Nested Documents in Lucene provides a solution for representing complex nested data structures in Lucene by allowing multiple "nested" documents to represent related items. It introduces a new NestedDocumentQuery class that understands document relationships and can execute child searches using arbitrary Lucene queries. This allows for efficient joins between parent and child documents when querying nested data.
Nested Documents inLuceneHigh-performance support for parent/child document relationsmark@searcharea.co.uk
2.
Problem:The Lucene datamodel is based on Documents, Fields and Terms. However many real-world data structures cannot be properly represented when collapsed into a single Lucene document.SingleLucenedocument
3.
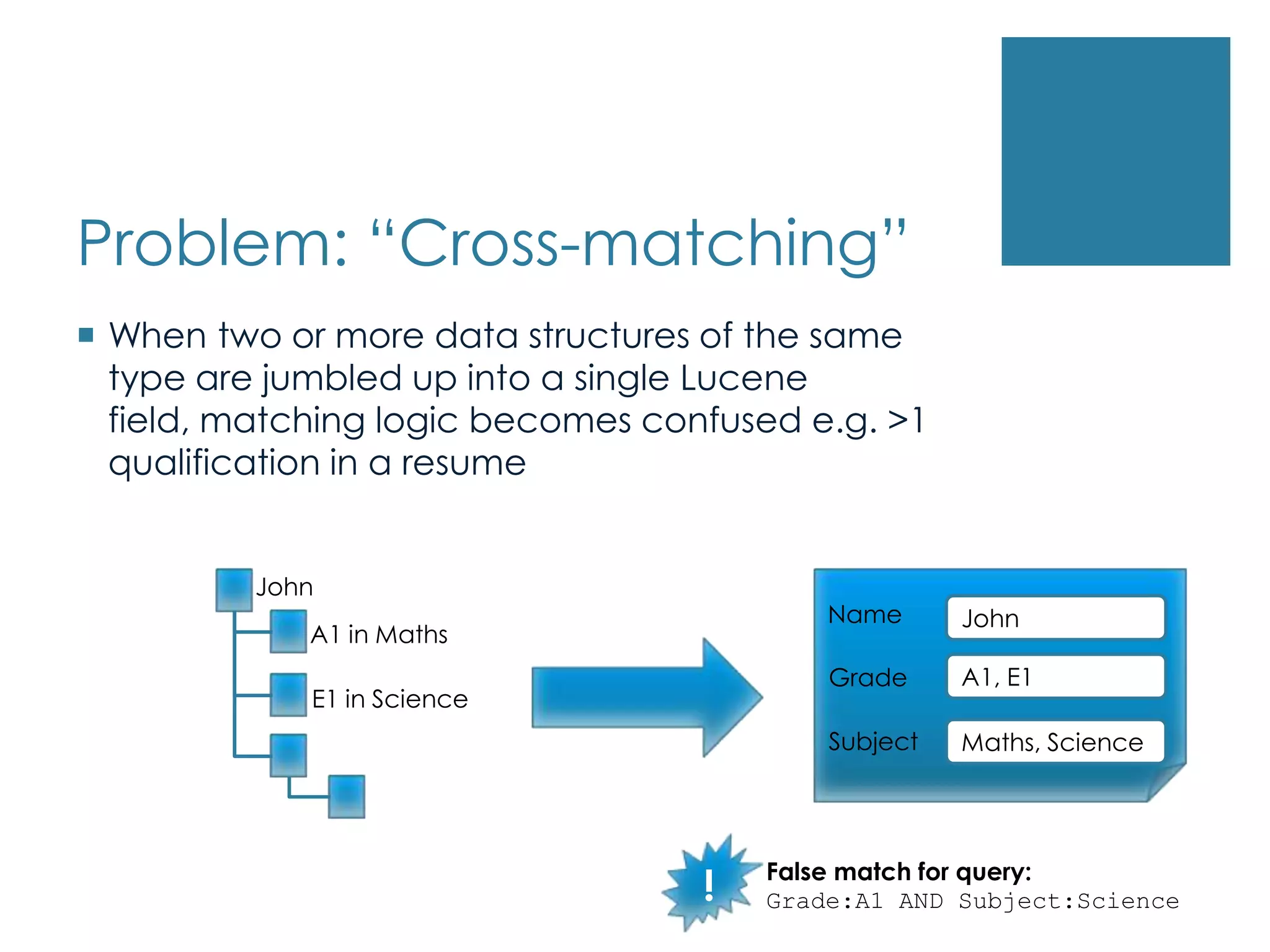
Problem: “Cross-matching”When twoor more data structures of the same type are jumbled up into a single Lucene field, matching logic becomes confused e.g. >1 qualification in a resumeJohnNameJohnA1 in MathsA1, E1GradeE1 in ScienceSubjectMaths, Science!False match for query:Grade:A1 AND Subject:Science
4.
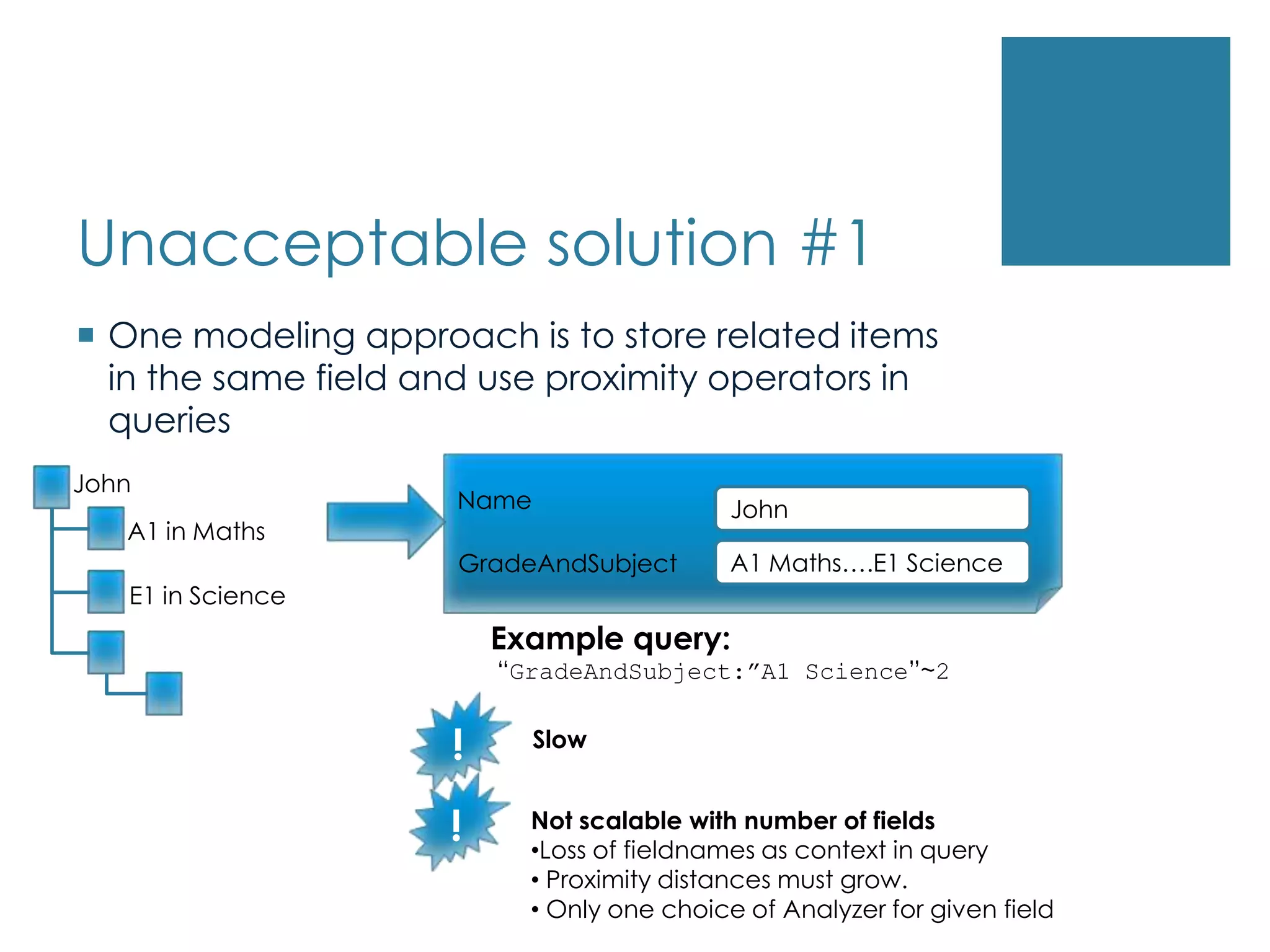
Unacceptable solution #1Onemodeling approach is to store related items in the same field and use proximity operators in queriesNameJohnA1 Maths….E1 ScienceGradeAndSubjectJohnExample query: “GradeAndSubject:”A1 Science”~2A1 in MathsE1 in Science!Slow!Not scalable with number of fields Loss of fieldnames as context in query
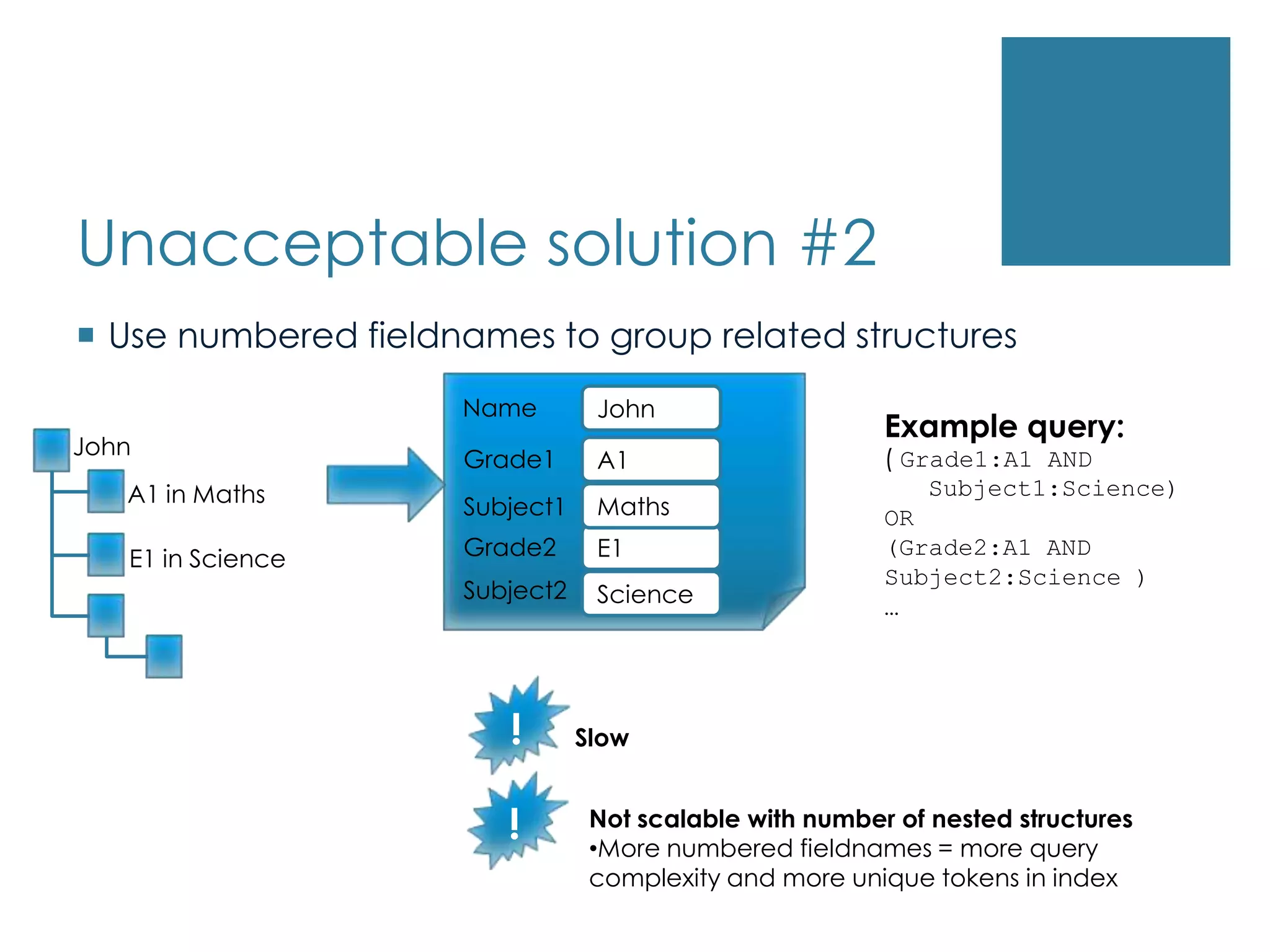
Only onechoice of Analyzer for given field Unacceptable solution #2Use numbered fieldnames to group related structuresNameJohnExample query:( Grade1:A1 AND Subject1:Science) OR (Grade2:A1 AND Subject2:Science )…A1Grade1MathsSubject1E1Grade2JohnSubject2ScienceA1 in MathsE1 in Science!Slow!Not scalable with number of nested structuresMore numbered fieldnames = more query complexity and more unique tokens in indexSolution: Nested documentsThe existing Lucene codebase can be used to simply store multiple “nested” documents to represent arbitrarily complex structures. Related documents are just added in sequenceJohnNameJohnA1 in MathsA1E1GradeGradeE1 in ScienceSubjectMathsSubjectScience?But how to query?....
7.
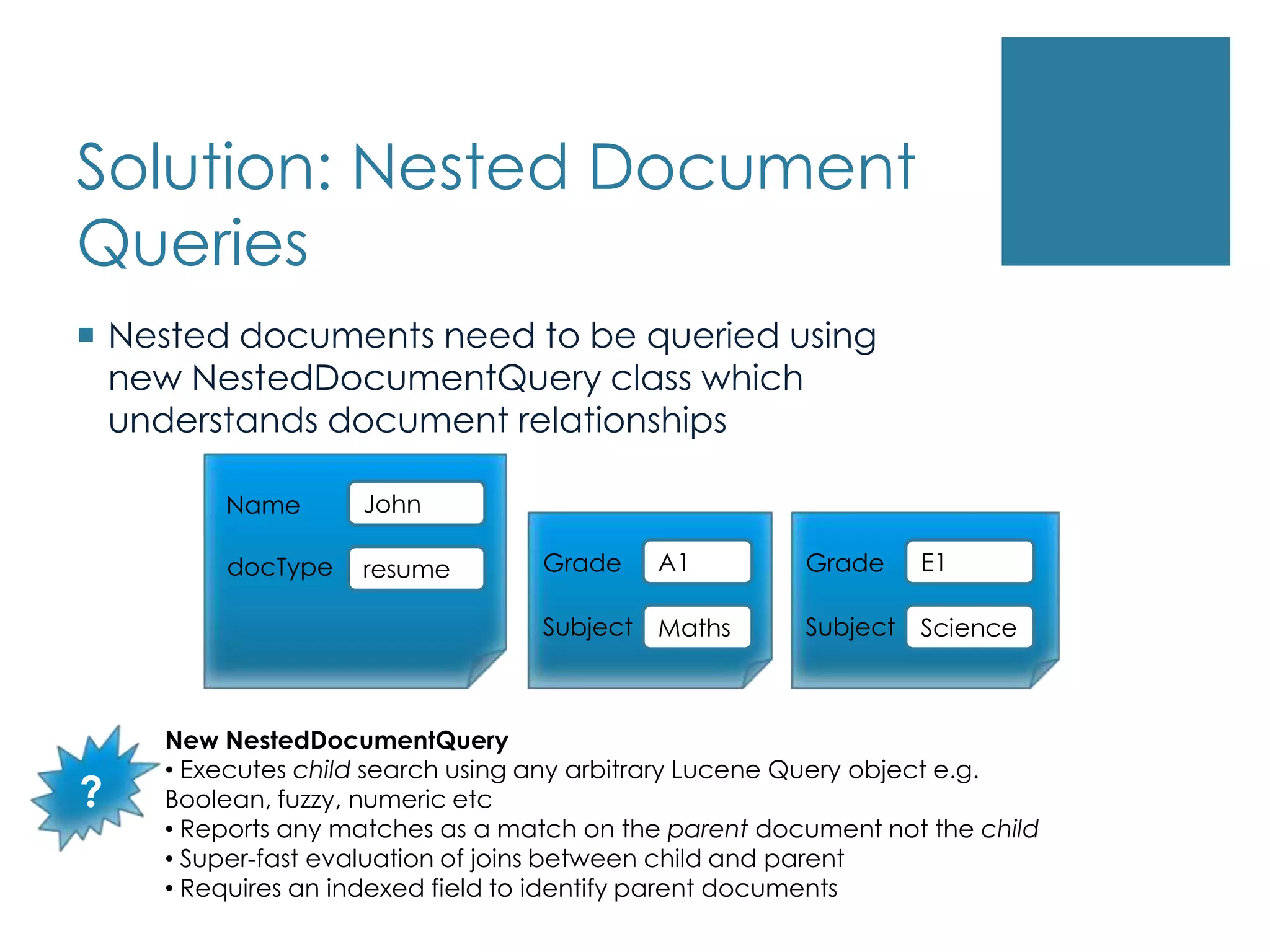
Solution: Nested DocumentQueriesNested documents need to be queried using new NestedDocumentQuery class which understands document relationshipsJohnNameA1E1GradeGradedocTyperesumeSubjectMathsSubjectScienceNew NestedDocumentQuery Executes child search using any arbitrary Lucene Query object e.g. Boolean, fuzzy, numeric etc
8.
Reports anymatches as a match on the parent document not the child
Requires anindexed field to identify parent documents?
11.
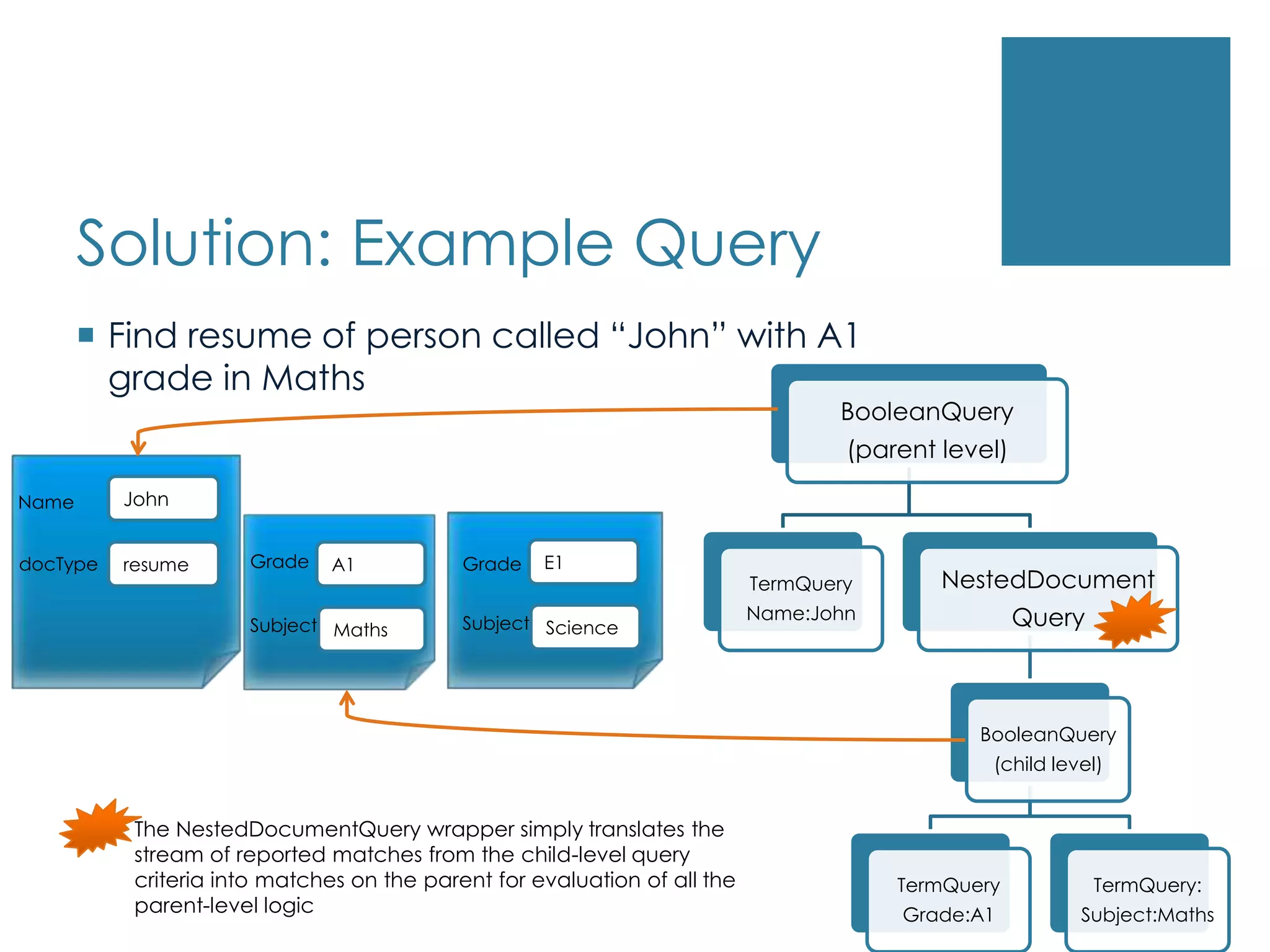
Solution: Example QueryFindresume of person called “John” with A1 grade in MathsJohnNameE1A1resumeGradedocTypeGradeSubjectScienceSubjectMathsThe NestedDocumentQuery wrapper simply translates the stream of reported matches from the child-level query criteria into matches on the parent for evaluation of all the parent-level logic
12.
Solution: Join speedUnlikea database, the cost of a join (child to parent) is blisteringly fast3) Find first prior set bit e.g. position #356,6701000001000000001000000010000000100000010000100000000010000001000001000012) Index directly into cached BitSet at position #356,6751) Match reported on document #356,675ParentQuery4) Attribute match to doc #356,670NestedDocumentQueryChildQueryThe BitSet for defining parents is obtained from a Filter and can be cached aggressively with minimal memory cost (one bit per document in the index)
13.
Other advantagesParent-child documentrelationships can also be used to limit child results from any one parent (e.g. efficiently control the max number of pages returned from any one website)Nesting levels can be arbitrarily deep Very powerful multi-child queries possible e.g. find people likely to know person X using resume’s employment histories (multiple employer names/urls and related date-ranges)
14.
“Lucene is nota database”, but…..Structure mattersMany data sources are a mix of structured and unstructured content (e.g. microformats). This is unlikely to change. Lucene has historically been about unstructured text but has steadily been adding structured capability (Trie, spatial, facets) and become a great solution for hybrid data. However support for modeling and querying non-trivial data structures is missing currently.Relationships matterThis proposal is not to recreate the full capabilities of a SQL database with arbitrary relationships. However we can benefit greatly from providing simple parent-child relationshipsWe have some unique capabilitiesParent-child joins are very fastUnlike SQL we can return partial, relevance-ranked matchesProbably more akin to XML databases than SQL databases
15.
Next stepsExisting code/unittests can be released to Lucene project if there is sufficient interest. This software has been deployed in production on large datasets.The matching approach is reliant on parents and children being held in the same Lucene index segment. Additional control is needed to enforce this more rigorously - either by Adding more user-control over IndexWritersegment creation where applications understand/control parent-child dependencies ORMaking Lucene aware of parent-child relationships e.g. new method Document.add(Document) Query parser supportXML Query Parser support is availableEnd-user Query parser could add new syntax e.g. +candidateLocale:UK +child(grade:A1 AND subject:music)













![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)











































































