Download as PDF, PPTX







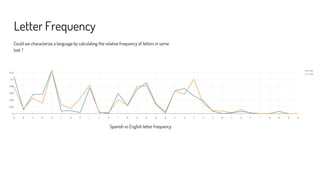









The document serves as a practical introduction to language classification using Apache Spark and Spark Notebook, detailing techniques such as letter frequency and n-grams for language identification. It includes references to sample notebooks and datasets used for training classifiers, along with the implementation of Spark ML transformers. The author, Gerard Maas, presents his experience with Spark and provides links to resources for further exploration.



































































