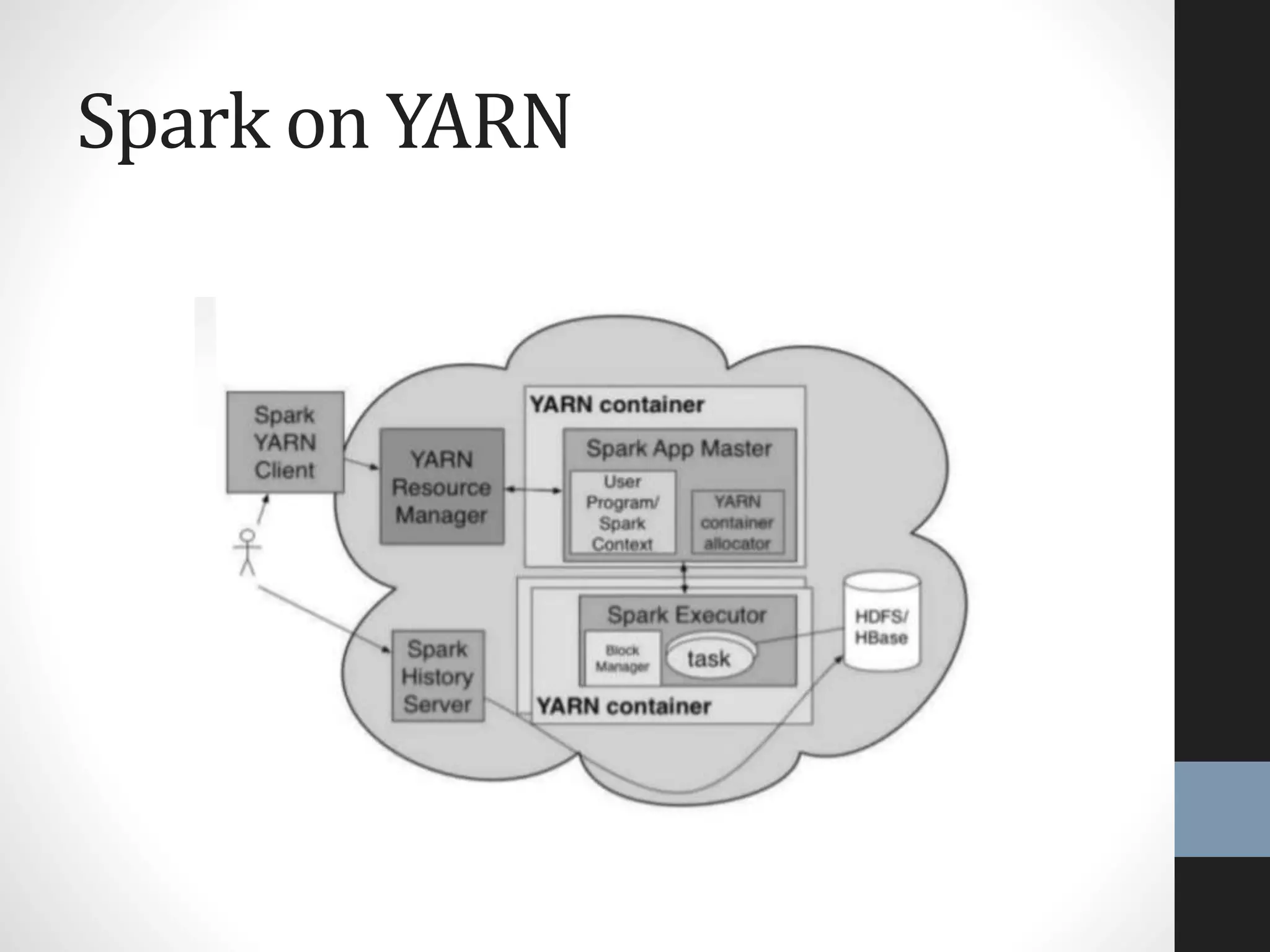
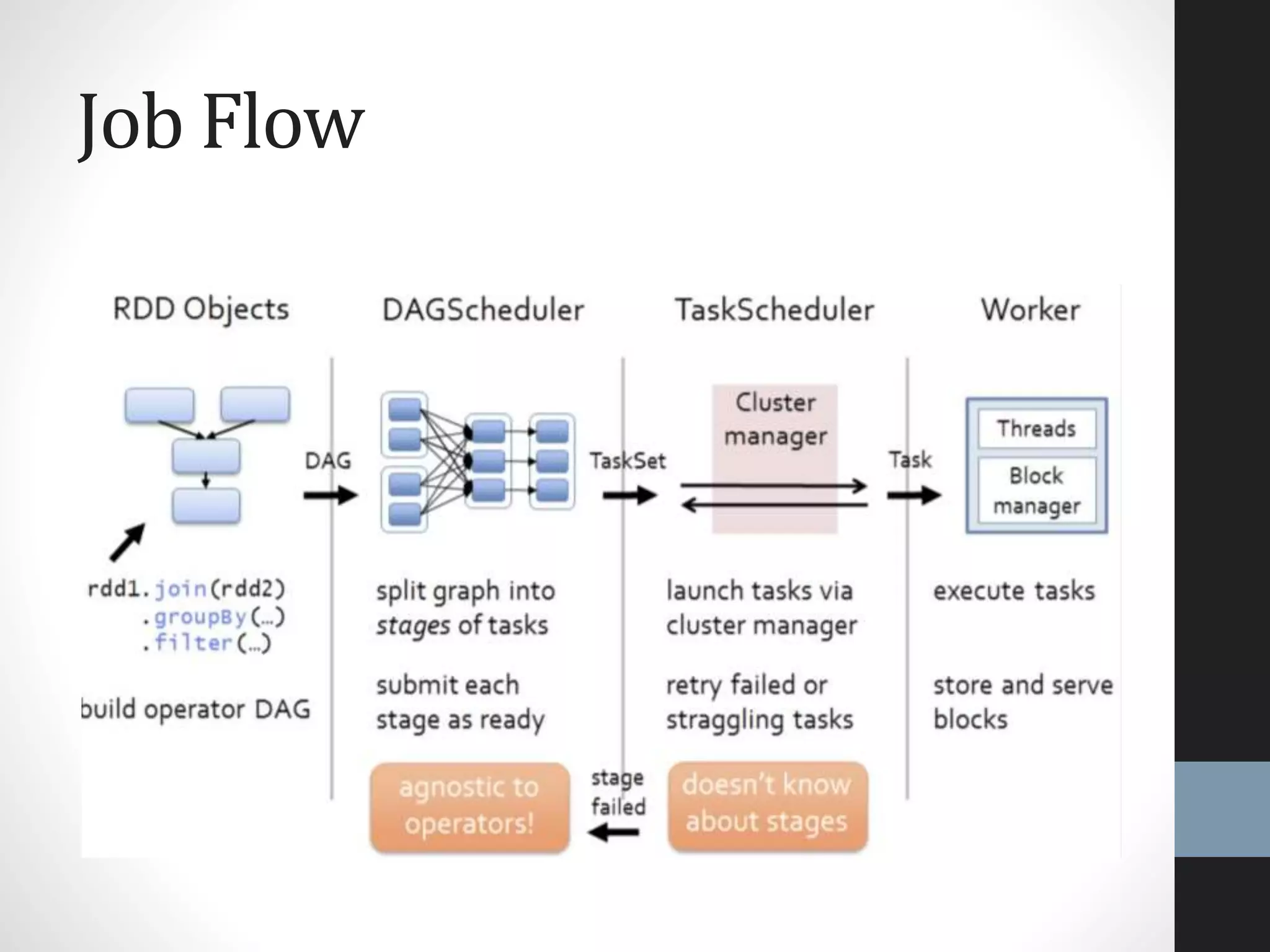




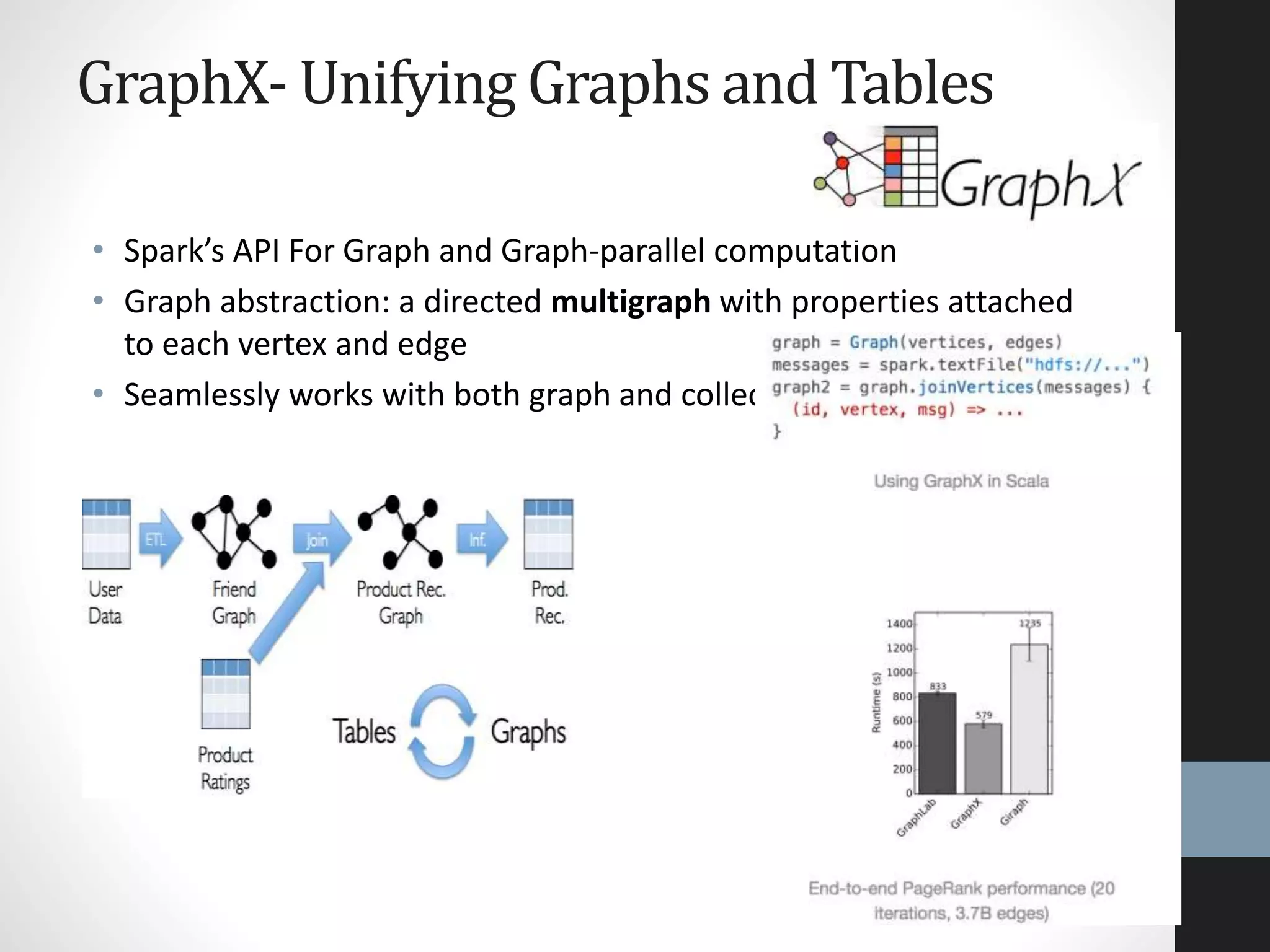

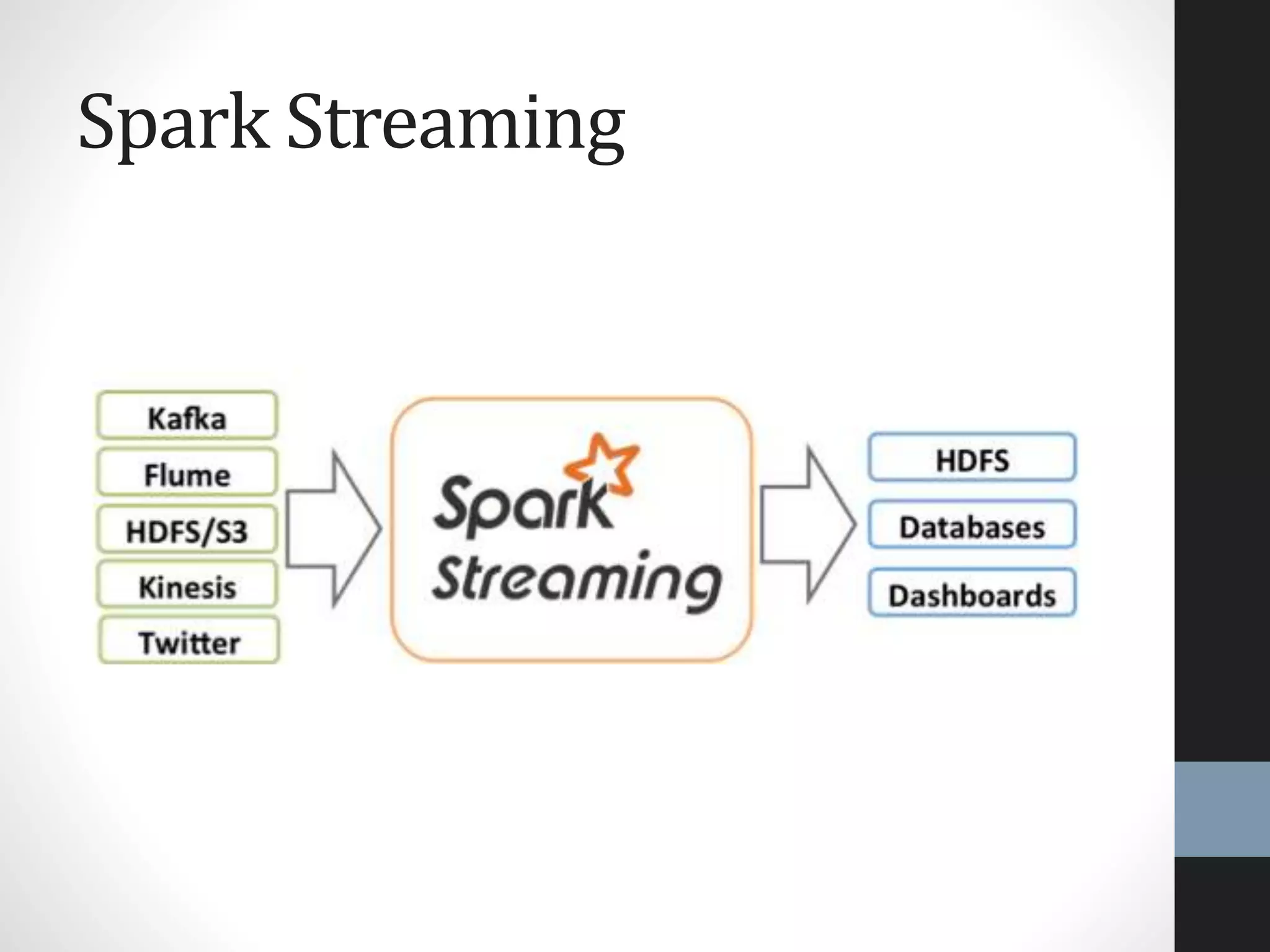



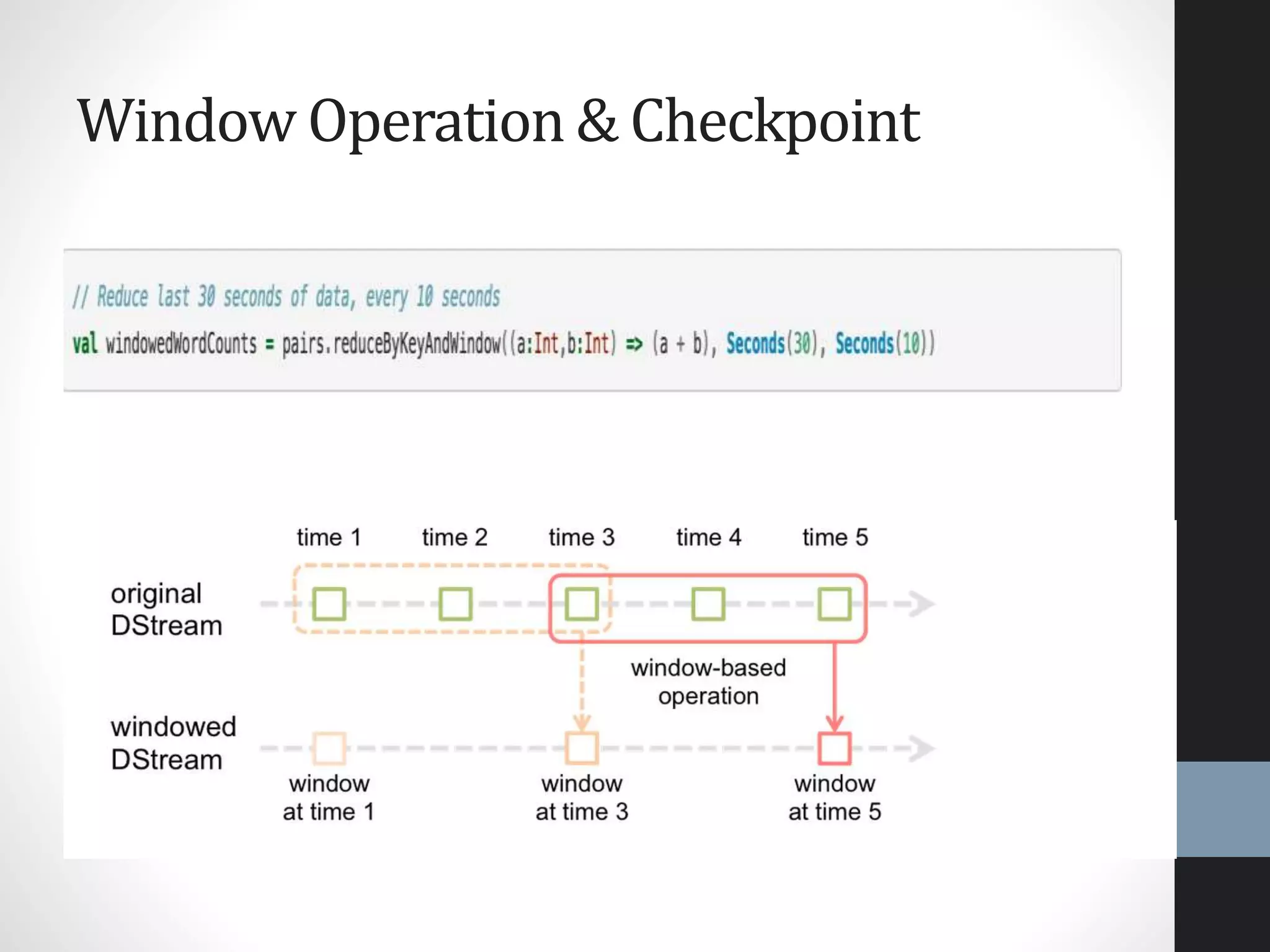
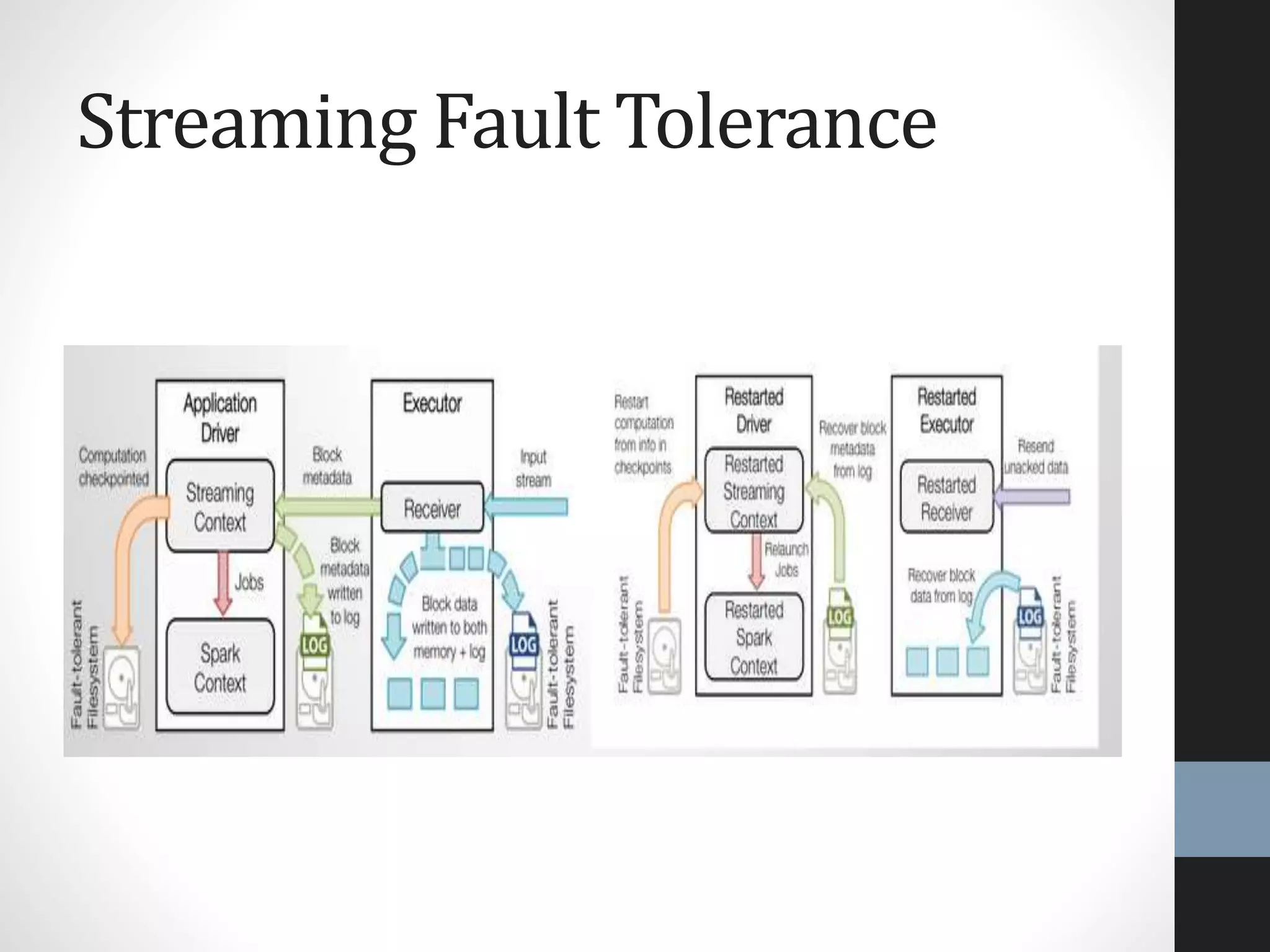

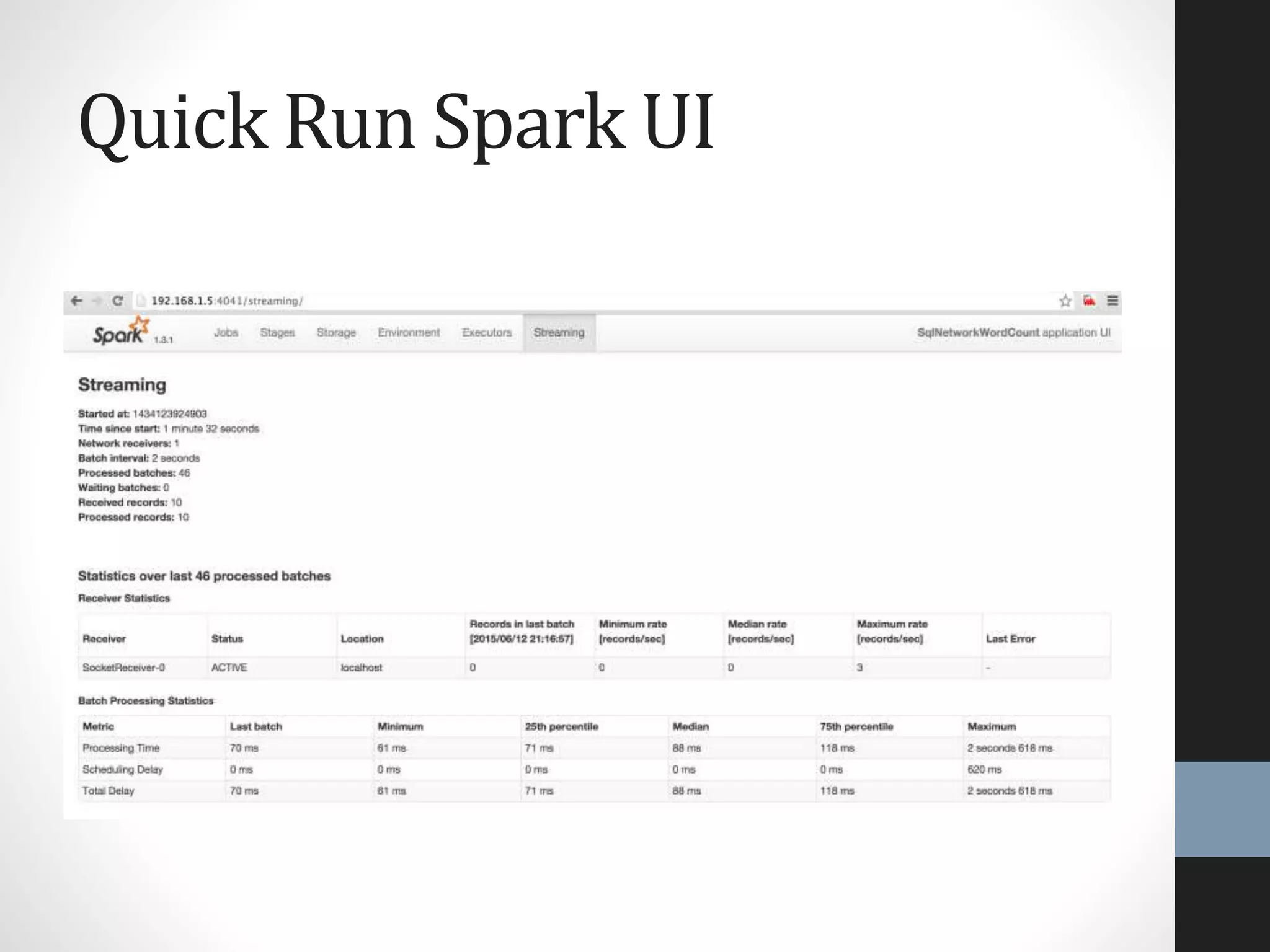








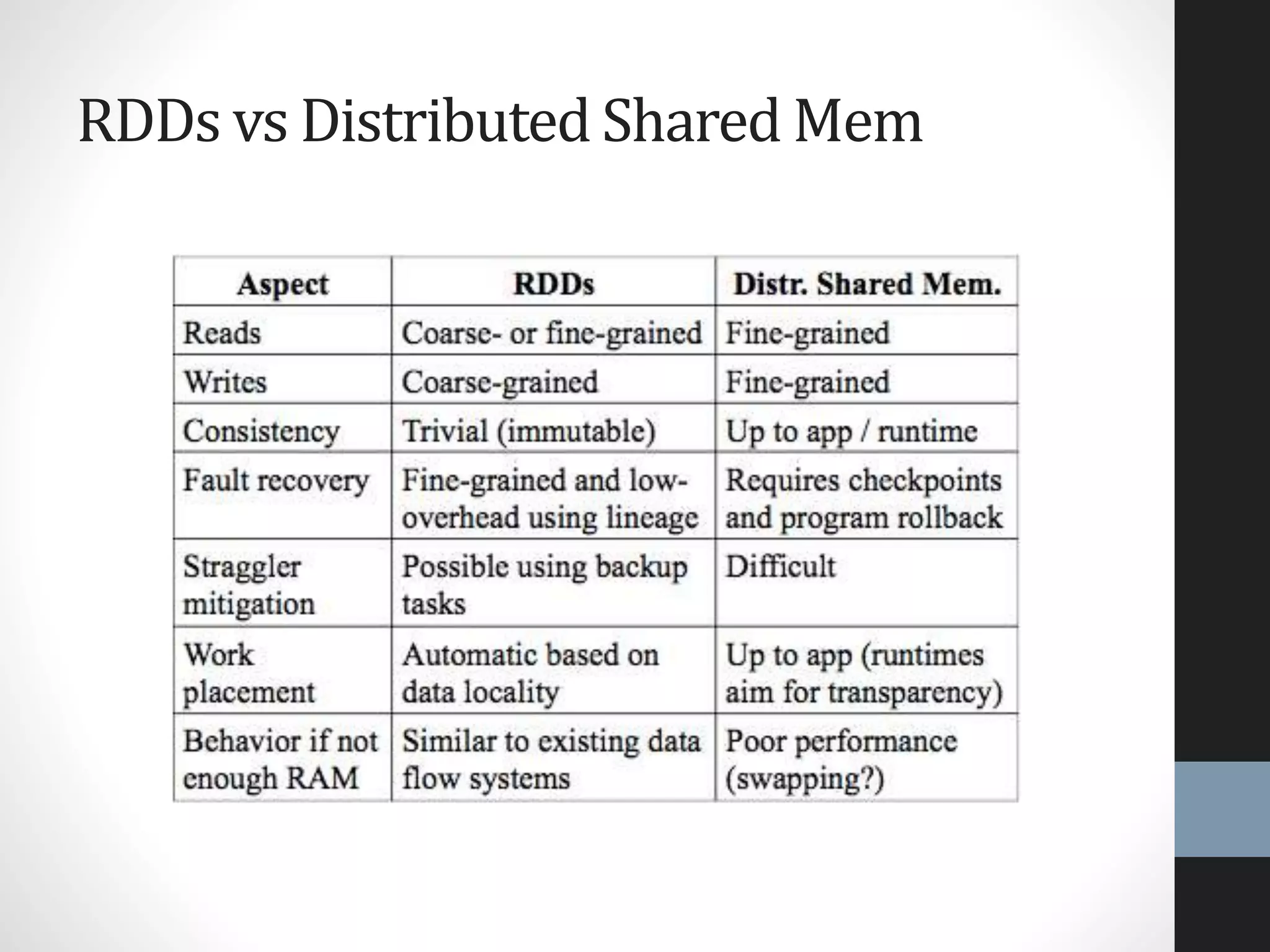
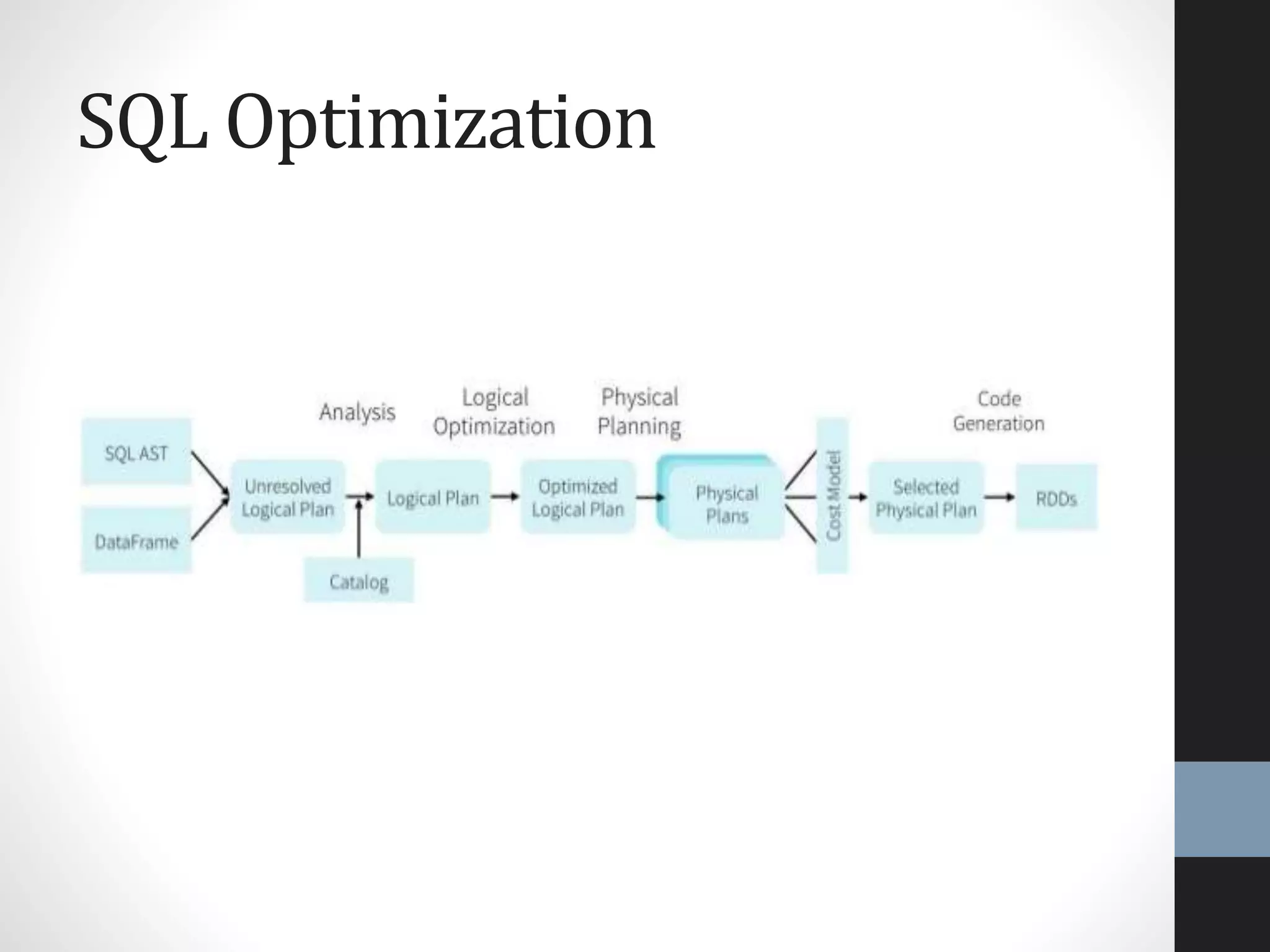

The document outlines an agenda for a presentation on big data, focusing on Spark and its features, including RDDs and fault tolerance. It discusses the challenges of existing data processing frameworks and how Spark improves efficiency over Hadoop with capabilities for both batch and streaming data. Additionally, it introduces key components of the Spark stack, machine learning libraries, and the Berkeley Data Analytics Stack for managing big data.

































































































