The document discusses various topics related to web mining and data mining including:
- Web mining techniques like web content mining, web usage mining, and web structure mining.
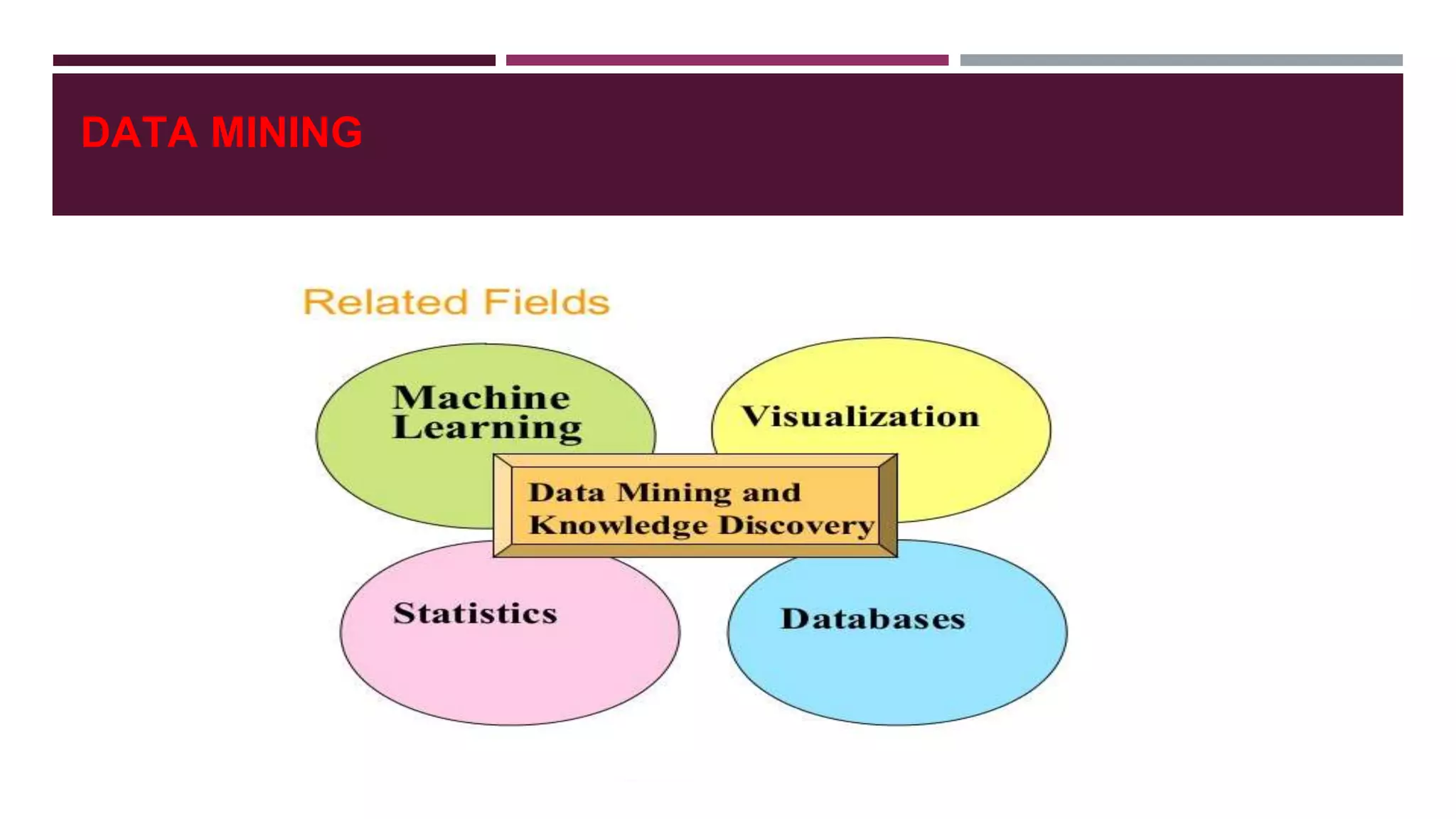
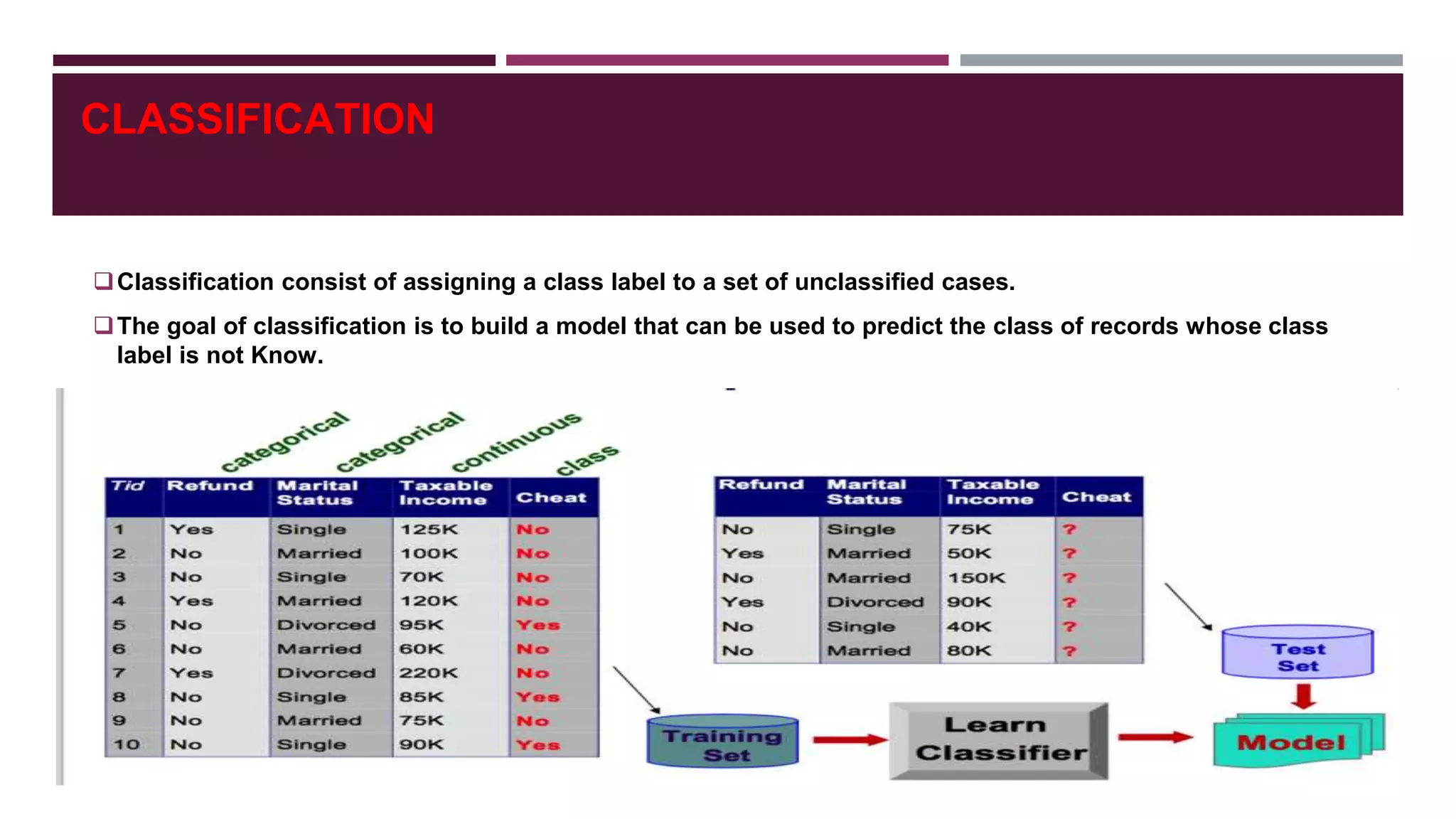
- Common data mining techniques like classification, clustering, association rule mining etc. and how they are applied in web content mining.
- How web usage mining analyzes server log files to understand user browsing behavior and patterns.
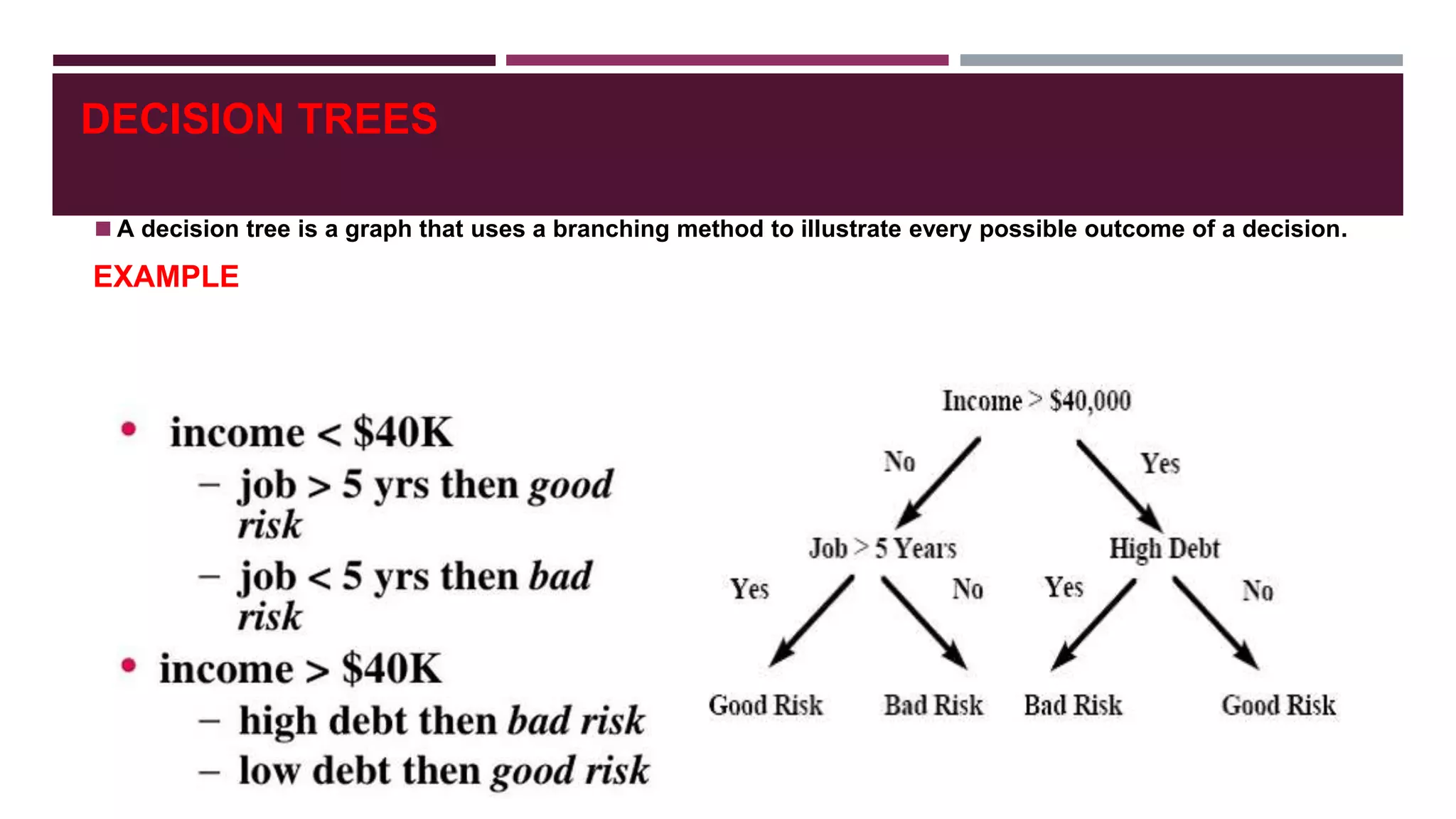
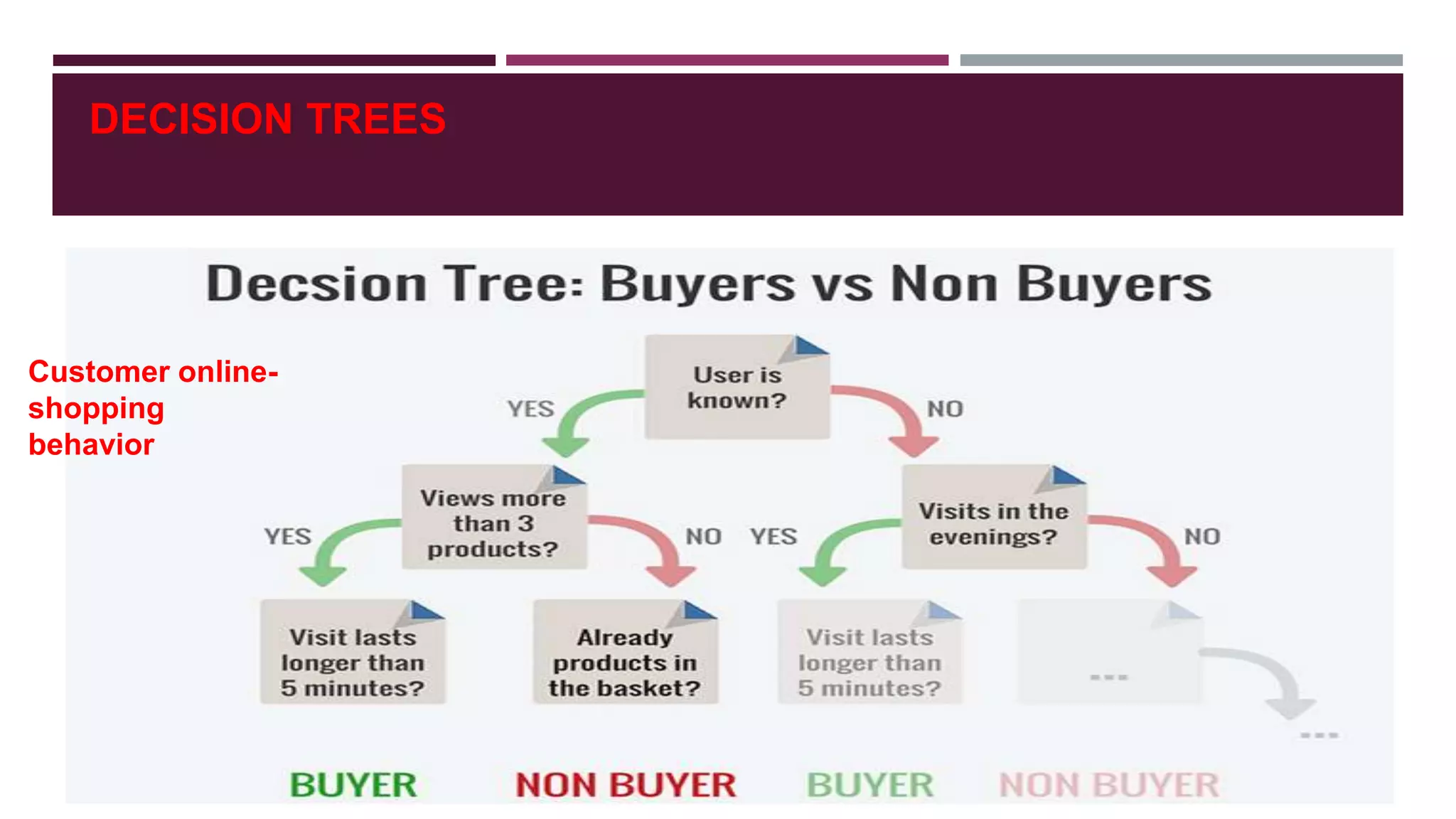
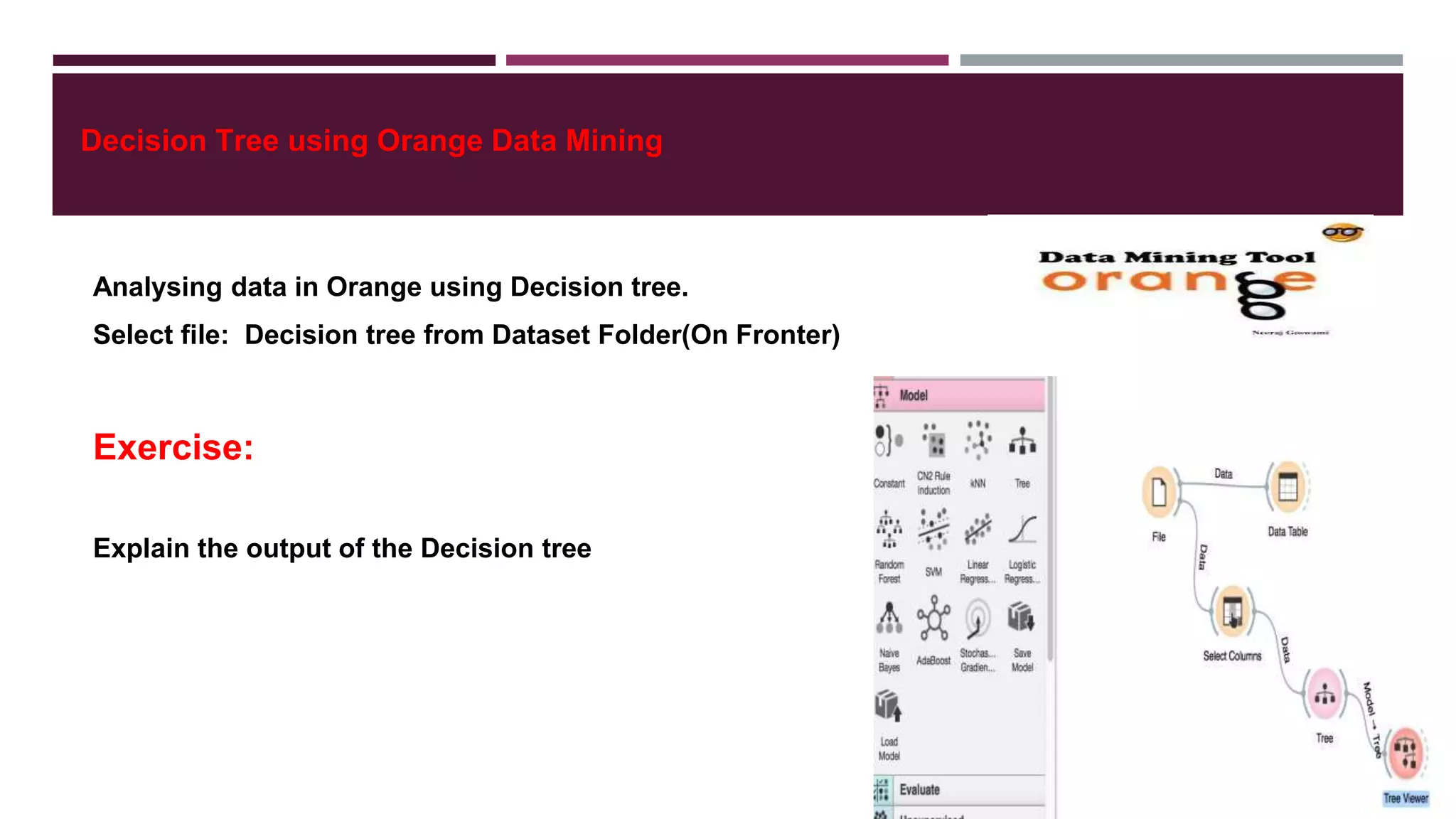
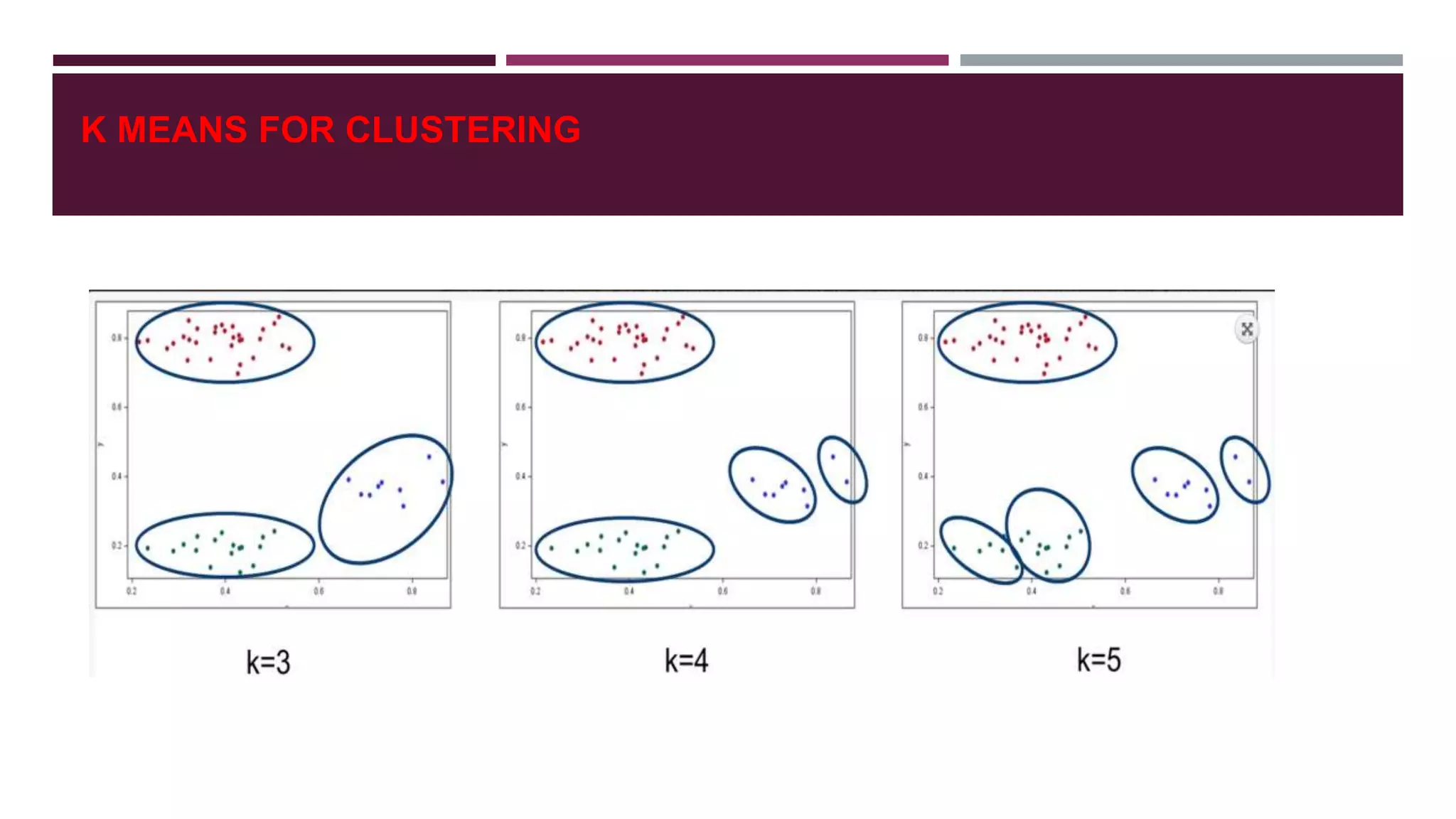
- Classification and clustering are two popular techniques used in web usage mining, with decision trees and k-means clustering provided as examples.


































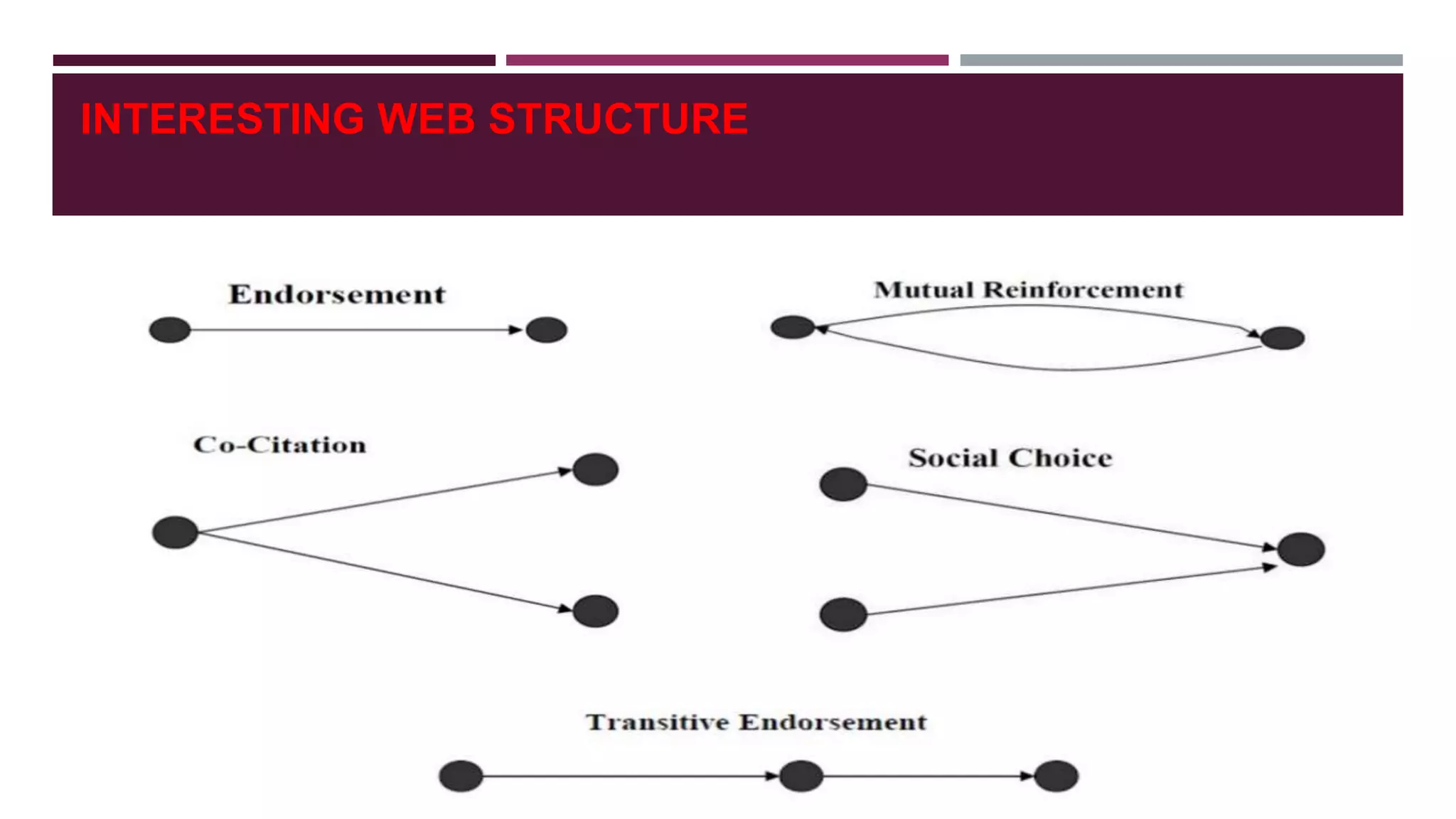
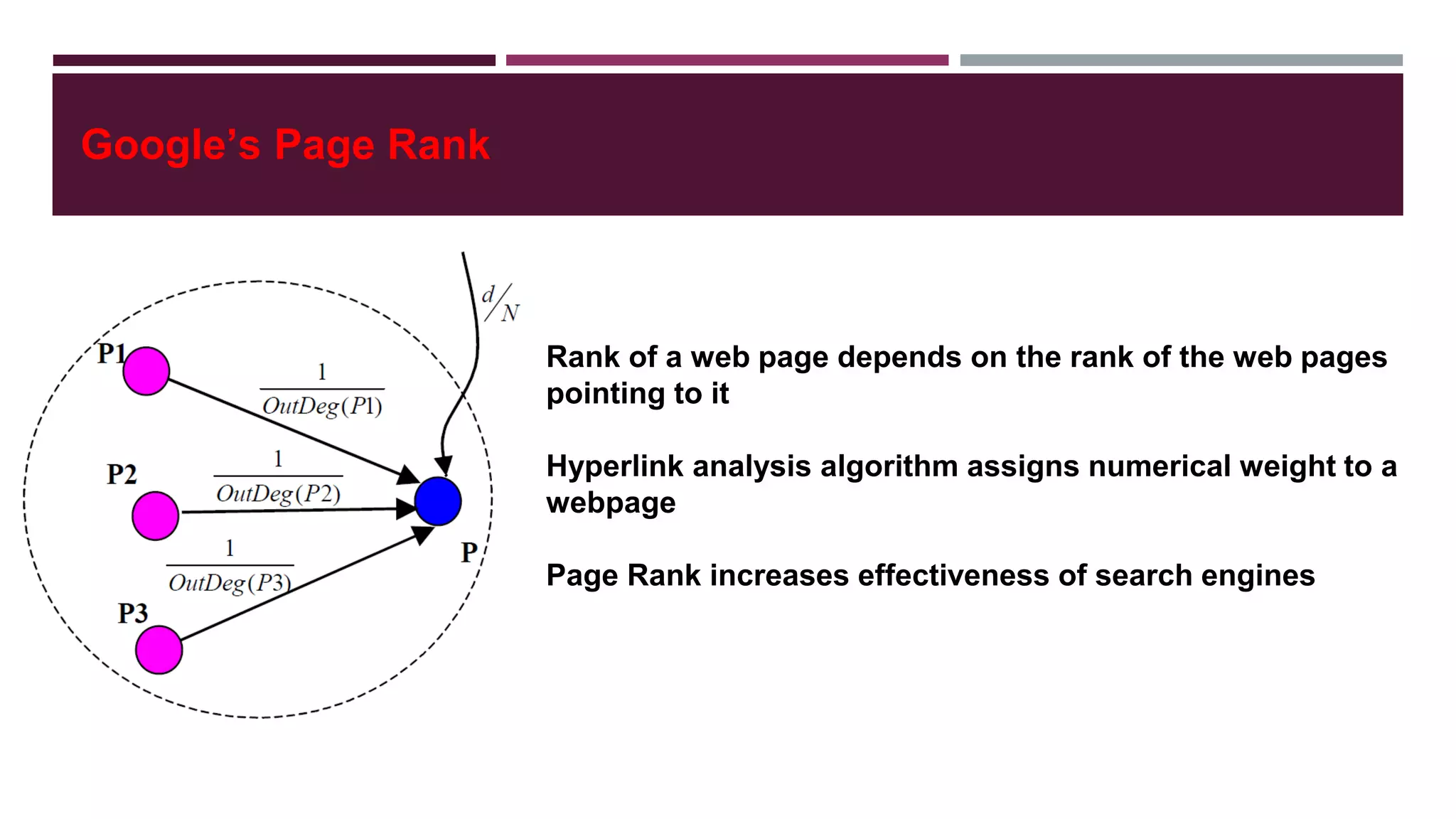

![SOCIAL NETWORK ANALYSIS
Social network analysis [SNA] is the mapping and measuring of relationships and flows between
people, groups, organizations, computers, and other connected information/knowledge entities.
The nodes in the network are the people and groups while the links show relationships or flows
between the nodes.
SNA provides both a visual and a mathematical analysis of human relationships.
EXAMPLE:
Who knows whom and who shares what information
and knowledge with whom through what media.](https://image.slidesharecdn.com/webminingsocialmediamining-190604083351/75/Web-mining-and-social-media-mining-44-2048.jpg)




















































![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)




