Downloaded 291 times





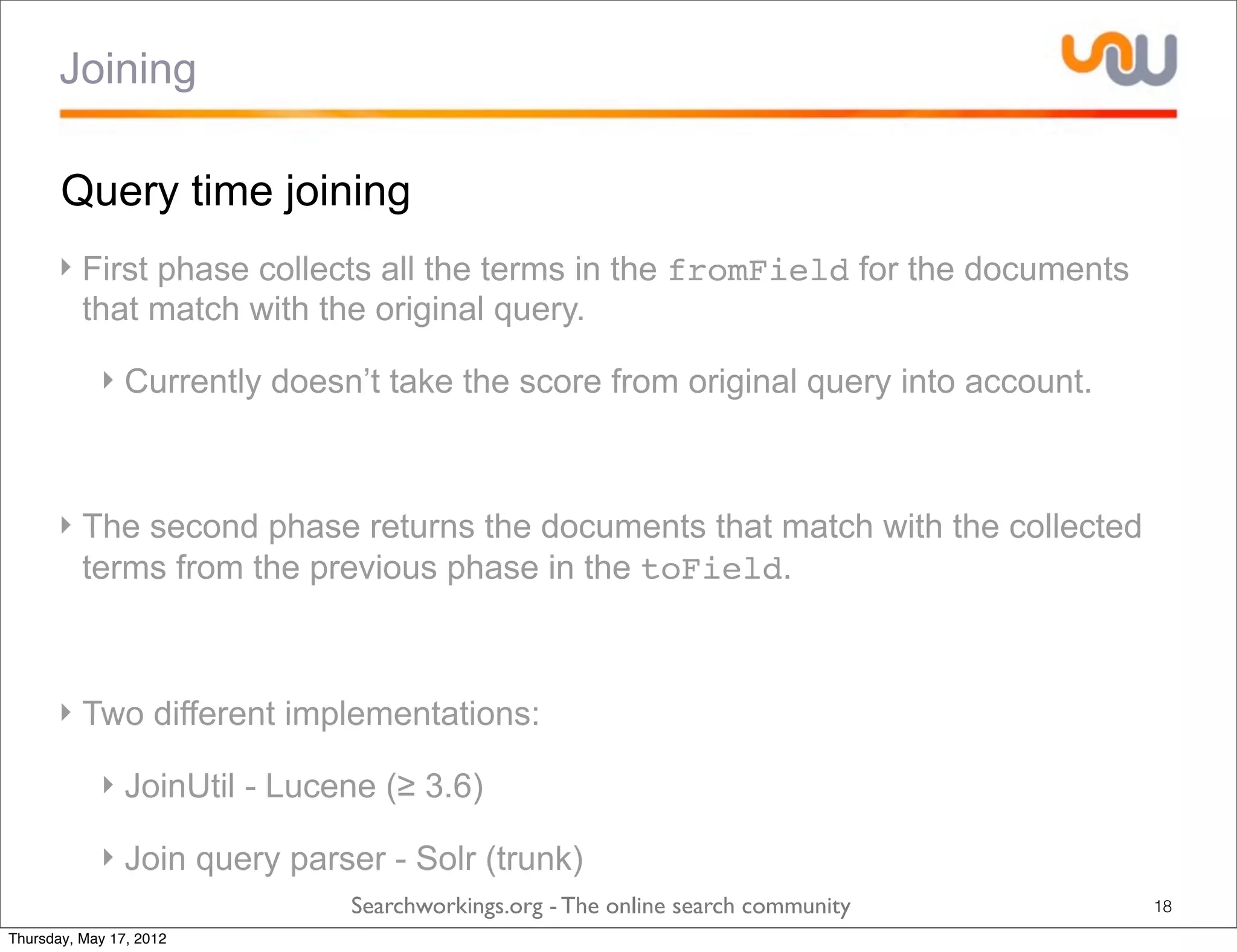
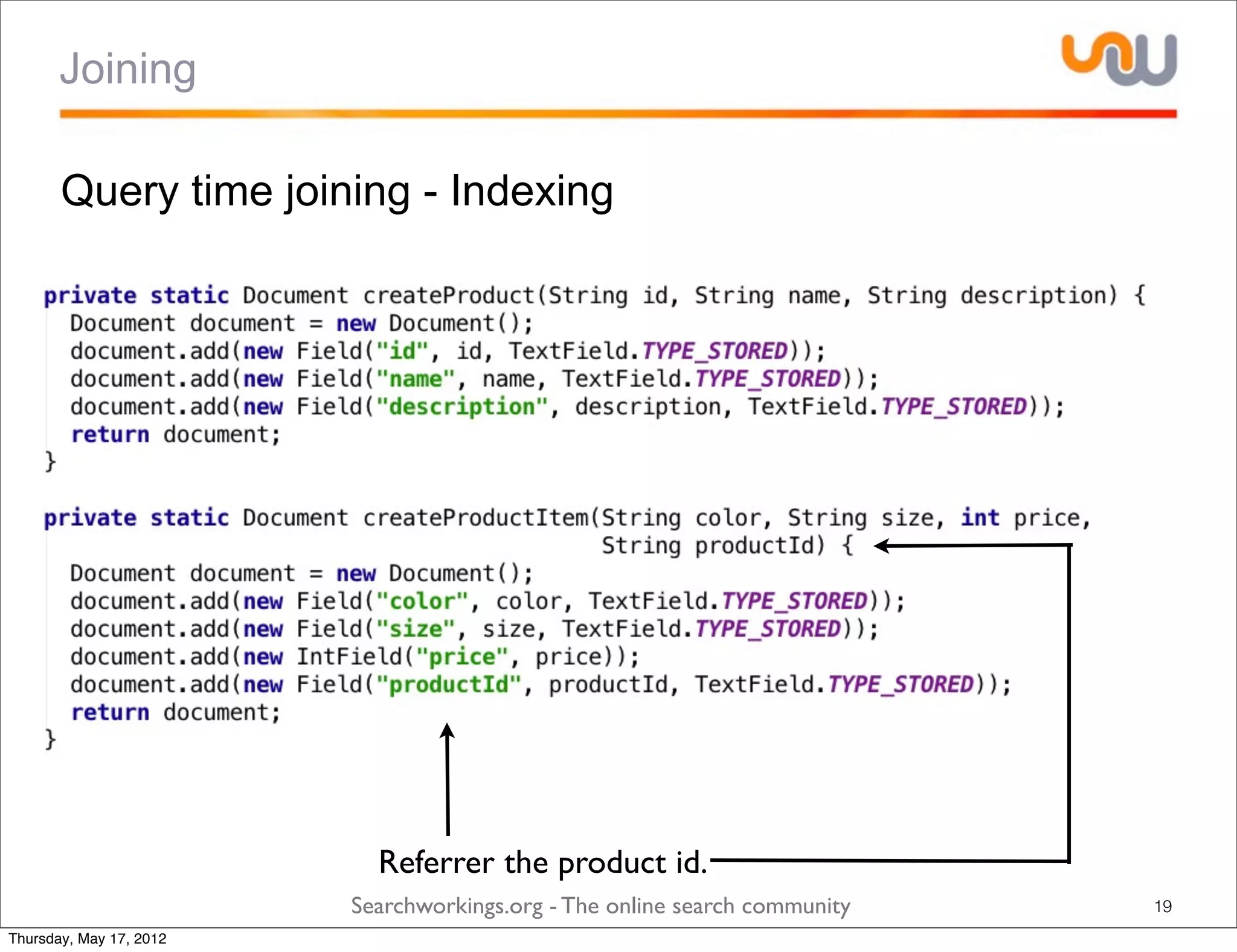
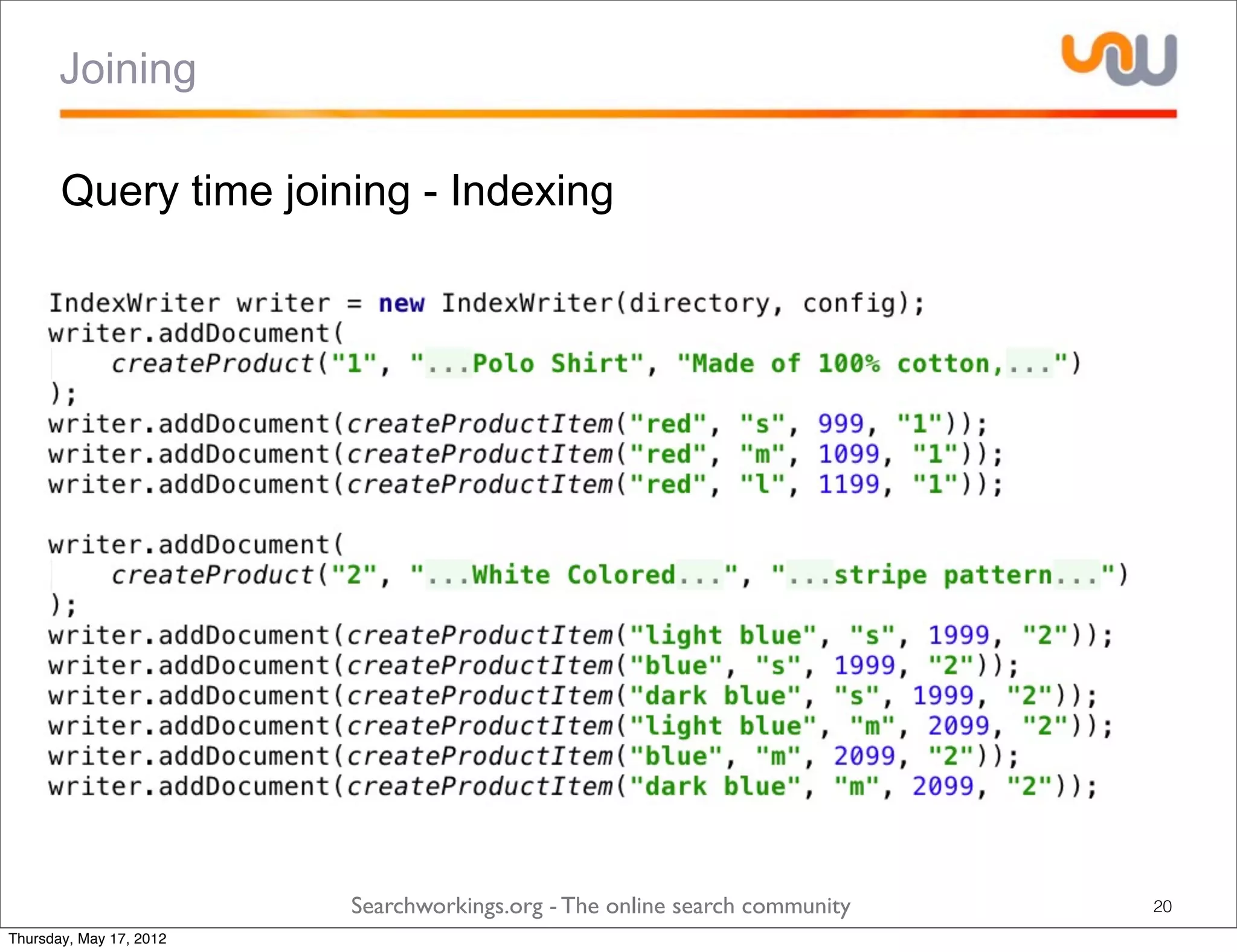
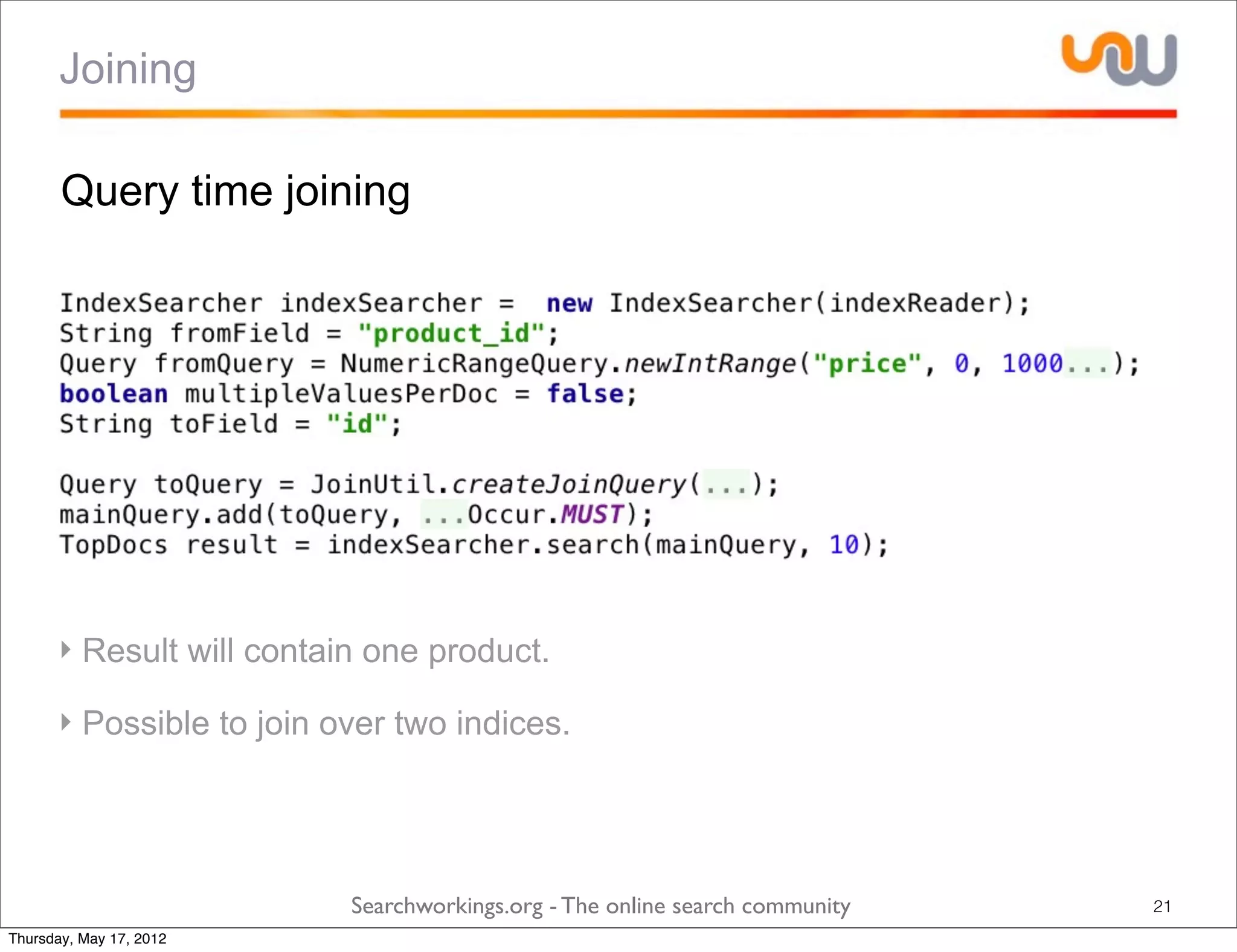



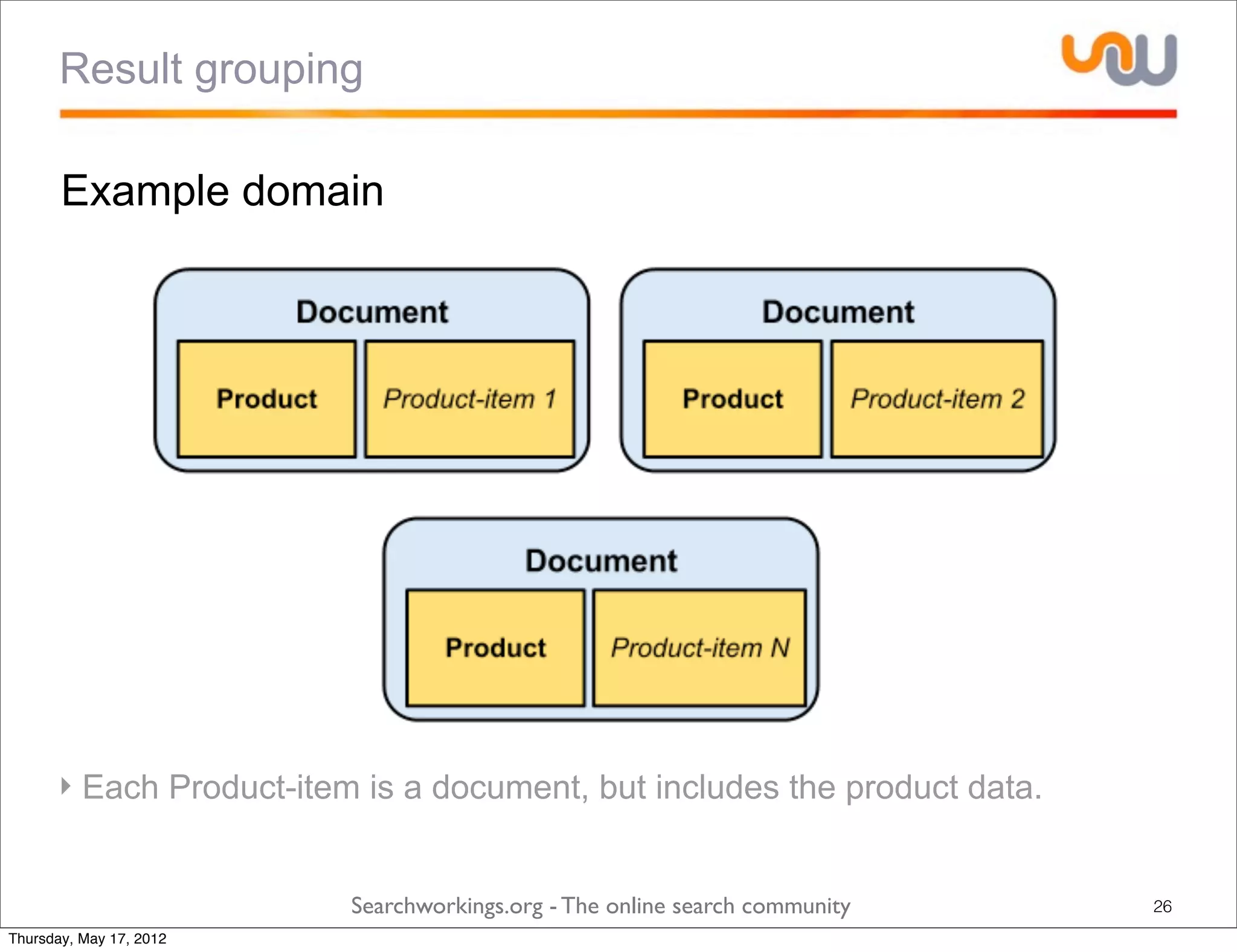



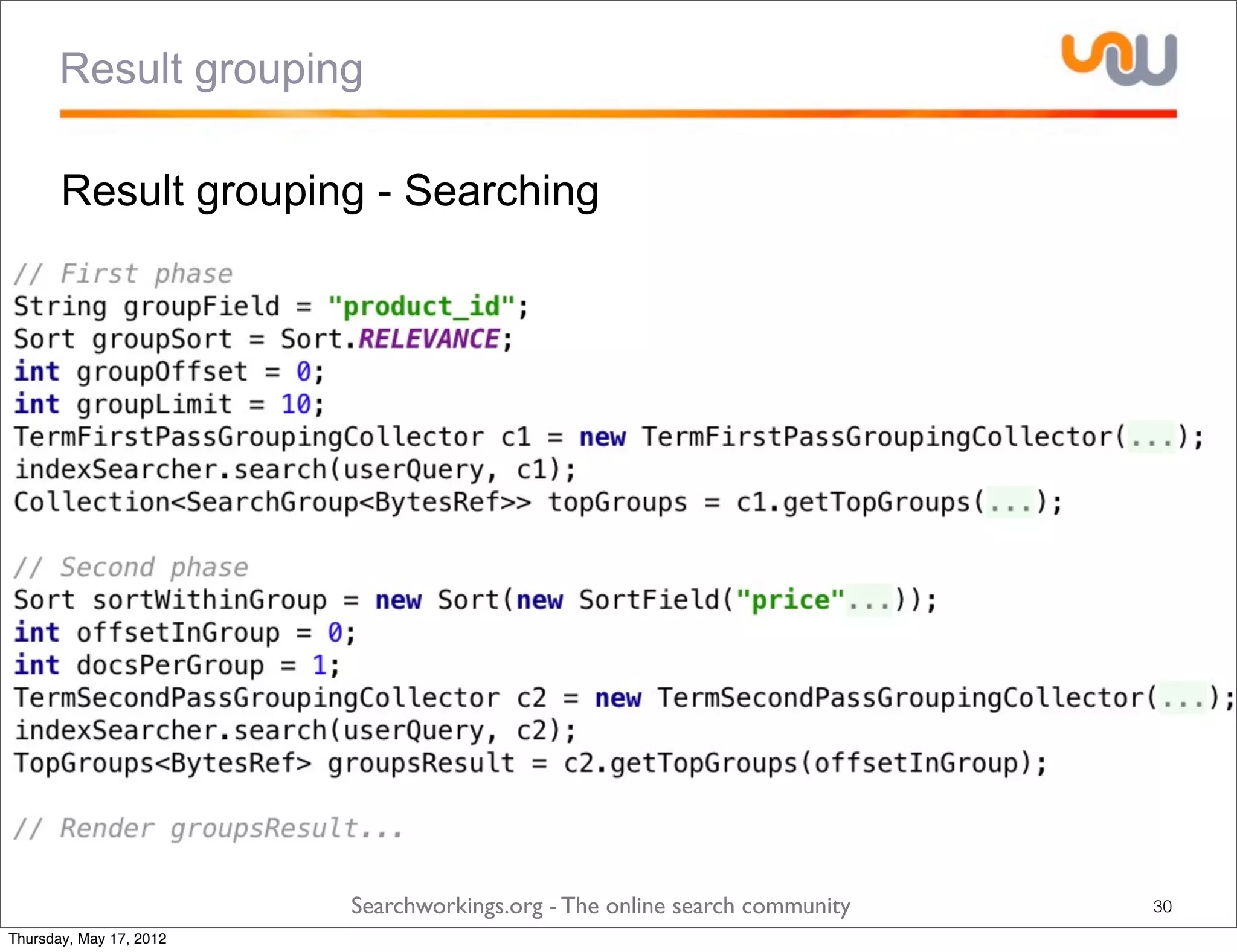
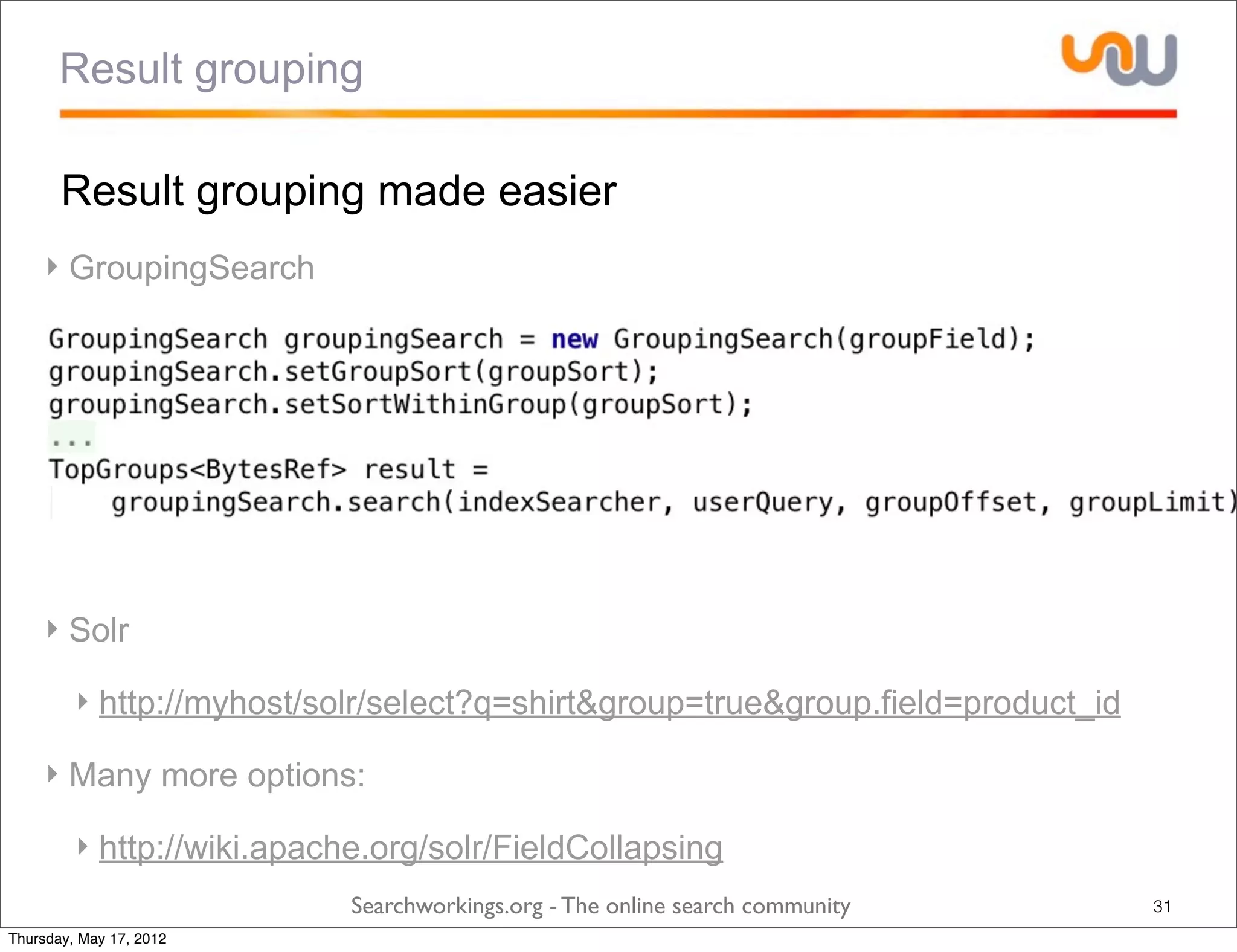
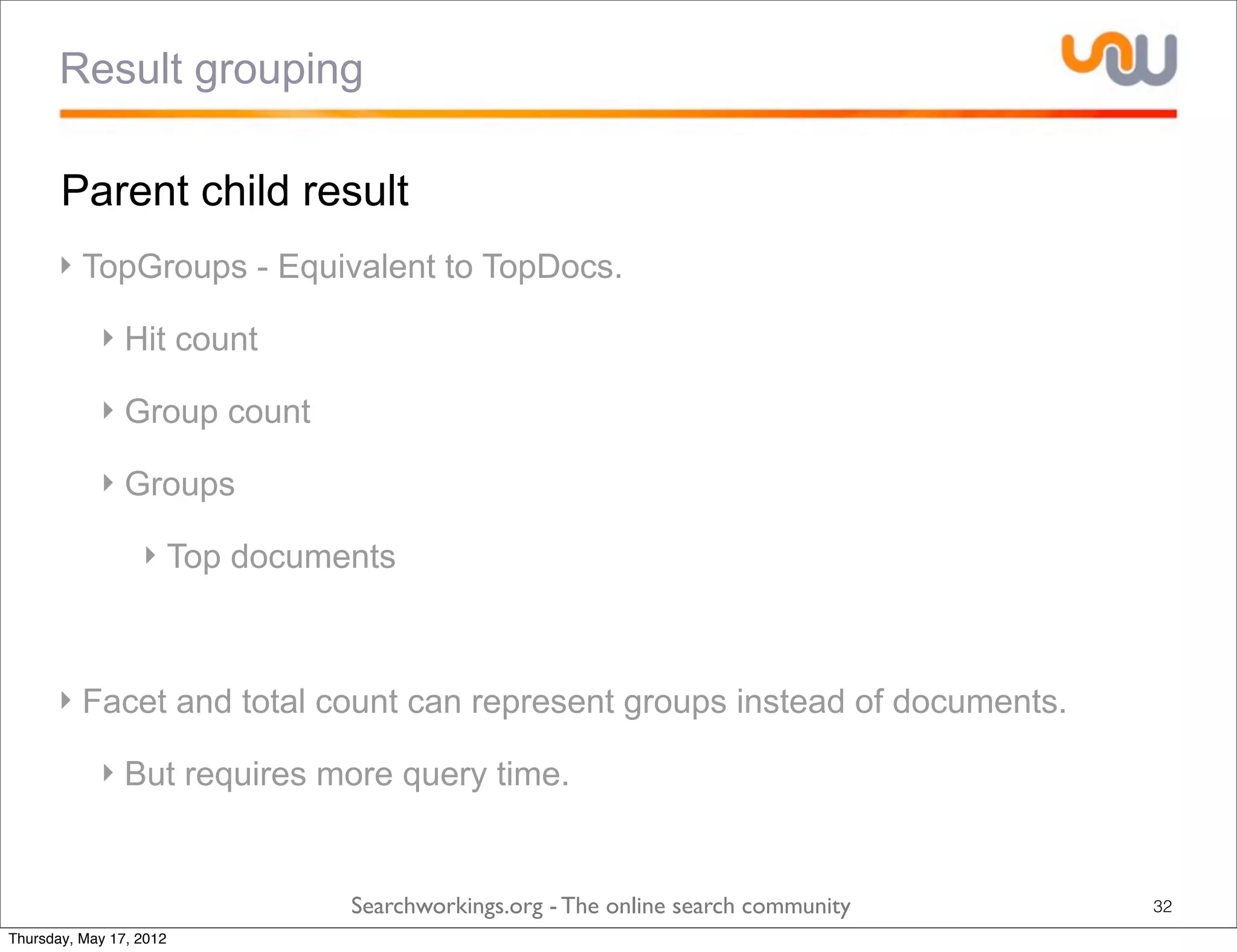

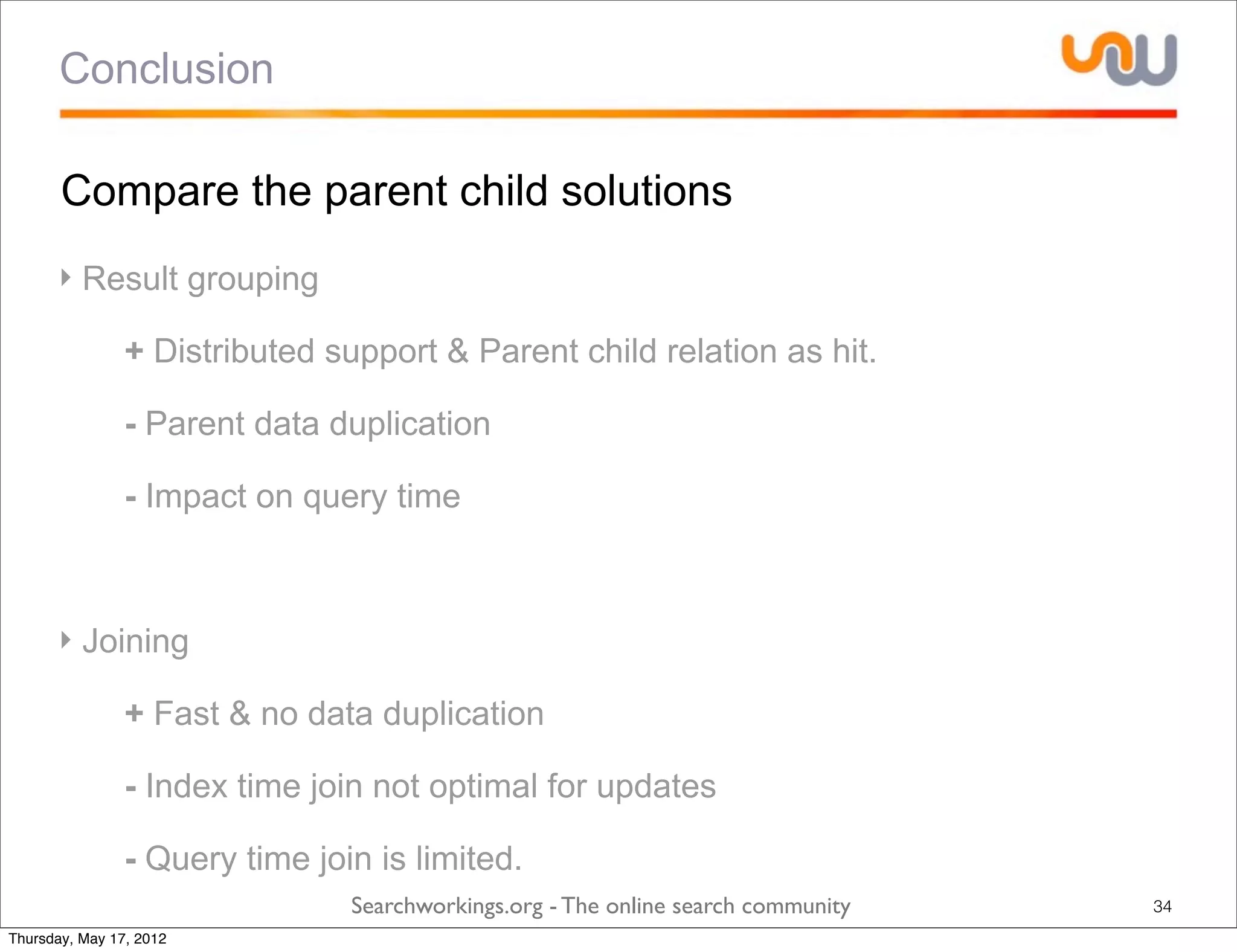
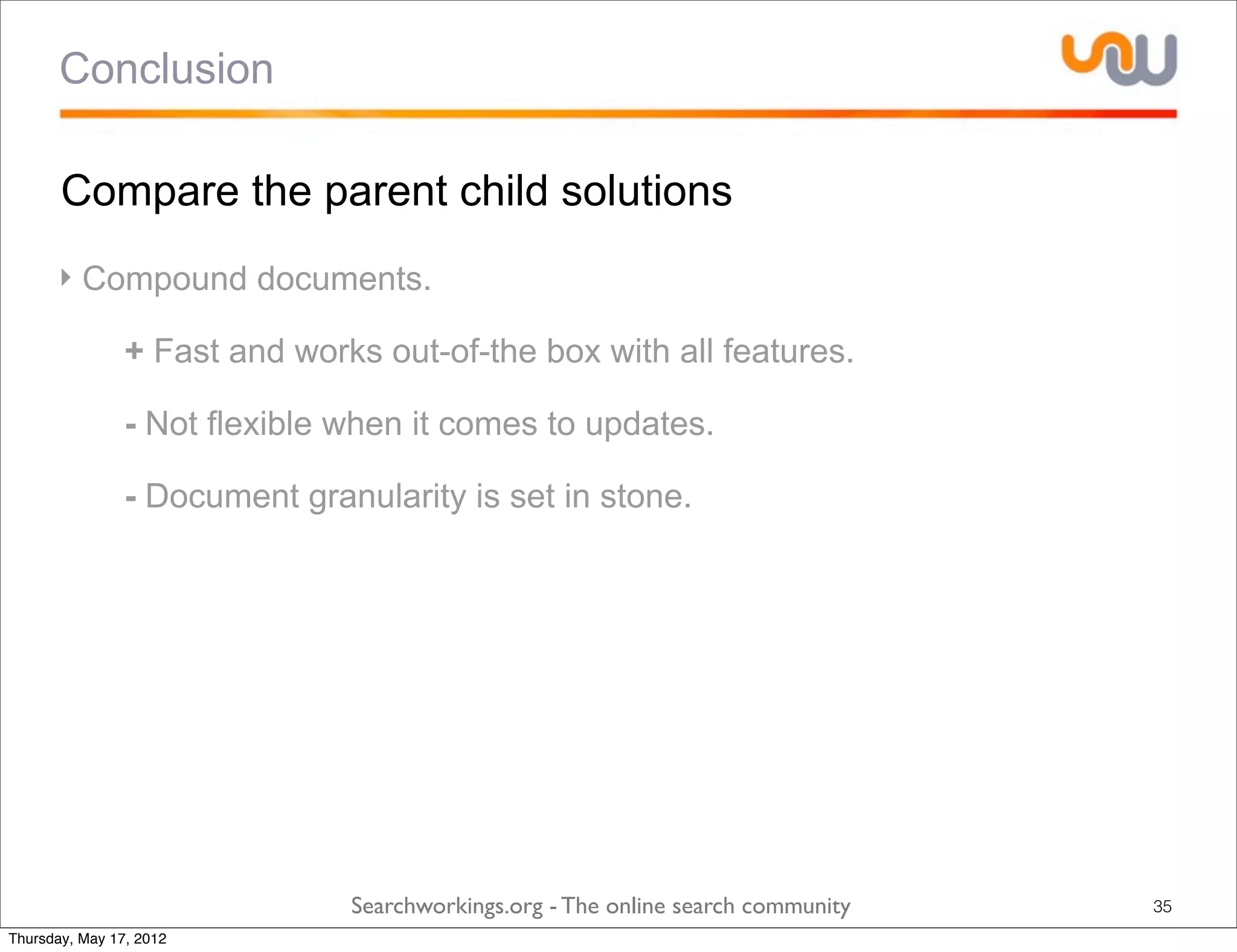


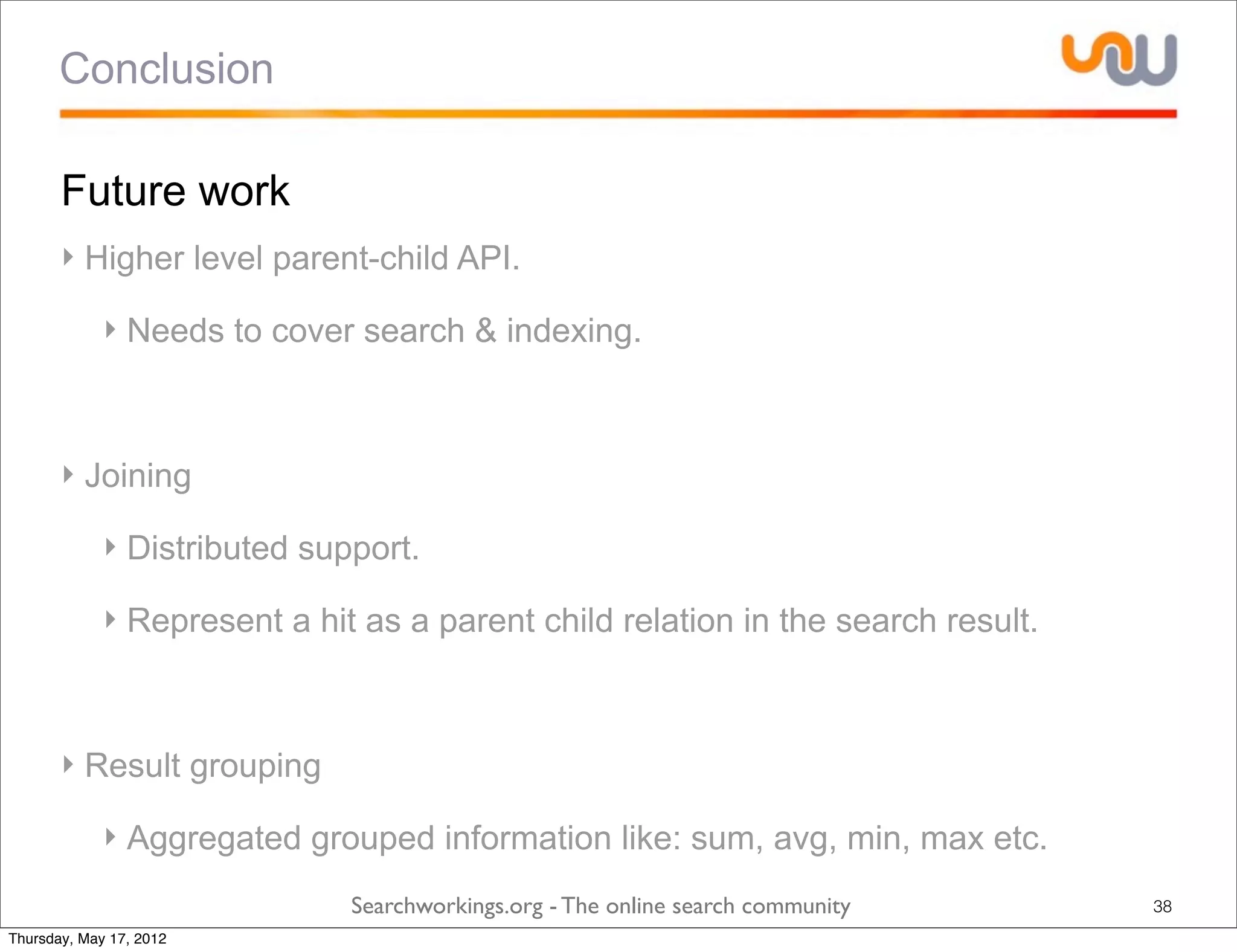
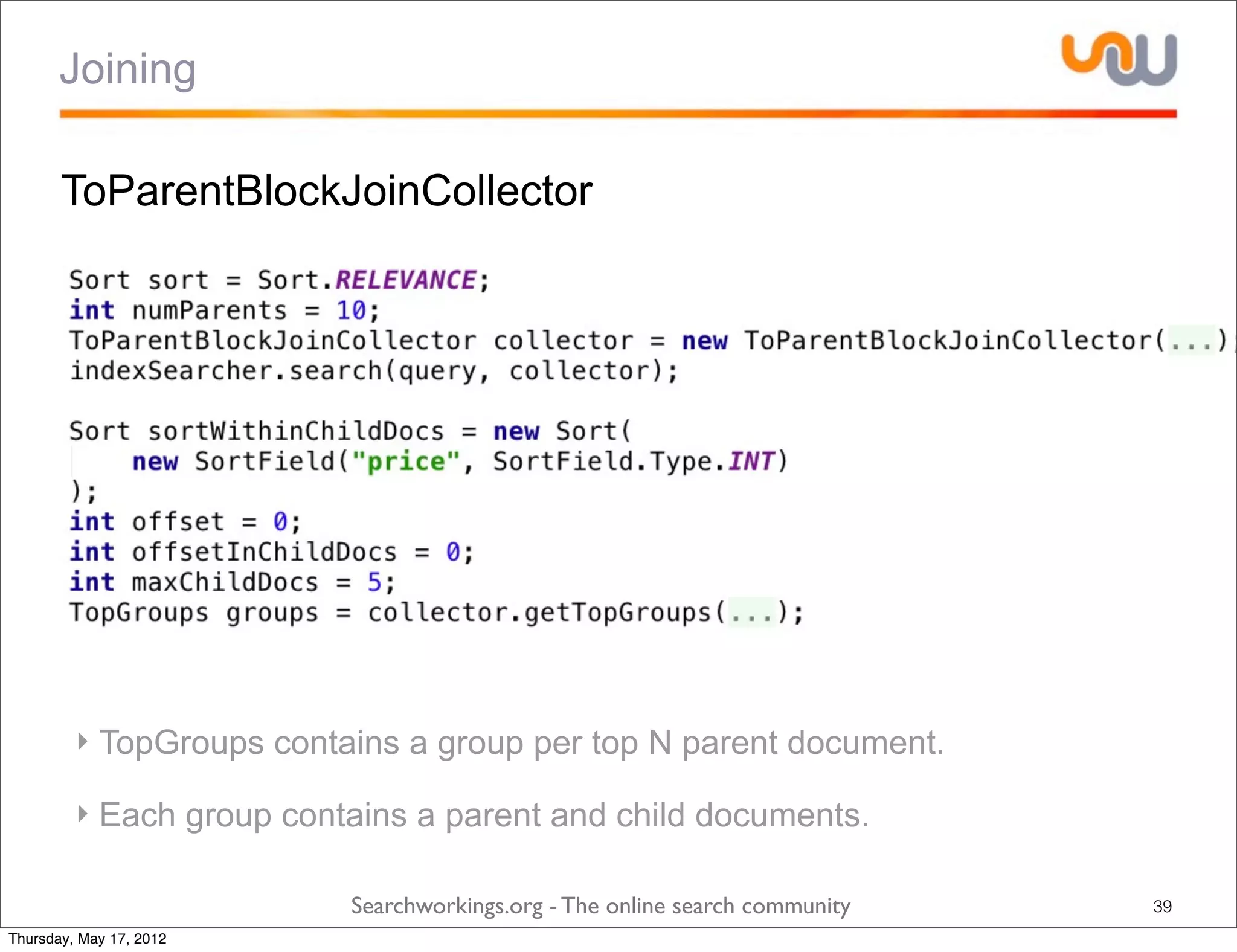
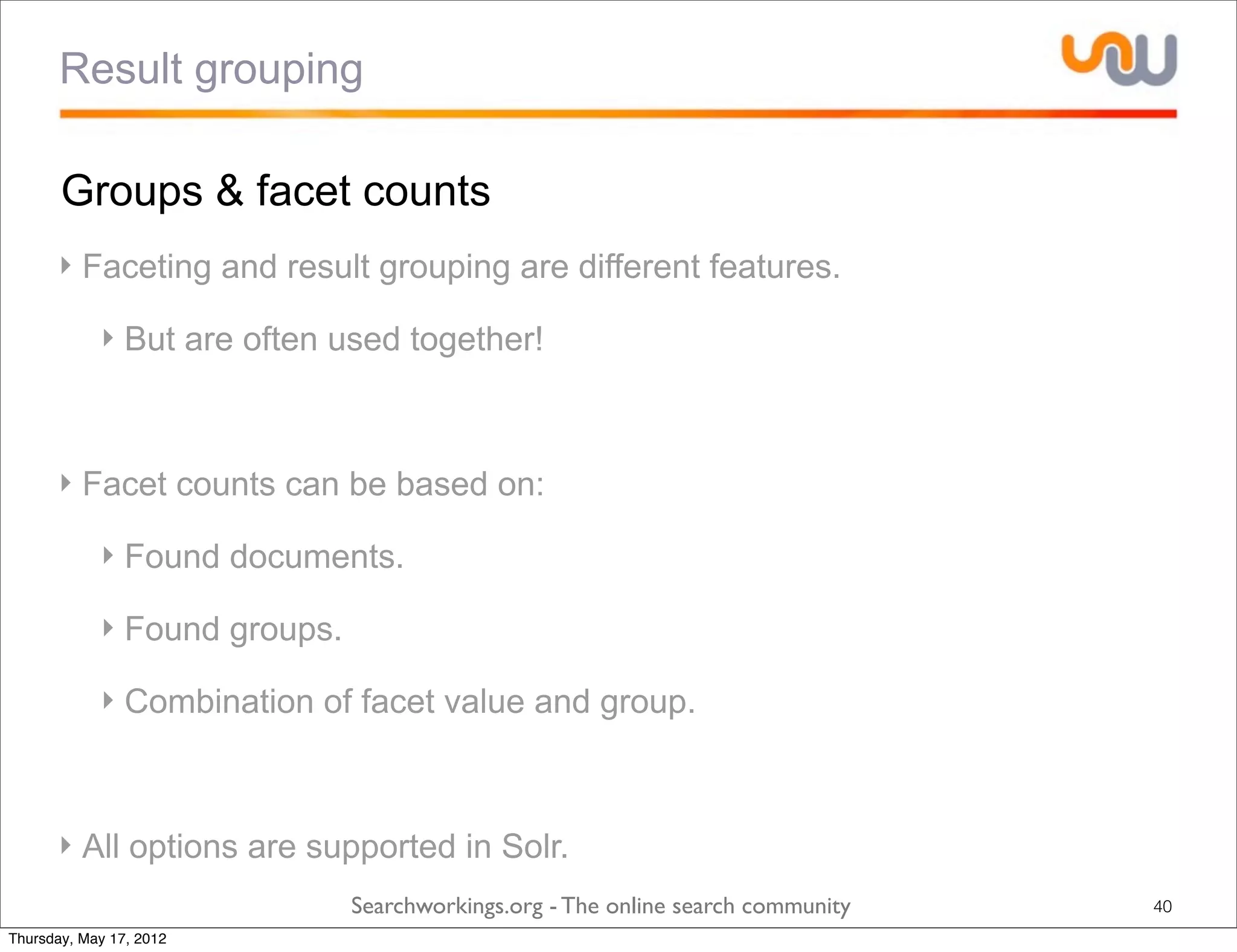
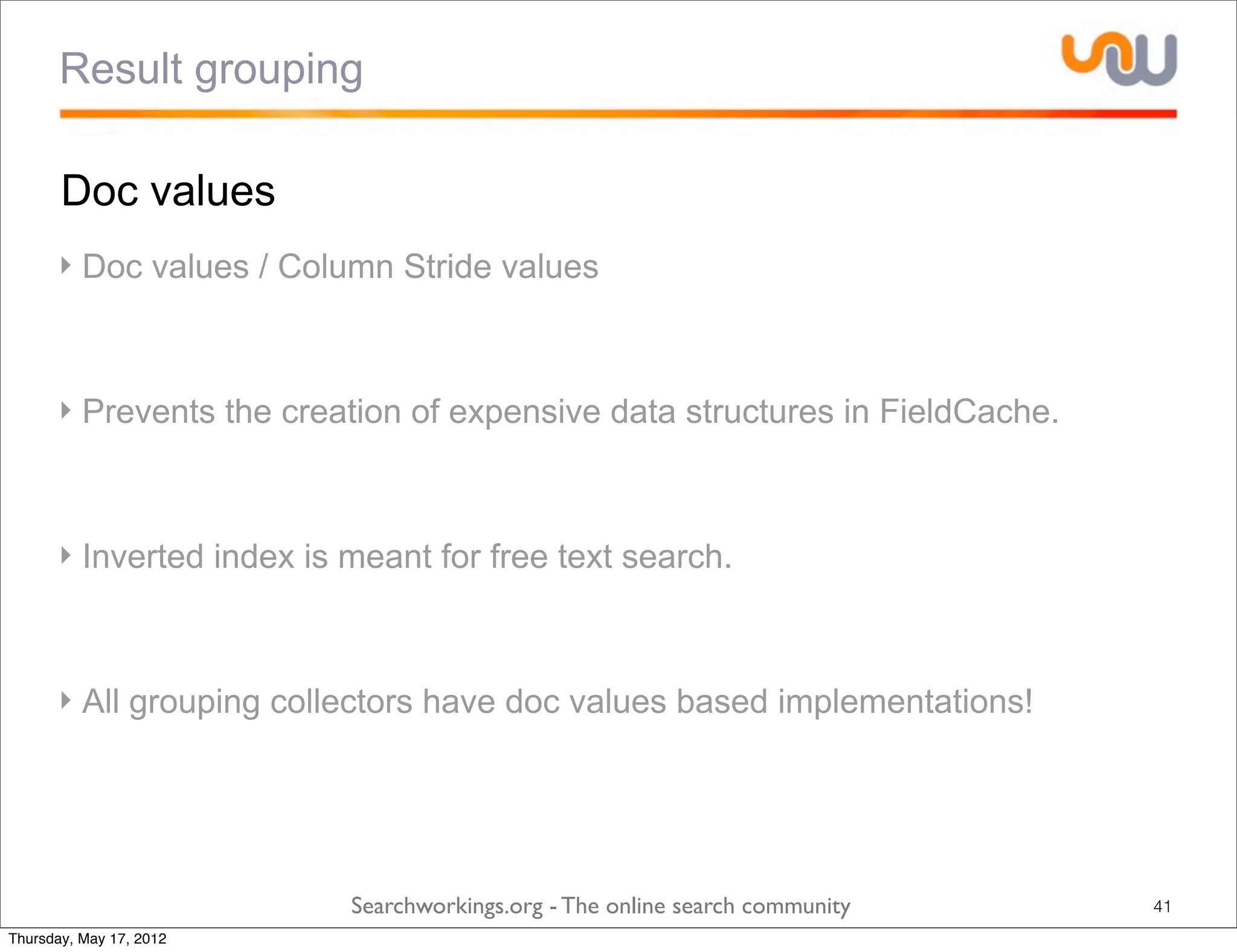

The document discusses the concepts of grouping and joining in Lucene, highlighting Lucene's document-based model and the lack of inherent relational capabilities. It presents various approaches, including index-time and query-time joins for handling parent-child relationships, along with result grouping techniques. The conclusion compares the benefits and limitations of each method, emphasizing the need for future development in these areas.


























![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)




























































