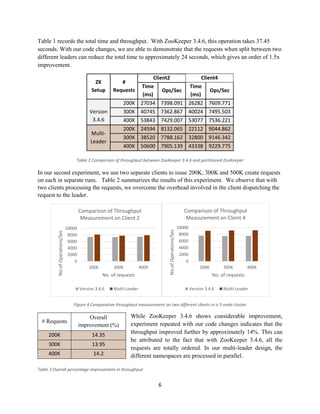
The document presents a project aimed at enhancing the write throughput of a Zookeeper cluster by implementing a partitioned namespace architecture, which allows processing client requests in parallel through multiple quorums each with its own leader. The experimental evaluation demonstrates a performance improvement of approximately 14% in write throughput by reducing ordering constraints for unrelated request paths while maintaining order for requests related to the same path. The authors suggest their approach provides a more economical use of resources compared to traditional methods that require separate clusters for different applications.
![1
Improving Write Throughput Scalability of ZooKeeper by
Partitioning Namespace
CSE 223B Term Project, Spring 2014
Pramod Biligiri
UC San Diego
psubbara@ucsd.edu
Anita Kar
UC San Diego
ankar@ucsd.edu
Anjali Kanak
UC San Diego
akanak@ucsd.edu
_____________________________________________________________________________________
Abstract: We demonstrate that write throughput of a ZooKeeper cluster can be increased by
implementing a partitioning system for the data. By enabling a single ZooKeeper cluster to have
multiple quorums, each with its own leader, client requests that want to access different partitions of
the namespace can be processed in parallel by relaxing the ordering guarantees across partitions.
Experimental evaluation of our implementation shows approximately 14% increase in throughput. The
only extra resource required for each node in the partitioned ZooKeeper is additional hard disk(s) to
cope with the increased throughput.
1. Introduction
ZooKeeper provides a distributed configuration service, synchronization service, and naming registry
for large distributed systems [1]. ZooKeeper nodes store their data in a hierarchical name space (called
znodes), much like a file system or a Trie data structure. Clients can read and write from/to the nodes
and in this way have a shared configuration service.
Partitioned ZooKeeper ZooKeeper follows a primary-backup replication scheme. Currently, the
leader node in a ZooKeeper ensemble processes all incoming client requests sequentially, thus ensuring
strictly ordered access to the znodes.
We created a partitioned version of the ZooKeeper with the goal of improving the write throughput
scalability. This was first suggested on the ZooKeeper wiki page [2] and discussed on the issue tracker
[3]. Thus, the user can specify a set of paths that can be updated independent of each other. This leads
to relaxation in ordering across all the root znodes, where each root znode corresponds to a path.
However for any particular path, the requests are still ordered. Hence, if there are independent
applications using the ZooKeeper ensemble, then partitioning should lead to increased throughput by
removing ordering constraints across independent operations and hence potentially parallelizing
processing and disk writes.
One of the existing suggestions to implement it is by creating completely separated clusters using the
available nodes. Our approach, however, differs from this as we are using the all the nodes while
making independent operations proceed parallelly. To enable this, we created multiple quorums with
the same set of available nodes. All nodes are members of all the quorums. Each quorum can be
visualized as a logical abstraction having its own leader and being responsible for a handling requests](https://image.slidesharecdn.com/zookeeper-partitioning-project-report-140617040820-phpapp02/85/ZooKeeper-Partitioning-A-project-report-1-320.jpg)
![1
Improving Write Throughput Scalability of ZooKeeper by
Partitioning Namespace
CSE 223B Term Project, Spring 2014
Pramod Biligiri
UC San Diego
psubbara@ucsd.edu
Anita Kar
UC San Diego
ankar@ucsd.edu
Anjali Kanak
UC San Diego
akanak@ucsd.edu
_____________________________________________________________________________________
Abstract: We demonstrate that write throughput of a ZooKeeper cluster can be increased by
implementing a partitioning system for the data. By enabling a single ZooKeeper cluster to have
multiple quorums, each with its own leader, client requests that want to access different partitions of
the namespace can be processed in parallel by relaxing the ordering guarantees across partitions.
Experimental evaluation of our implementation shows approximately 14% increase in throughput. The
only extra resource required for each node in the partitioned ZooKeeper is additional hard disk(s) to
cope with the increased throughput.
1. Introduction
ZooKeeper provides a distributed configuration service, synchronization service, and naming registry
for large distributed systems [1]. ZooKeeper nodes store their data in a hierarchical name space (called
znodes), much like a file system or a Trie data structure. Clients can read and write from/to the nodes
and in this way have a shared configuration service.
Partitioned ZooKeeper ZooKeeper follows a primary-backup replication scheme. Currently, the
leader node in a ZooKeeper ensemble processes all incoming client requests sequentially, thus ensuring
strictly ordered access to the znodes.
We created a partitioned version of the ZooKeeper with the goal of improving the write throughput
scalability. This was first suggested on the ZooKeeper wiki page [2] and discussed on the issue tracker
[3]. Thus, the user can specify a set of paths that can be updated independent of each other. This leads
to relaxation in ordering across all the root znodes, where each root znode corresponds to a path.
However for any particular path, the requests are still ordered. Hence, if there are independent
applications using the ZooKeeper ensemble, then partitioning should lead to increased throughput by
removing ordering constraints across independent operations and hence potentially parallelizing
processing and disk writes.
One of the existing suggestions to implement it is by creating completely separated clusters using the
available nodes. Our approach, however, differs from this as we are using the all the nodes while
making independent operations proceed parallelly. To enable this, we created multiple quorums with
the same set of available nodes. All nodes are members of all the quorums. Each quorum can be
visualized as a logical abstraction having its own leader and being responsible for a handling requests](https://image.slidesharecdn.com/zookeeper-partitioning-project-report-140617040820-phpapp02/75/ZooKeeper-Partitioning-A-project-report-1-2048.jpg)
![2
corresponding to a particular path. As every node is a part of multiple quorums, it is still involved in
processing of all the operations and its resources and fully utilized. This makes our approach more
economical than the aforementioned one in case of which resources like memory and CPU may remain
underutilized. Moreover, our implementation requires fewer nodes because each quorum comprises of
all the nodes and is contrary to the suggested approach where the nodes need to be distributed across
multiple quorums.
2. Motivation
ZooKeeper service is used in by many companies to provide coordination, synchronization and a
hierarchical namespace of data registers for various distributed applications. Typically, one ZooKeeper
cluster is used by multiple applications. These applications may be unrelated but still all requests are
still written sequentially to the transaction log on the disk since they are ordered and proposed by a
single ZooKeeper leader node. This leads to the possibility of the disk at the nodes becoming the
bottleneck for the cluster throughput. The ZooKeeper administrator’s guide [4] recognizes this issue
as it mentions that disk write into the transaction log is the most performance critical part of
ZooKeeper. Hence, for separate applications, the data can be handled and written separately.
Though one option is to have separate clusters for individual applications, it may end up being
expensive and lead to underutilization of resources. Hence, an ideal scenario would be to use the same
ZooKeeper cluster for multiple applications while removing the ordering guarantees between unrelated
requests coming from these separate applications. Then the independent sets of requests can be written
to different transaction logs which, as discussed earlier, can improve the performance. This is the issue
we tried to address through our implementation of partitioned ZooKeeper.
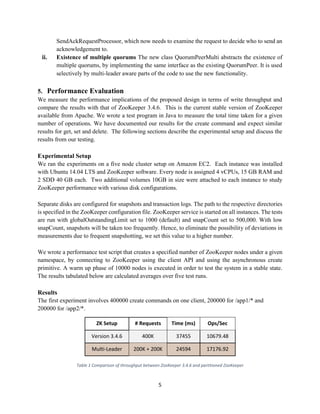
3. Design
Each ZooKeeper node is part of a quorum of nodes, where it participates in voting on proposals and
leader election. A ZooKeeper node can also service client requests. A client request is processed in
multiple stages. Each stage reads events from an incoming queue, performs its actions and passes the
output to the incoming queue of the next stage. The use of stages and queues is designed to avoid
blocking of incoming requests due to network and disk operations.
In ZooKeeper’s current design, a cluster can have only one leader and an associated quorum. We
modified this design to enable multiple leaders to exist within a cluster, each with their own quorum.
Each node can be part of multiple quorums. A node can be a leader in one quorum and a follower in
others, or a follower in all the quorums that it is part of. Having a node be the leader for multiple
quorums would have no benefit for the performance gains we are trying to obtain, so we did not
experiment with that option.
The namespace of nodes is partitioned among the leaders, with routing logic in each follower to
forward requests to the appropriate leader. Figure 1 below shows the current and modified designs of
ZooKeeper.](https://image.slidesharecdn.com/zookeeper-partitioning-project-report-140617040820-phpapp02/85/ZooKeeper-Partitioning-A-project-report-2-320.jpg)
![3
Figure 1: ZooKeeper cluster with multiple quorums
Whenever a node receives a proposal from the leader, it appends the request to a transaction log on
disk and sends back an acknowledgement. This transaction log is used for recovery in case of leader
failure. The write to disk constitutes a performance critical path of the request processing flow.
Therefore, the ZooKeeper administrator's guide [4] recommends keeping the transaction log on a
separate device from any other reads and writes on the system. Since each node can now be part of
multiple quorums, the transaction log for each quorum needs to be on its own device. We have
modified ZooKeeper to support this. Figure 2 shows this design.
Figure 2: Node operation as a part of multiple quorums](https://image.slidesharecdn.com/zookeeper-partitioning-project-report-140617040820-phpapp02/85/ZooKeeper-Partitioning-A-project-report-3-320.jpg)
![4
4. Implementation
Our initial approach [5] focused on partitioning
incoming requests and handling them in parallel. For
each distinct top-level path that comes in (/app1,
/app2 etc.), we create a new chain of request
processing stages and all subsequent requests on that
path are routed to that chain. Though this gave us a
performance speed up in the request processing stage,
the strict ordering guarantees of ZooKeeper’s atomic
broadcast protocol within a quorum meant that the
requests were getting serialized before being
forwarded to the leader. This led us to the current
design of having multiple quorums, in order to relax
the ordering guarantees across different request paths.
We are able to reuse a significant amount of the
routing logic from the initial implementation.
Figure 3 shows the class diagram for the multiple
quorum approach [6]. A separate thread is created
corresponding to each quorum to handle the request
flow and the inter-node communication. Each
QuorumPeerThread can be allocated one or more
partitions of the request namespace by the routing
logic, which determines the quorum by examining the
request.
Figure 3 Class diagram for the multiple quorum approach
Challenges during implementation
The original ZooKeeper codebase has the following core assumptions:
i. Total ordering of all requests, by a single primary
ii. All requests are treated alike
iii. Each node is part of only one quorum
Our design required changing each of these core assumptions, without compromising on performance
or safety. Further, the code uses multithreading extensively, and has optimized usage patterns for disk
and network I/O. Thus it was a challenge to modify the code-base to suit our needs.
Below we cite a couple of examples:
i. Request specific processing We introduced a new interface called RequestFlushable, along
the lines of the existing Flushable interface. This is implemented by](https://image.slidesharecdn.com/zookeeper-partitioning-project-report-140617040820-phpapp02/85/ZooKeeper-Partitioning-A-project-report-4-320.jpg)
![7
6. Future Work
In the current design of the ZooKeeper, a number of messages are exchanged between the leader and
the followers. By introducing two leaders, we do not increase the number of network messages since
the requests are split between the leaders. Hence, no latency is introduced by the partitioned ZooKeeper
design. Network latency can be one of the areas that might be of interest for future work through.
In our current implementation, the leaders for the quorum are statically chosen on system startup. We
have not handled leader failure and election of multiple leaders. The routing code that we have is quite
basic, and can be extended to be user configurable. We have also not studied the impact of network
latency on larger quorums with multiple leaders. For the purpose of performance evaluation, we chose
to implement only one of the primitives (create). This is similar to the rationale mentioned on the
original ZooKeeper ( [7], Section 5.1) paper for their performance evaluations.
7. Conclusion
Thus, using the same set of servers, we have implemented multiple quorums, each of which is
responsible for processing requests for a particular request path. Each quorum has its own leader which
orders only the requests targeted to the path that quorum is associated with. This relaxes the ordering
constraint across operations related to different paths while ensuring that for a particular path, the
ordering guarantee is still maintained. In order to parallelize disk writes, we assigned a separate disk
to each node for every quorum it was a part of. We demonstrated that write throughput of ZooKeeper
can be improved by separating the znode namespace and by having different leaders process
independent paths. We see an approximate improvement of 14% using this method.](https://image.slidesharecdn.com/zookeeper-partitioning-project-report-140617040820-phpapp02/85/ZooKeeper-Partitioning-A-project-report-7-320.jpg)
![8
References
[1] "Apache_ZooKeeper," [Online]. Available: http://en.wikipedia.org/wiki/Apache_ZooKeeper.
[2] "Partitioned ZooKeeper," [Online]. Available:
http://wiki.apache.org/hadoop/ZooKeeper/PartitionedZooKeeper. [Last edited by F. Junqueira, 18
May 2010].
.[3] D. Williams. [Online]. Available: http://ria101.wordpress.com/2010/05/12/locking-and-
transactions-over-cassandra-using-cages/.
[4] "ZooKeeper Adminitrator's Guide," [Online]. Available:
http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_commonProblems.
[5] "Bitbucket Link to Older Approach (zk-Partition)," [Online]. Available:
https://bitbucket.org/pramodbiligiri/zk-partition.
[6] "Bitbucket link to New approach (zk-Multileader)," [Online]. Available:
https://bitbucket.org/pramodbiligiri/zk-multileader.
[7] Patrick Hunt et al, "ZooKeeper: Wait-free coordination for Internet-scale systems," in
USENIXATC'10 Proceedings of the 2010 USENIX conference on USENIX annual technical conference,
2010-06-23.](https://image.slidesharecdn.com/zookeeper-partitioning-project-report-140617040820-phpapp02/85/ZooKeeper-Partitioning-A-project-report-8-320.jpg)










![[2A5]하둡 보안 어떻게 해야 할까](https://cdn.slidesharecdn.com/ss_thumbnails/2a5-140929211558-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












![Jms deep dive [con4864]](https://cdn.slidesharecdn.com/ss_thumbnails/jmsdeepdivecon4864-160927041349-thumbnail.jpg?width=640&height=640&fit=bounds)











































