Download as PDF, PPTX




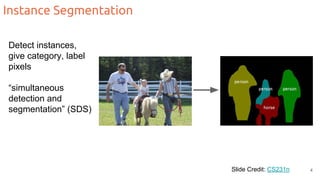


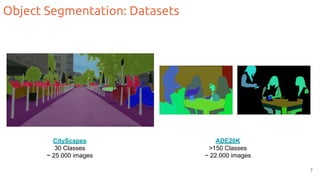
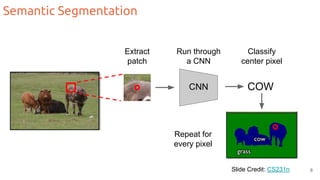
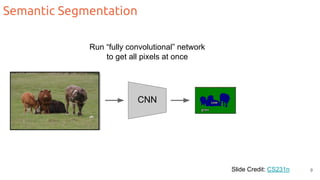
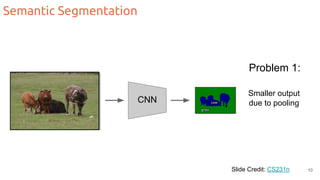
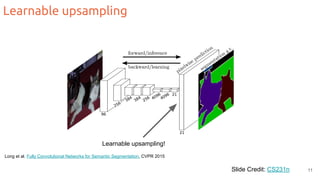
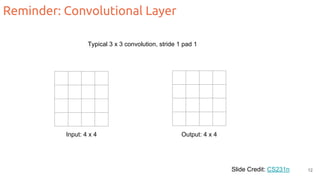
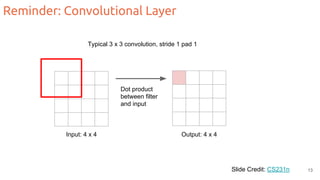
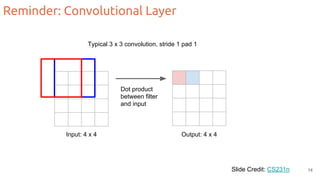
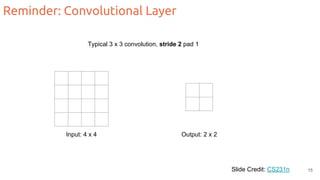
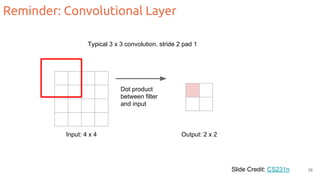
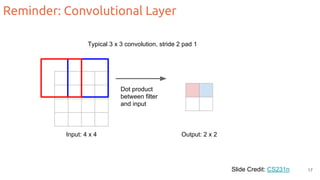

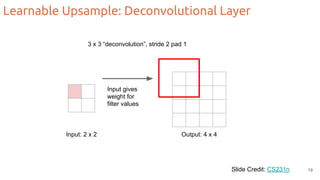
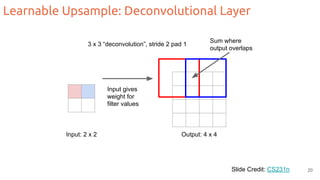
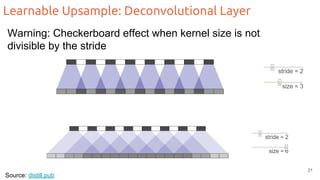

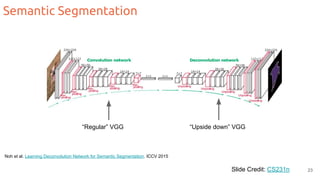
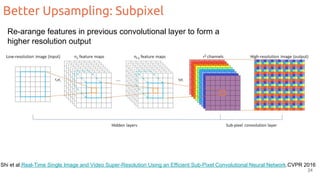
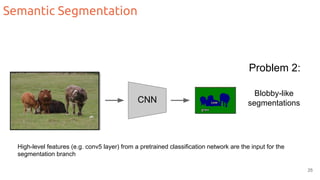
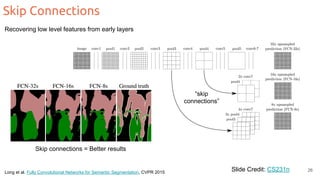

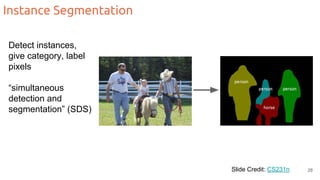

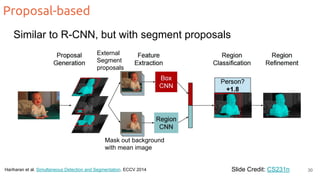
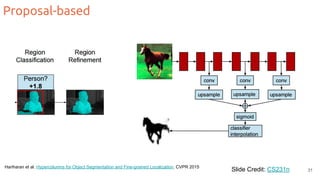
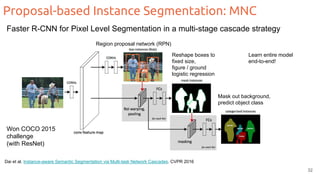

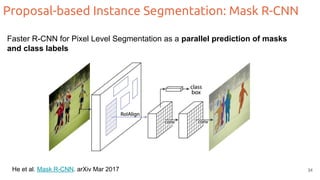
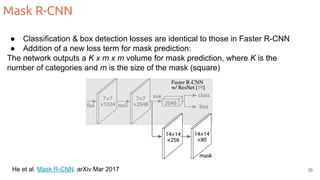
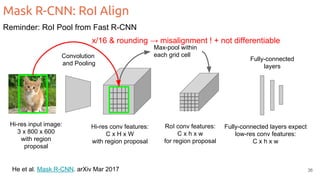
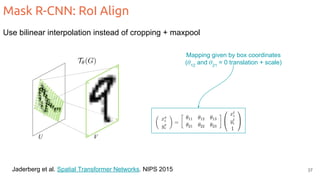

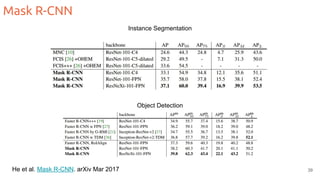
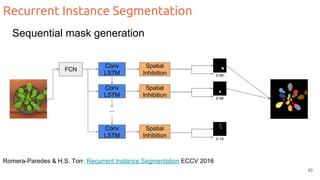
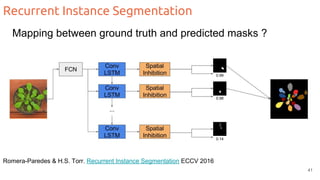









The document discusses object segmentation in deep learning, detailing semantic and instance segmentation techniques along with various datasets used in the field. Key methods for semantic segmentation include fully convolutional networks and learnable upsampling, while instance segmentation is addressed through proposal-based methods and recurrent approaches. Various challenges and innovations in these techniques are highlighted, including the implementation of skip connections and dilated convolutions for enhanced performance.





















































































