




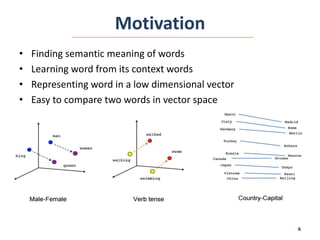


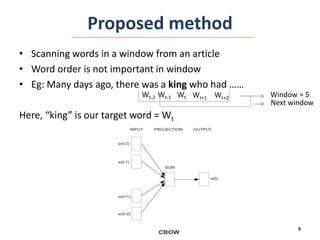







This document summarizes the Word2Vector model proposed by Tomas Mikolov et al. in 2013 for learning word embeddings from large amounts of text. It describes the motivation for representing words as vectors to capture semantic meaning based on context. The proposed method uses either the Continuous Bag-of-Words or Skip-gram model on a sliding window of words to predict target words. The models are trained using a neural network and stochastic gradient descent. The document also discusses applications of Word2Vector including using the model to learn embeddings of medical concepts from clinical notes.


























































