Download as KEY, PPTX







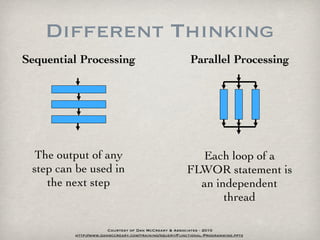
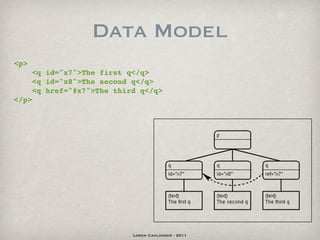
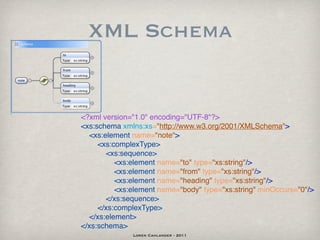

![Path Expressions
Find the first section of the chapter with the title
“Starry Night” of the document named “alpha.xml”:
document(“alpha.xml”)//chapter[title = “Starry Night”]/section[1]
Loren Cahlander - 2011](https://image.slidesharecdn.com/xquery-atechnicaloverviewrevised-121002132159-phpapp01/85/XQuery-a-technical-overview-11-320.jpg)

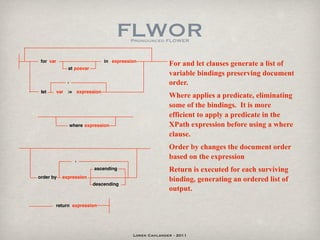












The document provides a technical overview of XQuery, highlighting its standardized nature for combining XML documents and its implementation in functional programming. It contrasts imperative and functional programming styles and details various XQuery features, functions, and elements. Additionally, it includes examples of XQuery expressions, such as FLWOR, and references several resources for further learning.































![Jms deep dive [con4864]](https://cdn.slidesharecdn.com/ss_thumbnails/jmsdeepdivecon4864-160927041349-thumbnail.jpg?width=640&height=640&fit=bounds)






















