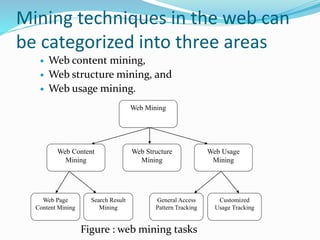
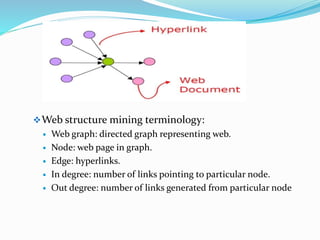
The document summarizes techniques for web mining, which involves mining web content, structure, and usage data. Web content mining extracts useful information from web page content and structures. Web structure mining analyzes the hyperlink structure between pages to determine important pages and group similar pages. Web usage mining analyzes server logs to discover general access patterns and customize websites for individual users based on their behavior. Text mining extends traditional data mining to unstructured text data through features like word occurrences and relationships.