Downloaded 212 times








![Instead Match the Data in your
Application
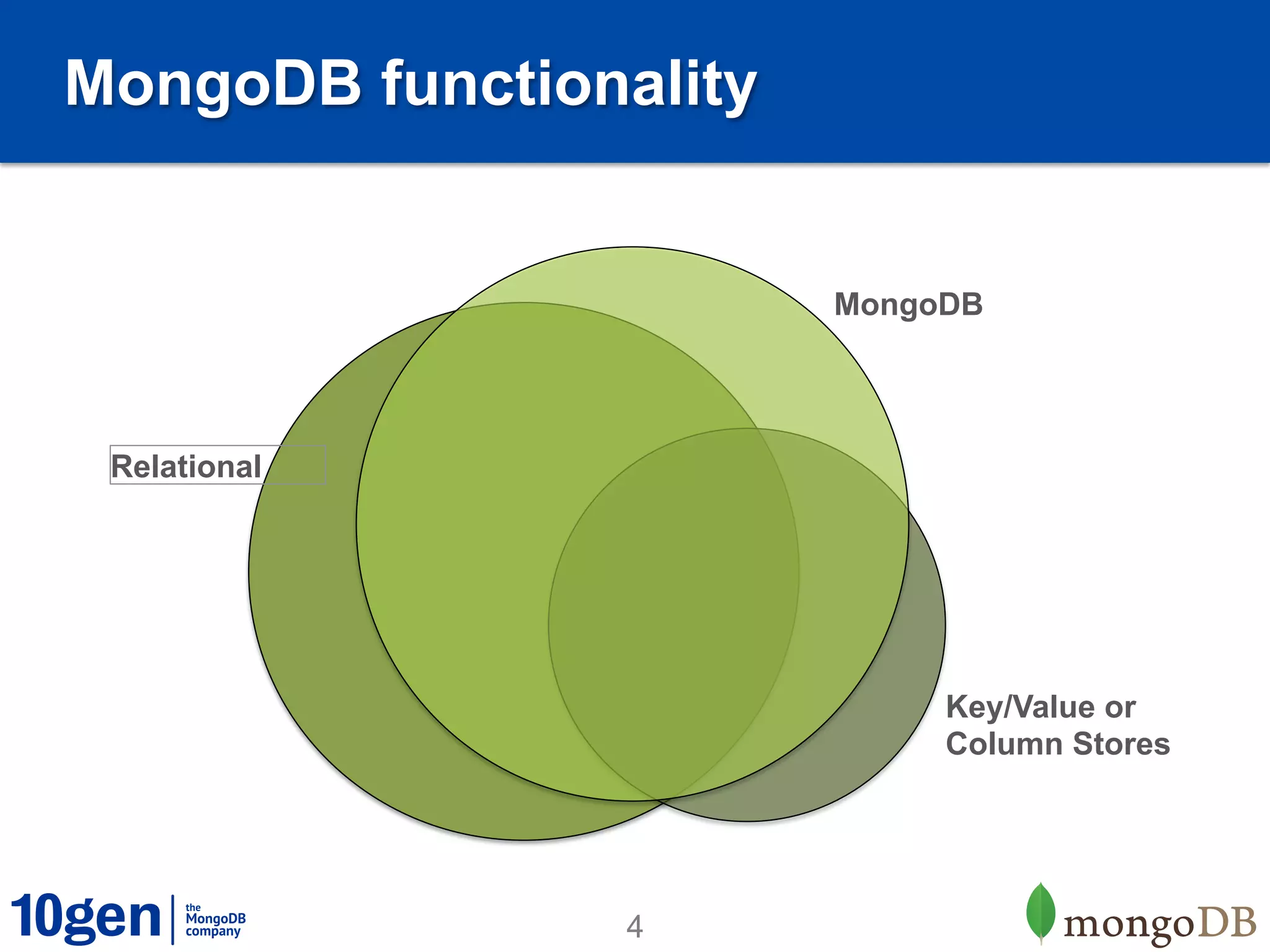
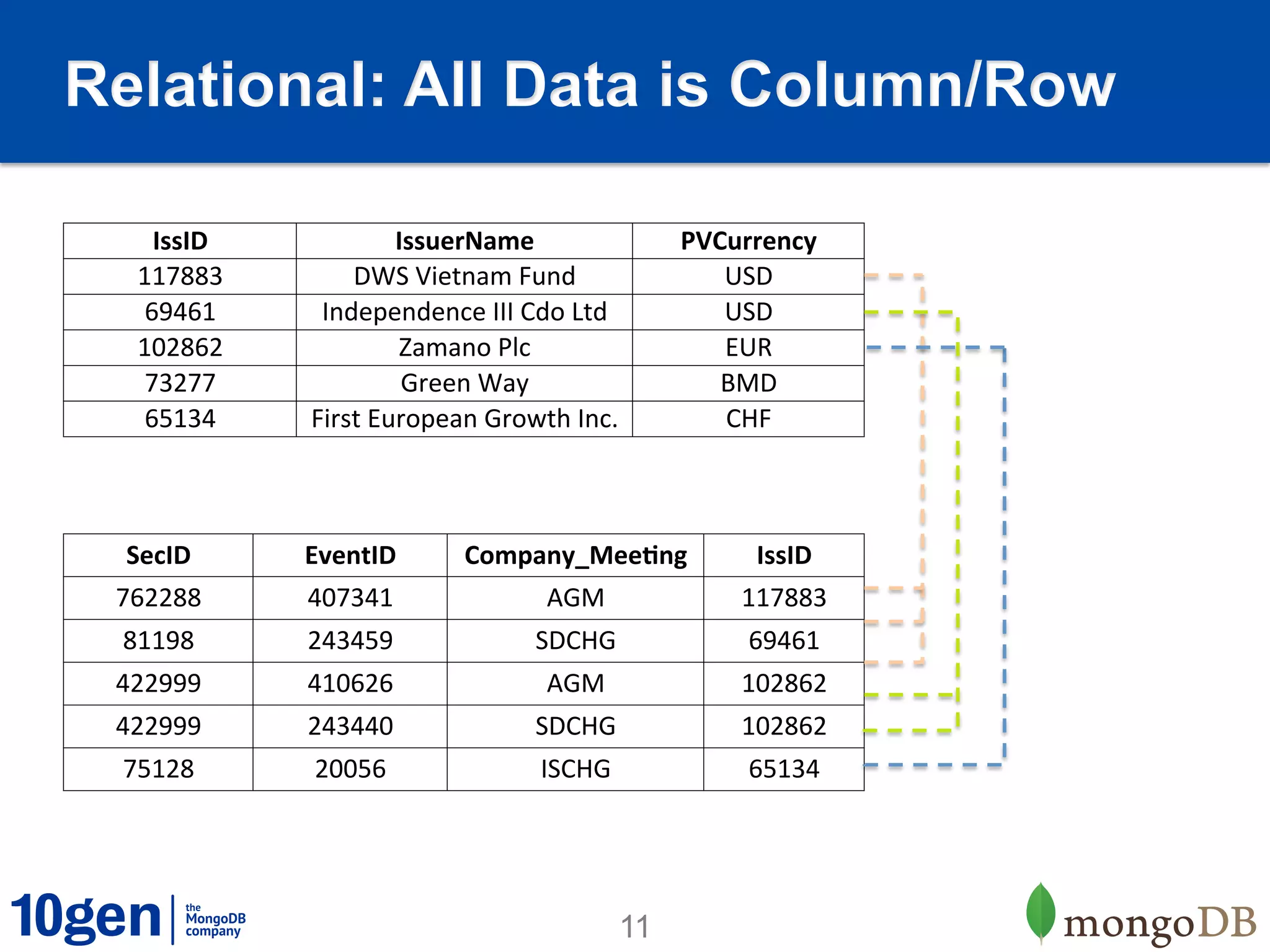
Relational MongoDB
{!
!"IssID" : 65134,!
!"IssuerName" : "First European
! ! ! ! !Growth Inc.",!
!"actions" : [!
! !{!
! ! !"Company_Meeting" : "ISCHG",!
! ! !"EventID" : 20056,!
! ! !"SecID" : 75128!
! !},!
! !{!
! ! !"Company_Meeting" : "LSTAT",!
! ! !"EventID" : 2716296,!
! ! !"SecID" : 75128!
! !}!
!]!
}!
12](https://image.slidesharecdn.com/1303-referencedatawebinar-130319102338-phpapp01/75/Webinar-How-Banks-Manage-Reference-Data-with-MongoDB-12-2048.jpg)


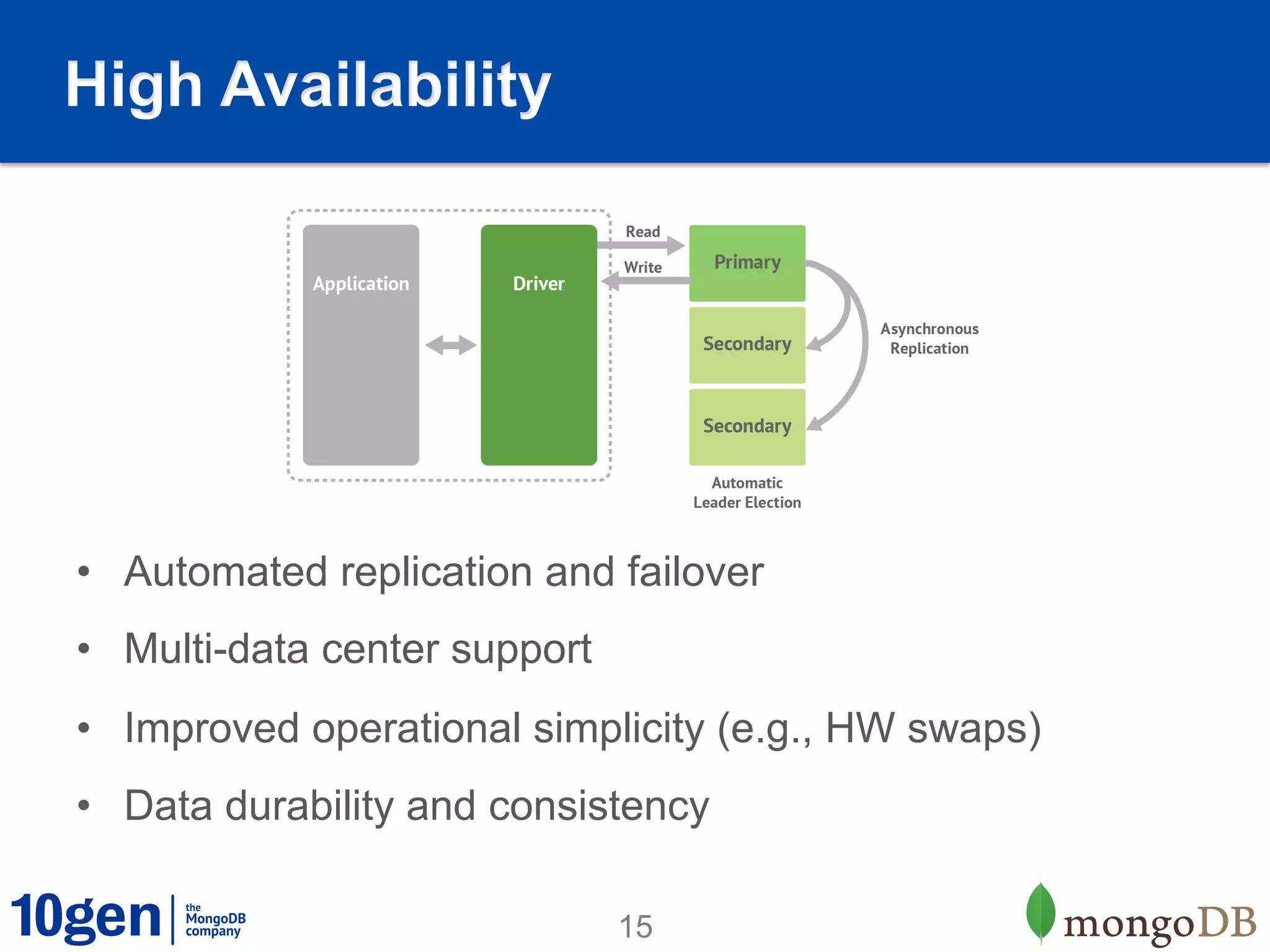
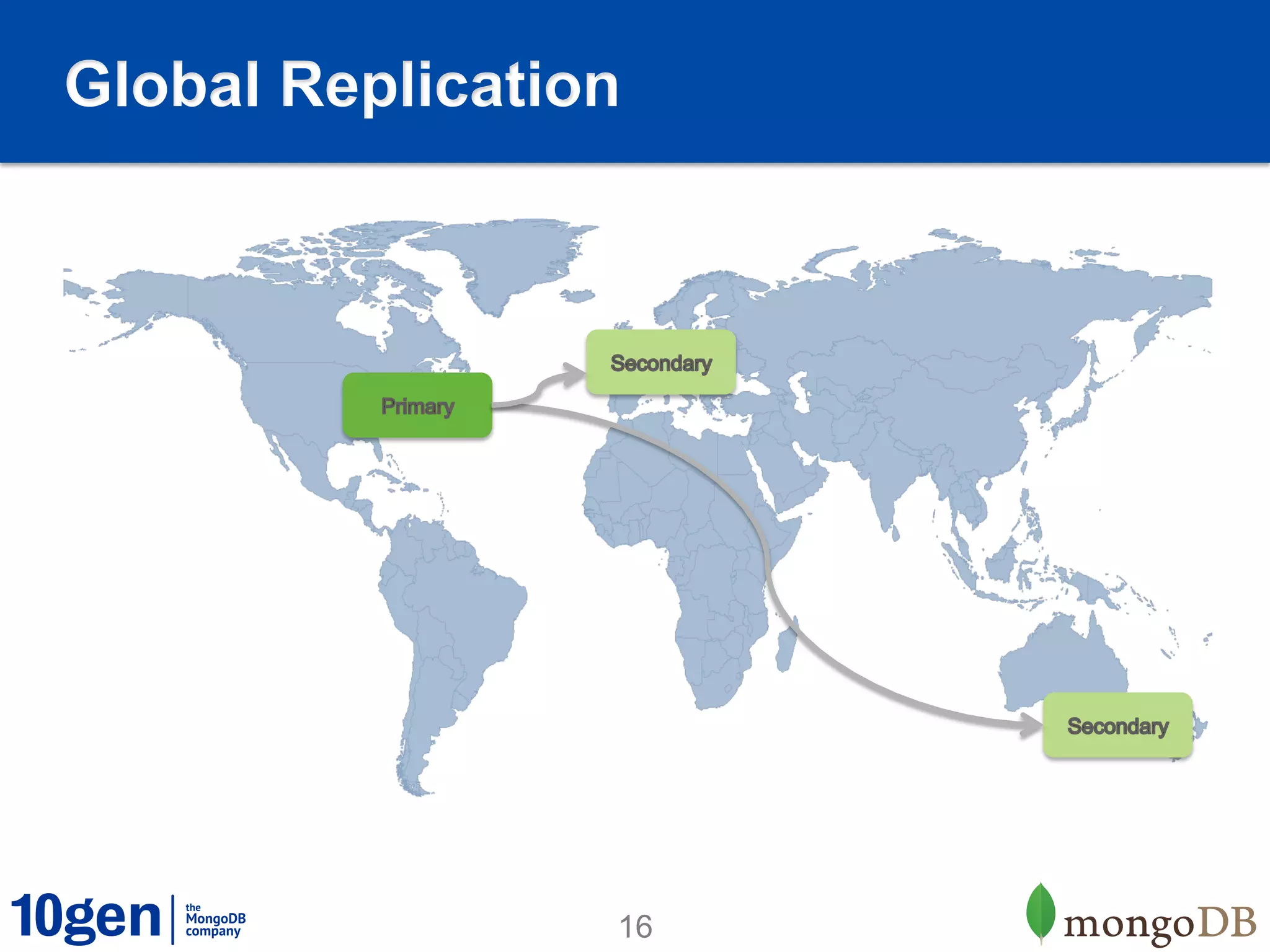

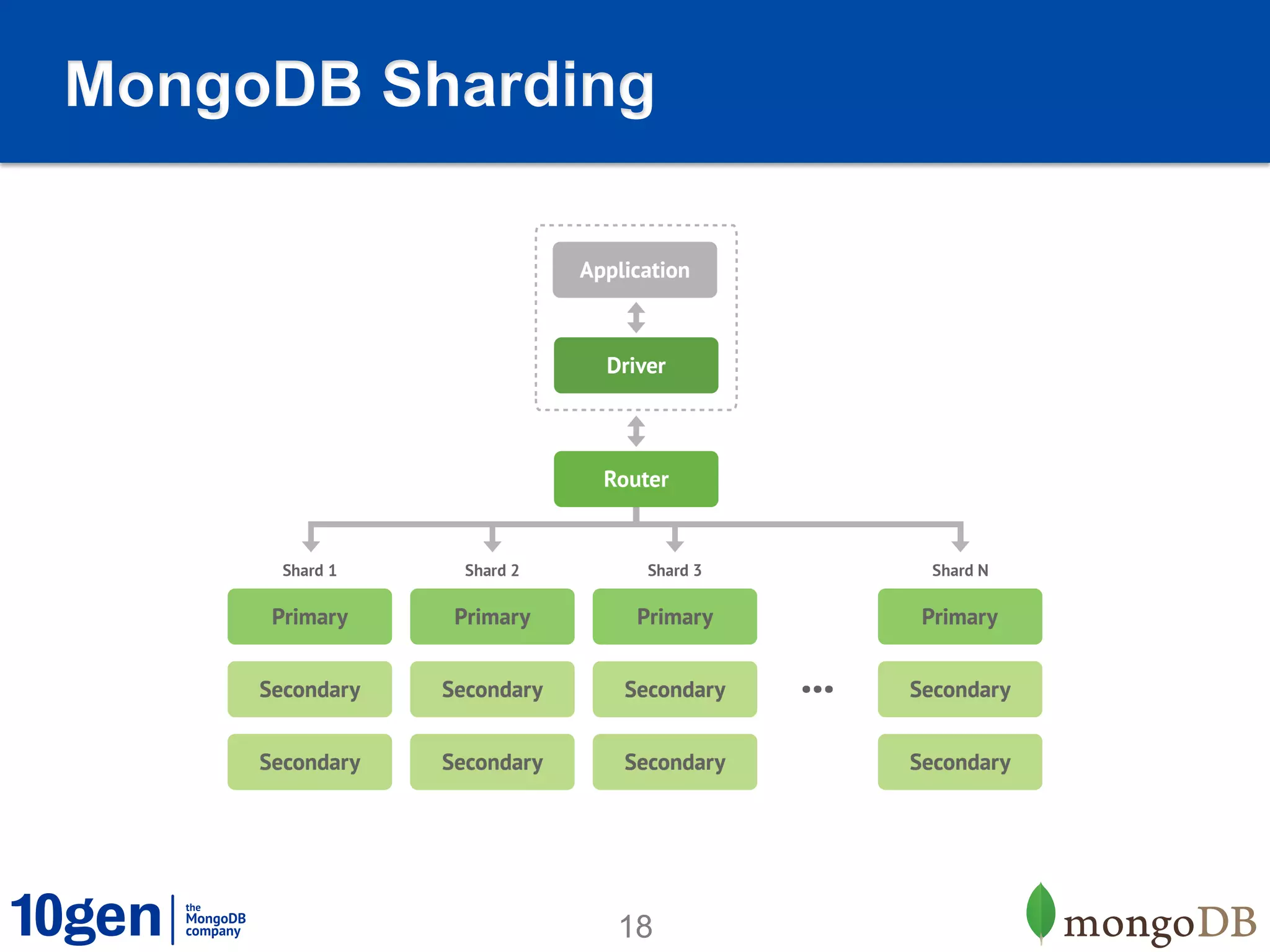
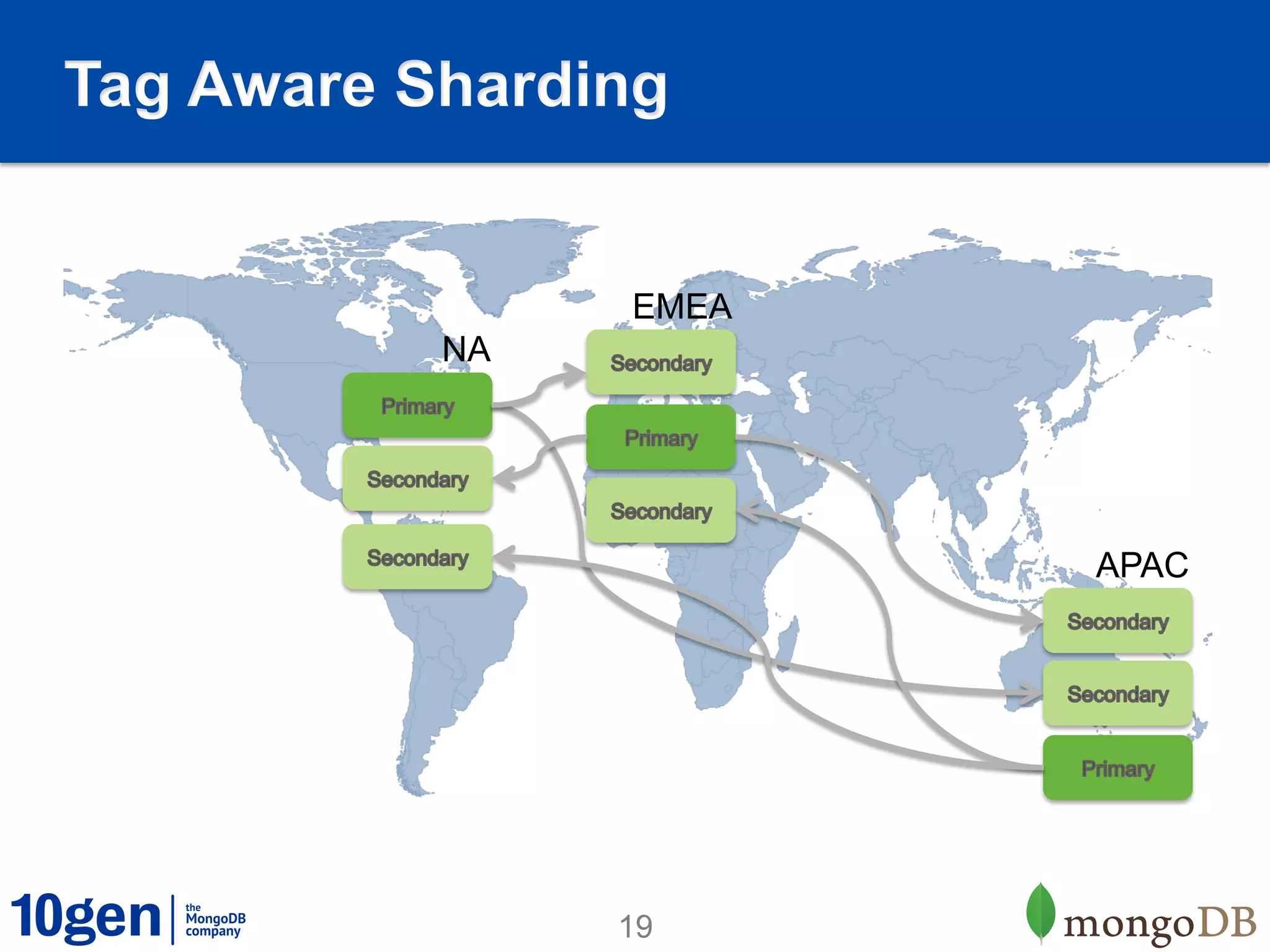
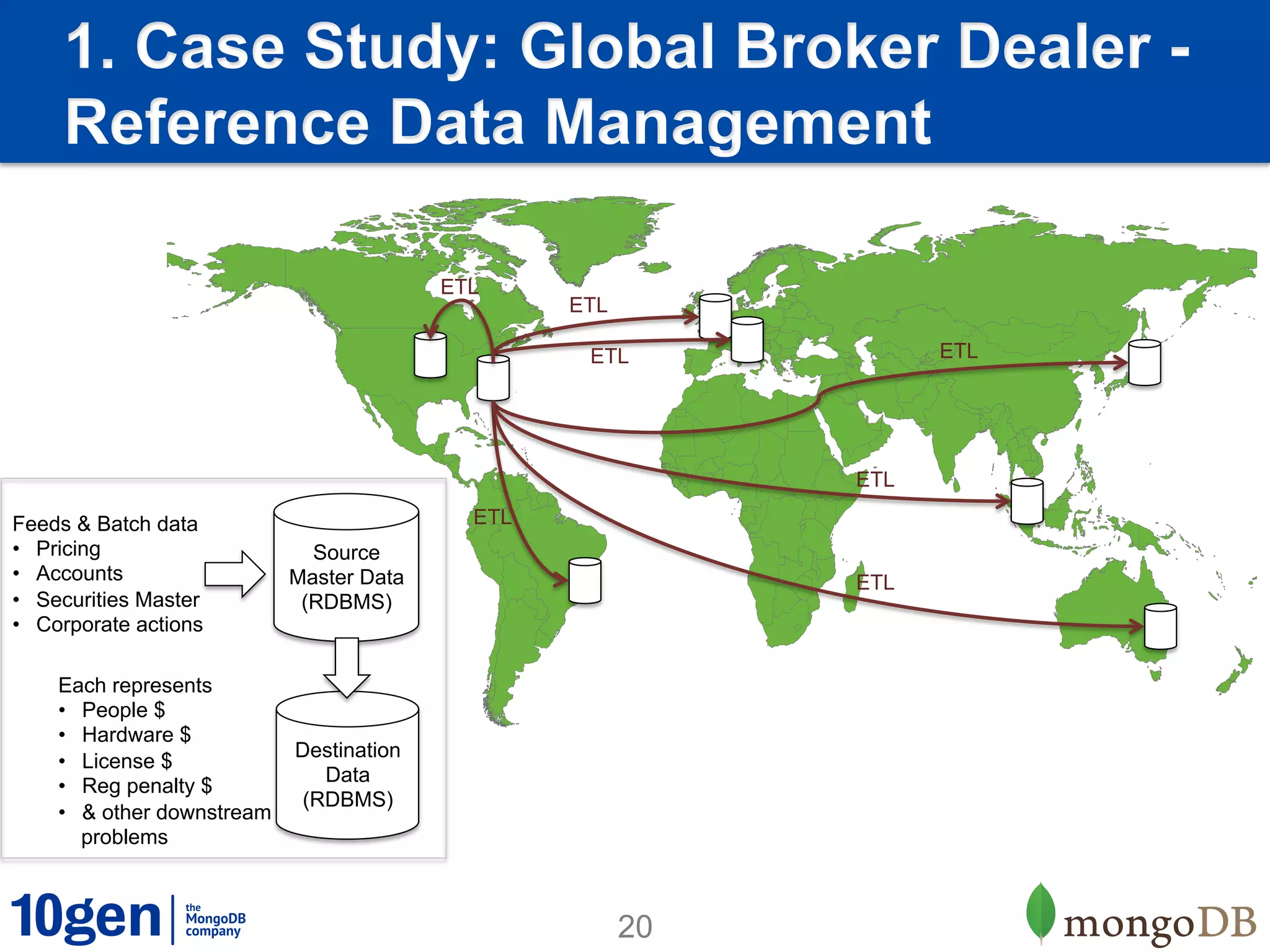
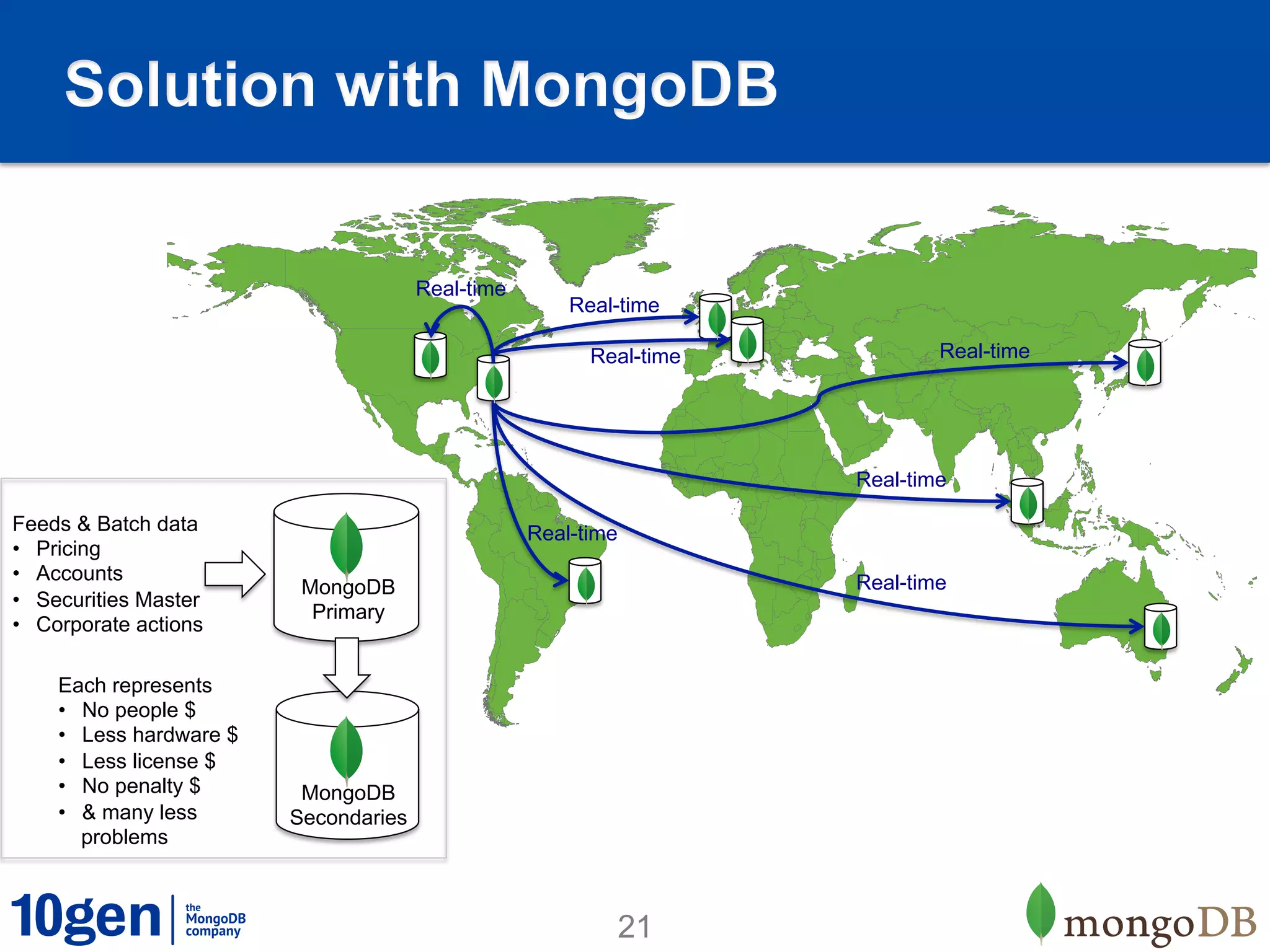
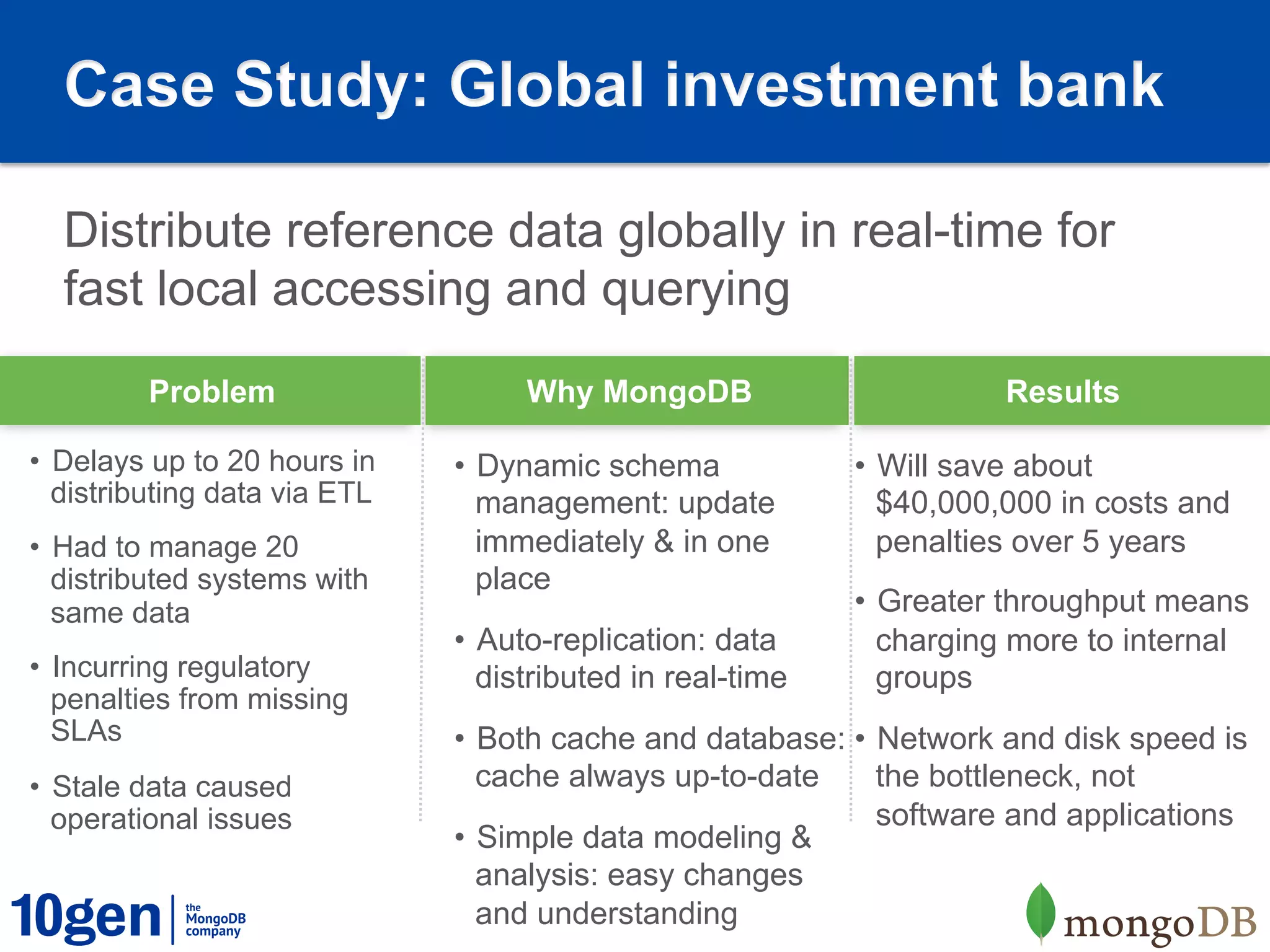




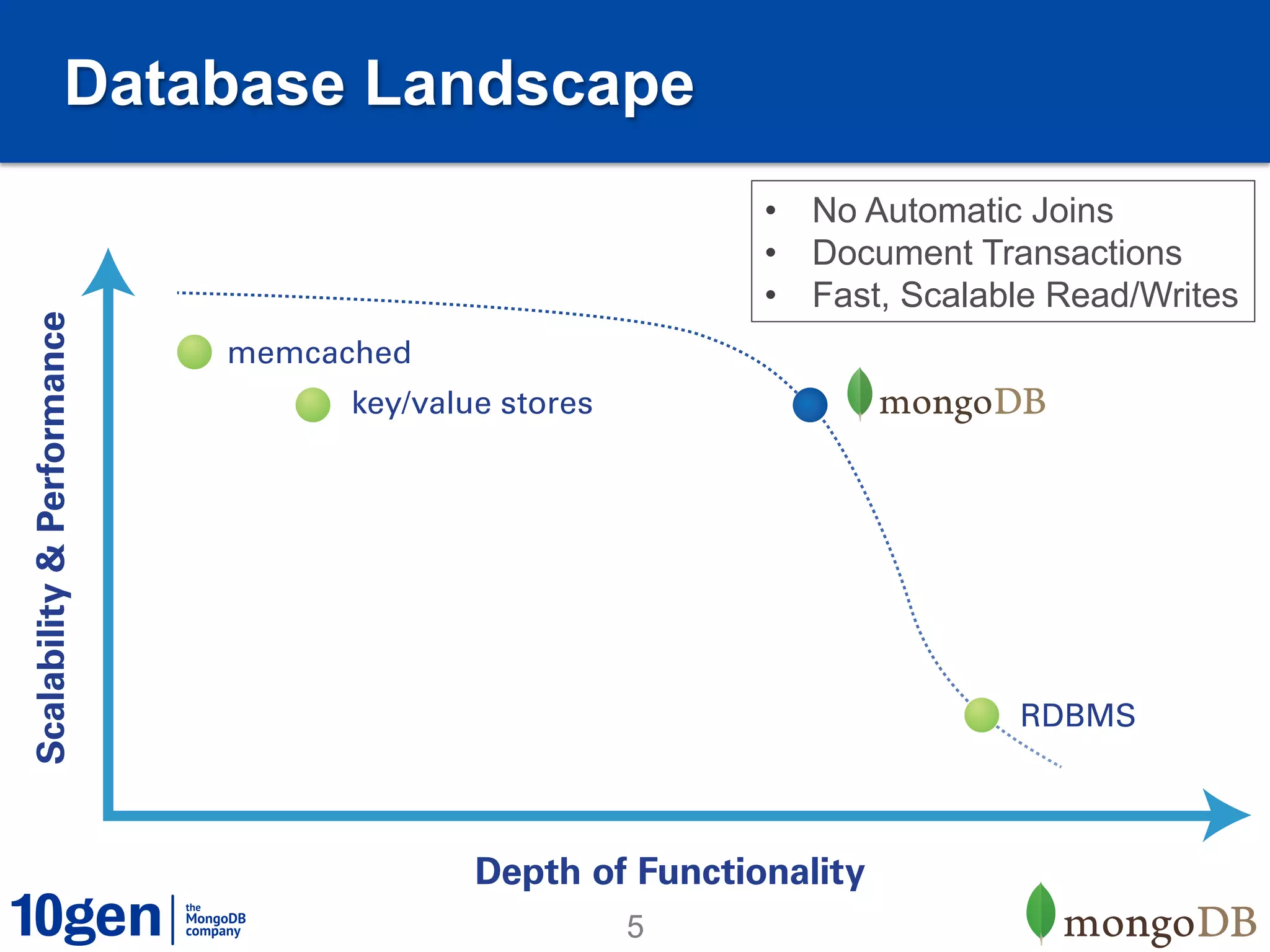
1. MongoDB is well-suited for reference data solutions due to its dynamic and flexible schema, built-in replication and high availability features, and tag aware sharding which allows for geographic distribution of data. 2. A case study of a global broker dealer showed how MongoDB could replace expensive and complex ETL processes for distributing reference data, saving over $40 million over 5 years. 3. Key benefits included real-time data distribution, faster querying of local data, and avoiding regulatory penalties from delays in data distribution.




































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











