참고로각 수렴간에는비교가 가능합니다
d‑수렴이d ‑수렴보다강하다(d is stronger than d )
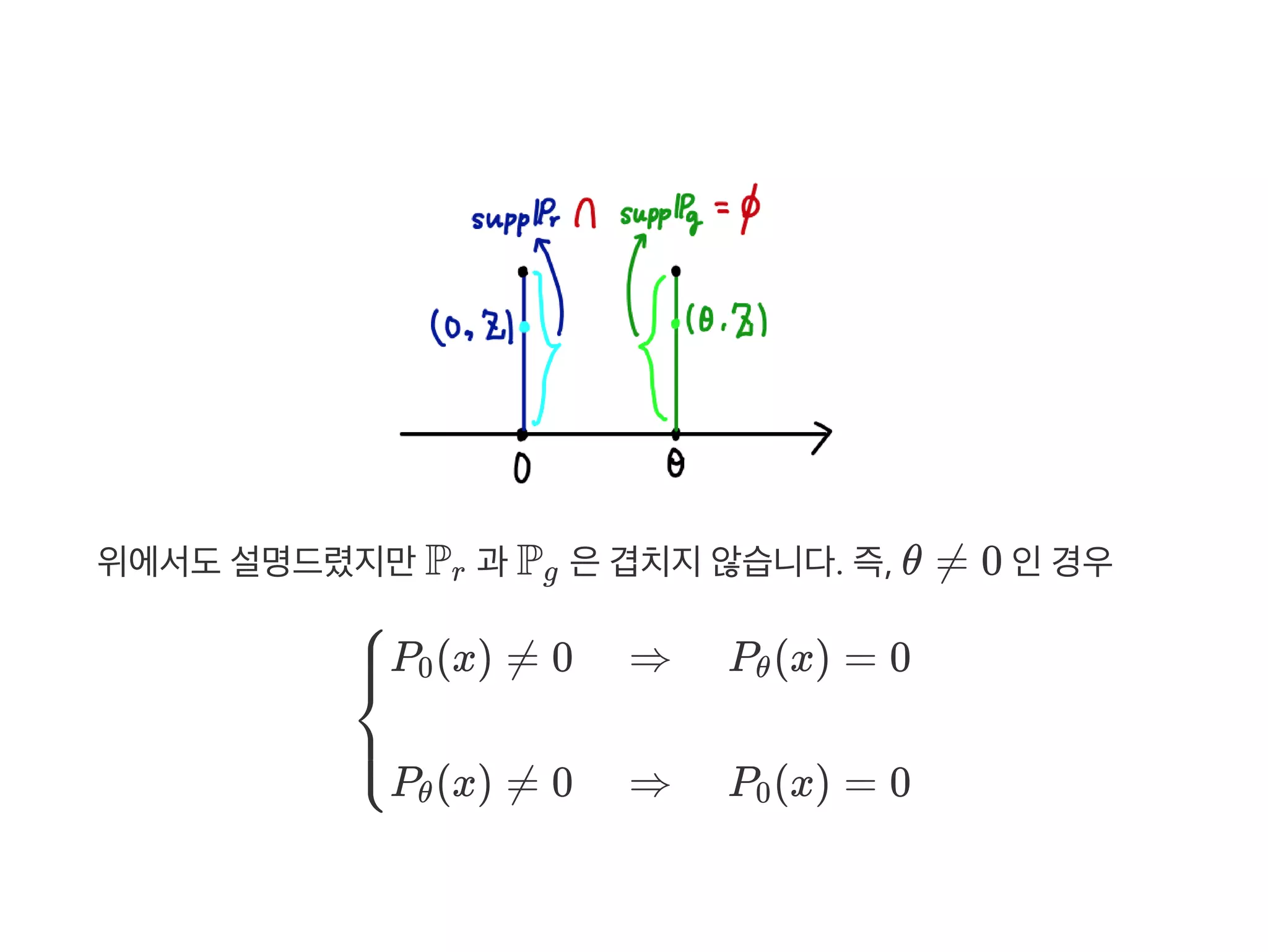
d (x , x) → 0 ⟹ d (x , x) → 0
거꾸로성립하면약하다고 합니다(d is weaker than d )
둘다성립하면동등하다고 합니다(d and d are equivalent)
공간에따라차이가 있어서비교가 항상가능하진않습니다
그래서수학자가 필요합ㄴ... 읍읍
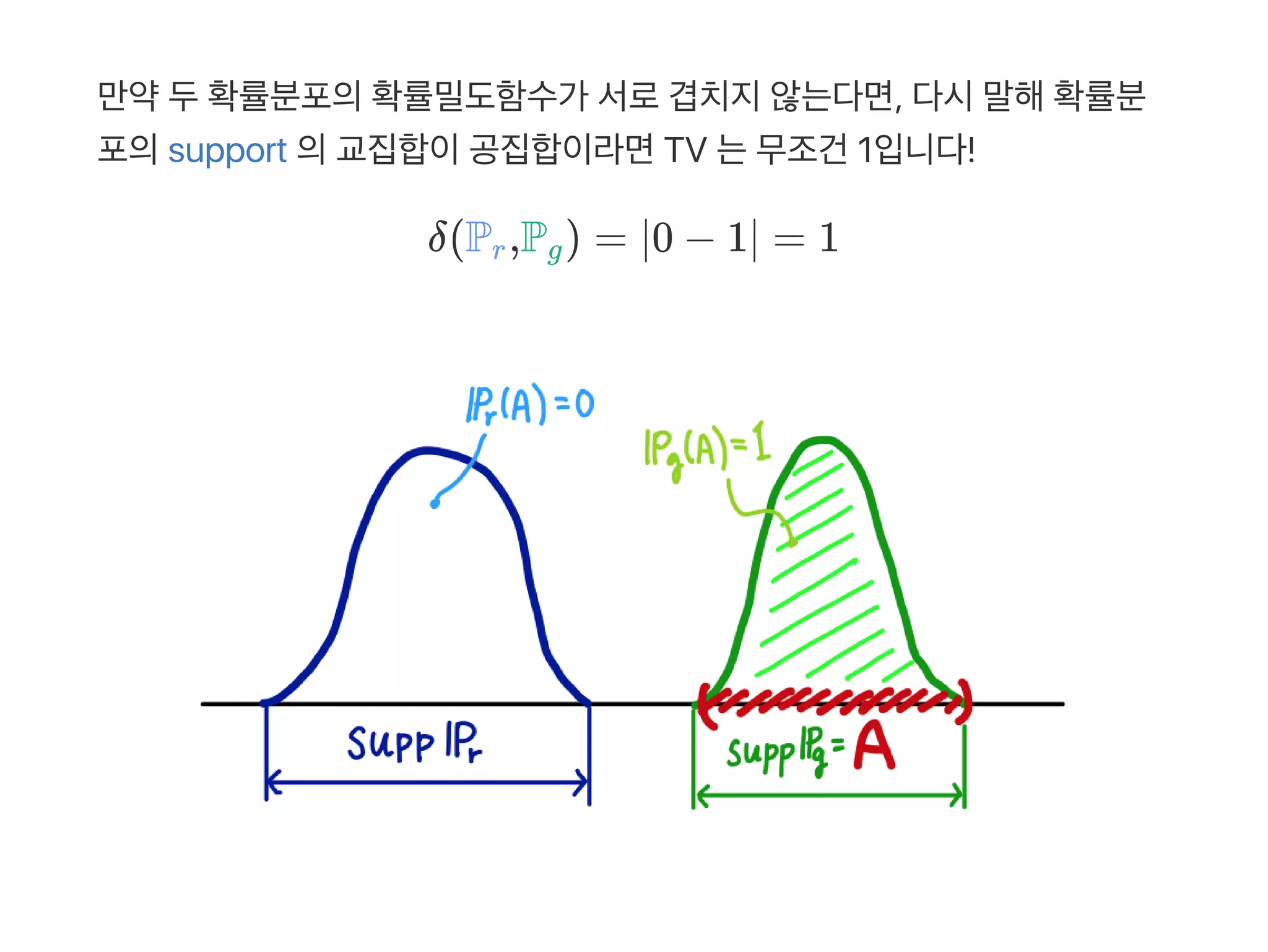
1 2 1 2
1 n 2 n
1 2
1 2
19.
일례로유클리드와맨해튼거리는동등한관계입니다
d (x, y)→ 0 ⟺ d (x, y) → 0
한줄증명:
n d (x, y) ≤ d (x, y) ≤ n d (x, y)
Euclid Manhattan
−1/2
Euclid Manhattan Euclid
X : compact metricset
Definition.
A topological space X is called compact if each of its open covers
has a finite subcover.
(해석) : 위상공간 X 를덮는임의의열린덮개들이있을때, 그 중유한개의부
분덮개들을뽑아서X 를항상덮을수있으면compact 라부른다
참고로compact set 은수학을전공한학생들도가장헷갈려하는개념입니다. 머리가
아프다면잠깐 세수를하고 휴식을취하세요. 갈 길은머니... 그냥모르고 싶다면넘어가
도크게 상관은없어요. 아마도...?
Heine‑Borel property.
If Xis compact, then it is closed and bounded
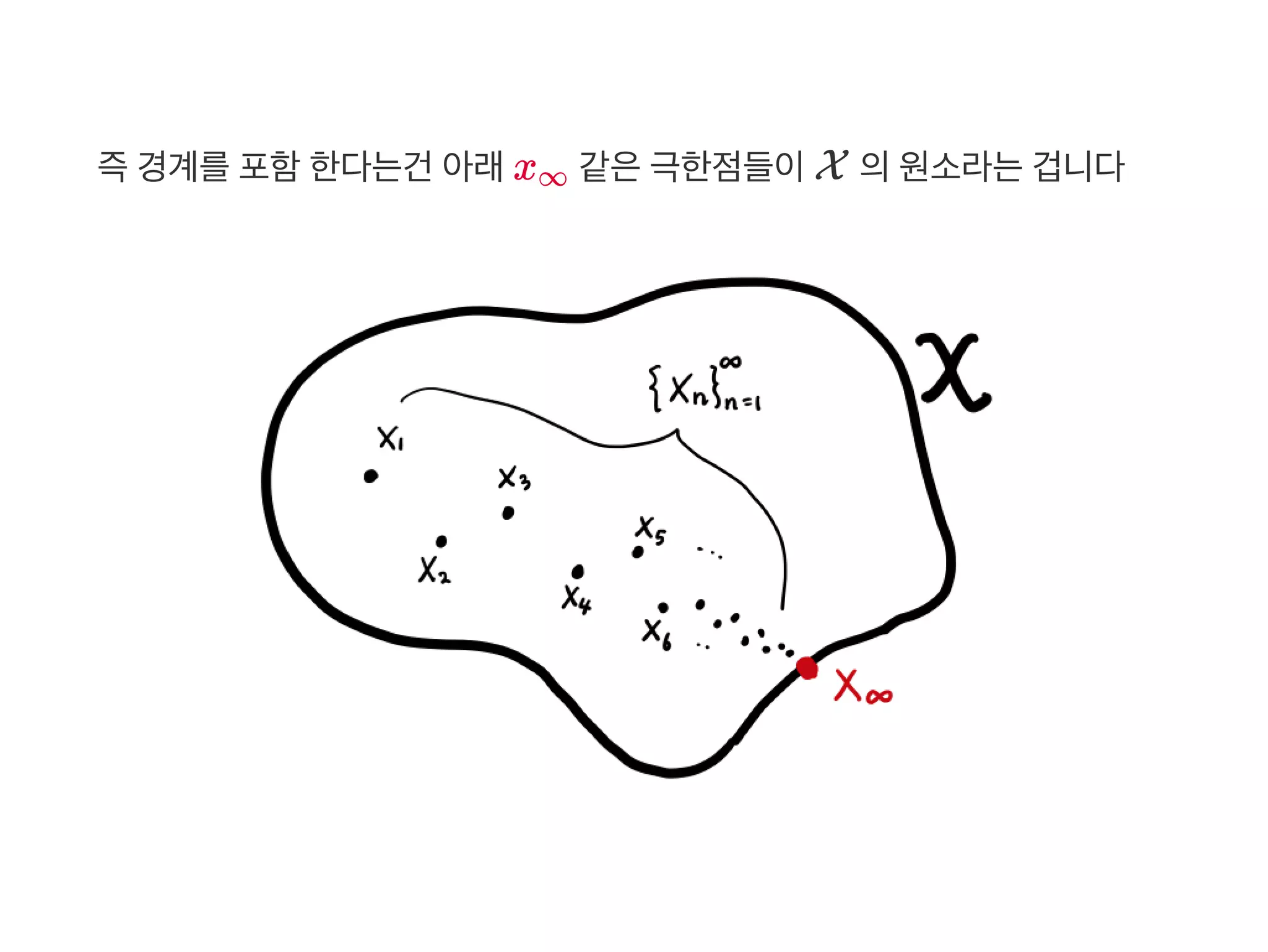
Heine‑Borel 정리를통해해석하면X 가 compact 란건 경계가 있고
(bounded) 동시에경계를포함한다(closed) 는집합이란겁니다
수학에서정식용어는유계(bounded), 닫힌(closed) 입니다
Σ : setof all the Borel subsets of X
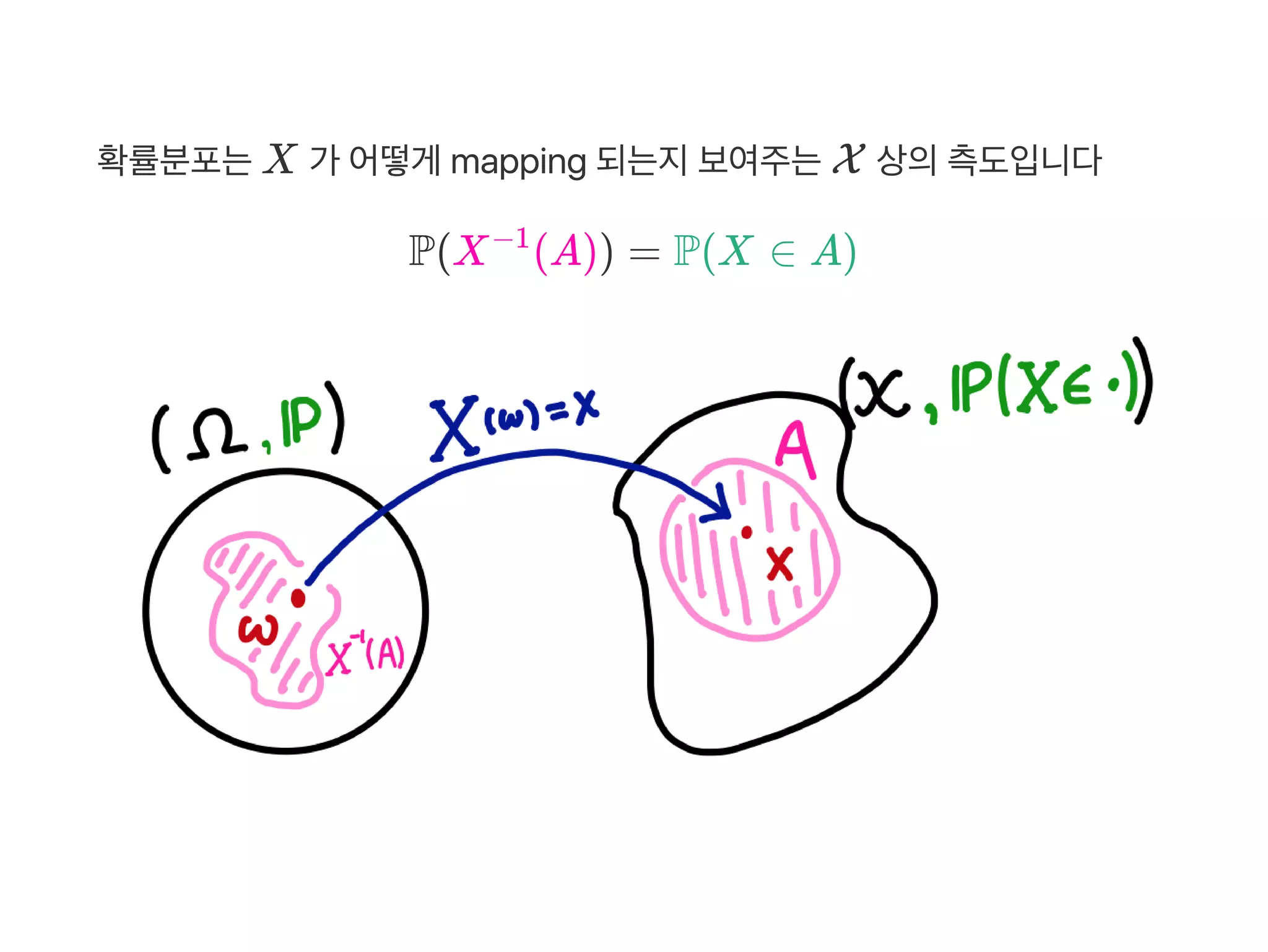
Borel 집합은X 내에서측정가능(measurable) 한집합들을말합니다.
여기서측정가능의의미는P , P 같은확률분포로확률값이계산될수
있는집합을말합니다
연속함수의기대값을계산하기 위한수학적인최소조건 이됩니다
(전문가의딴지) X 위에정의된닫힌(closed) 집합들을포함하는가장작은σ‑대수를
Borel 대수라고 합니다. Borel 집합은이Borel 대수의원소입니다.
r g
우리가 seed 함수로샘플링을고정하는건 ω∈ Ω 를하나뽑는것이고
numpy.random 의특정분포로값을추출하는건 X(ω) 를뽑는것입니다
import numpy as np
np.random.seed(10) # w 를 고정
np.random.normal(mu,sigma) # X(w) 를 샘플링
Kullback‑Leibler & Jensen‑Shannondivergence
KL(P ∥P ) = log P (x)μ(dx)
JS(P ,P ) = KL P ∥ + KL P ∥
KL 과 JS 는워낙익숙한애들이죠?
r g ∫ (
P (x)g
P (x)r
) r
r g
2
1
( r
2
P +Pr g
)
2
1
( g
2
P +Pr g
)














![f 이f 로모든x 에대해서ϵ 범위안에들어오면서수렴하게 만들수있으
면L ‑수렴또는균등수렴(uniformly converge)한다고 합니다
∥f − f∥ = ∣f(x) − f (x)∣ → 0
(전문가의딴지) 수렴안하는정의역의measure 가 0 이면됩니다
n
∞
n ∞
x∈[a,b]
sup n](https://image.slidesharecdn.com/wgan-170501022129/75/Wasserstein-GAN-I-15-2048.jpg)






















































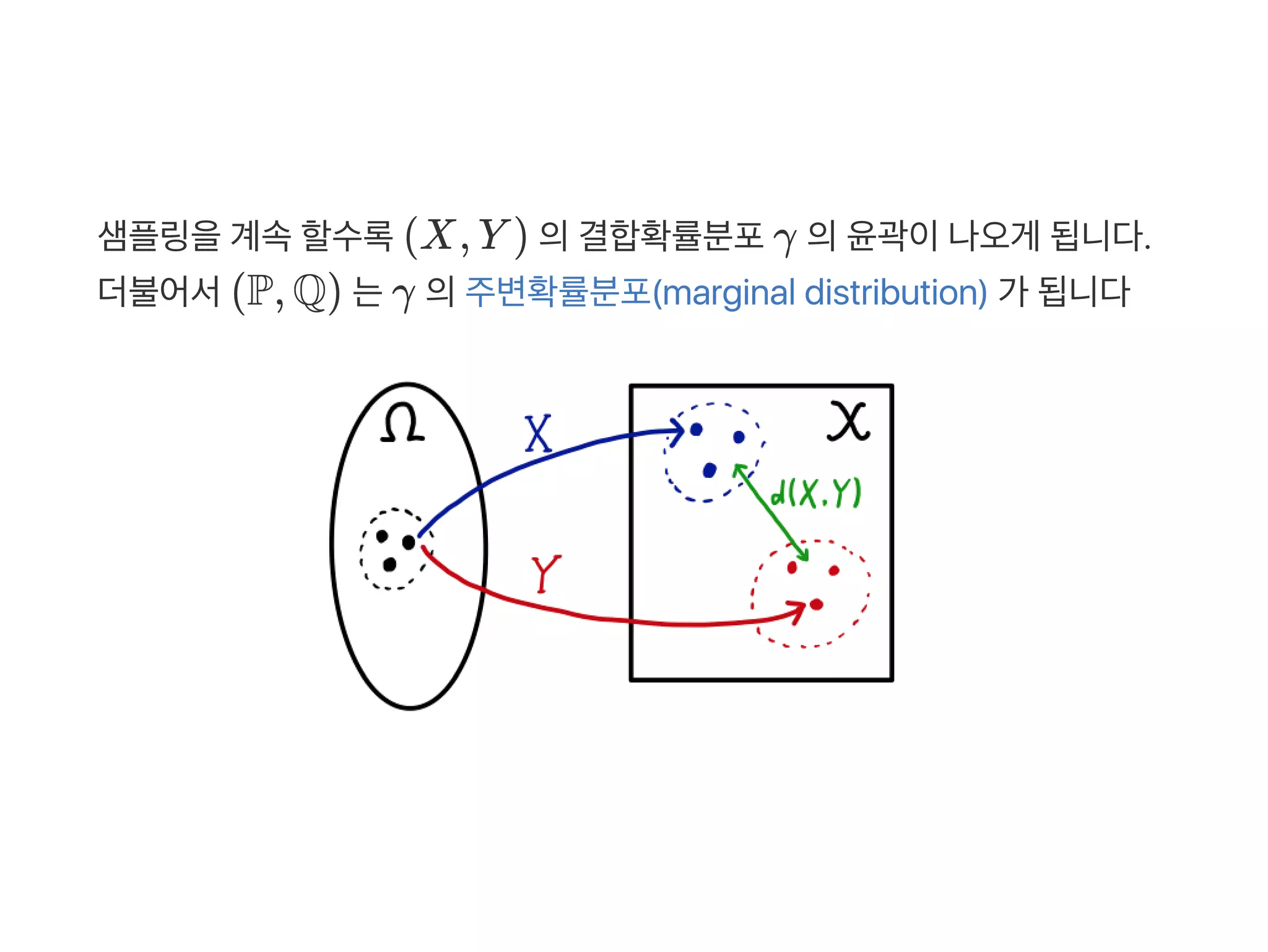
![Wasserstein distance 의정의는이렇습니다
여기서Π(P, Q) 는두확률분포P, Q 의결합확률분포(joint distribution)
들을모은집합이고 γ 는그 중하나입니다. 즉모든결합확률분포Π(P, Q)
중에서d(X, Y ) 의기대값을가장작게 추정한값 을의미합니다
W(P, Q) = d(x, y)γ(dxdy)
γ∈Π(P,Q)
inf ∫
= E [d(X, Y )]
γ∈Π(P,Q)
inf γ](https://image.slidesharecdn.com/wgan-170501022129/75/Wasserstein-GAN-I-76-2048.jpg)







![즉d(X, Y ) 의기대값은어떤결합확률분포γ 를사용하든항상∣θ∣ 보다크
거나같습니다
E [d(X, Y )] ≥E [∣θ∣] = ∣θ∣
음... 그런데기대값이∣θ∣ 인상황이있을까요?
γ γ](https://image.slidesharecdn.com/wgan-170501022129/75/Wasserstein-GAN-I-85-2048.jpg)



















![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)

![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[기초수학] 미분 적분학](https://cdn.slidesharecdn.com/ss_thumbnails/random-110803105819-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Word Embedding] Glove Complete Explanation - Yonghee Cheon](https://cdn.slidesharecdn.com/ss_thumbnails/wordembeddingglovecompleteexplanation-yongheecheon-200730154619-thumbnail.jpg?width=640&height=640&fit=bounds)


