Downloaded 77 times









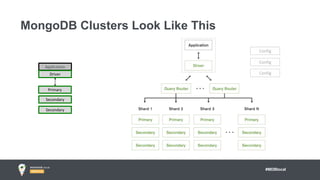




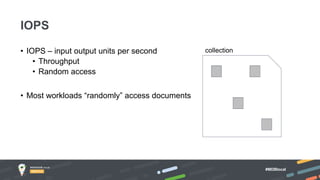
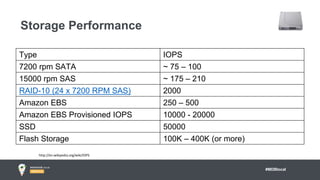


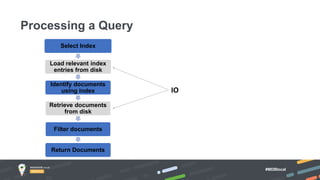
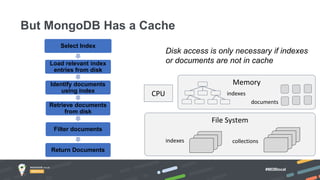
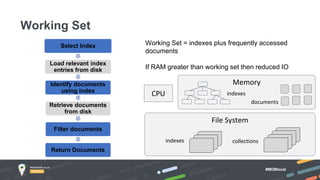











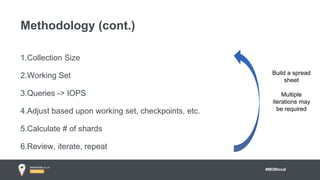
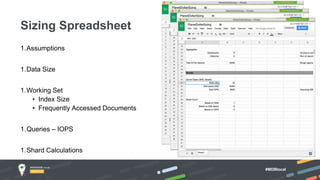


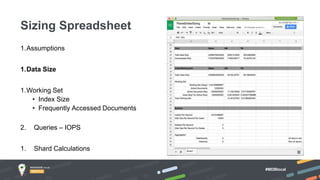






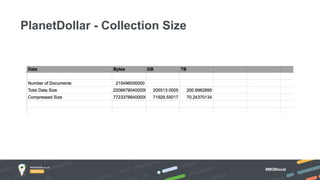


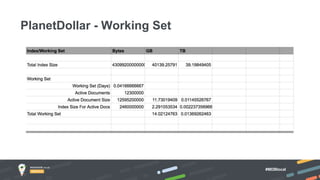









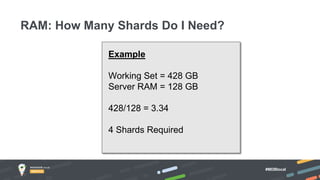

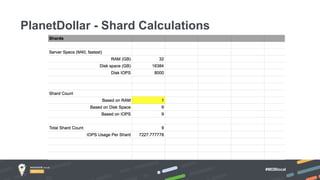



Jay Runkel presented a methodology for sizing MongoDB clusters to meet the requirements of an application. The key steps are: 1) Analyze data size and index size, 2) Estimate the working set based on frequently accessed data, 3) Use a simplified model to estimate IOPS and adjust for real-world factors, 4) Calculate the number of shards needed based on storage, memory and IOPS requirements. He demonstrated this process for an application that collects mobile events, requiring a cluster that can store over 200 billion documents with 50,000 IOPS.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































