Downloaded 1,472 times











































![Parsing (Chinese)
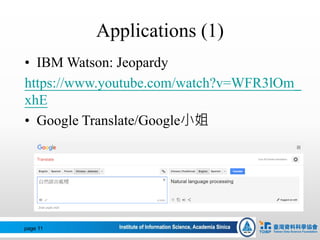
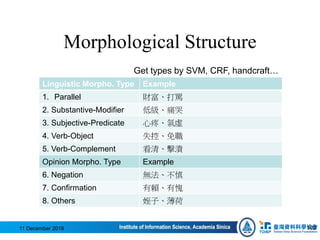
• #1:1.[0] S(experiencer:NP(Head:Nhaa:
我)|Head:VL1:愛|reason:NP(property:Na:自然
|Head:Nac:語言)|goal:VP(Head:VC2:處理))#
page 45](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-45-320.jpg)







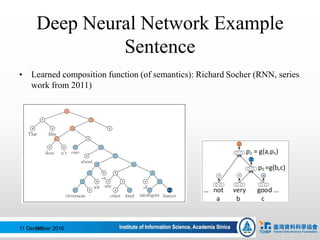
![Word Embeddings (2)
Pre-trained or train by yourself!
• w2v
• Glove
我不會deep learning怎麼辦?
You can find various of embeddings on the Web.
[Check here!]
page 53](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-53-320.jpg)






















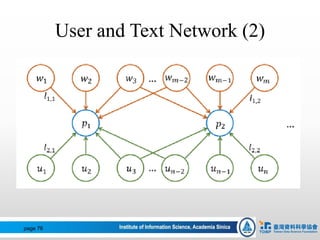





















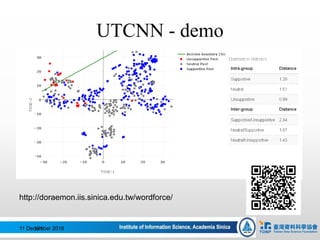
![[仇 (-1.0) + 視 (0.0)] / 2 = -1/2 = -0.5 (NEG)
[富(1.0) + 貴(0.936)] / 2 = 0.968 (POS)
好人、美麗、憤怒、弱小…
m
j
cc
n
j
cc
m
j
cc
c
jiji
ji
i
fnfnfpfp
fnfn
N
11
1
//
/
)( iii ccc NPS
p
j
cw j
S
p
S
1
1
m
j
cc
n
j
cc
n
j
cc
c
jiji
ji
i
fnfnfpfp
fpfp
P
11
1
//
/
99
Bag of Unit
11 December 2016](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-99-320.jpg)












































![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-151-320.jpg)
![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-152-320.jpg)
![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-153-320.jpg)
![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-154-320.jpg)
![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-155-320.jpg)
![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://image.slidesharecdn.com/nlptutorial-0828-170830062001/85/slide-156-320.jpg)

The document presents an overview of natural language processing (NLP), including its definition, applications, and challenges faced in the field. It discusses various tools and resources related to both English and Chinese text processing, as well as the significance of sentiment analysis in social media contexts. Additionally, it highlights the interdisciplinary nature of NLP, drawing connections to artificial intelligence, information retrieval, and machine learning.
![[AI / ML] 用 LLM (Large language model) 來整理您的知識庫 @Devfest Taipei 2023](https://cdn.slidesharecdn.com/ss_thumbnails/llm-231218061525-554e880d-thumbnail.jpg?width=640&height=640&fit=bounds)







![[系列活動] 文字探勘者的入門心法](https://cdn.slidesharecdn.com/ss_thumbnails/textmininghandout-170320140215-170327095320-thumbnail.jpg?width=640&height=640&fit=bounds)

![[系列活動] 手把手的深度學習實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharestepbystepdl-161213072731-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)









![[系列活動] Python爬蟲實戰](https://cdn.slidesharecdn.com/ss_thumbnails/python-170809083644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 一日搞懂生成式對抗網路](https://cdn.slidesharecdn.com/ss_thumbnails/gan-170813004356-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Python 程式語言起步走](https://cdn.slidesharecdn.com/ss_thumbnails/python20170812-170808043244-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Machine Learning 機器學習課程](https://cdn.slidesharecdn.com/ss_thumbnails/ml4ds02122017-170212005829-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 使用 R 語言建立自己的演算法交易事業](https://cdn.slidesharecdn.com/ss_thumbnails/rtradingbusiness-170115010649-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 智慧製造與生產線上的資料科學 (製造資料科學:從預測性思維到處方性決策)](https://cdn.slidesharecdn.com/ss_thumbnails/20170211datascienceinmanufacturing-170205150525-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 機器學習速遊](https://cdn.slidesharecdn.com/ss_thumbnails/mltourhandout-170310083857-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 智慧城市中的時空大數據應用](https://cdn.slidesharecdn.com/ss_thumbnails/dscstbigdata1060211-170211004152-thumbnail.jpg?width=640&height=640&fit=bounds)

![[系列活動] 資料探勘速遊 - Session4 case-studies](https://cdn.slidesharecdn.com/ss_thumbnails/session4-case-studies-170114072124-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 手把手教你R語言資料分析實務](https://cdn.slidesharecdn.com/ss_thumbnails/stepbystepr20170114-170113030702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Data exploration with modern R](https://cdn.slidesharecdn.com/ss_thumbnails/dataexplorationwithmodernr1221-161219044516-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 給工程師的統計學及資料分析 123](https://cdn.slidesharecdn.com/ss_thumbnails/0114lckungtdsaprerequisite-170110090917-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 一天搞懂對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/onedaybot0422-170421235605-170422003351-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC x TAAI 2016] 林守德 / 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/md-161124235136-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC 2016] 系列活動:李泳泉 / 星火燎原 - Spark 機器學習初探](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmllib-161026052038-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/openingsw-190315170512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 工業 4.0 與智慧製造的發展趨勢與挑戰](https://cdn.slidesharecdn.com/ss_thumbnails/20190316jyh-horngchou-190315170336-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiotforaiabytedchangho-190227081005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiinhealthcare-20190216victoria-v6-190227081004-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台北總校第三期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/tp3closingsw-190126030359-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] AI 引爆新工業革命,智慧機械首都台中轉型論壇](https://cdn.slidesharecdn.com/ss_thumbnails/aia-chen-190116063635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 2019 台灣數位轉型 與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/to-sheng-190116063620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 智慧製造成真! 產線導入AI的致勝關鍵](https://cdn.slidesharecdn.com/ss_thumbnails/thu-hsu-190116063619-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 從經濟學看人工智慧產業應用](https://cdn.slidesharecdn.com/ss_thumbnails/1-the-application-of-ai-industry-from-economics-190108064940-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台中分校第二期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/tc2-opening1-compressed-190107034100-thumbnail.jpg?width=640&height=640&fit=bounds)

![[台中分校] 第一期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/sw-ppt-181217031715-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 工業4.0潛力新應用! 多模式對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/20181206004-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] AI整合是重點! 竹科的關鍵轉型思維](https://cdn.slidesharecdn.com/ss_thumbnails/20181206002-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 2019 台灣數位轉型與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/20181206-001-181210031002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 深度學習與Kaggle實戰](https://cdn.slidesharecdn.com/ss_thumbnails/20181206003-181210031001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] Bridging AI to Precision Agriculture through IoT](https://cdn.slidesharecdn.com/ss_thumbnails/hc-2nd-openingai-school-181206104858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 產業經驗分享: 如何用最少的訓練樣本,得到最好的深度學習影像分析結果,減少一半人力,提升一倍品質 / 李明達](https://cdn.slidesharecdn.com/ss_thumbnails/lee-181130104127-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 啟動物聯網新關鍵 - 未來由你「喚」醒 / 沈品勳](https://cdn.slidesharecdn.com/ss_thumbnails/20181117shengfn-181130083931-thumbnail.jpg?width=640&height=640&fit=bounds)














![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




