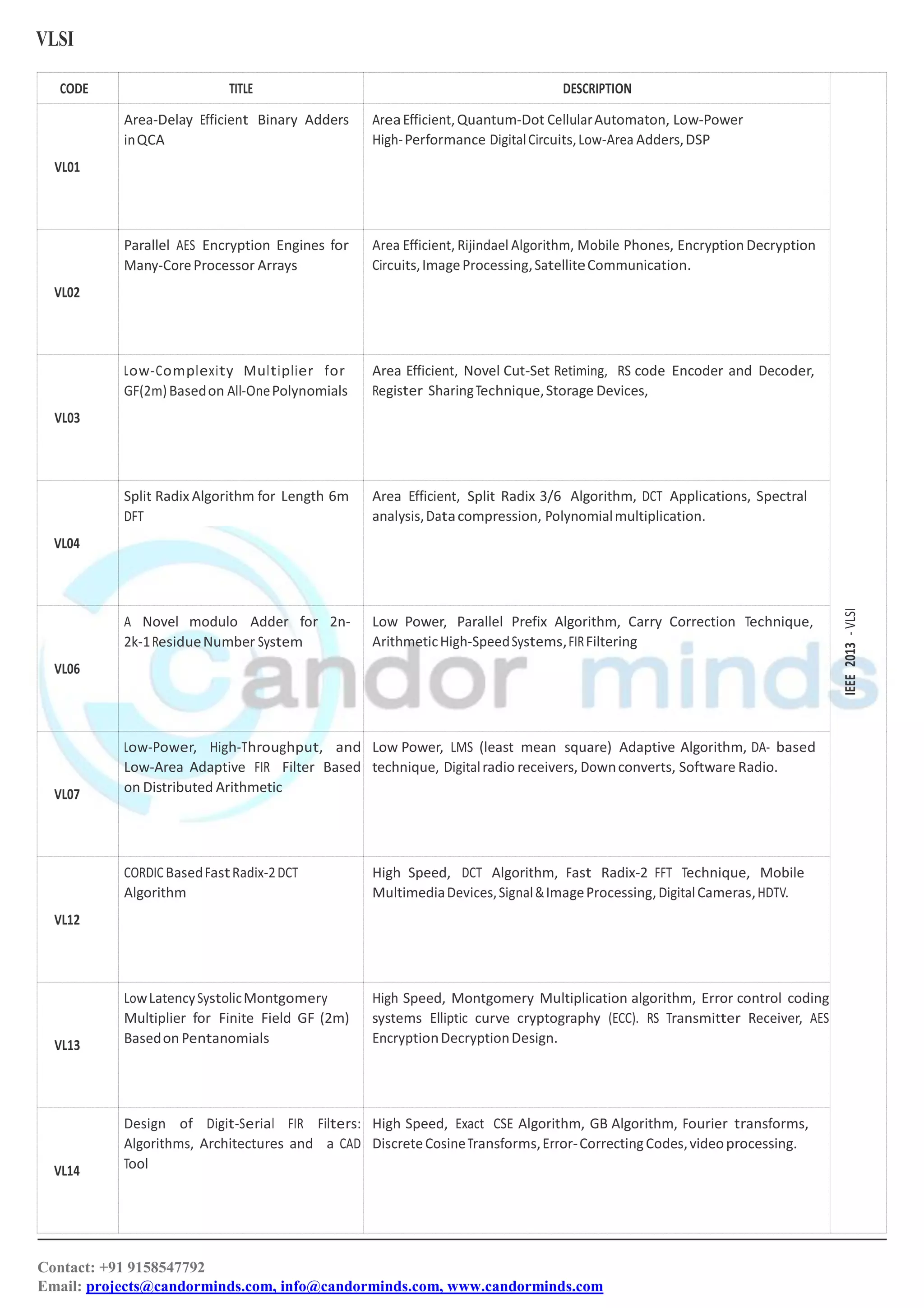
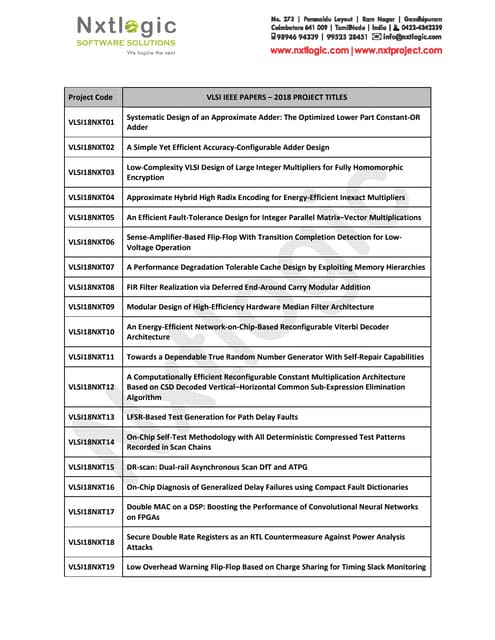
This document contains information about various VLSI and low power projects, including titles, codes, and brief descriptions. It lists 30 projects related to topics like area-efficient adders and multipliers, low power filter and encryption designs, testing techniques, and transforms. The projects aim to optimize aspects like area, speed, power consumption and implementation on FPGAs or ASICs.